
SQL & Orchestration Techniques For Functional, Idempotent, Tested, Two-Stage Data Architectures
If you’re tired of your data transformations randomly breaking, producing different results for no apparent reason, or taking forever to debug when something goes wrong, this article is for you. Stop fighting your data pipeline and start winning.
While FITT principles—Functional, Idempotent, Tested, and Two-stage design (What is FITT? Read the overview blog post)—sound compelling in theory, most data transformations occur in SQL within ELT frameworks that were not initially designed with functional programming paradigms in mind. SQL doesn’t just magically give you functional patterns, and getting true idempotence means actually planning for it – not just hoping the same query works the same way twice.
The key challenge is developing what we call FI chunks—Functional and Idempotent chunks—that follow FITT principles within the limitations of modern data stack tools.
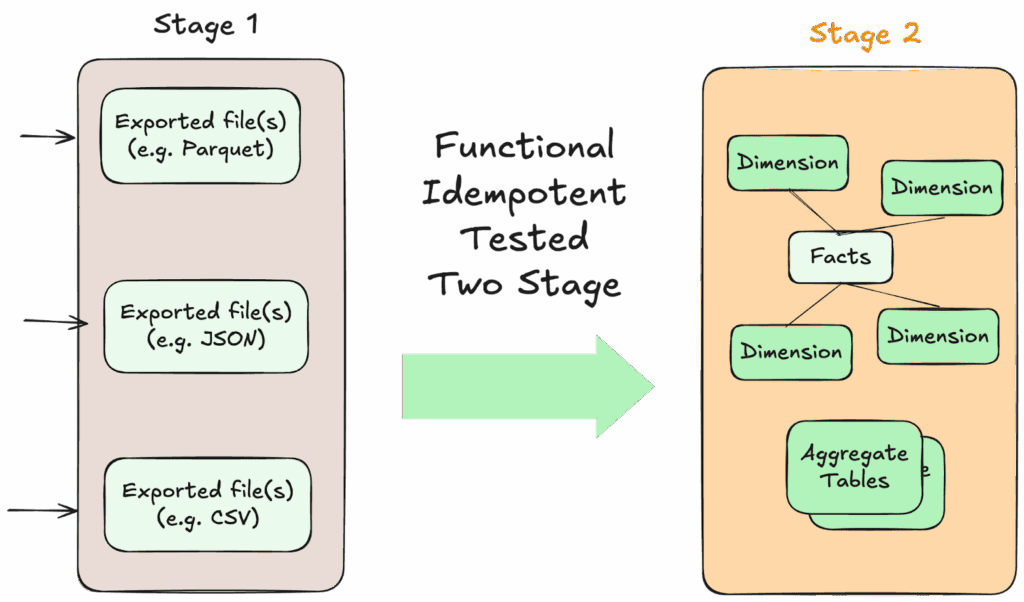
FITT data architecture—Functional, Idempotent, Tested, and Two-stage
After years of making FITT work in the real world – from old-school data warehouses to shiny new lakehouse setups – we’ve figured out specific SQL and ELT techniques that actually deliver on the promise. Whether you’re using dbt, Databricks, Snowflake, BigQuery, or cobbling together open-source tools, these approaches work.
This stuff really shines when:
- Your total data size data isn’t massive (under 100TB-ish, with much smaller updates)
- Updates happen hourly or longer
- You’re doing serious data integration work (building star schemas, complex joins, the whole nine yards)
- Business stakeholders keep asking for pipeline changes (because of course they do)
- You need results you can actually trust (and honestly, who doesn’t?)
If any of that sounds familiar, keep reading. We’re about to show you how to build data pipelines that don’t make you want to throw your laptop out the window.
The Challenge: Making SQL Functional and Idempotent
SQL as a language presents inherent challenges for functional programming approaches. Unlike pure functional languages, where functions always return the same output for given inputs, SQL doesn’t naturally lend itself to pure functional patterns for several fundamental reasons. Even Python, the data engineer’s favorite language, is easier to write in functionally.
State management and mutability create the most significant obstacles. Traditional SQL operations often involve modifying data in place through UPDATE and DELETE statements. Functional programming emphasizes immutability and avoiding side effects, which directly conflict with the mutable nature of database tables.
Mutability is the point of database tables, right? While CTEs (Common Table Expressions) and subqueries can help create intermediate, immutable result sets within queries, the underlying data remains mutable and stateful.
The lack of first-class functions limits compositional capabilities that functional programming relies upon. SQL does not natively support treating functions as values that can be passed as arguments or returned from other functions. This restriction makes it difficult to easily compose functions and apply higher-order functions, which are core tenets of functional programming approaches.

SQL is definitely NOT a functional language.
Idempotence in SQL requires even more deliberate design. The naive approach of simply re-running transformation queries often fails because SQL operations like INSERT, UPDATE, and DELETE are inherently stateful. Running an INSERT statement twice typically creates duplicate records rather than achieving the same end state. Even seemingly safe operations like CREATE TABLE AS SELECT can fail on subsequent runs if the table already exists.
The solution lies in structuring SQL transformations as discrete, self-contained units that explicitly manage their state and dependencies. These Functional and Idempotent chunks—FI chunks—become the fundamental building blocks of FITT-compliant data pipelines implemented in SQL. Making SQL fully functional is an active area of research in databases. Our approach uses the varieties of SQL that come with the top analytics databases today: Redshift, Snowflake, BigQuery, Synapse, etc.
Always Be Able To Do This: Complete Rebuilding Everything From Raw
The foundational pattern for FITT-compliant SQL processing is what we call the “One Big Chunk” approach—a complete rebuilding of all derived data from immutable raw sources in a single, comprehensive pass. This technique ensures complete consistency across the entire data pipeline while maintaining the functional and idempotent properties that make FITT architectures reliable.
The complete rebuild pattern starts from immutable raw data and reconstructs the entire analytical dataset through a carefully orchestrated sequence of transformations. Execution parameterization enables transformation workflows to accept explicit time window parameters that determine which data snapshot to process. You should address your raw data with explicit time-based parameters rather than assuming the current state, ensuring that any transformation can be executed against any historical data snapshot by simply adjusting the time window parameters. If your process has multiple tools, code types, etc., combine all those tools into a single overarching orchestration. And the code of that orchestration should be stored in git for version control. You want to make sure that the orchestration codebase becomes the single source of truth for all the data warehouse operations.
Compute and storage are so cheap that if your data is less than 100 TB, this is the way to go. And savings on errors and development environments more than make up the cost.
Implementation begins by creating an entirely new environment—whether that’s a new database schema, a separate data warehouse instance, isolated table namespaces within an existing system, or zero-copy clones in platforms like Snowflake. This clean environment ensures that the rebuild process won’t interfere with current production data access and provides a safety net if issues arise during processing.
Comprehensive testing occurs at every level of the rebuild process. Raw data validation ensures source quality and completeness. Intermediate transformation tests verify business logic correctness. Final dataset tests confirm that analytical outputs meet business requirements and match expected patterns from previous builds.
The promotion process moves validated results into production through blue-green deployment using atomic operations like IP address flipping that minimize downtime and eliminate inconsistent states. Database systems with robust transaction support can accomplish this through schema swapping or view redefinition. Cloud data warehouses often provide zero-downtime table replacement through metadata operations that instantly redirect queries to new data without copying underlying files.
Finally, try to follow these key rules of thumb:
- Create a repeatable, reliable process for releasing data analytics (new data set, data science models, schema, code, visualizations …) as one orchestratable unit.
- Always be able to rebuild completely from raw.
- Parameterize the whole process – be able to run in a new database, on a different git branch, quickly.
- Build quality in through automated testing at every step of the process.
- Define Done as released to production
- Love your errors and improve continuously
- Maintain ownership of the end-to-end pipeline, encompassing both development and production.
The (Functional Idempotent) FI Chunk Concept: Building Blocks of Functional SQL
A Functional and Idempotent chunk represents a complete unit of data transformation work that can be executed repeatedly with identical results regardless of external state. Each FI chunk follows specific patterns that ensure functional behavior and idempotent execution within SQL environments.
The structure of an FI chunk begins with data quality tests that validate input requirements. Rather than assuming data exists in specific tables or views, each chunk uses data quality tests to verify its input requirements through parameterized queries that can reference different source datasets depending on execution context. This parameterization enables the same transformation logic to run against yesterday’s data for development or today’s data for production.
State management within FI chunks follows a create-new-then-replace pattern rather than in-place modifications. Instead of updating existing tables, each chunk creates entirely new output tables, validates the results comprehensively, and then atomically replaces the previous version. This approach eliminates entire classes of consistency issues that plague traditional ELT pipelines.
Dependency isolation ensures that each FI chunk can execute independently without relying on side effects from other transformations. All required inputs are validated before processing begins. If data quality validation tests aren’t met, the chunk fails fast with clear error messages rather than producing incorrect results based on incomplete data.

A Functional Idempotent ‘Chunk’ — FI Chunk
Consider implementing a customer lifetime value calculation as an FI chunk. The transformation begins by using data quality tests to validate that the required input tables exist and contain expected data ranges. Your code creates new temporary tables with unique names that won’t conflict with concurrent activity elsewhere in your process. Business logic calculations reference only the validated inputs and produce deterministic outputs. Finally, comprehensive data quality tests validate the results before atomically replacing the previous customer lifetime value table with the new version.
When Needed: Partial Update Build With A ‘FI Chunk’
Practical considerations often require more efficient update patterns for large datasets or frequent processing schedules. The update build subtechnique maintains FITT principles while optimizing for performance and resource utilization. And just to emphasize the principle again: in this architecture, we are trying to maximize the efficiency and quality of the data engineer’s work, because data engineering time is so much more expensive than compute costs and storage costs.
This approach starts from a known-good state—typically the most recent successful production dataset—rather than rebuilding everything from raw data. The known-good state is established through backup restoration, zero-copy cloning (Snowflake supports this well), or similar techniques that create a complete copy of production data as the foundation for processing.
One of the most widely adopted patterns for keeping bad data out of production systems is Write-Audit-Publish (WAP). At its core, WAP is a gatekeeping process that ensures data is tested and approved before it’s exposed to downstream consumers. In WAP, new data never flows directly into live production tables. Instead, it follows a deliberate three-step process: Write: Incoming data is first stored in an isolated staging location—often a temporary branch, schema, or table that is entirely separate from production. This prevents incomplete or unverified data from interfering with real workloads. Think of it as a “quarantine zone” for new data. Audit: The staged data is then subjected to thorough inspection. This can include null checks, duplicate detection, referential integrity validation, business rule enforcement, and any other quality controls relevant to your domain. This stage is where data engineers and analysts can identify and fix problems before they propagate further. Publish: Once the data passes all required tests, it’s atomically promoted to production. Downstream consumers see either the complete, validated dataset or nothing at all—eliminating the risk of partial or inconsistent updates. It’s straightforward to implement in many modern data platforms, and it enforces a clear separation between untrusted and trusted data.
But WAP is not inherently functional or idempotent. Re-running a WAP pipeline will not necessarily create the same results. A WAP pipeline may have unwanted side effects on other tables.
We can improve on the WAP pattern with the idea of a ‘FI Chunk.’ Here, processing applies only the changes necessary to bring the dataset current, but does so through the same functional and idempotent patterns used in complete rebuilds. New raw data gets processed through the same transformation logic, intermediate results are validated through tests, and final outputs undergo the same quality checks as complete rebuilds.
The critical insight is that update transformations remain idempotent by making sure that, before the transformations start, a cleanup routine is run. This cleanup routine should delete temporary tables, QC tables, or any SQL components added during the steps ‘FI Chunk’. Whether the update processes one day’s worth of new data or thirty days, the same transformation logic with identical inputs produces identical results.
Do Your Development In ‘FI Chunks’ Iteratively
Complex data transformations rarely emerge fully formed and correct on the first attempt. Real-world analytics require iterative development, debugging, and refinement cycles that can take hours or days to perfect. You don’t want to rebuild everything when you’re working on a small piece of the process. The challenge lies in maintaining FITT principles during this iterative development process while enabling the rapid feedback cycles that developers need to build sophisticated transformations.
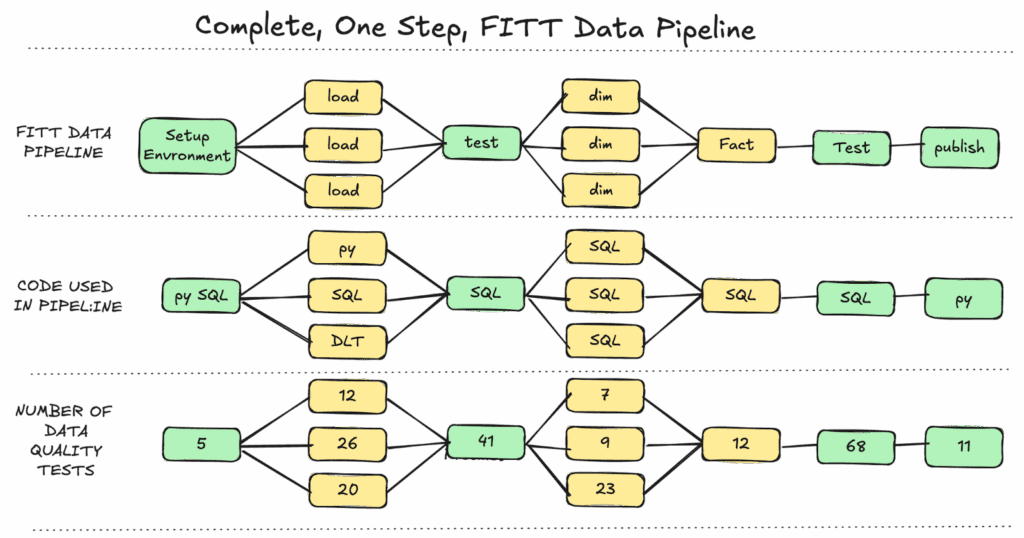
Make sure your FI chunks are small, independently testable components that can be developed and validated in isolation. In the diagram below, we have FI chunks that load a data set, build a dimension table, and the fact table.
The development process begins by establishing a stable starting point through zero-copy cloning, backup restoration, or partial build completion that brings the development environment to a known state. This starting point includes all the upstream dependencies that the FI chunk under development will require, ensuring that development work focuses on the specific transformation logic rather than recreating the entire pipeline.

A DAG of Functional, Idempotent Chunks (FI Chunks)
As usual, each development iteration creates new intermediate tables with timestamped or uniquely identified names to avoid conflicts with concurrent development work. Transformation logic gets applied to these new tables, producing results that can be tested and validated without affecting other development work or production systems. The advantage of intermediate tables over CTEs is that their state is preserved for traceability when you are debugging an error.
Comprehensive testing during development on each FI chunk ensures that each component behaves correctly before integration with larger transformation workflows. Data quality tests validate schema correctness, null handling, and value ranges. Business logic tests confirm that transformations produce expected results for known input scenarios.
The intermediate table management strategy balances development flexibility with resource efficiency. Tables created during development iterations can be deleted immediately after testing to conserve storage, or kept around for debugging and comparison purposes, depending on development needs. The key principle is that these intermediate artifacts are disposable and don’t affect the correctness of the overall transformation process. You need to remember to clean them up at the end of processing and check at the beginning of each chunk that they’re not there from previous failed runs.
When I started my career at NASA, our branch chief was fond of saying, ‘Build a little, test a little, learn a lot.’ I write code, run it, see the test results, and then write more code. You want a unit of development work that allows you to write a little code, process some with real data, run some tests, then do it over and over again.
Some Specific SQL Techniques for Maintaining FITT Principles
Implementing FITT principles in SQL requires specific techniques that work within the constraints of relational database systems while maintaining functional and idempotent behavior.
Eliminating Slowly Changing Dimensions
Traditional data warehouse approaches often rely on Slowly Changing Dimensions (SCD) patterns to track changes in dimensional attributes over time. However, SCD implementations introduce complexity and state dependencies that conflict with FITT principles of functional and idempotent processing.
The FITT alternative replaces SCD patterns with multiple-dimensional tables that capture all relevant attributes at each point in time without complex versioning schemes. Instead of maintaining separate current and historical records with effective date ranges, each analytical query joins against dimensional data that’s appropriate for the specific analysis time frame.
Analytical queries explicitly specify the temporal context for dimensional lookups rather than relying on complex SCD logic to determine appropriate values. You can create multiple similar dimension tables for different periods, and have the analyst pick the right one for their specific context. A customer analysis for Q3 2023 joins against customer dimensional data from that period. Year-over-year comparisons explicitly join against dimensional data from both comparison periods to ensure consistent attribute definitions.
This approach eliminates the complex ETL logic required to maintain SCD relationships while providing more transparent and predictable analytical results. Query authors understand exactly which dimensional attributes they’re using because the temporal context is explicit rather than hidden behind SCD implementation details. The elimination of complex SCD joins often improves query performance. It also makes it much easier to understand and maintain dimensional models.
Parameterization and Templates
Modern SQL development requires sophisticated parameterization and templating capabilities that enable the same transformation logic to execute against different datasets, periods, and environments. Tools like DataKitchen’s DataOps Automation Product, dbt with Jinja templating, or custom SQL generation frameworks like GCP’s dataform provide the flexibility needed to implement FITT principles effectively.
Template-driven SQL development treats transformation logic as parameterizable functions rather than static queries tied to specific table names or date ranges. Business logic gets encoded in SQL templates that accept parameters for source table references, processing date ranges, output destinations, and configuration values that affect transformation behavior.
Environment parameterization enables identical transformation logic to execute against development, staging, and production datasets by simply changing table prefixes, schema names, or database connections. The same template that processes yesterday’s data in development can process today’s data in production without any logic changes—only parameter values differ between environments.

Be able to produce many variations with simple parameter changes.
‘Time machine’ parameterization supports the capability that’s crucial for FITT architectures. Analytical queries can be executed against any historical date by adjusting date range parameters and source table references. This capability proves essential for debugging data quality issues, reproducing historical results, and validating changes against known-good outputs.
Configuration management through parameterization enables fine-grained control over transformation behavior without modifying underlying SQL logic. Business rules, data quality thresholds, aggregation levels, and processing options can all be controlled through parameter files that are maintained separately from transformation code. This separation enables business users to adjust analytical behavior without requiring deep SQL expertise.
Version control integration (git) treats SQL templates, Python code, orchestration configuration, and their associated parameter files as code artifacts. Changes to transformation logic or configuration parameters go through code review processes, automated testing validation, and controlled deployment procedures that ensure quality and maintain audit trails.
Complete Coverage Data Quality Testing
Comprehensive testing forms the cornerstone of FITT data architectures, but testing SQL-based transformations requires specialized approaches that account for the unique characteristics of data processing workflows. Unlike traditional software testing that focuses on discrete functions with limited inputs, data pipeline testing must validate complex transformations against large, evolving datasets while ensuring performance and scalability.
Inline testing integrates data validation directly into the transformation workflow rather than treating testing as a separate downstream activity. This approach catches data quality issues immediately when they occur rather than allowing problems to propagate through multiple processing stages before detection.
Implementation embeds test logic directly within SQL transformations through validation queries that execute as part of the main processing flow. These inline tests validate assumptions about input data quality, verify intermediate calculation results, and confirm that output datasets meet expected criteria before downstream processing begins.
The fail-fast principle ensures that inline tests halt processing immediately when validation failures occur rather than continuing with potentially corrupted data. Early failure detection minimizes wasted computational resources and prevents insufficient data from propagating to downstream systems, where correction becomes more expensive and disruptive.
Every table needs tests, as does every column. Creating the appropriate tests for each ensures full test coverage that validates data processing correctness and builds confidence in transformation results. Read more about achieving test coverage in data analytics systems.
Script-Driven, Stateless Environment Creation
None of this is enough if you’re hobbled by manual environment setup processes. Manual procedures create bottlenecks, introduce inconsistencies, and prevent the rapid iteration cycles that effective data development requires. Newer, script-driven environment creation automates the entire process of establishing new development, testing, or production environments through repeatable, version-controlled procedures.
Infrastructure-as-Code methods handle environment definitions as software artifacts that undergo the same development, testing, and deployment processes as transformation logic. Database schemas, table definitions, view specifications, and configuration parameters are all defined through declarative scripts that can be executed reliably across different target environments.
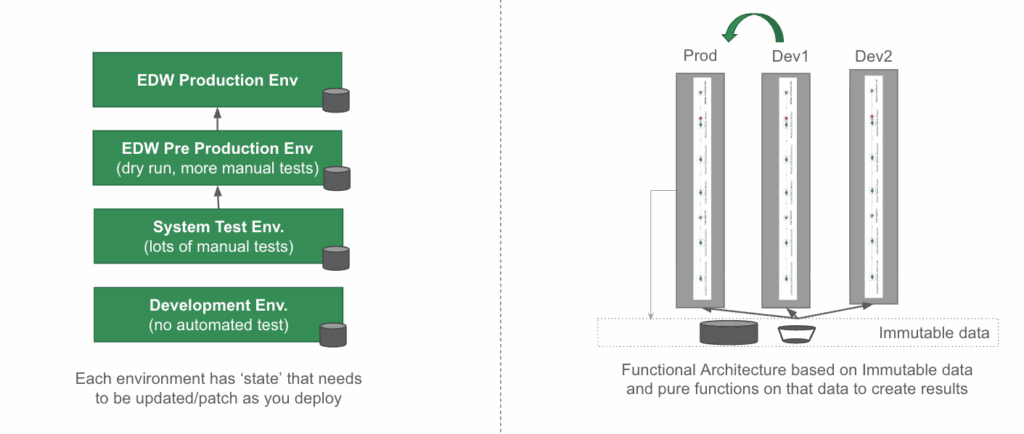
Stateful vs FITT environments during deployment
Parameterized deployment scripts enable the exact environment definition to create development environments with subsets of production data, staging environments that mirror production scale, or additional production environments that support parallel processing workflows. Parameter files specify environment-specific values like database connection strings, table prefixes, resource allocation limits, and data retention policies.
Benefits of FITT Techniques
Implementing FITT principles through disciplined SQL and ELT isn’t just academic theory – it actually makes your day-to-day work as a data engineer way better. Here’s why it’s worth the extra effort upfront.
Faster Development Iterations
You know that painful cycle where you make a change, wait forever for the whole pipeline to run, find something broken downstream, and have to start all over again? FITT basically kills that workflow. With FI chunk development, you can test and validate specific pieces in isolation.
You set up a known-good starting point (through environment cloning or just running part of your build), then iterate on your specific logic without rebuilding everything from scratch. Instead of waiting hours to see if your change worked, you get feedback in minutes. It’s the difference between actually being productive and spending your day waiting for builds.
Multiple people can work on different parts of the same complex transformation without stepping on each other’s toes. Clean interfaces between components mean you can develop in parallel and integrate without the usual drama.
Trusted Results
Here’s the thing – FITT architectures just eliminate whole categories of data quality nightmares. When your transformations are functional and idempotent, they give you the same results for the same inputs every single time. Debugging becomes so much easier when you’re not chasing down weird state issues.
You get complete audit trails through version control and parameterized execution, as well as data quality test coverage. So when someone asks, “How did we get this number?” you can actually show them exactly which data, logic, test results, and parameters were used. No more hand-waving. One of our customers was fond of saying to his doubting business analysts, “We have 5,000 tests running on the data, and all of them passed. Are you sure it’s a data error?”
And here’s a bonus – you don’t need separate unit tests with fake data anymore. Each FI chunk IS your testable unit.
Reproducibility isn’t something you have to bolt on later – it’s built right in. Do you need to recreate an analysis for compliance or debugging? Done. No more “mystery results” that nobody can explain.
Environment Parity
FITT techniques basically make dev, staging, and prod behave the same way. Same transformation logic, same results, regardless of where you’re running it. This eliminates those “works on my machine” situations that make deployments scary.
When your tests pass in dev, you can actually trust that prod will work too. No more crossing your fingers during deployments or dealing with environment-specific bugs that only show up at 2 AM.
You can even do fancy stuff like blue-green deployments and canary releases without breaking into a cold sweat. This really matters when you have an analyst waiting for a new data set, and you can give them a preview of the entire data set with their new data in parallel to the normal production release. You can get their feedback, test, and learn more about their needs.
Operational Flexibility
Once you have FITT working, you can do things that would be way too risky with traditional systems. Want to A/B test some transformation logic? Run multiple versions of production side-by-side. Need to gradually migrate to new business rules? No problem.
Since spinning up new environments isn’t expensive or scary anymore, you can run long-term parallel analyses to test different approaches or see what impact proposed changes might have – all without touching production.
And when something does break? Just fix the code and re-run it. No more trying to figure out how to repair a corrupted state or untangle some mess. Recovery becomes simple.
Simplicity and Development Ease
Here’s the thing that really matters – FITT techniques make developers feel safe to experiment, which leads to way better work and happier teams. When you’re not constantly worried about breaking production, you actually innovate more and enjoy your job. Breaking things down into small FI chunks means even junior developers can jump in and contribute to big projects without getting overwhelmed, since the boundaries are clear and the testing catches mistakes early.
New team members get up to speed much faster when systems behave predictably and are well-tested. This frees up senior developers to work on the interesting stuff – architecture and business logic – instead of spending their days debugging weird data issues or wrestling with complicated deployments. Everyone wins with higher job satisfaction and better productivity.
Conclusion
All of this together transforms data engineering from a high-stress, “hero saves the day” kind of job into something systematic and predictable that actually scales as your team and business grow. FITT SQL techniques give you a foundation for sustainable data engineering that supports long-term business success while helping technical teams maintain some semblance of work-life balance.
Moving from traditional data engineering to FITT-compliant SQL and ELT takes time, but it’s worth it. FITT isn’t just a technical architecture – it’s a sustainable way to do data engineering that grows with your business without drowning you in operational complexity.
Your Data Architecture Is Broken (Until You Make It FITT).








