
The DataKitchen DataOps Platform makes it easy for you to integrate any tool into your DataOps pipeline. A prospective customer recently asked if DataKitchen could orchestrate a tool we hadn’t encountered before – Qubole to be exact. Our response to a question like this is always the same. If a tool has an API or SDK, then DataKitchen can orchestrate it. Why? Because the platform uses containerization to facilitate a tool-agnostic architecture. If you can install a package or call an API to interact with your tool from within a Docker container, then DataKitchen can orchestrate your tool in our platform.
How It Works
In this specific use case, a customer was transferring data from Qubole to Snowflake for analysis. Therefore, they wanted a way to easily transfer their data from S3 into Snowflake and perform data integrity checks to ensure the transfer was successful. This use case was ideally suited for the DataKitchen Platform, which, among other things, serves as a unifying foundation for multi-tool, multi-language interoperability.
The DataKitchen Platform provides a general-purpose docker container node that makes it exceptionally easy to install dependencies and run scripts to perform analytics in the tool of your choice (in this case, the Qubole Data Service API python library). Similarly, our easy-to-use native testing infrastructure requires minimal effort to configure and add tests. This is especially helpful when testing spans multiple tools domains.
We implemented a pipeline (set of steps) consisting of two nodes in the graph shown below.

Figure 1: Example of a simple pipeline to transfer data from Qubole to Snowflake.
Step 1: Perform SQL metadata queries using Qubole
The Metadata_Queries node performs a set of Presto SQL queries on data in S3 using Qubole . These queries collect metadata for use in performing data parity checks (e.g. table row counts) on the data being transferred. Configuring the docker container node is as simple as specifying your DockerHub credentials and image details as shown below.
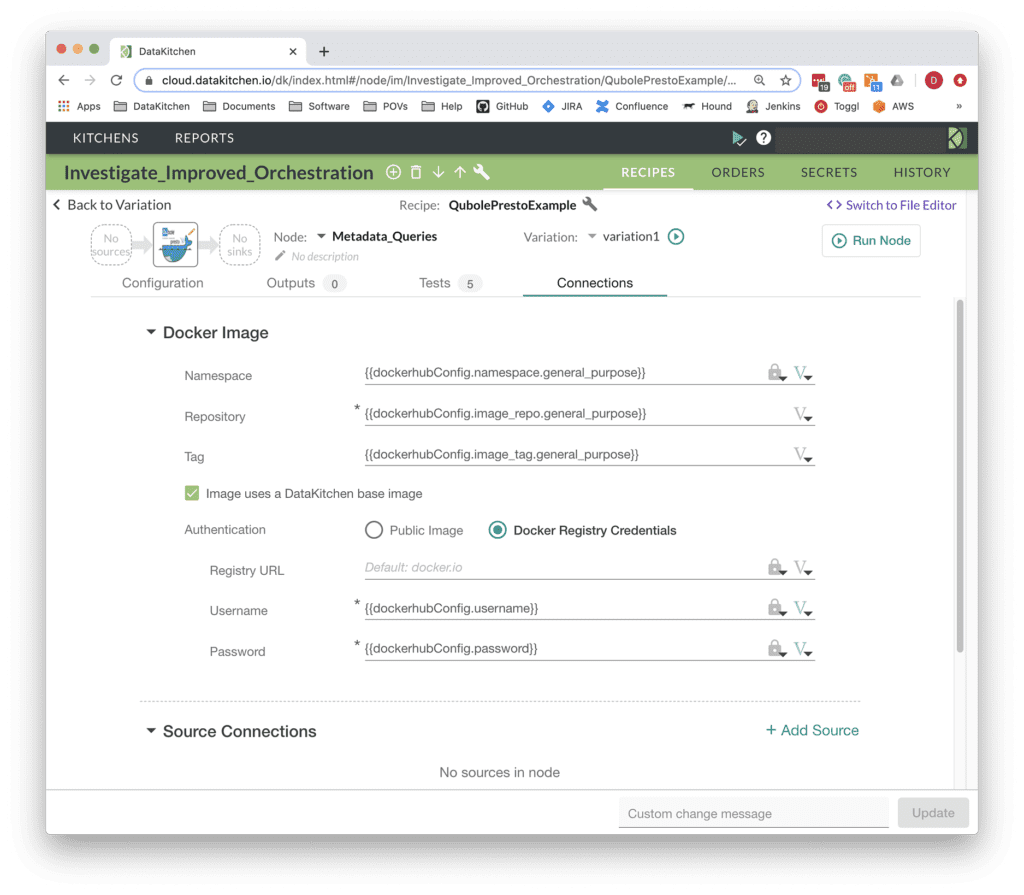
Figure 2: Using the DataKitchen UI, it’s simple to configure a Docker container to run Presto SQL queries using the Qubole Data Service Python SDK
Similarly, it’s simple and straightforward to add the required Qubole SDK dependency to the container, along with a python script (run_presto_sql.py) to connect to Qubole and perform queries. The DataKitchen platform also makes it easy to maintain security. A Vault is used to store and pass secrets such that they never appear in plain text – secrets are only resolved at runtime in a secure fashion.
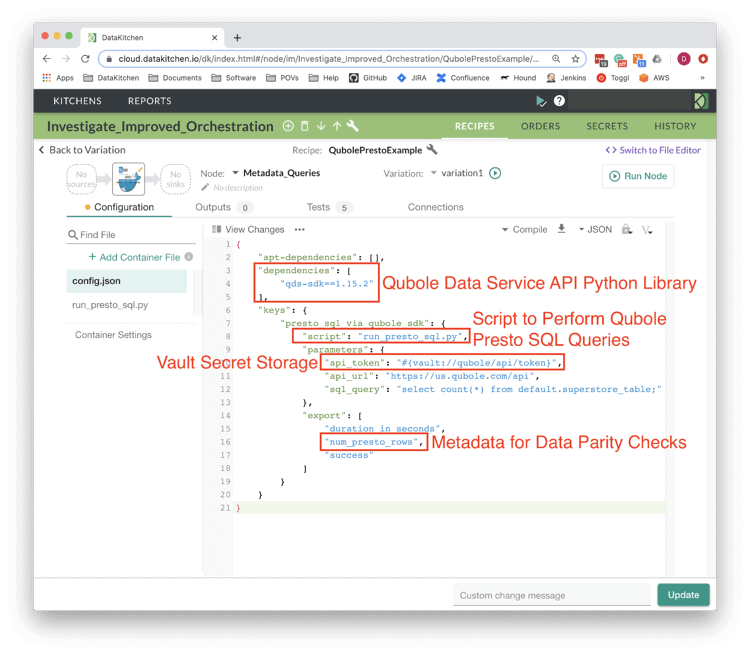
Figure 3: The DataKitchen Platform uses a JSON file to configure the container node: define the Qubole python library dependency, a python script to run, a secure Vault and a variable “num_presto_rows” which, among others, will be exported to a downstream node and compared with another value.
Step 2: Ingest Data Into SnowFlake and Ensure Data Parity
The “Ingest_and_Test” node ingests data from S3 into Snowflake tables and performs similar queries to collect metadata on the transferred data. Finally, tests were added to perform the data parity checks by testing for equality between the collected Qubole and Snowflake metadata. The “Ingest_and_Test” node is a native connector provided by the DataKitchen platform. To use this Snowflake connector, simply define the Connection Details and a list of steps (SQL queries) to be performed.
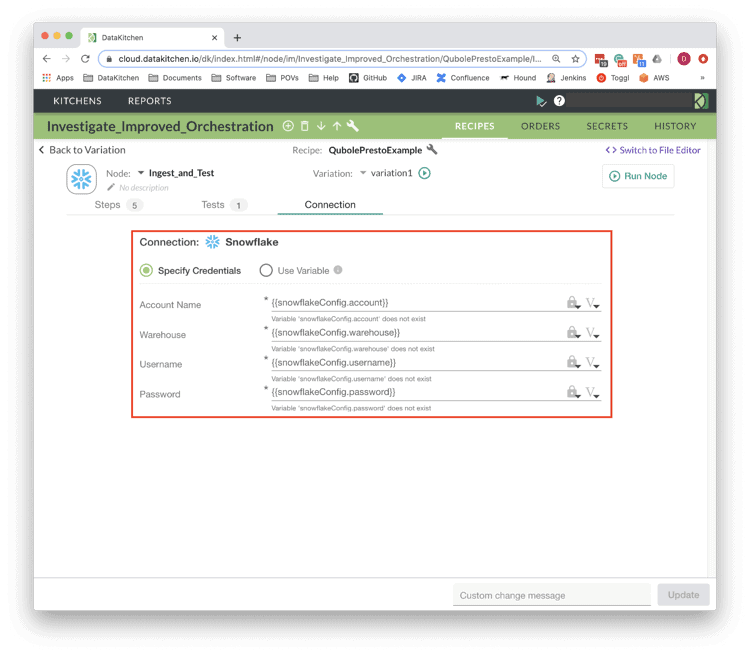
Figure 4: Configuring a Snowflake connection is simple via the DataKitchen UI.

Figure 5: The “Ingest_and_Test” Snowflake node consists of five sequential steps. The SQL query for the “populate_table” step is shown.
Additionally, the DataKitchen platform provides a simple and intuitive user interface for adding tests. As shown below, a simple row count test was added to check data parity between the original data on Qubole to the data transferred to Snowflake.

Figure 6: The DataKitchen UI shows a defined test which compares the row counts calculated from Qubole (Presto SQL) and Snowflake. This test ensures that the number of data rows output from Qubole is the same number as received into Snowflake.
The DataKitchen Platform makes it easy to share this pipeline within a list of reusable microservices. If the pipeline is ever incorporated into production analytics, the metadata comparison will catch any issue in the transfer of data from Qubole to Snowflake.
The big question is, how difficult was this to achieve and how long did it take? Not long at all, thanks to the flexibility of the DataKitchen Platform and its toolchain-agnostic approach to DataOps. The pattern above is not an uncommon one. For instance, many customers want to migrate their data into the cloud (not only is the platform tool agnostic, but it’s also cloud agnostic). Due to our agnostic approach to tools and infrastructure, our DataKitchen Platform makes this process a breeze.
To learn more about how orchestration enables DataOps, please visit our blog, DataOps is Not Just a DAG for Data.





