Data teams using inefficient, manual processes often find themselves working frantically to keep up with the endless stream of analytics updates and the exponential growth of data. If the organization also expects busy data scientists and analysts to implement data governance, the work may be treated as an afterthought, if not forgotten altogether. Enterprises using manual procedures need to carefully rethink their approach to governance.
With DataOps automation, governance can execute continuously as part of development and operations workflows. Governance automation is called DataGovOps, and it is a part of the DataOps movement.
DataGovOps in Data Governance
Governance is, first and foremost, concerned with policies and compliance. Some governance initiatives focus on enforcement – somewhat akin to policing traffic by handing out speeding tickets. Focusing on violations positions governance in conflict with analytics development productivity. Data governance advocates can get much farther with positive incentives and enablement rather than punishments.
DataGovOps looks to turn all of the inefficient, time-consuming and error-prone manual processes associated with governance into code or scripts. DataGovOps reimagines governance workflows as repeatable, verifiable automated orchestrations. DataGovOps strengthens the pillars of governance through governance-as-code, automation, and on-demand enablement in the following ways:
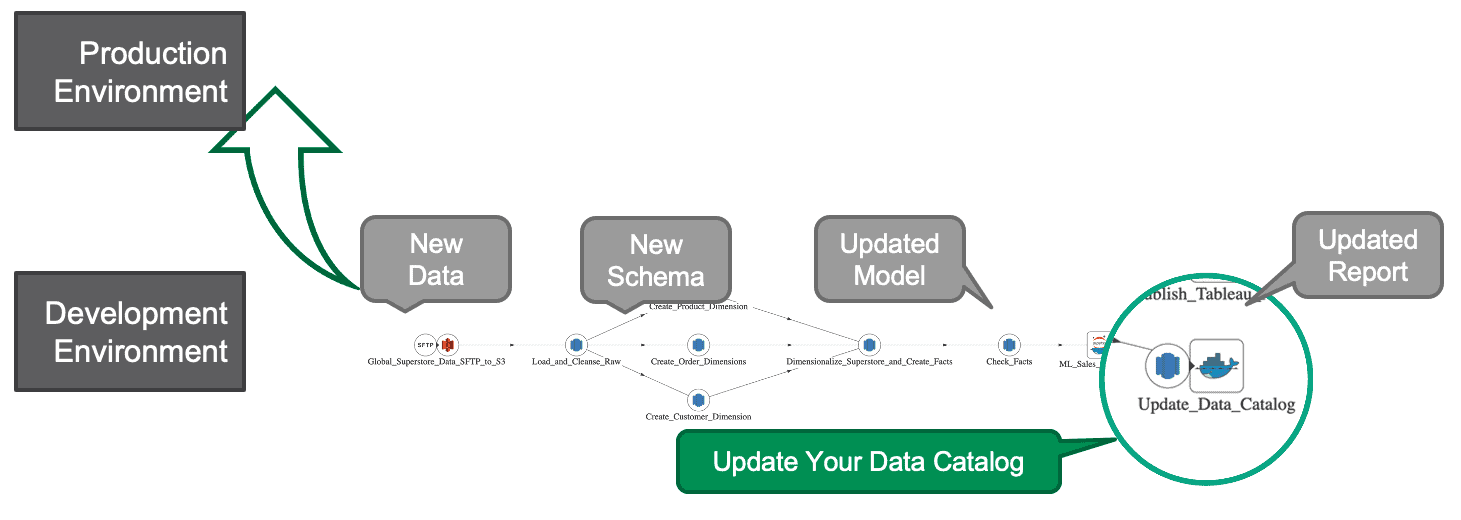
- Business Glossary/Data Catalog – The automated orchestrations that implement continuous deployment include DataGovOps governance updates (e.g., to glossaries/catalogs) into the change management process. All changes deploy together. Nothing is forgotten or heaped upon an already-busy data analyst as extra work. (See Figure 1)
Figure 1: The orchestrations that implement continuous deployment incorporate DataGovOps updates into the change management process.
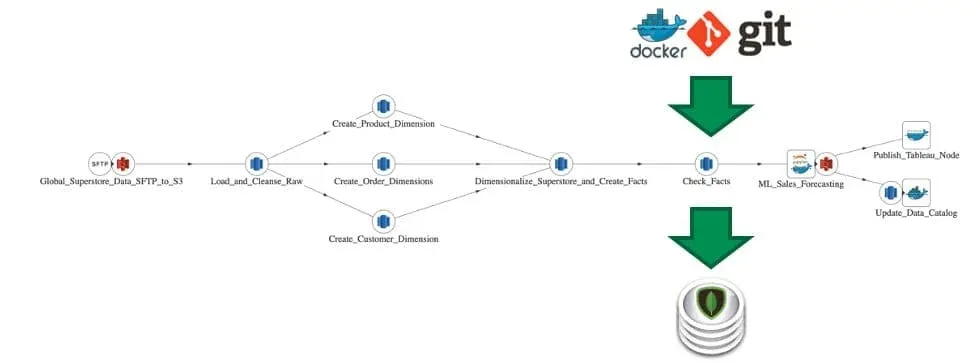
- Process Lineage – DataGovOps automation records and organizes all of the metadata related to data – including the code that acts on data. Test results, timing data, data quality assessments and all other artifacts generated by execution of the data pipelinedocument the lineage of data. All metadata is stored in version control so that you have as complete a picture of your data journey as possible. (See Figure 2)
Figure 2: All artifacts that relate to data pipelines are stored in version control so that you have as complete a picture of your data journey as possible.
- Automated Data Testing – A labor-intensive assessment of data quality can only be performed periodically, so at best it provides a snapshot of quality at a particular time. DataGovOps takes a more dynamic and comprehensive view of quality. DataGovOps performs statistical process control, location balance, historical balance, business logic and other tests as part of the automated data-analytics pipelines, so your data lineage is packed with artifacts that document the data lifecycle.
- Self-Service Sandboxes – A self-service sandbox is an environment that includes everything a data analyst or data scientist needs in order to create analytics. If manual governance is like handing out speeding tickets, then self-service sandboxes are like purpose-built race tracks. The track enforces where you can go and what you can do, and are built specifically to enable you to go really fast. Self-service environments are created on-demand with built-in background processes that monitor governance. If a user violates policies by adding a table to a database or exporting sensitive data from the sandbox environment, an automated alert can be forwarded to the appropriate data governance team member. The code and logs associated with development are stored in source control, providing a thorough audit trail.
Conclusion
The concept of governance as a policing function that restricts development activity is out-moded and places governance at odds with freedom and innovation. DataGovOps provides a better approach that actively promotes safe use of data with automation that improves governance while freeing data analysts and scientists from manual tasks. DataGovOps is a prime example of how DataOps can optimize the execution of workflows without burdening the team. DataGovOps transforms governance into a robust, repeatable process that executes alongside development and data operations.