
Chris Bergh, CEO of DataKitchen, delivered a webinar on two themes – Data Products and Data Mesh. Bergh started by discussing the complexity within data and analytics teams, stating that complexity makes everything more complicated and, in the long run, it kills productivity. Examples of complexity within data and analytics teams include multiple teams with different roles, thousands of different data sets of different types and shapes, each with unique needs, and interconnected project plans.

Bergh went on to talk about how the software industry has tackled complexity by applying lean and agile principles such as DevOps and domain-driven design software products. The data industry is now adopting similar principles, such as data testing instead of test-driven development, data observability instead of observability, and functional data engineering instead of functional programming.
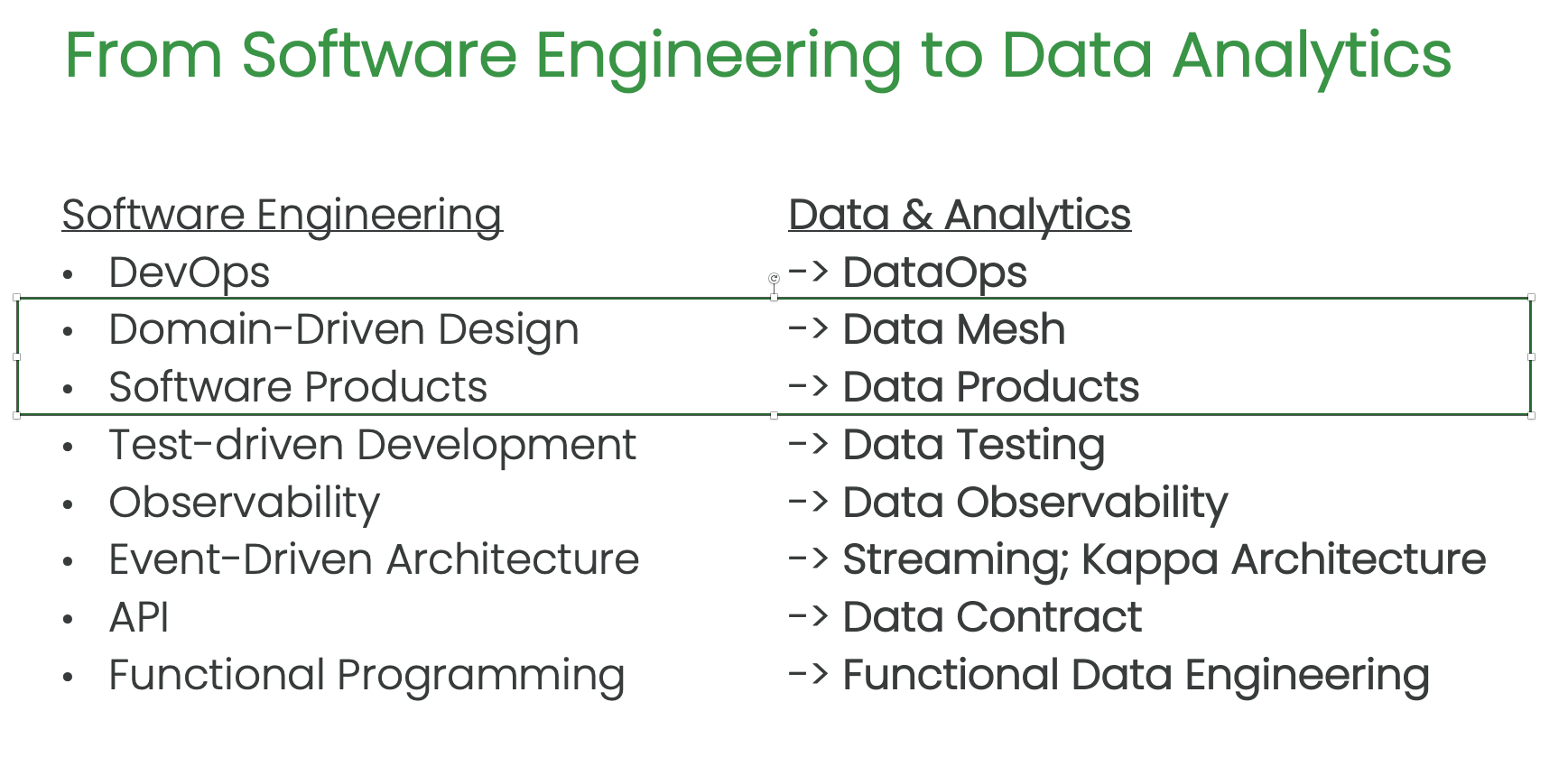
Data Mesh
Bergh explained that the Data Mesh organizes a team’s work into chunks called decentralized domains. Instead of boiling the ocean and focusing on all datasets and customers, the Data Mesh focuses on fewer datasets and customers, which reduces complexity and helps get more done.
On the other hand, Data Products are part of an ever-improving flow of value, where success is not defined by completing tasks on a project plan but by delivering insights to customers. Bergh explained that Data Products are about the flow of value to customers, repeatedly and improving the tools, data, and code that make up the product.
Bergh emphasized that Data Products and Data Mesh are not mutually exclusive, and both should be used together to help reduce complexity, increase productivity, and deliver value to customers.
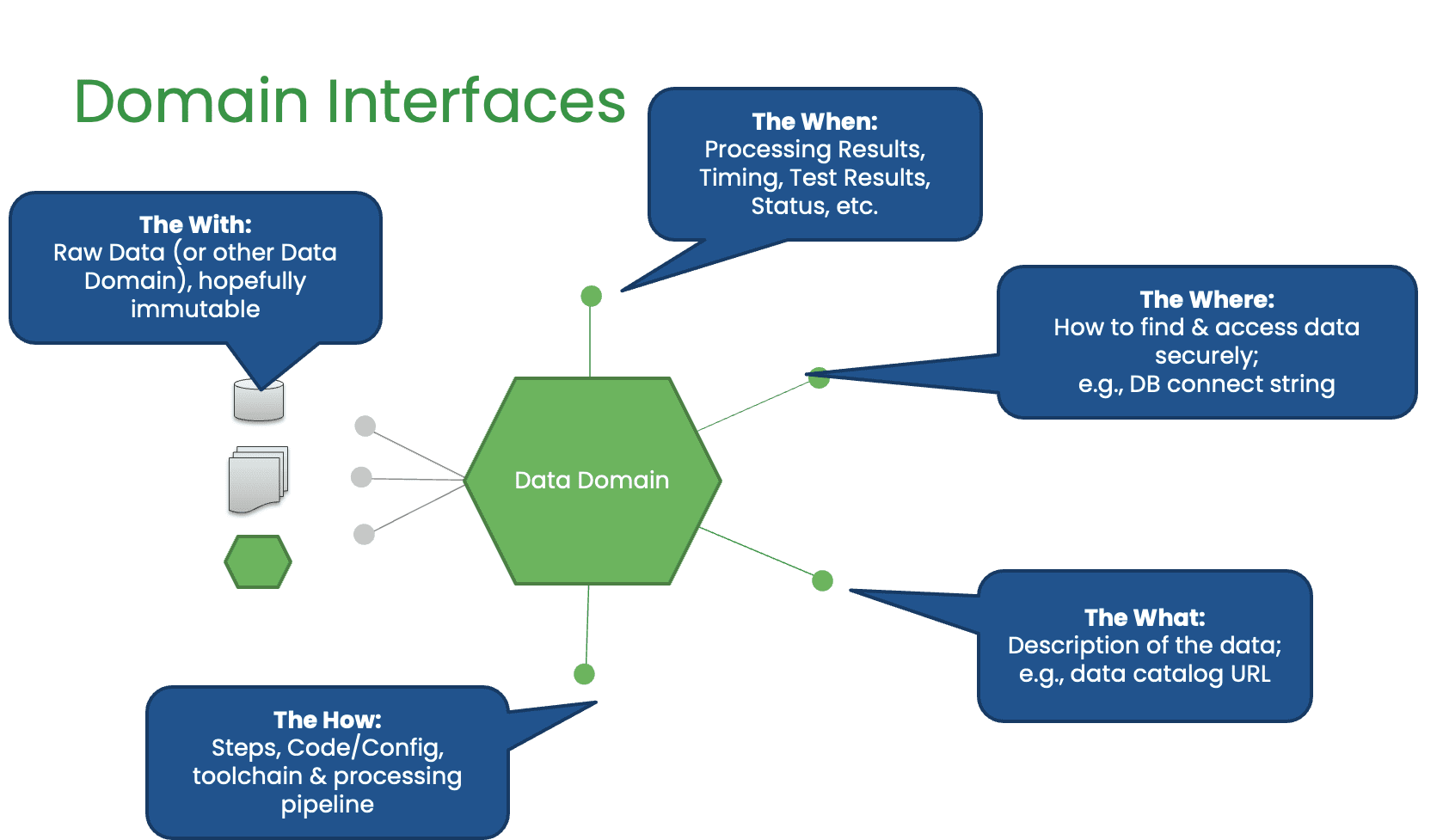
Chris talks about the idea of a ‘domain’ as a principle of Data Mesh. A domain is a unit that includes integrated or raw data, artifacts created from data, the code that acts upon the data, the team responsible for the data, and metadata such as data catalog, lineage, and processing history. The goal of a domain is to deliver value to the customer, which may be another team or a business user. The speaker emphasizes the importance of independence, trust, usability, discoverability, security, and interoperability in a domain. They suggest that a domain architecture can clarify responsibilities and improve customer intimacy. They describe five interfaces to a domain: the width (data), the where (location), the what (description), the how (process), and the who (team).
He also highlights the composability of domains, meaning that the work in one domain can be the input of another domain. This allows teams to control their own world but also utilize other people’s work. Chris argued that focusing on services provided to the customer rather than the project plan can improve productivity and value delivery. This approach requires observability to ensure that the domains work well together. Chris discussed the idea of decentralization and how well-designed domain interfaces can provide the freedom to innovate in data engineering. He argued that having central control over data can result in high context-switching costs and hinder innovation.
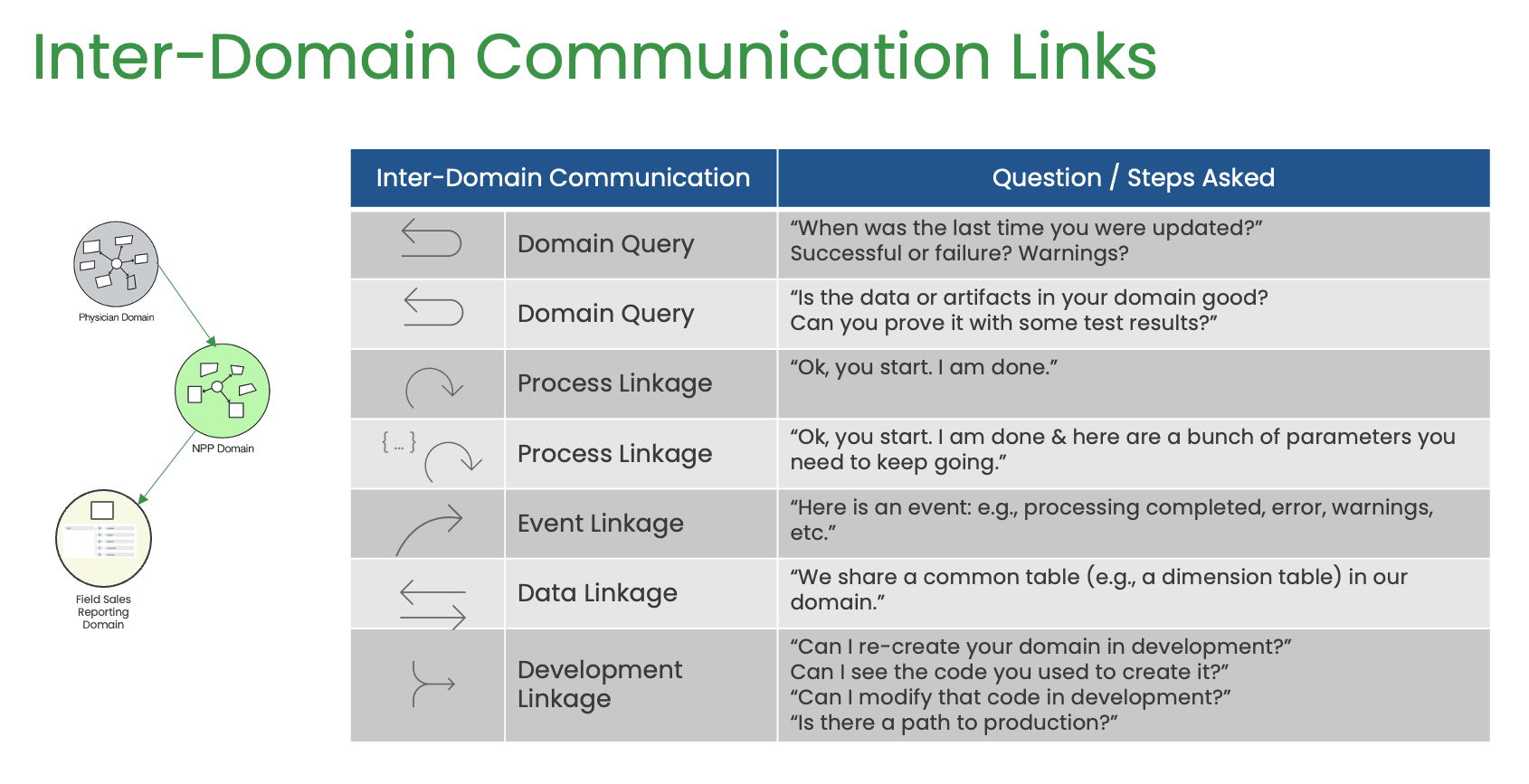
A Data Mesh Example
To illustrate this point, Bergh gave an example of using a Data Mesh in commercial pharma analytics. He explained how different parts of the pharma product lifecycle grow at different times, creating a combination of data and use cases reflected in the teams working on them. The data sets used to understand the launch of a product come from various sources; some are purchased through syndication, some are internal, and some are freely available. Bergh described how the purchase and integration of these data sets could be complicated as they do not come at the same time, have different frequencies, and have different characteristics.
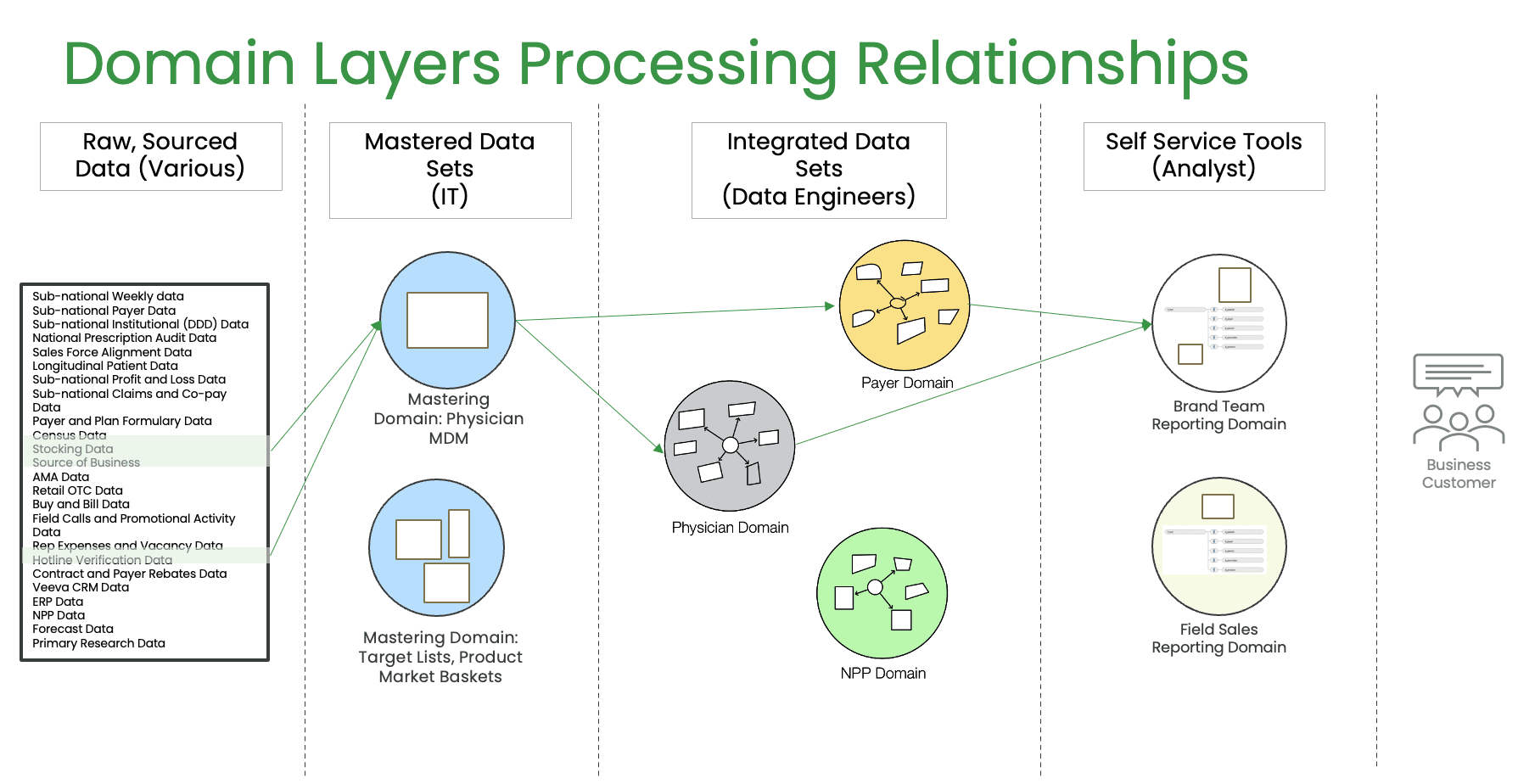
To address this, Bergh suggested using mastered data sets, small files that are in and of themselves a thing. There are also integrated data sets, raw data that comes in, and in some cases, facts or dimensions. Domains, such as a payer domain, a physician domain, and an NPP or non-personal promotion domain, separate these data sets. Finally, Bergh explained that analysts use the data, and they may have a self-service layer where they can access the data they need to analyze. Overall, Bergh’s talk emphasized the importance of decentralization in data engineering and the benefits of well-designed domain interfaces that provide the freedom to innovate.
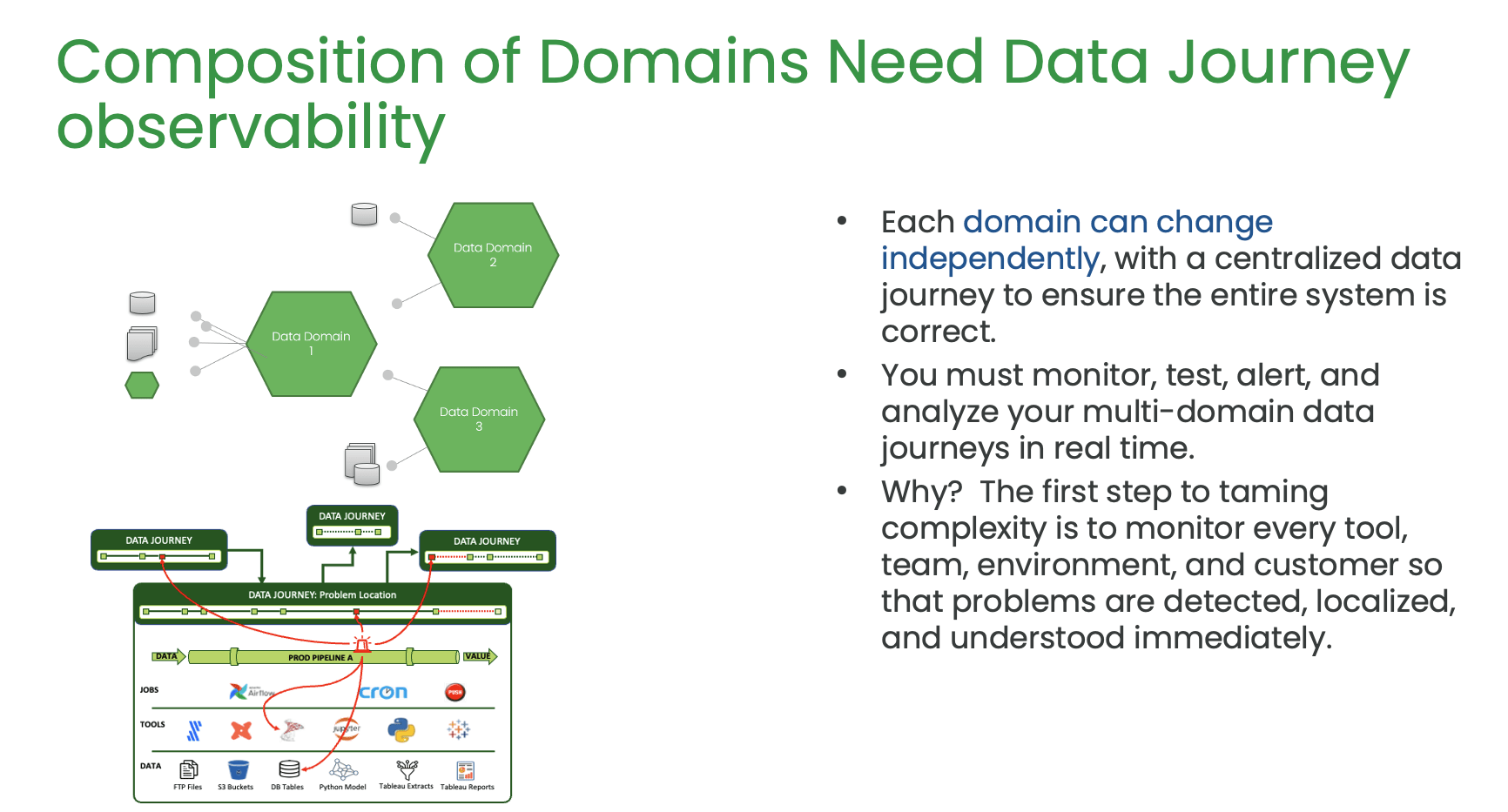
Data Products
Chris discussed the concept of transitioning from a project to a product-focused approach in data analytics and engineering. Bergh emphasizes that the traditional approach to measuring success in data engineering teams is task completion, where teams focus on finishing complicated project plans. However, this approach does not necessarily provide value to customers, as success should be measured by the usefulness of the data product being built.
Bergh suggests that instead of focusing on project plans, data engineers should concentrate on the flow of change to the customer. In contrast to a project-based approach, a product-focused approach is a continuous stream of value to the customer. Iterative development, focus on the flow of value to the customers, and small features delivered quickly to get feedback from the business are crucial components of the product methodology.
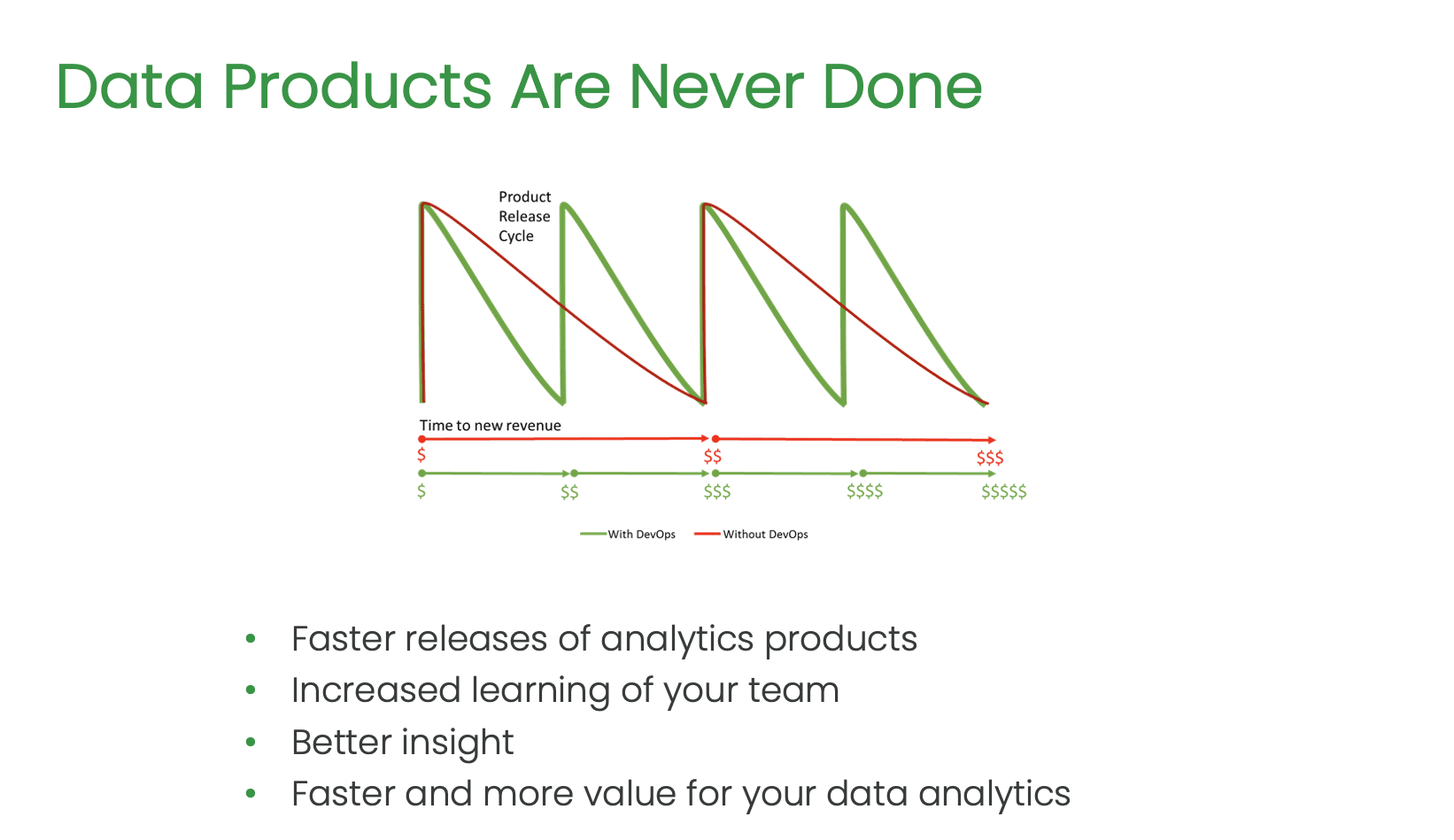
The speaker contrasts the fungibility of employees in a project-based approach with a more product-focused approach, where work is brought to people who know the product and customer. Small, cross-functional teams working on a product can learn and innovate more effectively than people working on individual tasks across different projects.
Bergh argues that data projects often involve a lot of waste in terms of waiting or context switching between different roles or projects. The traditional waterfall process, with its wait times between design, defining, development, QA, and release, causes significant delays in delivering the product to the customer. In contrast, the product-oriented approach minimizes the waiting time by having a more frequent checkpoint system and reallocating funding from project to product.
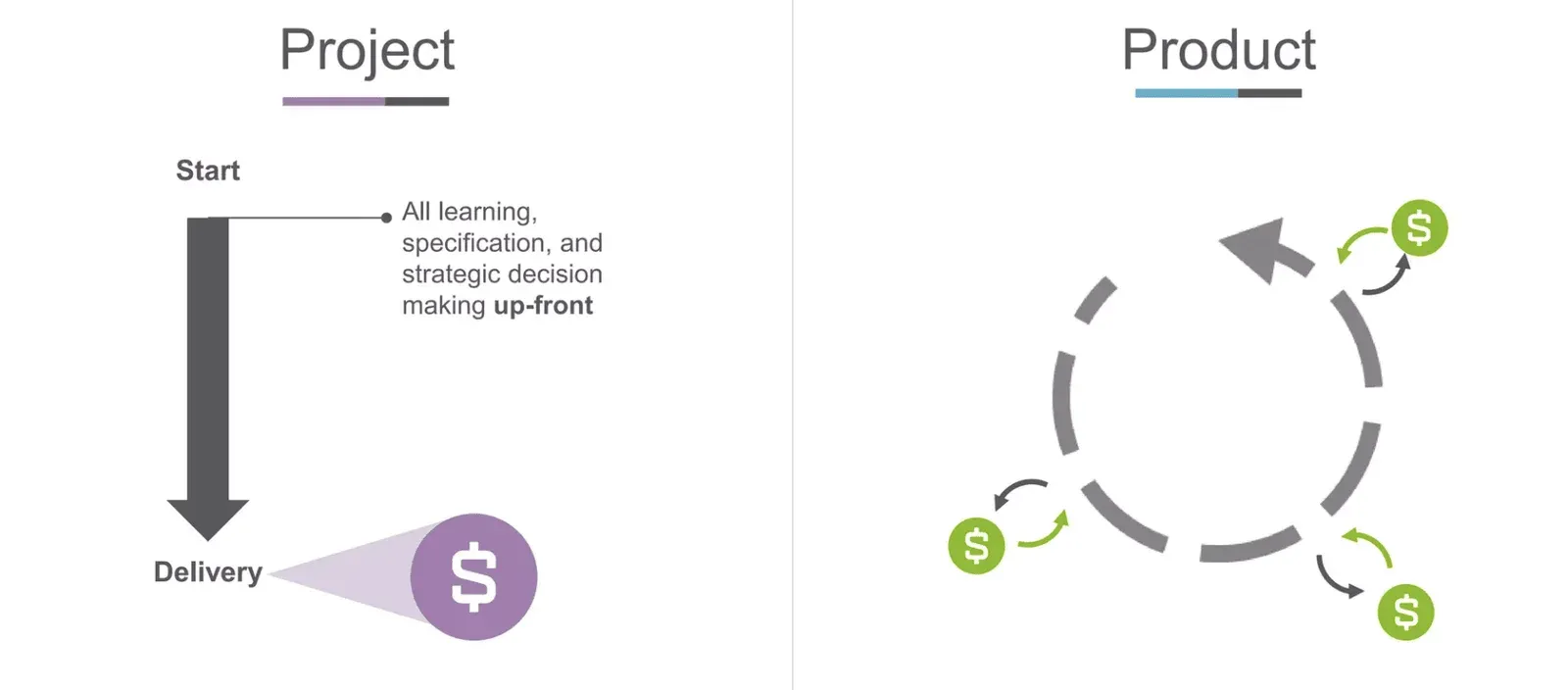
Bergh suggests that a product-based approach to data engineering is more customer-centric than a project-based approach. Success is measured by completing tasks on time and on budget and by how much value the customer has received from the product. The success of a data product is measured by whether the customer is happy with it, whether it has provided an ROI, and whether it has fulfilled its intended purpose.
Overall, Bergh’s talk encourages data engineering teams to focus on creating Data Products that provide ongoing value to the customer rather than merely completing tasks in a project plan. The product-oriented approach emphasizes customer-centricity, iterative development, and cross-functional teams that are continually learning and innovating.



