
At DataKitchen, we are believers in delivering value. We work with our customers to find a first project that can drive real benefits and meet their critical business needs. Customers use our DataKitchen technology and their experience to address a focused business problem.
Recently we’ve been working with customers in various industries: transportation, telecommunication, and consumer goods to jump-start their DataOps journey. Their business users often have no concept of what it takes to design and deploy robust data analytics. The gap between expectations and execution is one of the main obstacles keeping these analytics teams from succeeding. Managers may ask for a simple change to a report or model or a new dataset. They don’t expect it to take weeks or months.
These teams are trying to answer two simple questions. First, how can their team collaborate to reduce the cycle time to create and deploy new data analytics (data, models, transformation, visualizations, etc.) without introducing errors? And second, where to start this process? We’ve written about how to apply the ‘Theory of Constraints’ to choosing your first DataOps win. The answer relates to finding and eliminating the bottlenecks that slow down analytics development.
What follows are examples of different types of bottlenecks, why they were selected first, and the benefits of resolving those bottlenecks with DataKitchen.
Enabling Rapid Deployment to Production: From Months to Days
A telecom company needs to increase the rate at which new data features are delivered into production in the EDW. In one past example, it took four months to complete the development cycle from new ideas into production (i.e., to move code from development to production).
We worked to identify outcomes that will define success. Those include:
- Automate the manual tests, which alone will bring about major improvements in cycle time.
- Add new activities into the integration and test environment that will dramatically decrease the time it takes to find and fix issues, thus speeding features into production.
- Rapid addition of features and deployment into production in order to reduce the time from months to days (or faster).
Part of their challenge is that their current process involves a four-stage manual deployment from development to production (see below). This manual process introduces complexity, slowness, and errors (see diagram below).
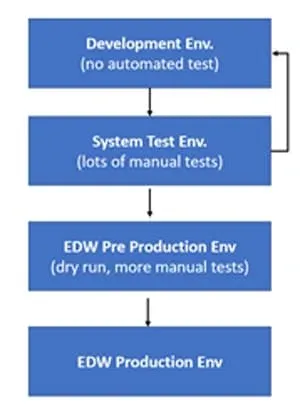
This customer has many tools, including Data Science, visualization and governance tools, in their analytics toolchain. They chose to focus on changes to their core data warehouse as the first bottleneck to address with DataOps. Their other teams have similar challenges, but a focused adoption by the data warehouse team was the biggest bottleneck that offered a significant short-term business benefit if addressed.
So how to do you make sure that when you move something from a Dev Environment through each of the other separate environments, when the business needs it, that everything still works? The answer is automated testing. This company, like many today had very little automated testing in place. Almost all testing to prove that new code works (in this case they are using SQL-based data transformation on Oracle DB) was done by hand. The DataKitchen Recipe below describes how they created dozens of automated tests in the DataKitchen platform that prove that everything works as they moved the new SQL code from one environment to another.
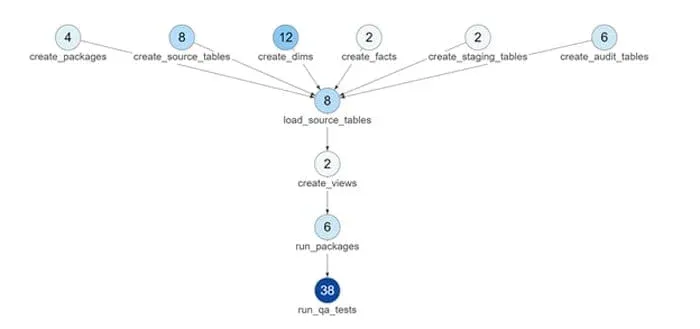
In some ways, the bottleneck is not just technical in nature. Quickly moving code from development into production can be scary – with sometimes painful and costly business implications. What if we make a mistake? Will we get yelled at by the business? Will the business make a critical (and wrong!) decision based on erroneous data? Ensuring new feature deployment success requires both a platform like DataKitchen and an effective approach to writing tests. As part of working with the customer we spend time educating them on how to write great tests as well as the core principles of DataOps.

Reducing Errors in A Multi-Technology Toolchain through Improved Orchestration and Collaboration
A transportation company has challenges, both real-time and in batch, managing the workflow orchestration of data streaming from their vehicles into actionable insight for their employees. Like many companies, they do not have just one data architecture, they have several – batch, streaming, big data, small data, on-premises, cloud, and prescriptive and predictive models – all working together. Plus, they have different teams managing the creation and the operation of these pipelines in different locations. Whew! What that means is that the disparate teams need to develop a common outcome (report, dashboard, model, etc.) together by addressing these business challenges:
- Data Pipelines = complexity – tools, platforms, teams
- Complexity = delays and risk – in value and innovation
- Slow delivery of data products (Data Science)
- Too much manual intervention/testing (Business Reporting)
- Slower delivery than desired
But to meet those challenges, they need to work on their current data operations, technologies and delivery:
- Orchestration: Running pipelines of various technologies at the right time
- Iteration: Rapidly creating, iterating and deploying data science and data engineering pipelines and their data products (reports, dashboards, models) – Full Pipeline CI-CD
- Quality: Detecting issues and errors in complex, multi-tool data pipelines
- Hybrid: Enabling on-premise and cloud approaches and an evolving technology landscape
- Collaboration: Enabling multiple teams to collaborate more effectively to deliver data products to end-users faster with higher quality. Also enabling transparency of all operations in a complex pipeline.
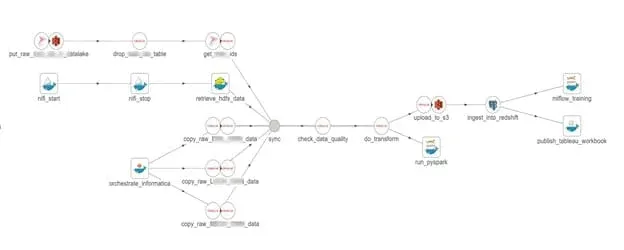
So, what bottleneck did they focus on first? Orchestration of the toolchain for low error execution and enhanced collaboration. They started with a variety of technologies that the company currently uses. These include: On-Prem
- Oracle
- SQL Server
- Informatica
- Apache Nifi
- Hadoop/HDFS
- PySpark Cloud
- Redshift
- S3
- Tableau online
- Mlfow
They then created a single DataKitchen Recipe, which provides a framework to detect issues in streaming data across a multi-technology toolchain, runs tests that ensure the quality of streaming data, and alerts users if the condition is not met. That Recipe uses all their existing tools to transform data into business insight. Other important considerations for the team were that the data was validated to be ‘fit for purpose’ so that the assumptions made while transforming data remain true. They also focused upon Recipe CI/CD so that once a change passes its tests across any of the technologies, it is deployed to the pipeline in less than five minutes.
Freeing Data Scientists’ Time Through Automation of Machine Learning Deployment and Production
A consumer product team recently completed a machine learning (ML) use case combining web scraped data with Oracle service cloud data. It works great; the business users love the early versions of the product, but:
- The various pipeline components are run by hand in an inconsistent manner, and the orchestration is not automated
- The movement of code from sandbox to development is manual
- There are few tests to ensure data quality
- The web scraping component frequently fails, and there is insufficient notification and restart capabilities
DataKitchen and the company have identified another bottleneck that first needs to be addressed. Talented (and expensive) Data Scientists can create the first version of an idea but have no interest in running it on a day to day basis. How can that ML model and all its associated data transformation, code, and UI be put into operation following a DataOps Approach? To address this bottleneck the team created a Recipe in DataKitchen that provides the ability to orchestrate the components developed in the ML use case. That Recipe has the ability to run data tests and detect errors in the data in the production environment. It also has the ability to detect operational errors (e.g., the web scraping issues), alert users to those errors, and permit re-start of the processing of the data pipeline (Recipe). See diagram below.
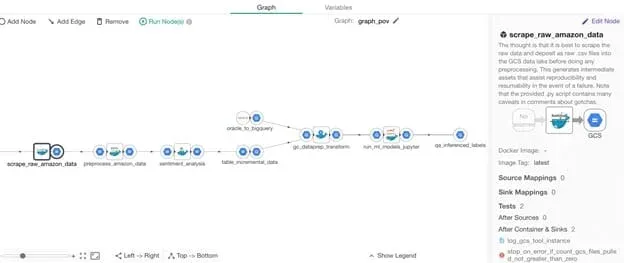
Furthermore, to enable a rapid development cycle and enhance the Recipe to add the Oracle Service Cloud data, the team needs to develop this new pipeline capability in a Development Kitchen and deploy quickly to a Production Kitchen. See the diagram below.
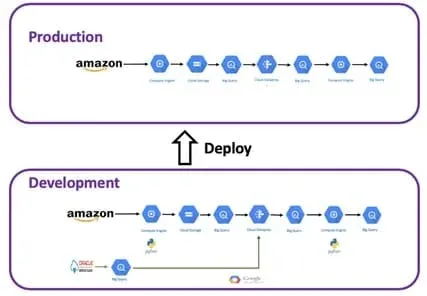
Where is your bottleneck? Where can you start doing DataOps today?
DataOps applies lean manufacturing management methods to data analytics. One leading method, the Theory of Constraints, focuses on identifying and alleviating bottlenecks. Data analytics can apply this method to address the constraints that prevent the data analytics organization from achieving its peak levels of productivity. Bottlenecks lengthen the cycle time of developing new analytics and prevent the team from responding quickly to requests for new analytics. If these bottlenecks can be improved or eliminated, the team can move faster, developing, and deploying with a high level of quality in record time. If you have multiple bottlenecks, you can’t address them all at once. As these examples have shown, there are multiple ways to provide immediate, clear value for doing DataOps and working with DataKitchen!



