
The Best DataOps Articles of Q2 2019
Every quarter we sift through the media and analyst coverage of DataOps and create a list of the best articles for the most recent period. This quarter there was so much activity we couldn’t list it all. DataOps is fast becoming one of the hottest initiatives in the data analytics industry.
Below is our roundup for Q2 2019. If you missed it, here is the previous roundup from *Q1 2019. *Please tweet us if we missed your favorite.*
7 Steps to Go From Data Science to DataOps
ODSC, March 19, 2019
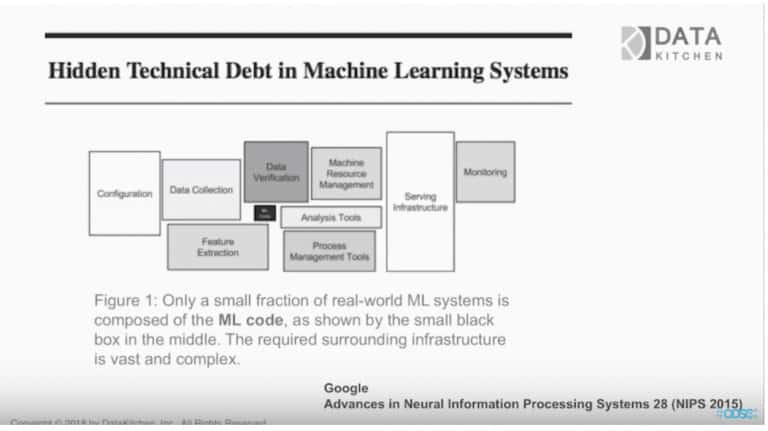
DataOps involve two pieces, people/process/organization, and the technical aspects. DataOps actually begin within the Agile environment, which is primarily that first piece. You’re focusing on value here, providing data for your audience and providing context for the business.
Lean manufacturing and DevOps make up the technical environment. This is where the fundamentals of our seven steps lie. Going from data science to data operations requires a change in the way you think about your technical environment.
OK, technically this one isn’t in Q2, but we missed it in our Q1 roundup.

Is DataOps the next big thing?, SD Times,
April 3rd, 2019

After watching application teams, security teams and operations teams get the -Ops treatment, data engineering teams are now getting their own process ending in -Ops. While still in its very early days, data engineers are beginning to embrace DataOps practices.
A Guide to DataOps Tools,
SD Times, April 3rd, 2019

Round up of notable DataOps tools: Ascend, Attunity, Composable Analytics, DataKitchen, Delphix, Devo Data Operations Platform, HPCC Systems, Infoworks, Kinaesis, Lenses.io, MapR, Nexla, Qubole, Redgate Software, StreamSets, Tamr. By Jenna Sargent,Online and Social Media Editor for SD Times.
DataOps: Building Trust in Data through Automated Testing,
Dennis Layton, April 7, 2019
Data used for analytics and subsequently decision making has to be both timely and trusted. DataOps addresses both of these challenges. Automated, continuous testing is about building trust in the data up front and reducing the time it takes to identify and fix problems before trust is lost.Consider, Google executes over one hundred million automated test scripts per day to validate any new code released by software developers. In one group, code is deployed in 8 minutes after a software engineer finishes writing and testing it. Although, this is an example of DevOps in action, the same principle of continuous and automated testing applies to DataOps.
The Explosion of “Manifestos” in Data and Analytics,
DataKitchen, April 11, 2019

Data professionals continue to experiment with new ways to approach analytics that improve outcomes for enterprises. Some propose dramatic changes while others are evolutionary. Here’s our list of the top data and analytics manifestos that industry leaders have proposed (in no particular order).
DataOps and Hitachi Vantara,
Hitachi Vantara Labs, April 11, 2019
 Grad Student Katie Bouman uses DataOps to capture first picture of a black hole
Grad Student Katie Bouman uses DataOps to capture first picture of a black hole
Data management has been around since the beginning of IT, and a lot of technology has been focused on big data deployments, governance, best practices, tools, etc. However, large data hubs over the last 25 years (e.g., data warehouses, master data management, data lakes, Hadoop, Salesforce and ERP) have resulted in more data silos that are not easily understood, related, or shared. Few if any data management frameworks are business focused, to not only promote efficient use of data and allocation of resources, but also to curate the data to understand the meaning of the data as well as the technologies that are applied to the data so that data engineers can move and transform the essential data that data consumers need. At Hitachi Vantara we have been applying our technologies to DataOps in four areas: Hitachi Content Platform, Pentaho, Enterprise IT Infrastructure, and REAN Cloud.
Data version control with DVC. What do the authors have to say?,
Favio Vázquez, April 16, 2019
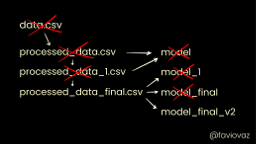
DataOps is very important in data science, and that my opinion is that data scientists should pay more attention to DataOps. It’s the less used feature in data science projects. At the moment we normally are versioning code (with something like Git), and more people and organizations are starting to version their models. But what about data?
Warring Tribes into Winning Teams: Improving Teamwork in Your Data Organization, DataKitchen, April 17, 2019
If the groups in your data-analytics organization don’t work together, it can impact analytics-cycle time, data quality, governance, employee retention and more. A variety of factors contribute to poor teamwork. Sometimes geographical, cultural and language barriers hinder communication and trust. Technology-driven companies face additional barriers related to tools, technology integrations and workflows which tend to drive people into isolated silos.
A Glimpse into DataOps, Valdas Maksimavicius, April 17, 2019

The data world is implementing DevOps principles with a twist. Whereas DevOps manages the cooperation of code, tools, and infrastructure to speed up the delivery of applications, DataOps adds the fourth element — data. To be more precise, data must be identified, captured, formatted, tagged, validated, cleaned, transformed, aggregated, secured, governed, visualized, analyzed, and acted upon. Everything gets even more complex as organizations have ambitions to use machine learning, utilize previously unexplored datasets, focus on building data-driven solutions.
DataOps is Here to Stay,Pedro Martinez, April 19, 2019

DataOps is a discipline that has become a necessity in a market where the demand for access to data assets and data products is skyrocketing. The inability of data platform teams and data management platforms to keep pace with the demands placed on them by DevOps-enabled teams led to the development of DataOps. In a nutshell, DataOps brings together data scientists, analysts, developers, and operations to work on the entire product/service lifecycle, from the design stage to production support.
The Gartner Magic Quadrant for DataOps Does Not Exist! Here is What to Look For!, Infoworks, April 19, 2019

As the title of this post notes, there is no Gartner Magic Quadrant for DataOps. However, this is a topic and space of growing interest. In fact, last year, I wrote a blog about the five characteristics that define DataOps. Almost 12 months have passed since that blog post so it is time to revisit those characteristics and update them to take into account new factors.
Building reliable data pipelines with AI and DataOps, ITProPortal, April 18, 2019

DataOps provides a series of values into the mix. From the agile perspective, SCRUM, kanban, sprints and self-organising teams keep development on the right path. DevOps relies on continuous integration, deployment and testing, with code and config repositories and containers. Total quality management is derived from performance metrics, continuous monitoring, benchmarking and a commitment to continuous improvement. Lean techniques feed into automation, orchestration, efficiency, and simplicity.
The DataOps Engineer Rises,insideBIGDATA, April 24, 2019
In this special guest feature, Tobi Knaup, Co-founder and CTO of Mesosphere, believes that most enterprises will need to build and operate production AI systems in order to stay competitive with next-generation AI-driven products. Organizations should hire DataOps engineers to build, operate, and optimize these systems, and evangelize best practices among their data scientists.
How DataOps Is Transforming Industries, TDWI April 29, 2019

In this, the third part of our four-part series, I’ll delve into a pair of examples of how customers are putting these principles into practice and making impressive strides toward transforming their businesses. Case Study #1: DataOps in Financial Services. Case Study #2: DataOps in Big Pharma. Both of these examples illustrate how a holistic approach to DataOps that involves people, processes, and technology can transform the way an organization innovates, interacts with customers, solves high-value problems, and improves its competitive position.
The Future of DataOps: Four Trends to Expect, TDWI, April 30, 2019

What’s ahead for DataOps? From automated data analysis to the transformation of subject matter experts into data curators, we look at what’s next in the last article in our four-part series. Trend #1: Ever-increasing sources of valuable data will intensify the need for smart, automated data analysis. Trend #2: You’ll want to stitch together your own custom solution from purpose-built components. Trend #3: User sophistication will increase and advanced tools will become more approachable. Trend #4: Subject matter experts will become data curators and stewards.
Get Ready for DataOps,DATAVERSITY, May 1, 2019

An emerging discipline called DataOps is taking a page out of the DevOps playbook. The latter is all about accelerating the time to software delivery, and the former about accelerating data flow. And just as DevOps replaces the waterfall method of software delivery, DataOps replaces the waterfall approach of delivering data to the data consumer.
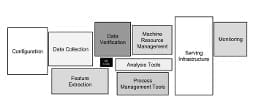
The DataOps Big Picture,The Software Ecologist, May 4, 2019
Many people have asked “Can you send me a picture of DataOps?” Most images you find if you search the web are conceptual graphics which don’t say much. So after much thought and discussion, this is my proposal for a DataOps picture.
DataOps: The role of the Data Architect,Dennis Layton, May 5, 2019

Much has been written about the role of data engineers and data scientists in building today’s data pipelines. For DataOps to scale in a consistent and cohesive manner, a data architect is essential but the approach to data architecture needs to change. It can’t be about what agile refers to a Big Up Front Design. (BUFD).
Take your machine learning models to production with new MLOps capabilities, Microsoft Azure, May 9, 2019
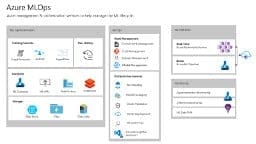
At Microsoft Build 2019 we announced MLOps capabilities in Azure Machine Learning service. MLOps, also known as DevOps for machine learning, is the practice of collaboration and communication between data scientists and DevOps professionals to help manage the production of the machine learning (ML) lifecycle.
What are MLOps and Why Does it Matter?, ODSC, May 13, 2019

During the first tech boom, Agile systems helped organizations operationalize the product lifecycle, paving the way for continuous innovation by clearing waste and automating processes for creation. DevOps further optimized the production lifecycle and introduced a new element, that of big data. With more businesses now turning to machine learning insights, we’re on the cusp of another wave of operationalization. Welcome to MLOps.
Kubernetes, The Open and Scalable Approach to ML Pipelines,
Yaron Haviv, May 14, 2019
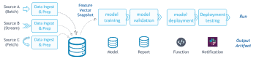
Engineers use microservices and automated CI/CD (continuous integration and deployment) in modern agile development. You write code, push and it gets tested automatically on some cluster at scale. It then goes into some type of beta/Canary testing phase if it passes the test, and onto production from there. Kubernetes, a cloud-native cluster orchestrator, is the tool now widely used by developers and devops to build an agile application delivery environment.
Why you need DataOps, Kinaesis, May 16, 2019

An ex colleague and I were talking a few days ago and he mentioned people don’t want to buy DataOps. To this I have given some thought and can only come up with the conclusion that I agree, in the same way that I can agree that I don’t want to buy running shoes, however I want to be fit and healthy. It is interesting to find so many people that are happy with their problems that a solution is less attractive.
Eliminate Your Analytics Development Bottlenecks, DataKitchen, May 16, 2019
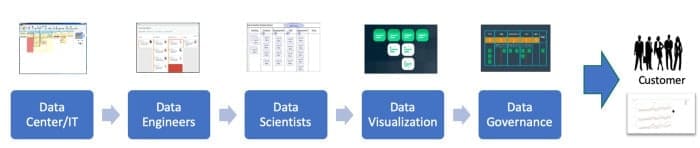
Analytics teams need to move faster, but cutting corners invites problems in quality and governance. How can you reduce cycle time to create and deploy new data analytics (data, models, transformation, visualizations, etc.) without introducing errors? The answer relates to finding and eliminating the bottlenecks that slow down analytics development.
Introduction to DataOps, DZone, May 17, 2019

The term DataOps is currently gaining a lot of traction, with solutions emerging that have significantly matured. Let’s discuss whatDataOps is all about. The idea in the end is to have two pipelines. A continuous data ingestion pipeline, and a pipeline for new developments, which meet during data production. Ideally, therefore, a unified platform is needed to handle all this and centralize people around the same tool. Tools exist, such as DataKitchen or Saagie, to monitor the data production chain.
The Rise of DataOps (from the ashes of Data Governance),
Ryan Gross, May 17, 2019

The vast majority of data governance initiatives fail to move the needle, with Gartner also categorizing 84% of companies as low maturity in data governance. Despite the fact that nearly every organization recognizes the need for data governance, many companies are not even starting data governance programs due to the strong negative connotation of the term within the executive ranks.
DataOps: Getting Data Right for DevOps,
Information Age, May 21, 2019

It’s sad but true, most attempts by companies to leverage data as a strategic asset fail. The challenge of both managing vast amounts of disparate data and then distributing it to those who can use it to drive value is proving incredibly difficult. The bad news: data is continuing to grow at a rapid rate and modern application development is getting more and more complex. As such, many organisations are recognising the need for a new paradigm. Enter: DataOps.
DataOps — DevOps for Data, Sandesh
Gawande, May 21, 2019
What is really happening in a data factory, is that the development teams & QA teams are processing the data & providing it to Business and Operations professionals (these include CDOs, business users, data stewards, data quality analysts & data governance professionals). Now when data issues are found, the business users point fingers at operations people. Operations people point fingers at QA professionals. Finally, QA professionals blame the development teams. That’s what happens data factories become data silos, concerned with only their set of respective operations.
DataOps Principles: How Startups Do Data The Right Way, Retina, May 24, 2019

If you have been trying to harness the power of data science and machine learning — but, like many teams, struggling to produce results — there’s a secret you are missing out on. All of those models and sophisticated insights require lots of good data, and the best way to get good data quickly is by using DataOps.
The 3 Principles of DataOps to Operationalize Your Data Platform,
Informatica, May 29, 2019
It’s becoming clear that data-driven organizations are struggling to keep up with all their enterprise data and manage it to their strategic advantage. Despite the vast amounts of data available to us, we still can’t provide cost-effective quality healthcare to the elderly, too many companies are not delivering great multi-channel customer experiences, and they can’t ensure data is governed and protected to comply with a myriad of global industry and data privacy regulations. Why aren’t companies delivering more data-driven breakthroughs? One reason is that many organizations simply haven’t figured out how to operationalize their data platforms at enterprise scale.
What is a Data Engineer?,
Lewis Gavin, May 31, 2019

This article comes off the back of the sea of articles I’ve seen recently talking about this exact point: that 80% of a Data Scientists work is data preparation and cleansing.
How to get started with DataOps,
Hewlett Packard Enterprise, June 3, 2019

Data operations are a messy business. Data quality is inhibited by siloed, complex data pipelines. A lack of collaboration across data functions stymies coordination and efficiency. Manual and ungoverned processes for data delivery across the supply chain can lead to compromised analytics processes. The analytics cycle time takes a hit, and product delivery suffers.
Opinion 5 requirements for success with DataOps strategies,
Information Management, June 4, 2019

Spring is traditionally a time to commence Spring cleaning. It’s also a great time for IT teams to look at how to better streamline the development and delivery of data to better support the business operations.
DataOps: Low adoption doesn’t mean low value, Techerati, June 5, 2019

DataOps provides a better and faster way of managing data pipelines. Helena Schwenk, global AR & market insights manager at Exasol, explains how to get DataOps off the ground and make it work in your organization
Opinion Surviving and Thriving in Year Three as a Chief Data Officer,
Information Management, June 5, 2019

As the chief data officer (or chief analytics officer) of your company, you manage a team, oversee a budget and a hold a mandate to set priorities and lead organizational change. The bad news is that everything that could possibly go wrong from a security, governance and risk perspective is your responsibility. If you do a perfect job, then no one on the management team ever hears your name.
How Real-Time Data Streaming and Integration Set the Stage for AI-Driven DataOps,
Dana Gardner, June 7, 2019

Just as enterprises seek to gain more insights and value from their copious data, they’re also finding their applications, services, and raw data spread across a hybrid and public clouds continuum. Raw data is also piling up closer to the edge — on factory floors, in hospital rooms, and anywhere digital business and consumer activities exist.
Cool Vendors in Data Management,
Gartner, June 7, 2019
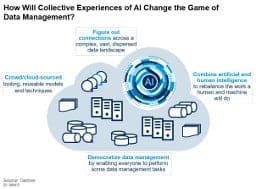
Traditional, bespoke designs for post implementation integration practices have led to unmanageable systems. These Cool Vendors offer data and analytics leaders ways to introduce collaborative, modern data management strategies.
Data as an Asset: The Potential of DataOps in the Enterprise,
Tamr, June 11, 2019
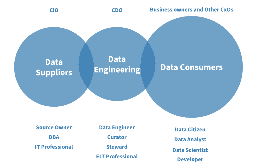
As modern enterprises embrace the potential value of data to their organization, they are beginning to build out a new generation of data infrastructure and human behavioral norms to complement their traditional legacy infrastructure and data culture. The technical methods and behavioral expectations at large internet companies are serving as an aspirational frame of reference for more-traditional companies, as they ask “How can we (Global 2000 Companies) manage and monetize data as an asset as effectively as Google, Amazon or LinkedIn?”
DataOps: What It Is, Why It’s Important Now, and How to Achieve It,
Toolbox Tech, June 12, 2019

DataOps is the alignment of people, automated technologies, and business agility to enable an order of magnitude improvement in the caliber and reduced cycle time of data analytics. DataOps expedites the flow of data for effective operations on both traditional and big data, by leveraging self-service capabilities to bypass traditional methods of engineering customized programs. Here, we take a deeper dive into DataOps to discover why it’s important now.
Case Study: DataOps Practices Create Incremental Business Value,
MAQ Software, June 13, 2019

In 2017, our client revolutionized its partner services. 440,000 partners relied on our client’s analytics platform, but the platform inefficiently sourced data from silos… To support the portal, we assembled a 40-member team… The principles the teams followed are codified as DataOps.
Best Practices in DataOps: How to Create Robust, Automated Data Pipelines,
Eckerson Group, Jun 17, 2019

DataOps is an emerging set of practices, processes, and technologies for building and automating data pipelines to meet business needs quickly. As these pipelines become more complex and development teams grow in size, organizations need better collaboration and development processes to govern the flow of data and code from one step of the data lifecycle to the next — from data ingestion and transformation to analysis and reporting.
The Taxonomy of DataOps,
DevOps.com, June 20, 2019

Like the cloud or DevOps, DataOps doesn’t make sense until you sit down and really think through what it entails. To that end, let’s take a look in this article at the taxonomy of DataOps — or, in other words, which IT disciplines, areas of expertise and types of work make DataOps happen.
How DataOps Improves Data, Analytics,
and Machine Learning, InfoWorld, June 20, 2019

Much of the work around data and analytics is on delivering value from it. This includes dashboards, reports, and other data visualizations used in decision making; models that data scientists create to predict outcomes; or applications that incorporate data, analytics, and models. What has sometimes been undervalued is all the underlying data operations work, or DataOps, that it takes before the data is ready for people to analyze and format into applications to present to end users.
How IBM is advancing DataOps and Watson Anywhere with new capabilities,
IBM Big Data Analytics, June 27, 2019

According to Gartner, by 2021, AI augmentation will recover 6.2 billion hours of worker productivity. With AI at the core of new product development, IBM is tackling the most prevalent data challenges by bringing out new tools that help clients get their data ready for business fast, and allow them to focus more time on generating insights…This week, we’re advancing the platform even further with the addition of several premium add-ons all designed to help people automate and improve their DataOps and discovery processes.
Data Manufacturing,
Best’s Review, June 2019

As industries across all sectors embrace corporate agility, and traditional vertical lines continue to blur, insurers are finding themselves in a digital transformation race. The race, as expected, has become more of an ultra-marathon than a sprint, with a greater focus on time frame and pace than on short-term winners and losers. DataOps is an emerging discipline recognizing the value to an insurer of data, both their own internal data and any other data available to them, in that digital marathon.






