
The data mesh design pattern breaks giant, monolithic enterprise data architectures into subsystems or domains, each managed by a dedicated team. With an architecture comprised of numerous domains, enterprises need to manage order-of-operations issues, inter-domain communication, and shared services like environment creation and meta-orchestration. A DataOps superstructure provides the foundation to address the many challenges inherent in operating a group of interdependent domains. DataOps helps the data mesh deliver greater business agility by enabling decentralized domains to work in concert.
This post (1 of 5) is the beginning of a series that explores the benefits and challenges of implementing a data mesh and reviews lessons learned from a pharmaceutical industry data mesh example. But first, let’s define the data mesh design pattern.
The past decades of enterprise data platform architectures can be summarized in 69 words. Note, this is based on a post by Zhamak Dehghani of Thoughtworks.
- First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt.
- Second-generation – gigantic, complex data lake maintained by a specialized team drowning in technical debt.
- Third-generation – more or less like the previous generation but with streaming data, cloud, machine learning and other (fill-in-the-blank) fancy tools. And you guessed it, managed by a specialized team drowning in technical debt.
See the pattern? It’s no fun working in data analytics/science when you are the bottleneck in your company’s business processes. A barrage of errors, missed deadlines, and slow response time can overshadow the contributions of even the most brilliant data scientist or engineer. The problem is not “you.” It lies somewhere in between your enterprise data platform architecture and the enterprise’s business processes. Below are some reflections upon the failure of modern enterprise architectures to deliver on data analytics agility and reliability:
- Centralized Systems Fail – Lots of inputs and outputs; numerous fragile pipelines; hard to understand, modify, monitor, govern; billions of dollars have been (and will be) invested in vain trying to cope with this vast complexity.
- Skill-based roles cannot rapidly respond to customer requests – Imagine a project where different parts are written in Java, Scala, and Python. Not everyone has all these skills, so there are bound to be bottlenecks centering on certain people. Data professionals are not perfectly interchangeable. Further, the teams of specialized data engineers who build and maintain enterprise data platforms operate as a centralized unit divorced from the business units that create and consume the data. The communication between business units and data professionals is usually incomplete and inconsistent. Centralized enterprise data architectures are not built to support Agile development. Data teams have great difficulty responding to user requests in reasonable time frames. Figure 1 illustrates the existence of barriers between data source teams, the platform team and data consumers.
- Data domain knowledge matters – The data team translates high-level requirements from users and stakeholders into a data architecture that produces meaningful and accurate analytics. This is much easier to do when the data team has intimate knowledge of the data being consumed and how it applies to specific business use cases. A schema designer who moves from project to project may not understand the nuances behind the requirements of each data consumer.
- Universal, one size fits all patterns fail – Data teams may fall into the trap of assuming that one overarching pattern can cover every use case. We’ve seen many data and analytic projects, and mistaken assumptions like this one are a common cause of project underperformance or failure.
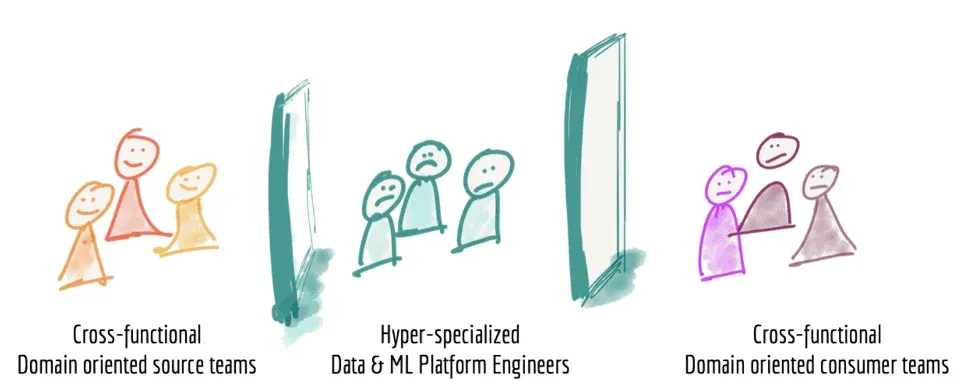
Figure 1: The organization structure builds walls and barriers to change. Source: Thoughtworks
Introduction to Data Mesh
The data mesh addresses the problems characteristic of large, complex, monolithic data architectures by dividing the system into discrete domains that are managed by smaller, cross-functional teams. Data mesh proponents borrow the term “domain” from the software engineering concept of “domain-driven design (DDD),” a term coined by Eric Evans. DDD divides a system or model into smaller subsystems called domains. Each domain is an independently deployable cluster of related microservices which communicate with users or other domains through modular interfaces. Each domain has an important job to do and a dedicated team – five to nine members – who develop an intimate knowledge of data sources, data consumers and functional nuances. The domain team adopts an entrepreneurial mindset, viewing the domain as if it were a product and users or other domains as customers. The domain includes data, code, workflows, a team, and a technical environment. Data mesh applies DDD principles, proven in software development, to data analytics. If you’ve been following DataKitchen at all, you know we are all about transferring software development methods to data analytics.
The organizational concepts behind data mesh are summarized as follows.
- A five to nine-person team owns the dev, test, deployment, monitoring and maintenance of a domain.
- The team organizes around the domain, not the underlying toolchain or horizontal data pipelines.
- Domain data assets, artifacts and related services are viewed as the team’s product. The product includes data and operations. Data consumers are the domain team’s customers.
- Data Engineers must develop an intimate understanding of data sets to really add value.
Benefits of a Domain
A well-implemented domain has certain attributes that offer benefits to the customers or domain users:
- Trusted – Users wish to be confident that the data and artifacts are correct. Trust must be earned, which is why it is so important for a domain to have interfaces that enable introspection and access. Users should be able to ask the domain questions and get answers.
- Usable by the teams’ customers – Customer experience improves by virtue of having a dedicated team that attains intimate knowledge of the data and its use cases. Also, the domain must support the attributes that are part of every modern data architecture.
- Discoverable – users have access to a catalog or metadata management tool which renders the domain discoverable and accessible.
- Understandable and well-described – terms are defined in a dictionary and the domain has clean, well-designed interfaces.
- Secure and permissioned – data is protected from unauthorized users.
- Governed – designed with data quality and management workflows that empower data usage.
- URL/API Driven – can easily interoperate with other domains through a hyperlink (URL) or application programming interface (API).
- Clear accountability – users interact with a responsive, dedicated team that is accountable to them.
- Easy to report problems and receive updates on fixes
- Users may request new insights/improvements and get them into production quickly.
Organizing a data architecture into domains is a first-order decision that drives organizational structure, incentives and workflows that influence how data consumers use data. Domains change the focus from the data itself to the use cases for the data. The customer use cases in turn drive the domain team to focus on services, service level agreements (SLA) and APIs. Domains promote data decentralization. Instead of relying on a centralized team, where the fungibility of human resources is an endless challenge, the domain team is dedicated and focused on a specific set of problems and data sets. Decentralization promotes creativity and empowerment. In the software industry, there’s an adage, “you build it, you run it.” Clear ownership and accountability keep the data teams focused on making their customers successful. As an organizing principle, domains favor a decentralized ecosystem of interdependent data products versus a centralized data lake or data warehouse with all its inherent bottlenecks.
If you have worked in the data industry, you already know that while decentralization offers many benefits it also comes with a cost. We’ll cover some of the potential challenges facing data mesh enterprise architectures in our next blog,Use DataOps with Your Data Mesh to Prevent Data Mush.


