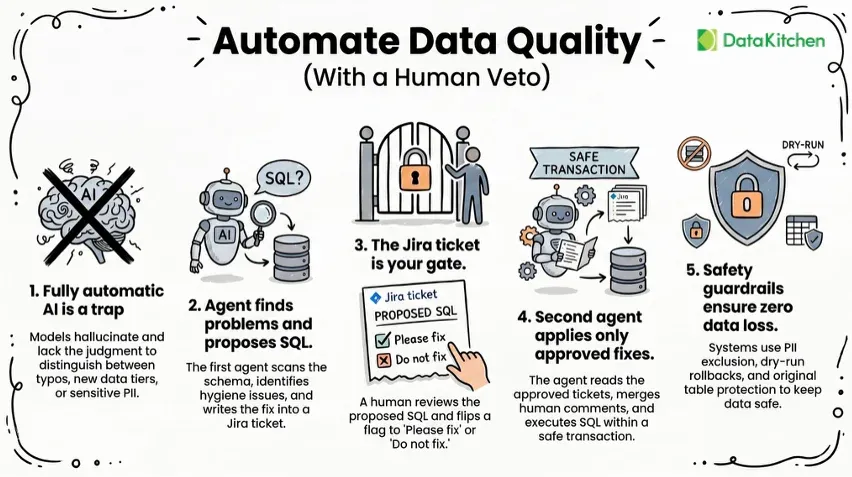
In this playful yet pointed talk, ‘Data Quality Coffee With Uncle Chip’ kicks things off by poking fun at the overcomplicated world of data quality dimensions. With so many dimensions and no consensus on definitions, vague terms like “accuracy” and “validity” just blur together. But the real problem, he warns, is not the number of dimensions—it’s that they’re too often treated as static, theoretical labels rather than dynamic markers of real-world process issues. This mindset, rooted in an outdated era of static data, keeps teams locked in abstraction and prevents meaningful action.
Uncle Chip contrasts this static perspective with the complex journey data now takes before reaching a decision-maker. Today’s data is touched by many layers: transfers, integrations, mastering logic, transformations, and summaries. Traditional quality dimensions ignore this entire upstream context. They assume the data is already baked and ready to be judged when the pipeline is the real factory floor. He argues that focusing solely on the end product blinds teams to where quality issues are introduced. DataOps flips this perspective by recognizing that process quality is the engine of data quality—if you control and measure the process; you can consistently deliver better data.
This is where Uncle Chip introduces DataOps Data Quality TestGen. This tool doesn’t just support the old dimensions but reorients teams to target the root causes of data issues within their pipelines. TestGen allows teams to monitor quality across multiple layers, from table groups down to columns, tagging and tracking where problems appear and where they originate. It equips users to pinpoint whether duplicates came from dirty source data, bad joins, or integration mismatches. This granularity transforms vague quality problems into actionable insights. It’s not about catching errors at the end of the pipeline—it’s about catching them as they emerge, where they’re easiest to fix.
Uncle Chip closes by highlighting how TestGen helps teams influence change, especially when they don’t have complete control over upstream systems. Through targeted issue reports and custom scorecards, TestGen gives data teams the tools to build accountability, even in distributed or data mesh environments. These reports include contextual details, sample data, and even SQL reproductions to enable fast resolution. He argues that the goal is to replace hand-waving and blame with visibility and progress. Data quality isn’t about reciting a list of dimensions—it’s about empowering teams to understand, diagnose, and improve the processes that produce data in the first place.
Watch The ‘Data Quality Coffee With Uncle Chip’ Series