
The Hidden Crisis in Data Teams: When Business Logic Lives Everywhere and Nowhere
There’s a quiet crisis happening in data organizations everywhere. Not the dramatic kind that makes headlines—no security breaches, no system failures. Instead, it’s a slow erosion of value that occurs when brilliant analysts independently solve the same problem in three different ways, when data scientists struggle to reproduce each other’s work, and when a single “simple” metric, such as Monthly Recurring Revenue, has five competing definitions scattered across the organization.
I’ve watched data teams double their headcount while their actual impact plateaus. The problem isn’t talent or technology—it’s the absence of what I call process guardianship: the deliberate, systematic work of consolidating how business logic lives and operates within an organization.
For data engineers reading this, I want to make a case that might initially feel uncomfortable: your job isn’t finished when you deliver clean, analyst-ready data. In fact, that’s where some of your most valuable work begins.
What Process Guardianship Actually Means
Process guardianship is the practice of consolidating disparate metrics, models, calculations, and code into a unified, tested, and highly agile data pipeline. It means taking the business logic that naturally scatters itself across SQL scripts, Jupyter notebooks, Looker reports, Python models, and Excel macros, and deliberately centralizing it into a maintainable, version-controlled, production-grade system.
This isn’t just about code hygiene or engineering best practices. It’s about recognizing that the real intellectual property of your data team—the accumulated knowledge of how your business actually works—shouldn’t live as tribal knowledge on the laptops of team members around the world.
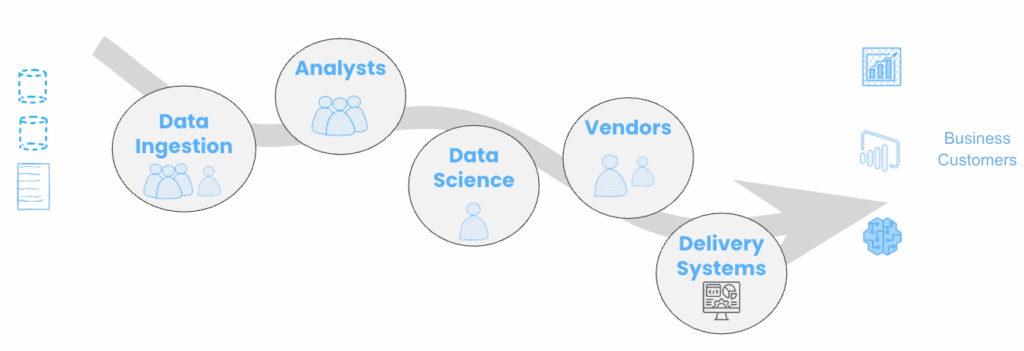
It takes a village to create insight for your customer. How do you stop duplicate or redundant work?
Think about the business logic in your organization right now. Where does the calculation for customer lifetime value actually live? Is it in the Excel macro on Bob’s laptop on the finance team? Or in the segmentation model the data science team built? Or in the SQL query your senior analyst wrote last quarter? The answer, more often than uncomfortable, is “all three places, and they don’t quite match.”
The Hidden Cost of Scattered Business Logic
Let me paint a picture of what happens without process guardianship.
Your marketing analyst builds a brilliant customer segmentation model. It works beautifully for their campaign targeting. Three months later, your data scientist builds another segmentation model for churn prediction—unaware that the first one exists. Six months after that, finance needs customer segments for their forecasting model and builds yet another version because they can’t find or don’t trust the existing two. Now you have three models that: use slightly different definitions of “active customer,” handle edge cases differently, produce overlapping but inconsistent results, and require separate maintenance when business rules change
When leadership asks, “How many customers do we have in our high-value segment?”, you get three different answers. This isn’t a hypothetical scenario—this is Tuesday afternoon in most data organizations.
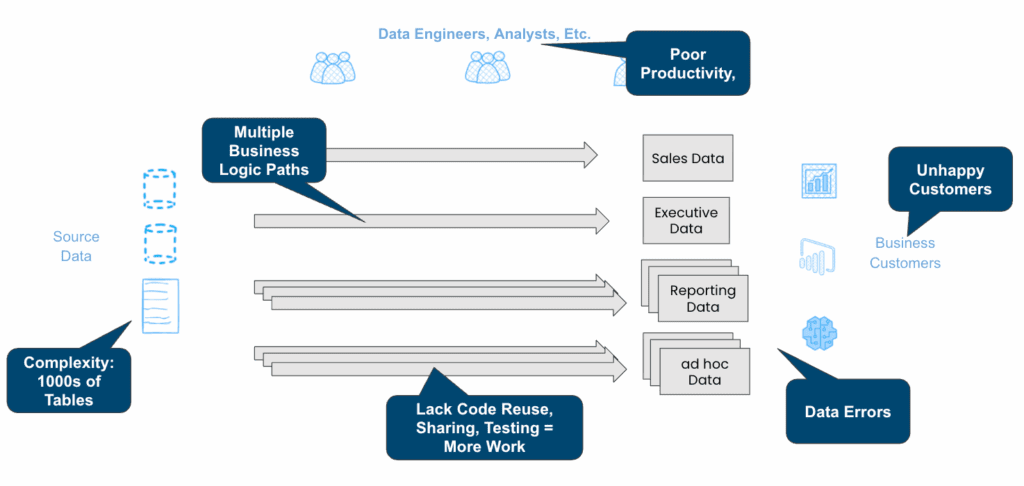
Challenges with a typical organization’s “Scattered Processes”
The costs compound quickly:
Duplicate work becomes the norm. Teams waste countless hours reinventing wheels because they don’t know what already exists or can’t trust it enough to reuse it.
Multiple overlapping metrics create confusion and erode trust. When “monthly active users” means something different in the product dashboard versus the board deck, stakeholders stop believing in your numbers.
Embarrassing data errors slip through. The marketing team launches a campaign targeting “high-value customers” based on one definition. At the same time, finance forecasts revenue using another method, and nobody notices until the numbers don’t add up at the end of the quarter. Or legitimate corrections identified by one team aren’t vetted or shared with the enterprise.
Lower data team productivity becomes the steady state. Your talented people spend more time reconciling discrepancies, explaining why numbers don’t match, and rebuilding things that should already exist than they do creating new value. Newer employees or vendors often struggle to get up to speed quickly.
The Data Engineer as a Process Guardian
Here’s where data engineers come in, and why this role is so critical.
Data engineers have a unique position in the extended data team. You sit at the intersection of raw data and business consumption. You understand both the technical infrastructure and the analytical workflows. You see the patterns—you’re the ones who notice when three different teams ask for “basically the same thing” in three different ways. Data engineers are the first to identify duplicate code and are ideally positioned to make recommendations.
Process guardianship means actively stepping into that space and saying: “This business logic is too important to live in scattered notebooks and ad-hoc queries. Let’s consolidate it, test it, and make it production-grade.”
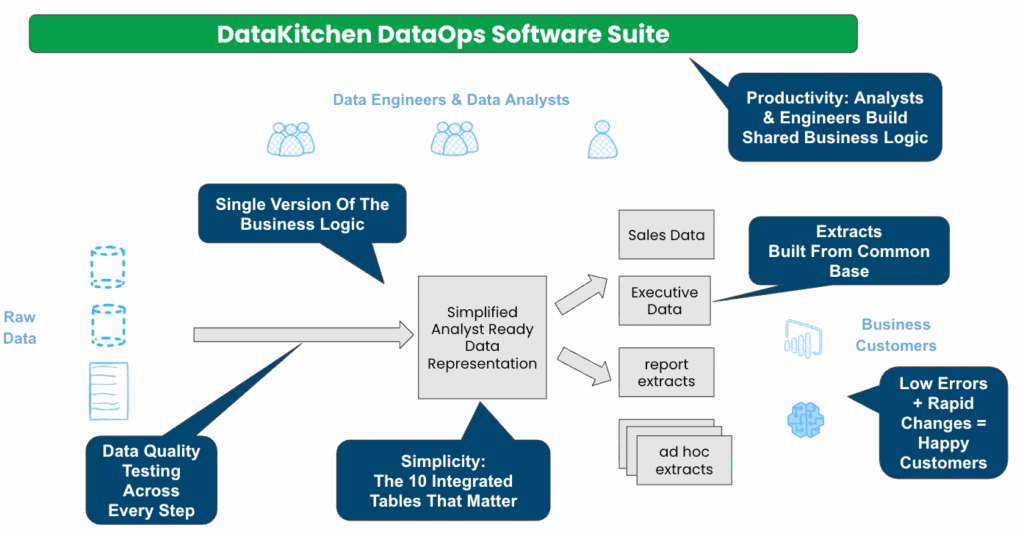
An example of the processes acting upon data, while facilitating Process Guardianship
This involves several concrete shift-left type activities:
Extracting business logic from its hiding places. That incredible revenue forecasting model your data scientist built in a notebook? That complex customer scoring logic buried in a Looker view? That critical date logic that exists only in your senior analyst’s SQL queries? These need to be identified, documented, and brought into a centralized system.
Creating a unified, tested pipeline. Business logic should reside in version-controlled code, accompanied by thorough testing, comprehensive documentation, and rigorous review processes. When your churn model definition changes, it should change in exactly one place, with a clear history of what changed and why. With source code version control.
Building for agility and experimentation. Done right, process guardianship creates a foundation that enables experimentation to be faster and safer. When analysts and data scientists can trust the foundational business logic and metrics, they can focus on asking new questions rather than rebuilding the basics.
Enabling smooth transitions from experiment to production. When that experimental model or analysis proves valuable, moving it into production shouldn’t require a complete rewrite. The path from notebook to production pipeline should be clear and well-traveled.
The Reality: Less Work Than You Think
Here’s something that might surprise you: from a pure engineering hours perspective, this work is often a small fraction of your total effort. You’re not rebuilding everything from scratch—you’re consolidating what already exists and creating structure around it.
The actual technical work might look like: converting that critical SQL logic from a report into a dbt model with tests, refactoring a data science model in Python from a notebook into a versioned, parameterized pipeline, creating shared metric definitions in your semantic layer that replace dozens of slightly different calculations, building lightweight frameworks that make it easy for analysts to contribute tested, reusable logic, or building a new fact in a shared fact table.
This isn’t months of architectural redesign. It’s often days or weeks of focused consolidation work. But the impact is wildly disproportionate to the time invested. Let me describe what this looks like in a well-functioning data organization.
When a data scientist wants to build a new churn prediction model, they don’t start by defining what “churned” means—that definition already exists in the centralized data pipeline, tested and agreed upon by the business. They can focus their improvement on the actual working code with tests.
When finance needs to create a new forecast, they pull from the same customer segmentation, revenue recognition rules, and metric definitions that marketing and product are already using. The numbers match by default, not by accident.
When a critical business rule changes—such as how you handle returns in your revenue calculations—that change occurs in one place, propagates automatically, and every downstream consumer receives the update without manual intervention.
When an analyst builds something experimental that proves valuable, the path to productionizing it is straightforward because it was built on top of tested, production-grade foundations from the start.
The data team’s collective knowledge isn’t locked in individual heads or scattered across folders. It’s codified, tested, documented, and accessible. New team members can onboard more quickly because they’re learning from a centralized, maintained body of work rather than searching through old tickets and Slack messages.
Why This Matters
The benefits extend well beyond the data team itself.
Stakeholder trust increases when numbers are consistent across different teams and tools. When executives see the same metrics in every dashboard, calculated the same way, they stop questioning the numbers and start acting on them.
Decision velocity improves because people are no longer waiting for analysts to rebuild basic metrics or reconcile conflicting definitions. The foundational layer is solid, allowing analysis to occur more quickly.
Experimentation becomes safer because there’s a clear distinction between production logic (tested, reviewed, maintained) and experimental work (rapid, flexible, creative). You can move fast without breaking things.
Knowledge persists when key team members leave. The business logic they understood isn’t lost—it’s captured in the centralized system, so there’s no more tribal knowledge.
Compliance and governance become manageable. When you need to audit how a metric is calculated or ensure specific data handling rules are followed, having logic centralized makes this dramatically simpler.
Streamlined compliance and governance. Auditing metric calculations or enforcing data handling rules is significantly simplified with centralized logic.
In summary, you end up with a single version of the truth.
Common Objections and How to Address Them
“We’re too busy building new pipelines to worry about consolidating existing logic.” This is the trap. You’ll always be too busy if you never invest in consolidation. The duplicate work and scattered logic are what’s making you busy. Process guardianship is how you break the cycle.
“Our analysts need flexibility—centralized logic will slow them down.” Good process guardianship increases flexibility. When analysts can trust foundational metrics and logic, they spend less time on basic plumbing and more time on actual analysis. The goal is to liberate analysts from production drudgery.
“This sounds like a lot of bureaucratic overhead.” It doesn’t have to be. This isn’t about creating approval workflows or committees. It’s about making it easier to do the right thing than the wrong thing. When contributing to centralized, tested logic is simpler than copying someone else’s query and modifying it, people naturally gravitate toward it. It is about refactoring.
“Our business changes too fast for this to work.” Actually, the opposite is true. When business logic is scattered, every change requires hunting down every instance and updating every one. When it’s centralized, changes happen in one place and propagate automatically. Process guardianship makes you more agile, not less.
Ultimately, process guardianship is as much about mindset as it is about technical practice. It requires seeing your role as a data engineer not just as building pipelines, but as a steward of how your organization’s business logic lives and evolves.

Scattered Process vs Process Guardianship
It means asking questions like: Does this calculation exist anywhere else? Should this logic live in a production pipeline instead of a notebook? How will we maintain this when business rules change? What happens when the person who wrote this leaves the company?
It means having the conviction to say “before we build this, let’s consolidate what already exists,” even when there’s pressure to ship something new. It means advocating for the unsexy work of consolidation and refactoring, knowing that it’s often more valuable than the flashy new project.
In Complex Organizations, This Becomes Invaluable
In small organizations with simple data needs, you can sometimes get away without deliberate process guardianship. Everyone knows everyone, communication is easy, and the surface area is small enough to keep in your head.
As organizations grow in size and complexity—adding more data sources, teams, stakeholders, and systems—the chaos caused by scattered business logic becomes exponentially more costly. The importance of having someone actively guard these processes shifts from “nice to have” to “absolutely critical.”
Data engineers who practice process guardianship become force multipliers. The time investment is relatively small compared to other data engineering tasks. But the impact—on data quality, team productivity, stakeholder trust, and organizational agility—is enormous.
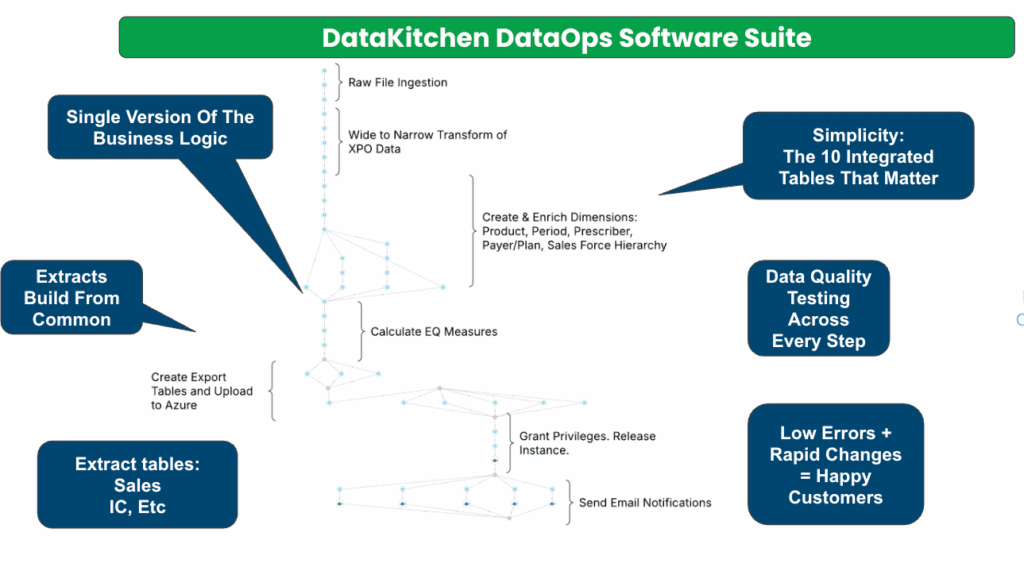
An example of a process to guard from a DataKitchen DataOps Automation Recipe.
Be the Guardian Of Your Team’s Collective Intelligence
When people think of data engineers, the description usually stops at “building high-quality pipelines that deliver analyst-ready data.” That is true, but incomplete. In modern organizations, data engineers hold a deeper responsibility. They are not just the builders of pipelines—they are the curators of the business logic itself.
This guardianship role involves consolidating fragmented definitions of the business—metrics scattered across dashboards, SQL scripts, notebooks, and models—into a unified, tested, performant, and agile data production line. It involves extracting business logic from hidden corners and tribal knowledge, then encoding it in a centralized, version-controlled, and production-ready system.
The payoff? More consistent decisions, fewer errors, and higher productivity across the extended data team.
Process guardianship means making it a core part of how your data team operates. It means recognizing that your job isn’t done when the data is clean and accessible—it’s done when the business logic that acts on that data is consolidated, tested, and maintainable. It means seeing yourself not just as a builder of data infrastructure, but as a guardian of your organization’s collective intelligence about how to make sense of that data.
For data engineers, this is an opportunity to expand your impact beyond technical infrastructure into the strategic heart of how your organization operates. The IP of your data team—the accumulated knowledge of what metrics matter and how to calculate them, what models work, and how to apply them—is too valuable to scatter. It needs a guardian.
The question is: are you ready to take on that role? Your organization is ready for the benefits.






