If you’re a data engineer tired of being the last to hear when something goes wrong, this is for you.
You know the feeling: a business stakeholder messages you at 2 PM on a Tuesday saying, “Hey, the revenue numbers look off.” You open your laptop and spend the next three hours manually querying tables, checking row counts, and trying to figure out what happened to a pipeline that ingested data six hours earlier. Multiply that by a few incidents a month, and you could be losing upwards of a dozen analyst-hours every week just on detective work. By the time you find the cause—a simple upstream schema change no one told you about—the damage is already done.

This is the daily grind for data engineers, but it doesn’t have to be. With DataKitchen’s DataOps TestGen, you can be the reliability champion on your team. With open source, you can ensure data stays trustworthy, and issues are resolved before anyone else even notices something’s wrong. Instead of reacting to problems after the fact, you can take pride in being proactive and build a reputation for dependable, flawless data delivery.
What Is TestGen’s New Table Monitoring Feature?
TestGen’s monitoring is based on one simple idea: continuous, automated watching of your data tables without needing you to write any SQL, Python, or YAML. After you set up the tables to monitor, TestGen runs regular checks and uses machine learning to spot problems before they turn into disasters.
Setting Up Monitoring: Simpler Than You’d Think
The Monitor Tables workflow in TestGen helps you start monitoring quickly and easily. Just pick the tables you want to watch, set the schedule, and TestGen handles the rest. You don’t have to create thresholds or baseline stats yourself, since TestGen learns your data’s normal patterns and spots anything unusual. For teams that want more control, you can also define custom monitors, set manual thresholds, or override the machine learning-based checks for specific cases. This flexibility lets you cover both the everyday and the edge cases, so you get the level of monitoring that fits your needs.
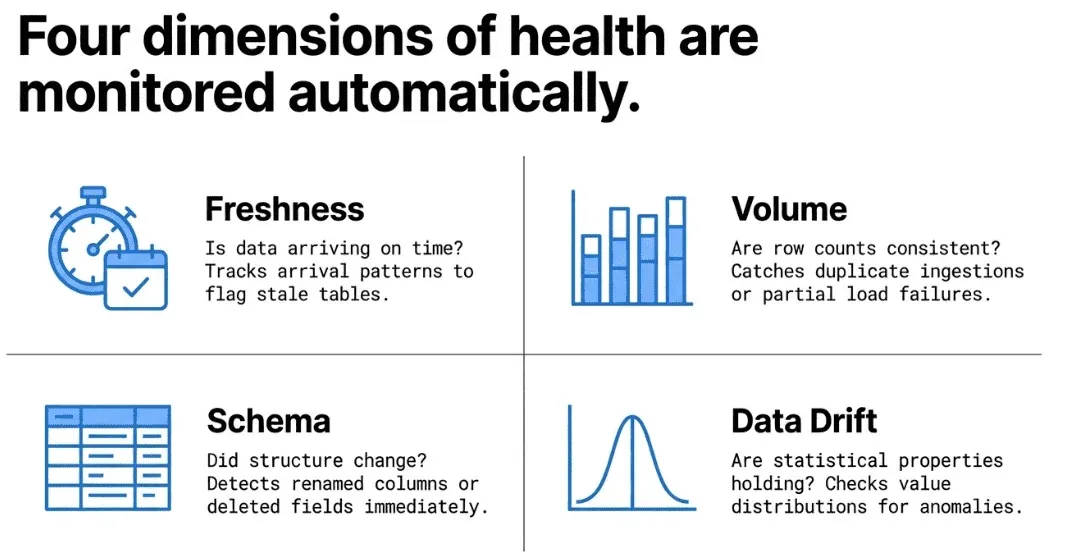
The monitors TestGen generates cover the four dimensions that matter most to data engineers in production:
Freshness — Is your data arriving on time? If a table that normally refreshes every hour suddenly hasn’t received new rows in four hours, you want to know immediately. TestGen tracks data arrival patterns and flags when a table goes stale.
Volume — Are the right number of records showing up? Unexpected spikes or drops in row counts are among the most common signals that something went wrong upstream. TestGen determines whether it’s a duplicate ingestion, a partial load failure, or a row-count issue. TestGen monitors row count trends and alerts you when volume deviates from expected norms.
Schema — Did someone alter a column without telling you? Schema drift is a silent killer in data pipelines. A column that gets renamed, a data type that gets widened, or a field that quietly disappears can break downstream models and reports. TestGen watches your schemas and catches changes the moment they happen.
Data Drift — Are the statistical properties of your data changing in ways that suggest a quality problem? TestGen looks at the actual distributions and characteristics of column values. If a numeric field that normally has values between 0 and 100 suddenly contains values in the thousands, that’s a signal worth investigating. You can add any metric that can be expressed in SQL to monitor for anomalies. Track sales volume, manufacturing output, user conversions, anything your data can tell you about, automatically.
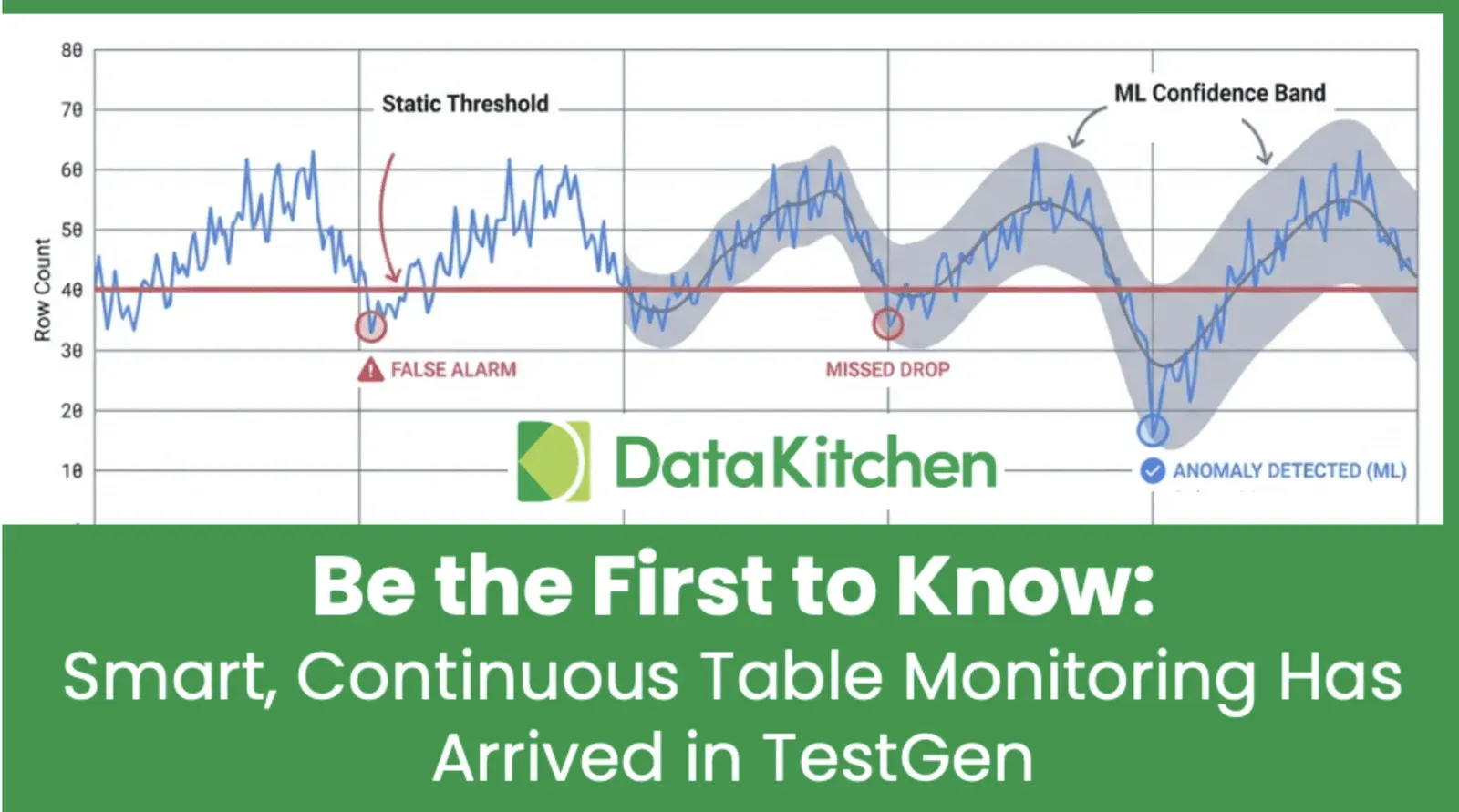
From blunt thresholds to adaptive ML: TestGen’s ML-Based Time Series Anomaly Detection. TestGen stands out from tools that use fixed thresholds or simple rules. Traditional solutions rely on rigid thresholds, creating alerts like “notify me if row count drops by more than 15%” and missing more subtle issues. TestGen advances this limitation by using machine learning models trained on historical time-series data for each table and column. The ML engine learns your data’s natural rhythms, including seasonal patterns, day-of-week changes, and long-term trends, and flags anything unusual. This means fewer false alarms waking you up at night and better detection of subtle, slow problems that fixed thresholds would miss. Other vendors charge extra for this smart detection, but TestGen includes it by default as part of our open source. Why pay $100K for commodity algorithms? When an anomaly is detected, TestGen delivers alerts to your team where they already work: email.
Viewing Monitor Results: A 360° View of Table Health
Once your monitors are running, the View Monitor Results screen gives you a consolidated, actionable view of everything TestGen has observed.
Instead of digging through log files or running random queries to find problems, you get a dedicated UI that shows anomalies in context. The results screen tells you which tables are healthy, which have alerts, and the history of each metric. This is especially helpful when you want to know, “When did this problem actually start?” because the trend data is all right there.
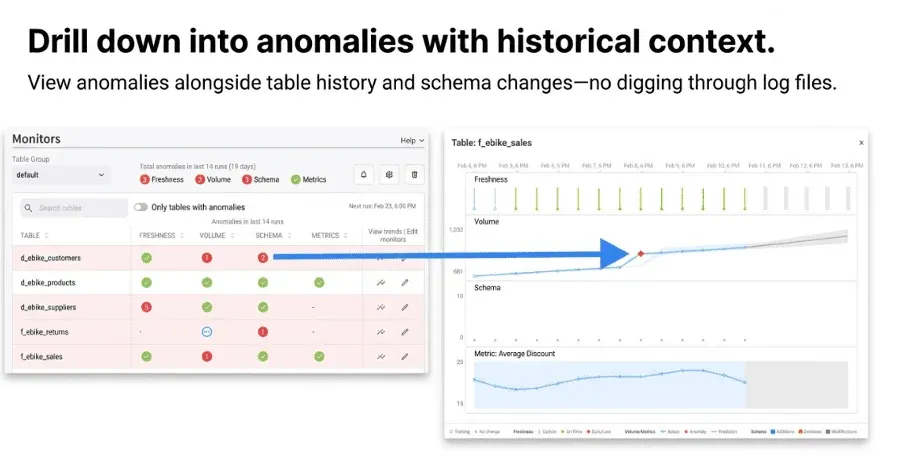
From the monitor results, you can dig into specific anomalies to see how big they are and what caused them. Did row counts drop by 10% or 90%? Did the schema change today or three days ago? This detail helps make monitoring useful rather than noisy alerts you learn to ignore.
The results also feed into TestGen’s broader quality scoring and dashboard capabilities, so monitoring anomalies don’t live in a silo — they connect to the bigger picture of your data estate’s health.
Why This Matters for Data Engineering Sanity
Let’s be direct about what this feature solves for you day-to-day:
You no longer have to manually check whether a nightly batch loaded correctly. You won’t have to wait for users to tell you a dashboard looks off. You don’t need to build and maintain a custom monitoring system or patch together Great Expectations configs and cron jobs. TestGen watches your data so you can focus on building. IT takes minutes to set up, comes with a great UI, and runs on-item for security.
The monitoring works inside your database. TestGen runs queries directly there instead of pulling data out. That means no data copies, no security issues, and no unexpected slowdowns.
Since monitoring is integrated with TestGen’s profiling, test generation, data catalog, and quality dashboards, an anomaly won’t leave you staring at a number alone. You get the full context in one place: the table’s history, column details, and quality test results all in one place.
The Pricing Story: Flat $100 — No Table Tax. Finally, Something That Makes Sense
Here’s something refreshing for teams who have checked prices for other data observability tools and felt sticker shock.
DataKitchen’s Enterprise version of TestGen uses a flat-rate, predictable pricing model: $100 per month, per user, per database connection — and that’s it. Unlimited tables. Unlimited data volume. All features included.
This pricing rejects the “per-table tax” common in data observability. Many vendors charge based on the number of tables you monitor, so the more data you want to protect, the more you pay. That forces teams to pick and choose which tables to watch, hoping they’re right. That’s the opposite of how monitoring should work.
With TestGen’s pricing, there’s no reason to leave any tables unmonitored. You can cover your entire data estate — every table in every schema — without your bill growing out of control. A typical mid-size data team pays just a fraction of what similar closed-source, VC-backed platforms charge for the same coverage.
And if you want to start for free? The open-source version of TestGen is Apache 2.0 licensed and fully functional for individual users. You get one user, one database connection, and the complete feature set running locally or in your own Kubernetes or Docker environment. There’s no feature-gated free tier that forces you to upgrade to the paid plan. It’s a genuine open-source product.
Security and privacy are top priorities for teams adopting new data tools, especially in regulated industries. TestGen securely manages credentials, following best practices for encryption at rest and in transit. Your database credentials are encrypted and never shared outside your configured environment. Since TestGen runs queries directly inside your database and does not move or extract your raw data, your sensitive information stays protected behind your own firewall. TestGen is built with privacy and compliance in mind, making it suitable for environments with strict regulatory requirements. Audit logs and role-based access controls help you monitor and manage who can access monitoring features and data.
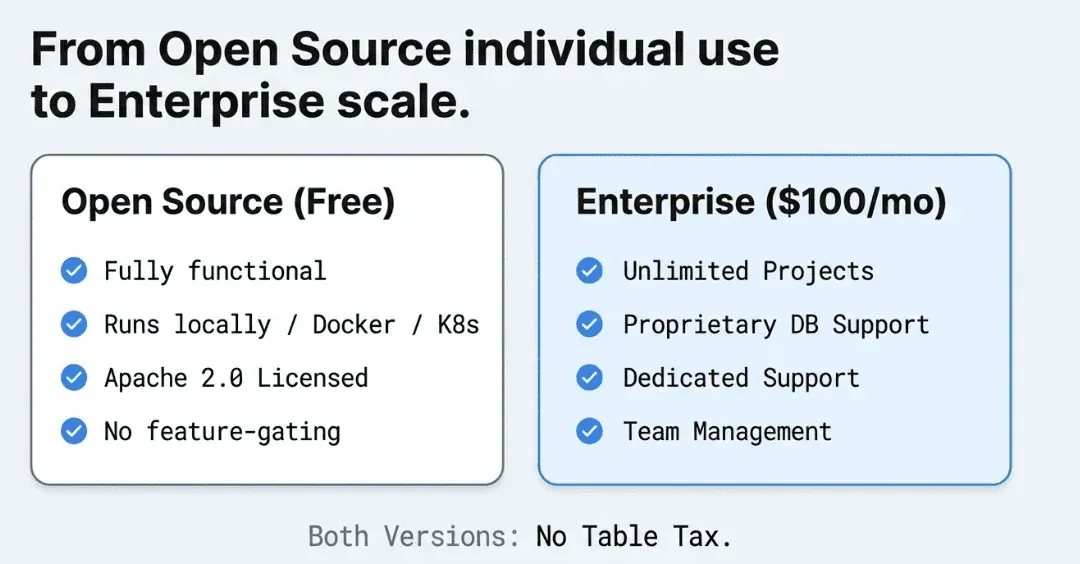
For teams, the Enterprise tier adds unlimited projects, support for proprietary databases, DataKitchen’s dedicated support, and the latest releases — still at that straightforward $100/user/connection rate.
DataKitchen is a profitable, independent company, which means we are not racing to satisfy VC investors by jacking up prices or sunsetting features on a whim. That stability matters when you’re building production monitoring infrastructure.
Getting Started
If you’re ready to stop being the last to know about data problems, TestGen’s monitoring is worth exploring.
- Install the open-source version for free: info.datakitchen.io/install-dataops-data-quality-testgen-today
- Review the monitoring documentation: [https://docs.datakitchen.io/testgen/monitor-tables/)
- See the full pricing details: datakitchen.io/pricing
- Request a demo: datakitchen.io/request-a-demo
- Release Note: Version 5.0.2

The days of learning about data problems from an angry business analyst should be over. With TestGen’s table monitoring, you’re watching everything automatically and continuously — all for a price your boss will appreciate.
Frequently Asked Questions, TLDR;
What is the Summary of this article, TLDR??
- Data engineers are always the last to know when something breaks — TestGen’s new table monitoring flips that script with continuous, automated observation of your tables in production.
- Four critical dimensions monitored automatically — freshness, volume, schema changes, and data drift catch the most common pipeline failures before downstream users do.
- ML-powered time series anomaly detection is built in — TestGen learns the natural rhythms of your data and flags real problems, reducing false positives without requiring you to set a single threshold.
- No SQL, Python, or YAML required — monitoring runs in-database, generates automatically from your data’s own history, and feeds directly into TestGen’s quality dashboards.
- Enterprise-grade monitoring at a fraction of the cost — DataKitchen’s flat-rate pricing ($100/user/connection, unlimited tables) eliminates the “per-table tax” that forces other teams to leave most of their data estate unwatched.
How Does Enterprise TestGen Compare To Other Data Observability Vendors?
Short answer: 90% of the features at 5% of the price
The data observability market is crowded, and for good reason — monitoring your data in production is no longer optional. But when you dig into how the major vendors actually work and what they cost, the differences become stark. Here’s how TestGen compares to the most common names data engineers encounter.
Monte Carlo Data
Monte Carlo is the market leader and a genuinely capable platform. It uses ML to monitor freshness, volume, schema, and field-level anomalies across your entire data stack, and its lineage features are among the best in the industry. If you need end-to-end pipeline observability with deep BI integration out of the box, Monte Carlo delivers.
The catch is the price. Monte Carlo runs a credit-based pricing model — $0.25 per credit on the Scale tier and $0.45 per credit on the Enterprise tier, with each monitor consuming credits at varying rates. Teams running thousands of monitors across large data estates regularly land in the $100,000–$300,000+ annual range. That per-monitor structure is a classic example of the per-table tax: the more of your data estate you want to protect, the faster the bill climbs. TestGen covers unlimited tables for $100/user/connection — full stop.
Bigeye
Bigeye offers a library of over 70 data quality monitoring metrics, along with ML-powered anomaly detection and granular root-cause analysis, to proactively detect and resolve data issues before they impact the business. It handles freshness, volume, schema changes, and distribution anomalies with a relatively quick setup. For teams wanting deep column-level monitoring with lineage-aware alerting, it’s a solid product.
Pricing, however, is entirely custom — Bigeye doesn’t publish rates or routes, and all inquiries go through sales. Users frequently report that costs scale significantly with table counts, putting it squarely in the expensive-per-table camp. There’s no open source option, and you’re fully dependent on their cloud infrastructure.
Anomalo
Anomalo uses a tiered approach: low-cost metadata-based observability for all tables, AI-based anomaly detection using unsupervised machine learning for deeper value monitoring, and user-defined validation rules for the most critical tables. The unsupervised ML is genuinely impressive — Anomalo takes a sample of 10,000 records from the most recent data and compares them against previous days to learn patterns and identify unexpected changes.
The tradeoff? Anomalo users report a non-transparent pricing structure, and it’s architected primarily for large enterprises with mature data stacks — reviewers note it assumes an established infrastructure and can be a poor fit for teams still building their data architecture. The per-table pricing model also means that full-warehouse coverage gets expensive fast. TestGen’s flat-rate model removes that calculus entirely.
Soda
Soda takes a different philosophical approach from the others — and to their credit, they recently published transparent pricing, which is refreshing in a space full of “contact sales” black boxes.
Here’s how it actually breaks down. Soda’s Free plan is $0/month but caps you at 3 production datasets — barely enough to evaluate the product. The Team plan is $750/month and includes 20 datasets; each additional dataset costs $8/month. The Enterprise plan is custom pricing, negotiated through sales.
The math gets uncomfortable fast for any real-world data team. A team monitoring 100 tables pays $750 + (80 × $8) = $1,390/month, or $16,680/year. Scale that to 500 tables — common for a mid-size organization — and you’re at $750 + (480 × $8) = $4,590/month, or $55,080/year. That per-dataset fee is a textbook per-table tax that discourages broad coverage. Teams end up cherry-picking their most important 50 or 100 tables and hoping the problems don’t come from somewhere else.
Functionally, Soda’s anomaly detection is threshold-based rather than behavior-based ML, meaning it works best when you already know what “good data” looks like and can predefine your checks in SodaCL, Soda’s YAML-based check language. If you enjoy writing data quality checks as code and want tight integration with your CI/CD pipeline, Soda is a reasonable tool. But if you want ML-based time series anomaly detection that learns your data’s natural rhythms automatically — without writing a single check — that’s TestGen’s territory.
Compare that to TestGen: 5 users and 3 database connections come to $800/month ($9,600/year) for unlimited tables. At 500 tables, TestGen costs roughly 83% less than Soda ‘s Team plan — while including ML-based anomaly detection that Soda’s threshold-based approach simply doesn’t match.
All the other vendors … same story TOO EXPENSIVE
There are many vendors offering commercial observability and data quality. Check out our blog: </the-2026-data-quality-and-data-observability-commercial-software-landscape/.>
Where TestGen Wins
The honest summary is that Monte Carlo, Bigeye, and Anomalo are all capable platforms — but they’re built for enterprises with large budgets and an appetite for opaque pricing negotiations. Soda is more transparent on price but still charges per dataset and requires significantly more upfront configuration work.
TestGen occupies a distinct position: it combines genuine ML-based time-series anomaly detection — the same capability competitors charge a premium for — with automated generation of over 120 data quality tests, in-database execution that never copies your data, a full data catalog, quality scoring dashboards, and unlimited table coverage. All at $100/user/connection with a fully functional open source version available free under an Apache 2.0 license.
The per-table tax that drives up costs at every other vendor simply doesn’t exist in TestGen’s pricing model. A mid-size team that would pay $55,000–$300,000+ annually with a competing observability vendor can achieve the same coverage with TestGen for a fraction of that cost … with full transparency into how the platform works.