The same “pets vs cattle” philosophy that transformed Devops explains exactly when to invest in data quality dashboards versus when to rely on automated anomaly detection—and why you need both.

The same “pets vs cattle” philosophy that transformed Devops explains exactly when to invest in data quality dashboards versus when to rely on automated anomaly detection—and why you need both.

Confess your data sins. Find redemption. Maybe even laugh about it.
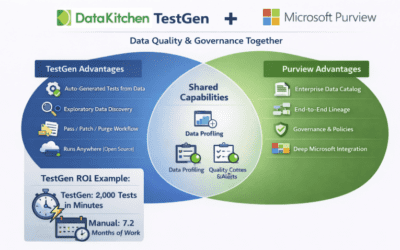
DataKitchen’s TestGen and Microsoft’s Purview complement each other: Purview serves as the governance and catalog “source of truth,” while TestGen is the deep, automated data-quality and testing engine that writes thousands of data quality tests in seconds.

The five organizational problems are systemic failures of culture and structure that lead to warring teams, a corrosive blame culture, “data blindness” regarding pipelines, a short-term project mindset, and the chaotic scattering of business logic. Learn how to identify and fix below.

A Consultant’s Guide to Using DataKitchen’s Open Source Data Quality and Data Observability Tools: How to Find New Clients, Strengthen Relationships, and Deliver Better Results
Confess your data sins. Find redemption. Maybe even laugh about it.

In A Masterclass In The Six Types of Data Quality Dashboards, you’ll learn how to build all six powerful data quality dashboard types in under an hour using 100% open source tools.

Many professionals would rather *not* know about data quality problems. Isn’t finding and fixing issues the job? Yes … but organizational dynamics around data errors punish the messenger. Here’s how to fix that dynamic.

What to do when your team doesn’t care about data errors in production? The “deploy and forget” ostrich mindset is one of the most corrosive patterns in data engineering teams. Here’s How to Change That.

How does a data team prevent poor data from poisoning AI when they have piles of raw and imperfect data?
 “We Just Eyeball Row Counts and Pray”
“We Just Eyeball Row Counts and Pray”
DataOps Data Quality TestGen:
Simple, Fast, Generative Data Quality Testing, Execution, and Scoring.
[Open Source, Enterprise]

DataOps Observability:
Monitor every data pipeline, from source to customer value, & find problems fast
[Open Source, Enterprise]

DataOps Automation:
Orchestrate and automate your data toolchain with few errors and a high rate of change.
[Enterprise]

DataOps Consulting, Coaching, and Transformation
Commercial Data & Analytics Platform for Pharma
Data Production Teams
Data Science/AI
Data Engineering
Data Quality
Business Analytics
Data Products
Data Mesh
Data Contracts
ModelOps / MLOps
DataGovOps
Self-Service Operations
Data Quality Assessments
Data Quality Testing
Data Observability
Data Orchestration


Monitor every Data Journey in an enterprise, from source to customer value, in development and production.
Simple, Fast Data Quality Test Generation and Execution. Your Data Journey starts with verifying that you can trust your data.
Orchestrate and automate your data toolchain to deliver insight with few errors and a high rate of change.