Transform data engineering from a high-stress, “hero saves the day” kind of job into something systematic and predictable that actually scales as your team and business grow. Stop babysitting pipelines: SQL & ELT the FITT Way.
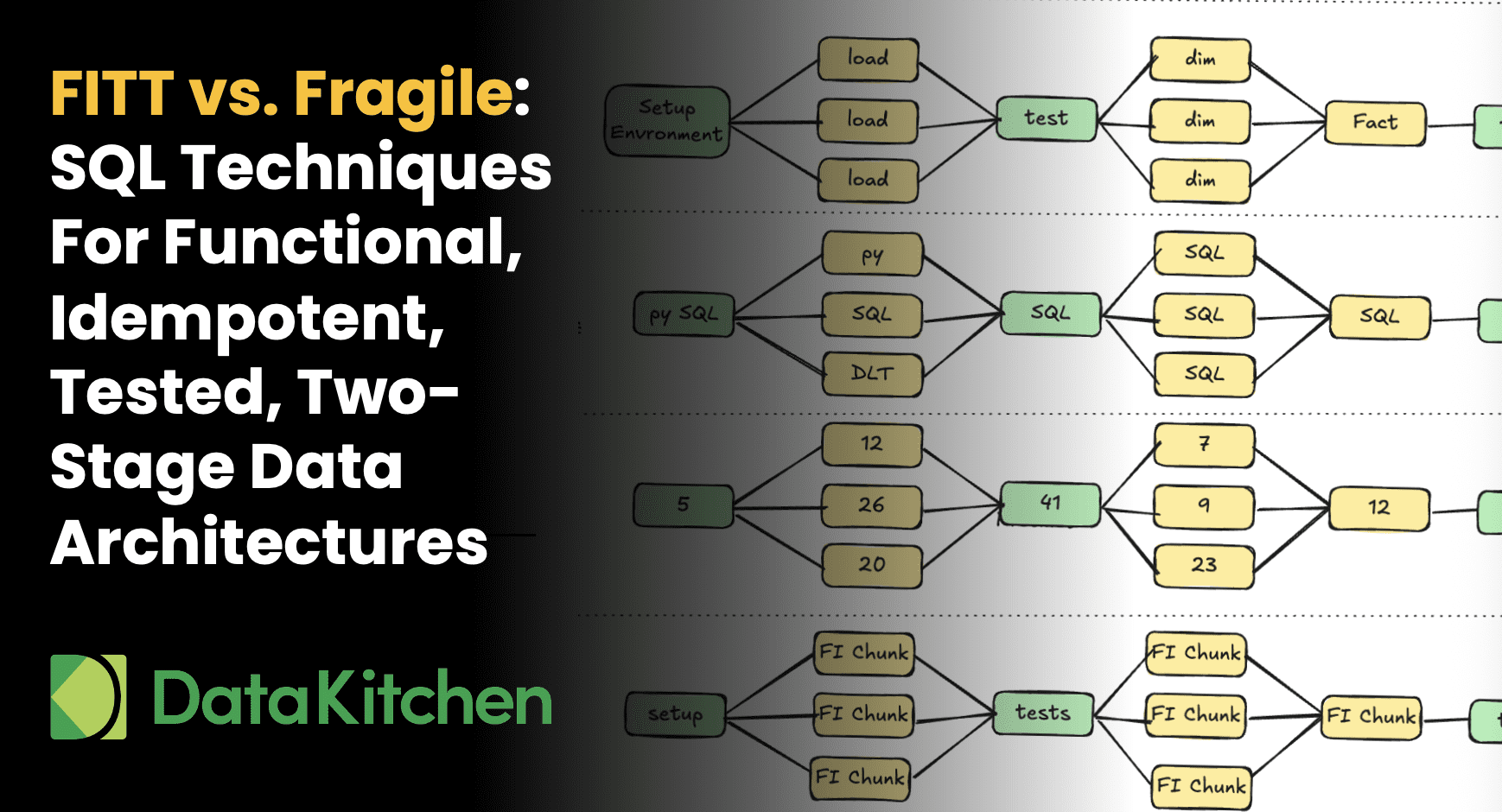
Transform data engineering from a high-stress, “hero saves the day” kind of job into something systematic and predictable that actually scales as your team and business grow. Stop babysitting pipelines: SQL & ELT the FITT Way.

Most data architectures are designed to maximize data vendor revenues, not data team productivity. Let us show you how a Functional, Idempotent, Tested, Two-Stage (FITT) data architecture can deliver better productivity, reliability, and happiness.
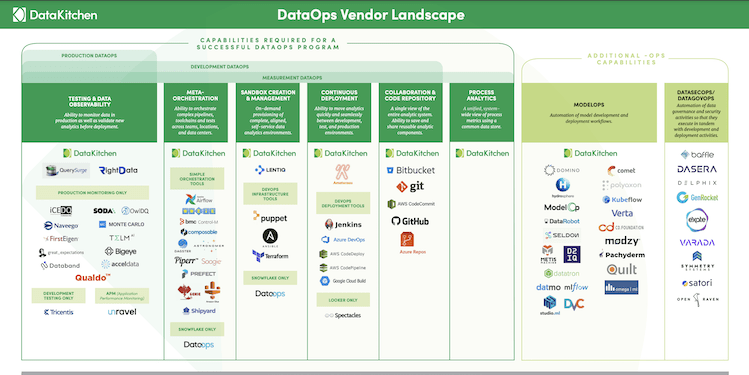
Download the 2021 DataOps Vendor Landscape here. Read the complete blog below for a more detailed description of the vendors and their capabilities. DataOps is a hot topic in 2021. This is not surprising given that DataOps enables enterprise data teams to generate...

The cacophony of tools and mission-critical deliverables are the reason behind the high complexity of modern-day data organizations. Data groups include a wide range of roles and functions that are intricately woven together by their “Data”. Teams include data...

We often hear people say that DataOps is just automating the data pipeline — using orchestration to execute directed acyclic graphs (DAGs). Enterprises may already use orchestration tools (Airflow, Control-M, etc.) and mistakenly conclude that they have DataOps...
 The 2026 Open Source Data Profiling Software Landscape
The 2026 Open Source Data Profiling Software Landscape
DataOps Data Quality TestGen:
Simple, Fast, Generative Data Quality Testing, Execution, and Scoring.
[Open Source, Enterprise]

DataOps Observability:
Monitor every data pipeline, from source to customer value, & find problems fast
[Open Source, Enterprise]

DataOps Automation:
Orchestrate and automate your data toolchain with few errors and a high rate of change.
[Enterprise]

DataOps Consulting, Coaching, and Transformation
Commercial Data & Analytics Platform for Pharma
Data Production Teams
Data Science/AI
Data Engineering
Data Quality
Business Analytics
Data Products
Data Mesh
Data Contracts
ModelOps / MLOps
DataGovOps
Self-Service Operations
Data Quality Assessments
Data Quality Testing
Data Observability
Data Orchestration


Monitor every Data Journey in an enterprise, from source to customer value, in development and production.
Simple, Fast Data Quality Test Generation and Execution. Your Data Journey starts with verifying that you can trust your data.
Orchestrate and automate your data toolchain to deliver insight with few errors and a high rate of change.