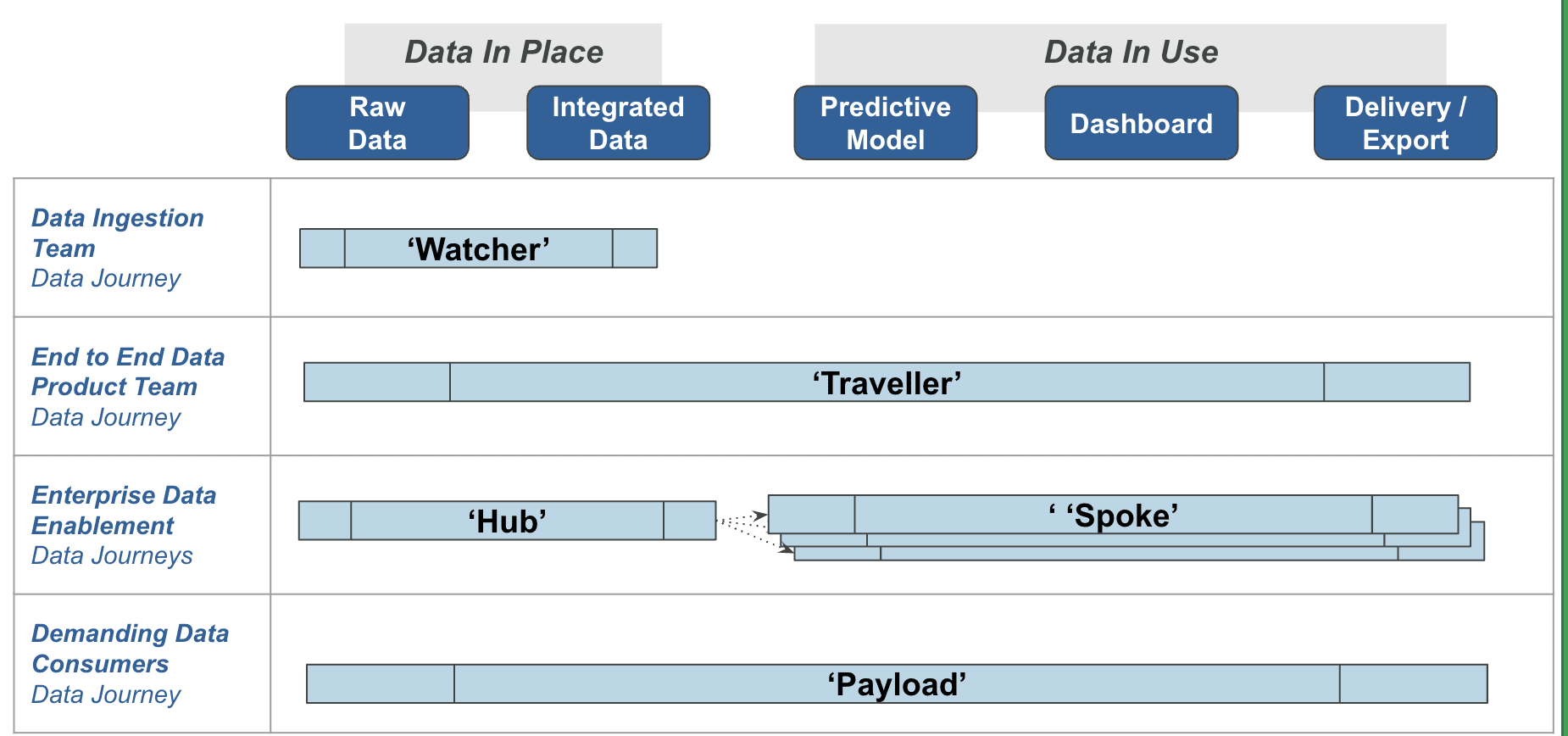
In the rapidly evolving landscape of data management and analytics, data teams face various challenges ranging from data ingestion to end-to-end observability. This comprehensive article delves into the complexities encountered by various types of data teams—Data Ingestion Teams, End-to-End Data Product Teams, and Enterprise Data Enablement Teams—to name a few. It explores why DataKitchen’s ‘Data Journeys’ capability can solve these challenges. Whether the Data Ingestion Team struggles with fragmented database ownership and volatile data environments or the End-to-End Data Product Team grapples with real-time data observability issues, the article provides actionable recommendations. It also addresses the unique demands of specialized Data Consumers who require personalized data tracking. The article illuminates how Data Journeys can enhance data governance, improve operational efficiency, and ultimately lead to organizational success by thoroughly examining different Data Journey types— ‘Watcher,’ ‘Traveler,’ ‘Hub & Spoke,’ and ‘Payload.‘
What’s a Data Journey?
Data Journeys track and monitor all levels of the data stack, from data to tools to code to tests across all critical dimensions. A Data Journey supplies real-time statuses and alerts on start times, processing durations, test results, and infrastructure events, among other metrics. With this information, data teams can know if everything ran on time and without errors and immediately identify the parts that didn’t. Journeys provide a context for understanding and observing complex elements across and down a data analytic system. You can learn more about the principles and ideas behind the Data Journey in the Data Journey Manifesto, Data Journey 101, and the Five Pillars of Data Journeys.
The Data Ingestion Team Data Observability Challenges
The Data Ingestion Team, armed with various tools, including databases, pipeline utilities, and ETL/ELT frameworks, faces complex challenges that significantly impede operational efficiency and data reliability. One of the most pressing issues is the ownership of databases by multiple data teams, each with its governance protocols, leading to a volatile data environment rife with inconsistencies and errors. This fragmented ownership model complicates data updates and results in a constant influx of erroneous data, making it exceedingly difficult to maintain data quality. The team finds itself in a Sisyphean struggle to deliver trusted and validated data, only to have it compromised again by uncoordinated changes from various stakeholders.

Moreover, the team grapples with an overwhelming number of ever-changing data objects it does not control, making it virtually impossible to answer even basic questions about the data they manage. This lack of control is exacerbated by many people and/or automated data ingestion processes introducing changes to the data. This creates a chaotic data landscape where accountability is elusive and data integrity is compromised. The team is caught in a vicious cycle: the data team is responsible for data health but lacks any visibility into its current state.
How ‘Watcher’ Data Journeys Help Data Ingestion Teams
Two types of ‘Watcher’ Data Journeys (DJs) offer a transformative approach to addressing Data Ingestion Teams’ challenges. It benefits teams overwhelmed by many ever-changing data objects. This type of Data Journey provides a continuous monitoring framework that can be augmented by data quality checks (such as those automatically generated by DataKitchen’s TestGen product), ensuring the quality of datasets and tables. Doing so offers real-time insights into data quality, enabling the team to identify and rectify erroneous data before it propagates through the pipeline. This proactive approach replaces the reactive firefighting that often characterizes data ingestion efforts, enhancing data reliability and operational efficiency.
It also addresses the need for managing data objects that are frequently refreshed. In this model, data objects are treated like “cattle, not pets,” meaning they are cared for interchangeably and not individually managed, which is ideal for high-throughput, scalable data pipelines. The Watcher comprehensive view from a data perspective encompassing datasets, tables, schema, test results, anomalies, and profile information. Additionally, it allows for implementing rules and alerts specific to each DJ instance, thereby automating the governance process and ensuring data integrity. By adopting these ‘Watcher’ Data Journeys, Data Ingestion Teams can significantly improve their ability to manage complex, dynamic data landscapes, making them more agile and responsive to the ever-evolving needs of the business.
The End-to-End Data Product Team Data Observability Challenges
The End-to-End Data Product Team is confronted with a particularly vexing issue related to data observability that has far-reaching implications for internal operations and customer relations. The team often discovers data-related problems at the most inopportune moments—right in front of their customers. This erodes customer trust and puts the team in a reactive stance, scrambling to identify and resolve issues that should have been caught much earlier in the data lifecycle. The uncertainty of not knowing where the next data issue will emerge creates a climate of apprehension, making it difficult to assure stakeholders about the reliability of their data products. Additionally, these End-to-End Data Product Teams are often responsible for both the execution and development of these processes. The team’s excess time spent fighting fires takes away valuable time needed to deliver new business solutions.

Compounding this challenge is the tiresome game of “who’s to blame” that ensues whenever a data failure is identified. The lack of clear data observability and governance mechanisms makes it exceedingly difficult to pinpoint the root cause of failures, leading to internal friction and a waste of valuable resources. This blame game hampers productivity and creates a toxic work environment that can stifle innovation and collaboration. Without a robust data observability framework that provides real-time insights into data lineage, quality, and operational metrics, the End-to-End Data Product Team will continue grappling with these challenges, putting their reputation and customer satisfaction at risk.
How ‘Traveler’ Data Journeys Help End-to-End Data Product Teams
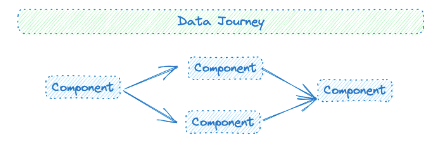
The adoption of ‘The Traveller’ Data Journeys can be a game-changer for the Data Product Team, particularly in addressing data observability challenges. This Data Journey is designed to handle complex, multi-tool data ecosystems with multiple components acting upon the data, which aligns well with the end-to-end team’s use case. ‘The Traveller’ provides a holistic view of the data as it moves through various stages and tools, enabling “across and down” problem identification. This means the team can quickly pinpoint issues horizontally across different components (Is the order of operations correct? Did each technology start and end successfully and on time?) and technologies and vertically within a specific stage of the data pipeline (did this step in the process produce the expected output? Did it use the expected amount of resources?). The Traveler’s real-time alerts and analytics features ensure that any anomalies or issues are immediately flagged, allowing for rapid intervention before these problems reach the customer.
Moreover, ‘The Traveler’ type Data Journey is built for fast integration with existing tools and systems, minimizing the friction often associated with implementing new data governance solutions. It also incorporates data tests to validate the quality and integrity of the data at various checkpoints, thereby reducing the uncertainty and apprehension associated with not knowing where the next data issue might arise. Providing a comprehensive suite of features, from alerts and analytics to fast integration and data tests, ‘The Traveler’ empowers the End-to-End Data Product Team to manage their data landscape proactively. This proactive approach eliminates the tiresome blame game and enables the team to focus on delivering high-quality data products, enhancing operational efficiency and customer satisfaction.
Enterprise Data Enablement Data Observability Challenges
The Enterprise Data Enablement is the Hub, and their linked ‘Insight Creators’ are the Spokes. Both teams face unique challenges from their pivotal role in the data supply chain. The customers of a Data Enablement Team are typically internal stakeholders who rely on data to create insight for various functions. These can include Data Scientists and Analysts, Business Units and Departments, Product Teams, and Spoke Teams. As the enablers of downstream data processes, they often find themselves at the crux of critical processing issues, particularly in the ‘last mile’ before data reaches the customers. This high-stakes position makes them a frequent target for blame when things go awry, as any hiccup in data quality or availability can have immediate and far-reaching consequences. This team is constantly under pressure to ensure that data is accurate and delivered on time, making them vulnerable to many issues that can arise in the final stages of data delivery.

This difficult situation is further exacerbated by a culture of finger-pointing, frustration, and poor productivity that permeates some organizations. When problems occur, the immediate response is often to identify a scapegoat rather than collaboratively seeking a solution, leading to internal strife and inefficiencies. This not only hampers the team’s ability to resolve issues quickly but also creates a toxic environment detrimental to innovation and long-term success. The lack of a unified, transparent approach to data observability and problem-solving means that issues are more likely to be passed down the line rather than addressed at their source, perpetuating a cycle of blame and inefficiency that undermines the team’s core mission of enabling robust, reliable, trusted data insight for their joint customers.
How ‘Hub & Spoke’ Data Journeys Lead To Organization Success
Enabling both ‘Data Enablement’ and ‘Insight Creators’ Data Journeys (DJs) can be a cornerstone for organizational success. The Hub & Spoke Data Journeys is the central nexus for monitoring data production and distribution, ensuring downstream customers have curated datasets and tables and produce insight correctly for their customers. The Hub Data Journey provides the raw data and adds value through a ‘contract. This contract is a blueprint for data quality and integrity, ensuring that downstream consumers—data scientists, business analysts, or other departments— operating as spoke Data Journeys can trust their data. The Hub DJ sets the stage for a producer/consumer relationship that is both robust and transparent.

On the other side of the equation, the Spoke Data Jounieys monitor the work of the Insight Creators. These Data Kourneys take the baton from the Hub, either adhering to the provided contract or operating independently based on specific needs. These are typically multi-tool data processes managed by independent teams that generate insights, analytics, or other data products and also require granular observability to ensure success. The Spoke DJs leverage the foundational work done by the Hub Team to create actionable insights that drive business decisions. This layered approach creates a virtuous cycle, where the Hub Team focuses on data quality, governance, and distribution, and the Spoke DJs focus on successful insight creation. These combined Data Journeys allow for specialization and depth in data management and utilization, leading to more accurate insights, better decision-making, and, ultimately, organizational success when insight is trusted, timely, and high quality.
Demanding Data Consumers Need Personalized Data Observability
Data and Analytics Teams face a unique set of challenges posed by some Demanding Data Consumers who require ‘personalized’ Data Observability. These critical customers are not content with generic status updates; they want real-time, granular insights into the status of ‘their data’ as it moves through the complex labyrinth of the data production process. This requires tracking specific data ‘payloads’ across many systems and tools, a technically demanding and resource-intensive task. To enable this, the data team must enable sophisticated tracking mechanisms that can follow these payloads through various stages of ingestion, transformation, and delivery, all while ensuring that they can communicate the status to the relevant data consumer.

The complexity is further heightened by the need for personalized monitoring and alerts tailored to each customer’s unique data processing payload status. This level of customization goes beyond the capabilities of most off-the-shelf data observability platforms and calls for a Data Journey Instance unique to each personalized customer payload. The data team must answer the ‘Where is My data’ question while maintaining operational efficiency and data quality to ensure customer satisfaction and maintain the team’s credibility.
How ‘Payload’ Data Journeys Answer The ‘Where is My Data’ Question Quickly
The introduction of ‘Payload’ Data Journeys (DJs) can be a game-changing solution for Data and Analytics Teams grappling with the challenge of providing personalized data observability to demanding Data Consumers. A ‘Payload’ DJ is specifically designed to track the status of individual data payloads as they traverse through multi-component and multi-dataset journeys. The Payload DJ offers a granular view of each payload’s status across various systems and tools using real-time tracking mechanisms. It can send targeted alerts to the specific ‘customer’ or stakeholder concerned with that data payload. This ensures that customers are immediately notified of any changes, delays, or issues affecting their data, answering the perennial questions of “Where is my data and what is its status?” in real-time.
For demanding Data Consumers, the ‘Payload’ DJ serves as a personalized view that provides transparency into the status of their specific data payloads. This enhances customer satisfaction and builds trust, as consumers can independently verify their data’s status, quality, and integrity at any moment. The real-time alerts act as an additional layer of assurance, notifying customers of any critical events or milestones in their data journey. By adopting ‘Payload’ DJs, Data and Analytics Teams can effectively meet the high expectations of demanding Data Consumers, offering them the level of personalized data observability they require.
Conclusion
We looked at the multifaceted world of Data Teams and types of Data Journeys, shedding light on the hurdles and solutions in enabling data observability across various team structures—from Data Ingestion Teams to End-to-End Data Product Teams and Enterprise Data Enablement Teams. We explored how specialized Data Journeys like ‘Watcher,’ ‘Traveler,’ ‘Hub & Spoke, or ‘Payload’ can revolutionize these teams’ operations, enhancing data reliability, operational efficiency, and customer satisfaction. Whether you grapple with fragmented data ownership, the blame game in data failures, or the demands of personalized data observability, this article offers actionable insights to guide your team toward data maturity and organizational success.
The good news is that data teams do not have to develop these Data Journey capabilities themselves. DataKitchen’s DataOps Observability can deliver these Data Journeys with little to no development and few, if any, changes to production processes.
DataOps TestGen adds another layer of security by providing the ability to automatically generate a suite of standard data tests – with no development – which is then shared with DataOps Observability for a unified view. This synergistic combination of products ensures that data engineers have a panoramic view of their data environment, helping them anticipate issues, make informed decisions, and ultimately deliver more value to the end-users.



