
DataKitchen’s Data Quality Testgen Found 18 Potential Data Quality Issues In A Few Minutes (Including Install Time) On Data.Boston.Gov Building Permit Data!
Imagine a free tool that you can point at any dataset and find actionable data quality issues immediately! It sure beats having your data consumers tell you about problems they find when you are trying to enjoy your weekend. There is such a tool: DataKitchen’s Data Quality TestGen. I took TestGen for a test drive on ~600k rows of Boston City data and found 18 data quality hygiene issues in a few minutes.
First, I grabbed building permit data from Approved Building Permits from data.boston.gov and used Superset to load it into a Postgres DB. Second, I installed TestGen, which took just a few minutes. Then, I started profiling, which completed in 3 minutes and 16 seconds on 646,899 records containing 23 columns (14,878,677 data points). TestGen finds potential data quality issues during the profiling process! Here is a summary of the data hygiene issues that TestGen found:

Try TestGen on your data to have your data suppliers improve their data and alert your users to potential issues. Here are TestGen’s install instructions.
The one “Definite” finding was non-standard blank values in the comment column. It turns out that in this data set, there were four ways to indicate no comment for the permit: [NULL], “?”, “none”, and “tbd”. You can see the frequencies from this screenshot:

What else did TestGen find? It seems like the city should be known for a permit, so I took at the findings on the city column:

Good news: Only 0.03% of the records had no city. Bad news: 185 permits were missing the city. This could be an issue for a quality circle or a data steward to fix.
Looking further at the city column and pressing the “Source Data” button for the “Similar Values Match When Standardized” Hygiene Issue, I see that some names have an initial capital and others are all uppercase. Are two systems feeding this dataset? There are a few slashes that worked their way into the data, too:
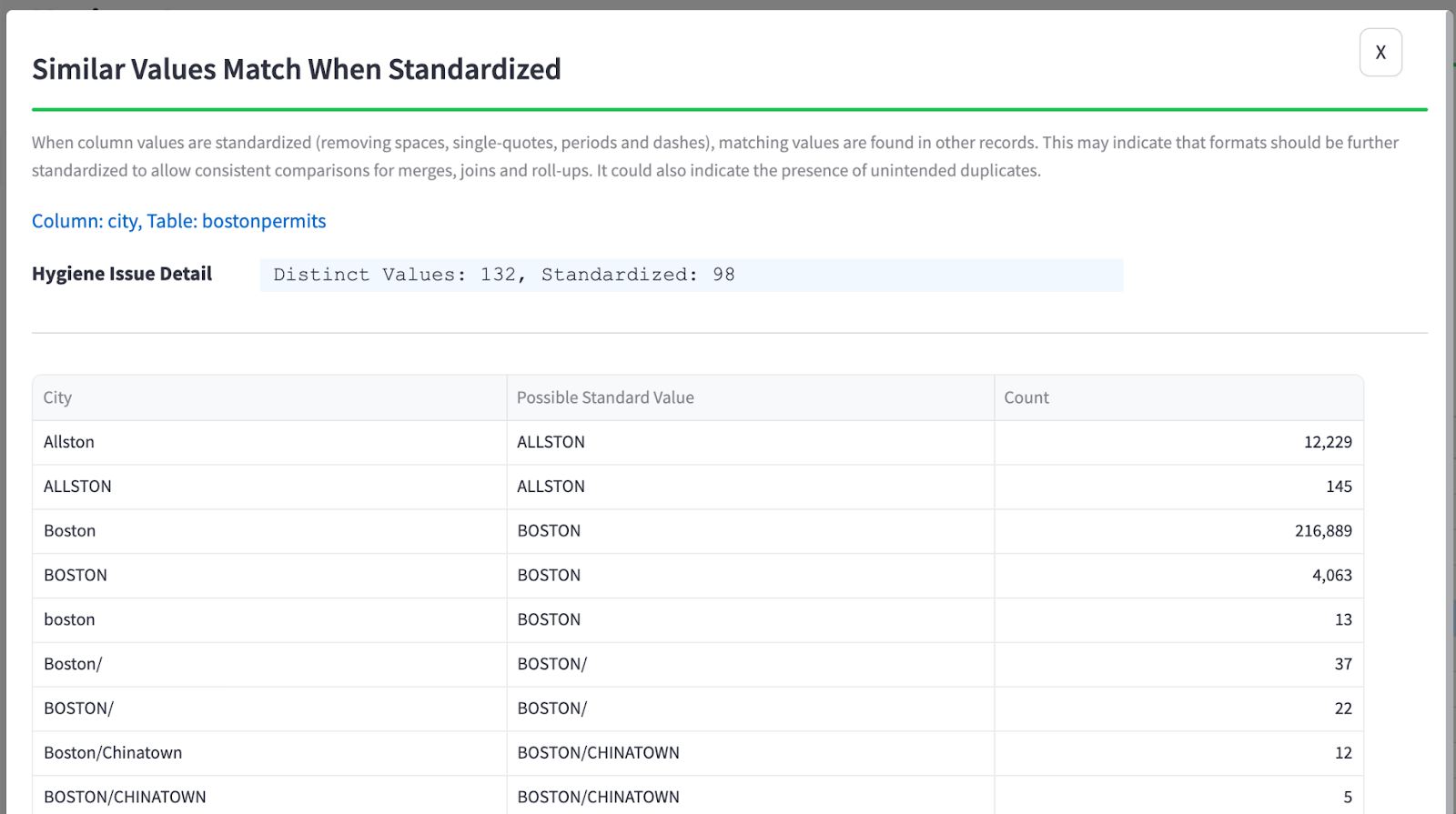
Zooming in on some values:

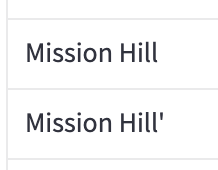
A little more scrolling shows that a stray quote worked its way in there three times.

Zooming in on the values:
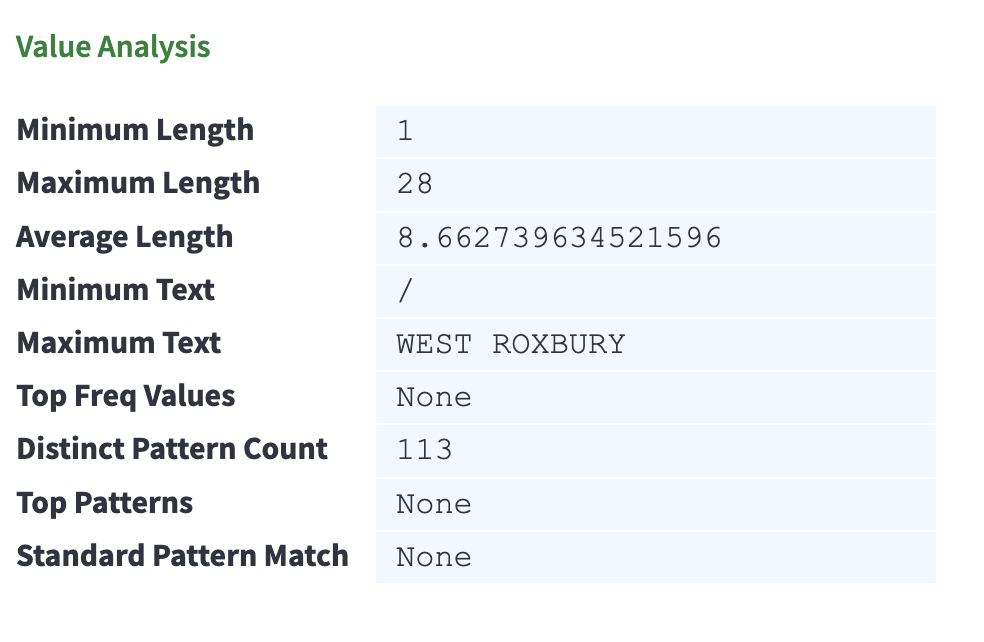
Switching to the profiling results on the city column and looking at the “Value Analysis” section, I observed that while the Maximum Text looked good, “WEST ROXBURY”, I did not recognize the city with the Minimum Text, “/”.
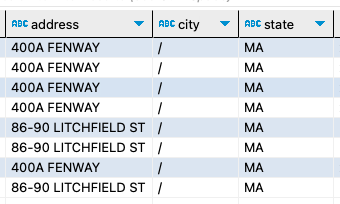
A quick query revealed that there were 8 records with a city of “/”
select * from bostonpermits where length(city) < 5;
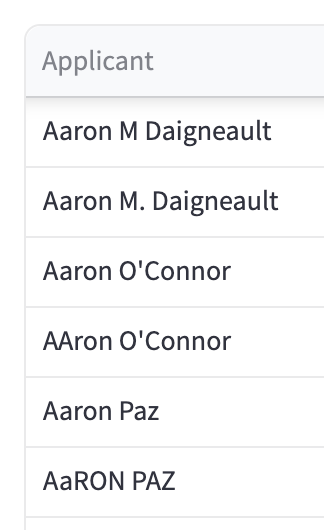
The applicant field had similar issues:

Shouldn’t every permit have an applicant? 1.47% blank is low, but that is still 9,365 permits with no applicant. Also, if one wanted to analyze applicants, the field would benefit from some standardization.

Zooming in on the values:
Twelve other data hygiene issues were flagged and are not discussed in this article. You can try this experiment on your computer and see what you think. Better yet, try it on your own data.
My next steps were to generate data quality tests (this took about 2 seconds). These tests can be run in production to quickly catch errors on new batches of Boston permit data. To benchmark the testing operation, I ran the tests on the existing dataset, which took 23 seconds.
Here was my setup:
- Data Quality Tool: DataKitchen DataOps TestGen v2.7.0 open-source edition
- Superset running in docker
- Postres SQL running in docker
- SQL Editor: DBeaver
- Hardware: MacBook Pro, Processor 2.2 GHz 6-Core Intel Core i7, Memory 16 GB
Software cost: $0
I invite you to try TestGen on your data to have your data suppliers improve their data and alert your users to potential issues. Here are TestGen’s install instructions.







