
We often hear people say that DataOps is just automating the data pipeline — using orchestration to execute directed acyclic graphs (DAGs). Enterprises may already use orchestration tools (Airflow, Control-M, etc.) and mistakenly conclude that they have DataOps covered. While it is true that automated orchestration is a critically important element of DataOps, the methodology is about much more than orchestration.
What is Orchestration?
Many data professionals spend the majority of their time on inefficient manual processes and fire drills. They could do amazing things, but not while held back by bureaucratic processes. An organization is not going to surpass competitors and overcome obstacles while its highly trained data scientists are hand editing CSV files. The data team can free itself from the inefficient and monotonous (albeit necessary) parts of the data job using an automation technology called orchestration.
Think of your analytics development and data operations workflows as a series of steps that can be represented by a set of directed acyclic graphs (DAGs). Each node in the DAG represents a step in your process. For example, data cleaning, ETL, running a model, or even provisioning cloud infrastructure. You may execute these steps manually today. An orchestration tool runs a sequence of steps for you under automated control. You need only push a button (or schedule a job) for the orchestration tool to progress through the series of steps that you have defined. Steps can be run serially, in parallel or conditionally.
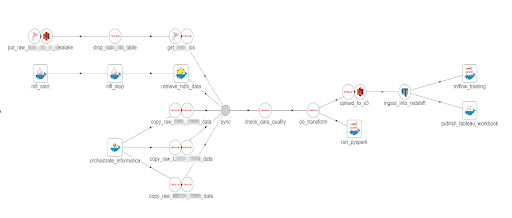
Figure 1: The set of steps that produce analytics represented as a directed acyclic graph (DAG)
There are numerous data pipeline orchestration tools that manage processes like ingesting, cleaning, ETL, and publishing data. There are also DevOps tools that focus on orchestrating development activities like spinning up a development environment. For examples of these tools, check out Paolo Di Tommaso’s list of awesome data pipeline and build automation tools. DataOps doesn’t replace these tools; it works alongside them. The typical enterprise deploys analytics using numerous data platforms, tools, languages and workflows. DataOps unifies this cacophony into coherent pipelines. In DataOps, orchestration must automate both the data pipeline (“Value Pipeline”) and the analytics development pipeline (“Innovation Pipeline”). If you observe organizational workflows, staffing and the activities of self-service data users, you’ll likely see that these two major pipelines are actually comprised of numerous and myriad smaller pipelines flowing in every direction. However, to keep it simple, we’ll speak of the Value and Innovation Pipelines in broad terms.
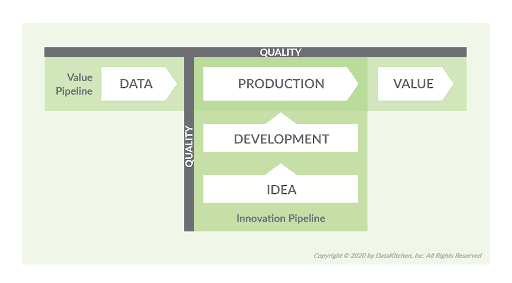 Figure 2: DataOps must orchestrate both the Value and Innovation Pipelines – data operations and analytics development.
Figure 2: DataOps must orchestrate both the Value and Innovation Pipelines – data operations and analytics development.
Value Pipeline Orchestration
The Value Pipeline extracts value from data. Data enters the pipeline and progresses through a series of stages – access, transforms, models, visualizations, and reports. When data exits the pipeline, in the form of useful analytics, value is created for the organization.
In most enterprises, the Value Pipeline is not one DAG; it is actually a DAG of DAGs. The figure below shows various groups within the organization delivering value to customers. Each group uses its preferred tools. The toolchain may include one or many orchestration tools. DataOps complements these underlying tools through meta-orchestration – orchestrating the DAG of DAGs. DataOps embraces and harmonizes the heterogeneous tools environment typical of most data organizations.
Figure 3: DataOps orchestrates the DAG of DAGs that is your data pipeline
Innovation Pipeline Orchestration
It’s not enough to only apply orchestration to the data operations pipeline. DataOps also orchestrates the Innovation Pipeline, which seeks to enhance and extend analytics by implementing new ideas that yield analytic insights. It is essentially the new analytics development processes and workflows. DataOps orchestrates the Innovation Pipeline based on the DevOps model of continuous deployment. As shown in the figure below, each team in the data organizations that produces analytics has its own workflow processes that reflect its unique structure. This includes self-service users who are both consumers and producers of analytics. Like the data pipeline, the Innovation Pipeline is not one DAG; it is a DAG of DAGs.
As mentioned previously, each DAG orchestration relies upon its preferred tools. DataOps meta-orchestration doesn’t impose any restrictions on the tools that may be chosen for any given task.
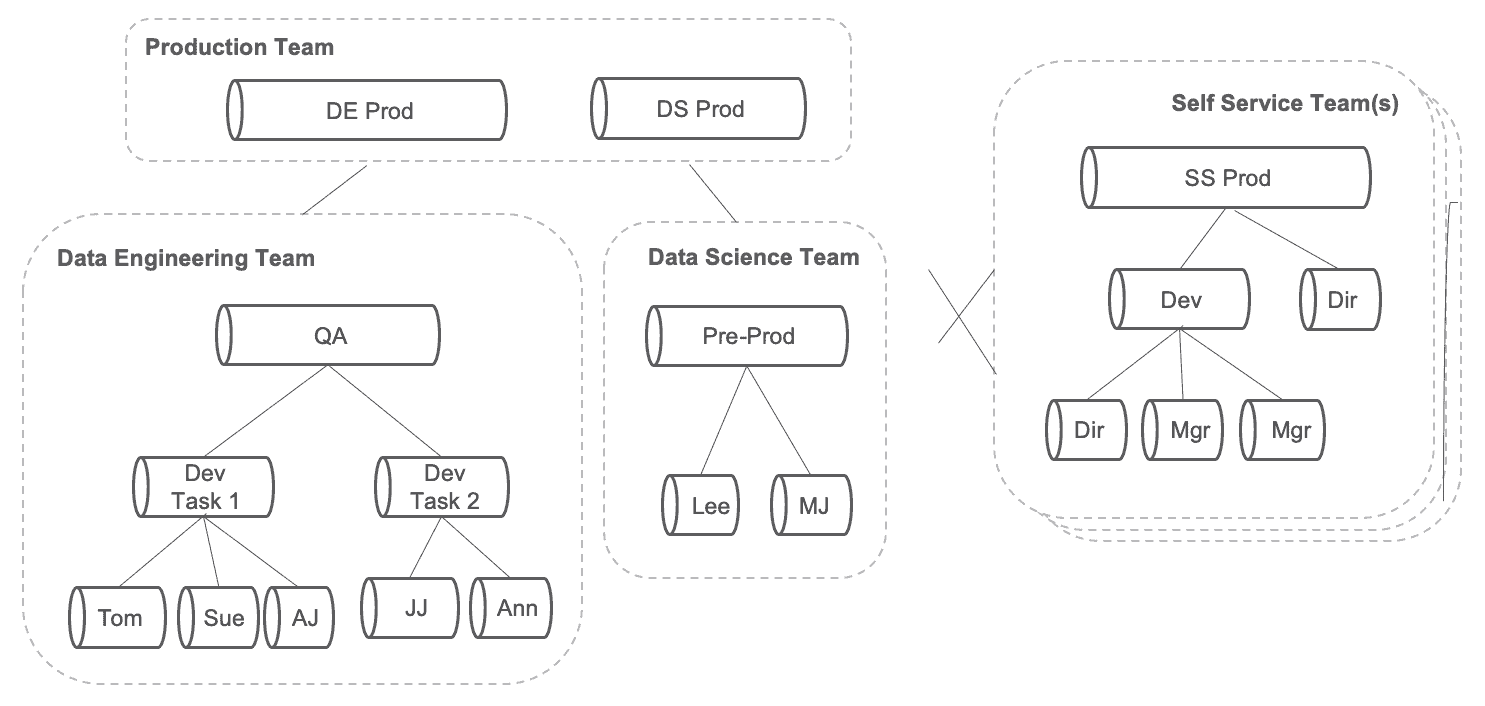
Figure 4: The development of new analytics by various teams and self-service users is a DAG of DAGs that flow into production.
Orchestration Alone is Not Enough
Automated orchestration is a key part of an overall DataOps initiative, but by itself, it can’t fully deliver the benefits of DataOps. For example, data operations could be fully automated, but without tests and process controls, data and code errors could propagate into analytics wreaking havoc. A data team that is constantly fighting fires is unable to achieve peak productivity. A comprehensive DataOps initiative requires several key methods and processes in addition to orchestration.
The End-to-End Data Life Cycle of DataOps
Even as we describe the unique requirements of enterprise data orchestration, it is important to keep a broad understanding of DataOps in mind. DataOps governs the end-to-end life cycle of data. Here are some key ingredients of DataOps:
- Process Controls – In DataOps, automated tests and statistical process controls, operating at every step of the data pipeline, filter and eliminate the data errors that corrupt analytics and create the unplanned work that derails productivity.
- Change Management – DataOps concerns itself with the tracking, updating, synchronization, integration and maintenance of the code, files and other artifacts that drive the data-analytics pipeline.
- Parallel Development – DataOps organizes and compartmentalizes analytics development so team members can work productively without resource conflicts.
- Virtualized Technical Environments – DataOps virtualizes technical environments so that development is isolated from production even as both environments are better aligned with each other. Virtualization also enables analytics to flow more easily through development and eventually to production. When a project begins, data analysts quickly spin up a development environment that includes the required tools, security access, data, code and artifacts.
- Reuse – DataOps enables the reuse of analytics components, standardizes widely used functionalities and eases migration across virtual environments.
- Responsiveness and Flexibility – DataOps designs the data-analytic pipeline to accommodate different run-time circumstances. This flexibility makes analytics more responsive to the organization’s needs and changing priorities.
- Rapid Change – DataOps architects the technical environment to achieve the minimal possible analytics-development cycle time, in addition to meeting application requirements. DataOps designs for change. A DataOps data architecture considers changes to production analytics a “central idea,” not an afterthought.
- Coordination of Teams – DataOps coordinates tasks, roles and workflows to break down the barriers between data teams so that they work together better.
- Coordination of People Within Teams – DataOps helps data professionals achieve a much higher level of overall team productivity by establishing processes and providing resources that support teamwork.
- Orchestration – Any list of DataOps capabilities has to include orchestration. As mentioned above, DataOps automates the workflows associated with the Value and Innovation Pipelines to promote efficiency, quality and reduce organizational complexity.
In summary, DataOps governs how analytics are planned, developed, tested, deployed and maintained.
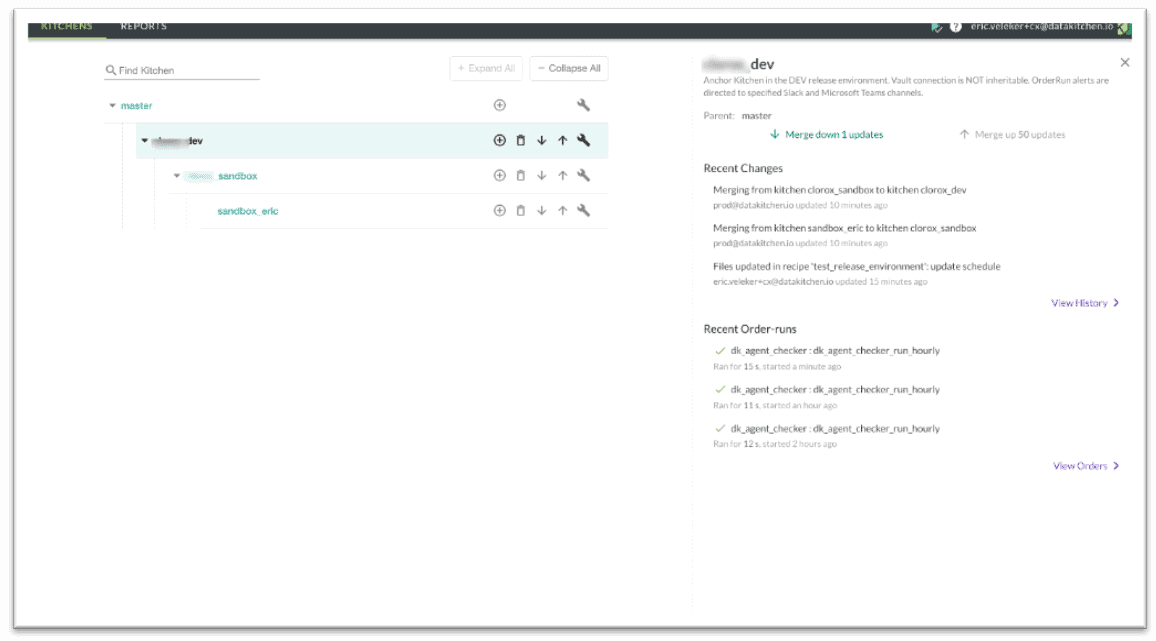
Figure 5: Data professionals access the capabilities of DataOps using a virtual environment called a “Kitchen.”
DataOps Kitchens
It might be challenging for a person in a non-DataOps enterprise or an organization that is only doing orchestration to understand how DataOps accomplishes the aims that we have described. DataOps is not a new tool that replaces your existing tools. It is a set of tools and methods that improve the way you use your existing tools. Many of the DataOps capabilities that we described above are localized in a new virtual construct that we call a “Kitchen.” In DataOps, Kitchens are the controlled and repeatable environments where data professionals do their work. Data professionals access the capabilities of DataOps using a Kitchen.
A Kitchen reflects the production technical environment and integrates and enables data testing, code quality control, process controls, version control, parallel development, environments, toolchains, component reuse, containers, conditional execution, vault security, workflow management and yes, orchestration of data operations and analytics-development pipelines. A Kitchen is a repeatable environment that promotes sharing among team members. Kitchens may be easiest to understand in the context of a data team working to produce new analytics on a tight schedule – see our user story here.
Kitchens Enable DataOps
Kitchens enable DataOps to coordinate tasks between and within teams. Kitchens are the virtual environments where all DataOps functionality comes together. Using Kitchens, DataOps delivers several important benefits:
- Rapid experimentation and innovation for the fastest delivery of new insights to customers
- Elimination of errors
- Collaboration across complex sets of people, technology, and environments
- Clear and precise measurement and monitoring of results
DataOps accomplishes these goals by streamlining the end-to-end data life cycle. It provides a way for enterprises to cope with massive amounts of data, real-time application requirements, and organizational/workflow complexity. Orchestration plays a key role in DataOps, but it is only one tool of many available in DataOps Kitchens. DataOps provides the roadmap for data organizations to adapt their structure, tools, and methods to thrive in increasingly complex and competitive markets.
For more information on the DataKitchen Platform, see our whitepaper, Meeting the Challenges of Exponential Data Growth.





