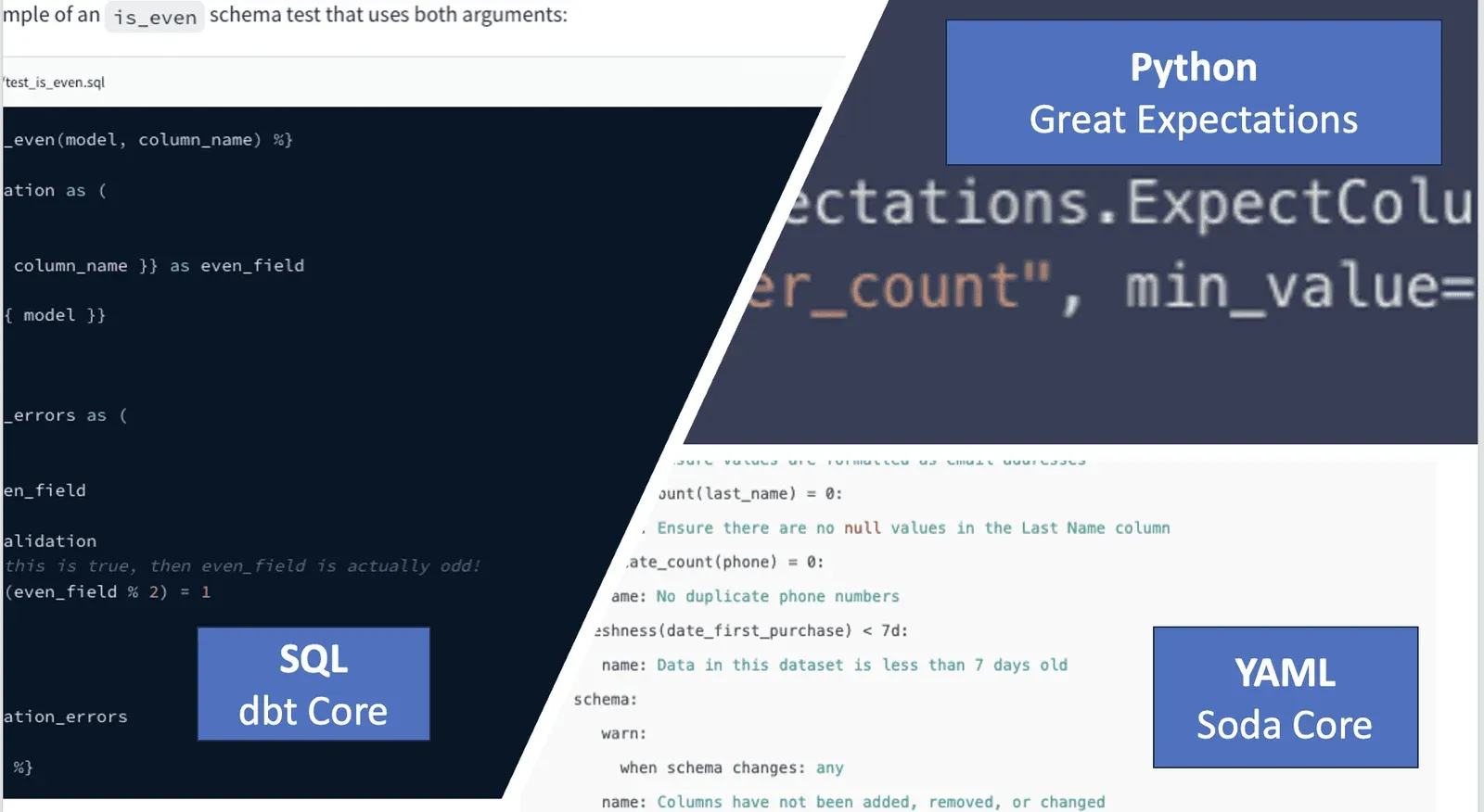
As a data engineer, ensuring data quality is both essential and overwhelming. The sheer volume of tables, the complexity of the data usage, and the volume of work make manual test writing an impossible task to get done. Everyone wants to write more tests, yet they somehow never get it done. Every customer we talk to has a considerable test debt. Current open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of data quality tests. They are all in the realm of software, domain-specific language to help you write data quality tests.
The data engineer’s job is to ensure reliable, high-quality data pipelines that fuel analytics, machine learning, and operational use cases. But there’s a growing problem—data quality testing is becoming an unsustainable burden. You don’t have the time to write exhaustive data quality tests, and even if you did, you lack full context on business data usage. Meanwhile, business data stewards don’t have the skills to program or even tweak these tests. The reality is that 80% of data quality tests can be generated automatically, eliminating the need for tedious manual coding.
The solution? An open-source AI-driven data quality testing that learns from your data automatically while providing a simple UI, not a code-specific DSL, to review, improve, and manage your data quality test estate—a Test Generator.
The Challenge of Writing Manual Data Quality Testing
Organizations often have hundreds or thousands of tables. Writing comprehensive data quality tests across all datasets is too costly and time-consuming. Even if data engineers had the resources, they lacked the full context of data use. Business data stewards who understand data semantics should co-manage these tests. However, they do not have the programming skills required to define them in code.
Data quality tests are critical to ensuring correct and trustworthy data but have significant challenges. One of the biggest hurdles is the sheer volume of tables in modern data environments. Organizations today manage hundreds or even thousands of tables, making it prohibitively expensive and time-consuming to write data quality tests manually for each one. Even with frameworks like dbt tests, Great Expectations, or Soda Core, creating and managing custom tests at such a scale quickly becomes overwhelming.
Another challenge is the lack of full context surrounding the data. As a data engineer, you are responsible for managing pipelines, but you may not have deep domain expertise on how the data is used in the business. On the other hand, business users often have a better understanding of data semantics but lack the technical skills to write tests. This disconnect makes it difficult to ensure that data quality tests are comprehensive and relevant. Ideally, data quality tests should be co-managed by data engineers and business users, but current tooling does not support this collaboration effectively.
Furthermore, data quality tests serve multiple vital purposes beyond just catching issues in production. They are crucial for data quality scorecards, which help track the long-term health of an organization’s data. These scorecards are essential for regulatory compliance, executive reporting, and decision-making. Manually writing tests limits the scope of what gets tested and can introduce biases, making it difficult to get a complete picture of data quality. Organizations that fail to prioritize data quality testing risk compromising their data integrity, affecting their ability to make informed business decisions.
Current Open Source Data Quality Testing: It’s Coding
Current leading open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of data quality tests. They are all in the realm of software, domain-specific language to help you write data quality tests.
The AI-Driven Solution To Data Quality Testing: You Can Get 80% Of The Way There Fast
AI-driven data quality testing presents a transformative shift in how organizations maintain the integrity of their data. Traditional methods rely heavily on manual rule-writing, requiring significant engineering effort. However, AI can analyze historical data, learn its natural constraints, and automatically generate tests for critical aspects such as schema drift detection, data volume fluctuations, missing values, null anomalies, referential integrity, and business logic validation based on past trends. These tests can be generated instantly with a single button, enabling data engineers to focus on ensuring pipeline reliability rather than spending time on custom validation rule development. AI-driven automation allows organizations to start fast and scale their data quality efforts effortlessly.
In The Land Of The Blind, The Data Engineer Who Has Data Quality Testing In Production Is King
Data engineers experience burnout at alarming rates, with many considering leaving the industry or their current company within the following year. Surveys consistently reveal that the most significant sources of burnout include spending too much time fixing errors, repetitive manual tasks related to data preparation, and an endless stream of often unrealistic requests from colleagues. Data quality testing, unfortunately, is almost always treated as an afterthought—an overlooked necessity that only becomes urgent when something breaks. But testing is the gift that engineers give to their future selves. By proactively implementing automated and AI-driven testing, engineers can reduce their manual workload, prevent errors before they occur, and establish a more sustainable workflow. And let’s not forget—most bosses are already asking about AI-driven solutions. Why not take charge of bringing AI to data quality testing and lighten your load?
Test Are A Shared Artifact: Business and Governance Users Need a UI, Not Code
Data quality is not merely a technical concern but a business imperative. Business users, who play a crucial role in defining and managing data governance, should be able to participate in data quality testing without the need for programming expertise. Writing SQL, Python, or YAML-based rules should not be a prerequisite for their involvement. Instead, a simple user interface should empower them to review and approve AI-generated tests, define additional rules using natural language inputs, and collaborate with engineers to refine data quality standards. Organizations can bridge the gap between business and technical teams by providing a UI-driven approach, ensuring a collaborative and more efficient data quality management process.
The Remaining 20% Of Domain-Specific Custom Tests Should Be Where You Focus Your Time.
Although AI can generate most data quality tests, some industry-specific validations require a level of customization that AI alone may not capture. These tests, however, should not be buried in complex code repositories that make them inaccessible or difficult to maintain. Instead, organizations should maintain a library of reusable test patterns, such as historical balance tests, transaction anomaly detection, and time-series trend analysis. Businesses can apply these custom tests flexibly across multiple datasets without reinventing validation logic for each use case by treating these custom tests as structured templates rather than hardcoded rules. This approach ensures that critical domain-specific data quality checks remain scalable and manageable while allowing organizations to benefit from automation wherever possible. This is where you can add real value to the business instead of just being a data plumber.
The Future: AI-Powered, Generative Data Quality Management as a Standard Practice
AI is revolutionizing data management; data quality testing should be no exception. The current approach of manual rule-writing is unsustainable at scale, and the cost of poor data quality is too high to ignore. By leveraging AI:
- Data engineers free up time for more strategic work.
- Business data stewards gain visibility and control over data quality.
- Organizations achieve higher trust in data with minimal human effort.
The next generation of data quality frameworks must be built around AI-powered automation and human-in-the-loop validation. The time has come to move beyond manual test writing and embrace intelligent, self-learning data quality monitoring.
A robust AI-driven data quality platform eliminates the pain of manual test writing while providing governance teams with visibility and control. The future of data quality is automation-first, with AI-generated tests forming the baseline and domain-specific rules captured as reusable templates.
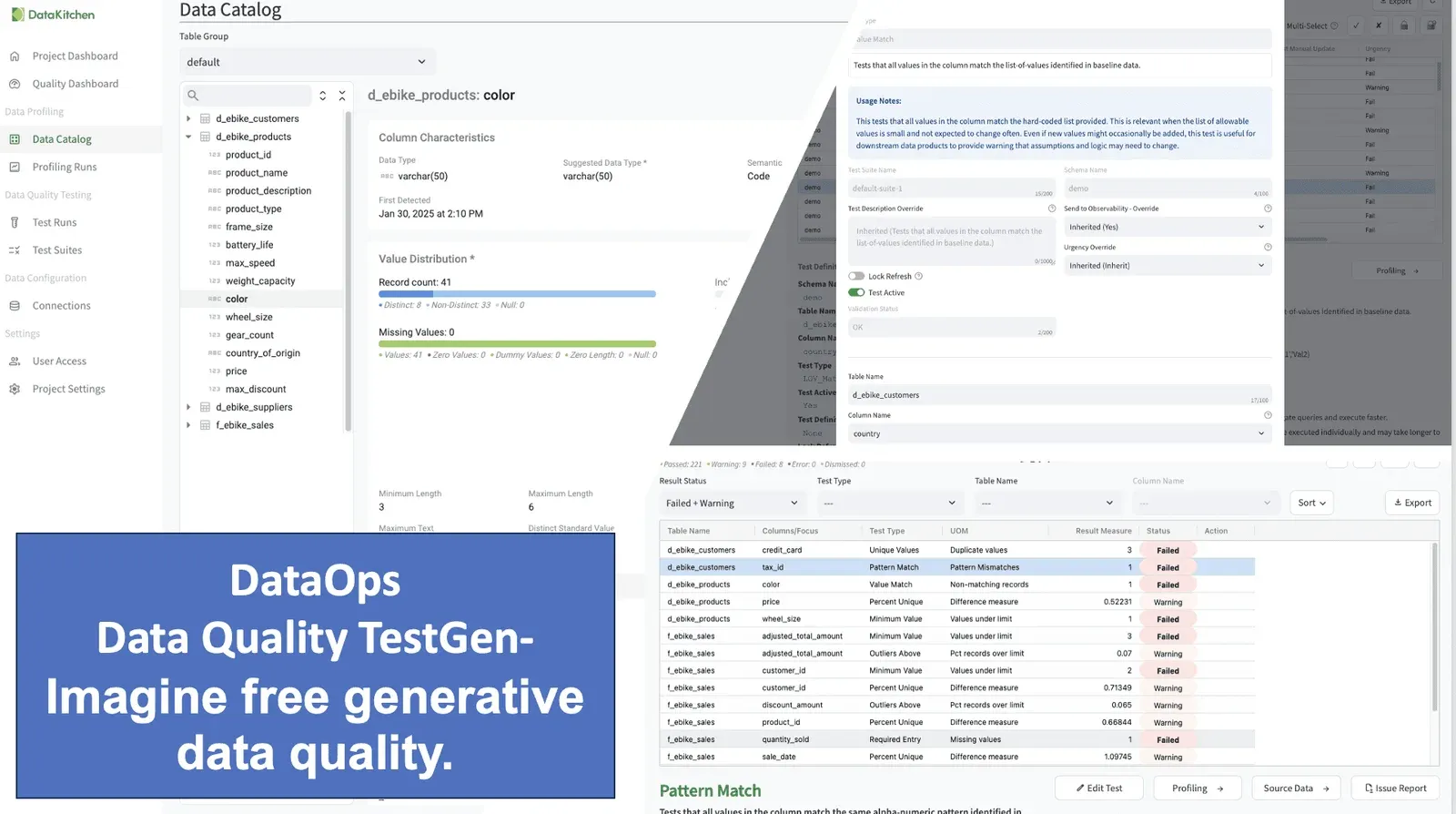
Our Open Source DataOps Data Quality TestGen product provides robust AI-driven open-source software that automates data integrity checks and anomaly detection while enabling business collaboration via a simple UI.
- One-Button Data Quality Checks – Instantly generate automated tests without deep data expertise.
- 120+ AI-Driven Data Quality Tests – Automatically complete data integrity, hygiene, and quality coverage.
- Anomaly Detection – Stay ahead of data issues with automated alerts on freshness, volume, schema, and data drift.
- Customizable Quality Scoring & Dashboards – Automated scorecards with drill-down reports to track and improve data quality.
The time has come to move beyond manual test writing and embrace intelligent, self-learning data quality monitoring that seamlessly integrates business and engineering needs.