The cacophony of tools and mission-critical deliverables are the reason behind the high complexity of modern-day data organizations. Data groups include a wide range of roles and functions that are intricately woven together by their “Data”. Teams include data scientists, business analysts, data analysts, statisticians, data engineers, and many more people. Each of these roles has a unique mindset, specific goals, distinct skills, and a preferred set of tools. It’s not news that everyone loves their tools and are seldom willing to give them up.

DataOps orchestrates your end-to-end multi-tool, multi-environment pipelines – from data access to value delivery. Using the DataKitchen DataOps Platform, you can continue to use the tools you love. For example, one popular tool is StreamSets, which allows teams to build and operate smart data pipelines for data ingestion and ETL. However, an ETL tool on its own will not deliver the benefit of DataOps. Although tools like StreamSets play an important role in the data operations pipeline, they do not ensure that each step is executed and coordinated as a single, integrated, and accurate process or help people and teams better collaborate. A platform like DataKitchen is needed to orchestrate StreamSets (or any ETL tool) as part of your end-to-end data pipeline. StreamSets and DataKitchen are complementary tools. Orchestrating StreamSets with DataKitchen enables you to achieve key elements of DataOps, such as the ability to:
- Manage and seamlessly deploy StreamSets pipelines easily across different release environments (DEV/PROD/QA).
- Automate the testing and monitoring of StreamSets pipelines using the python-sdk or API exposed by StreamSets.
- Easily design data pipelines (Recipes) that include StreamSets along with any of your favorite tools.
- Manage and control different versions of the StreamSets pipeline configuration.
- Facilitate collaboration amongst users by allowing easy sharing of resources (Ingredients) including the StreamSets pipeline in their respective isolated work environments (Kitchens).
How It Works
For the infrastructure setup, StreamSets runs inside of a docker container on an AWS EC2 instance. DataKitchen interacts with StreamSets using the StreamSets CLI. StreamSets also has a subscription-based python-sdk which may be leveraged to exchange some information that can later be used to configure some automated QA tests in the DataKitchen DataOps platform.
The picture below shows a basic recipe built in less than a day that imports an existing StreamSets pipeline, starts the pipeline, triggers it by mimicking an event and in the end stops the pipeline. All the tasks mentioned above are performed in individual nodes each of which can be configured to add automated QA tests that can either pass/fail or issue a warning upon execution.
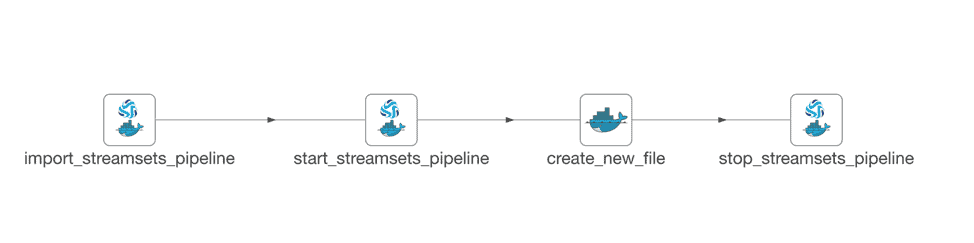
Step 1: Import the StreamSets pipeline
This step is performed by the node import_streamsets_pipeline as shown in the picture above. It uses a docker container to log into the AWS EC2 machine and import the StreamSets pipeline as defined by the JSON extract provided by the user using the StreamSets CLI. The JSON extract can be exported from StreamSets and passed into the docker node as a source file. This step also makes sure that the StreamSets pipeline is versioned in Github.
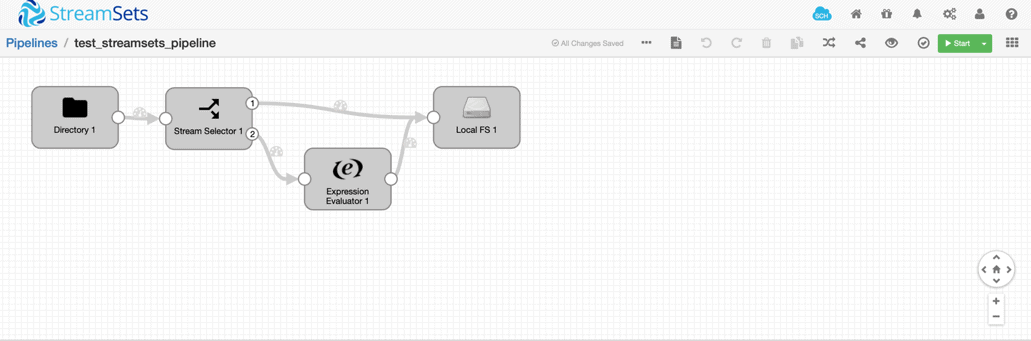
bin/streamsets cli -U https://localhost:18630 store import -n “$pipelineID” -f <file_name>.jsonThe sample StreamSets pipeline we designed for demo (as shown in picture below) moves a file from local directory (local directory on the ec2 instance) to an Amazon S3 bucket.
Step 2: Start the StreamSets Pipeline
The start_streamsets_pipeline node uses a docker container to log into the AWS EC2 machine and interact with StreamSets using the StreamSets CLI to start the StreamSets pipeline.
bin/streamsets cli -U https://localhost:18630 manager start –name <pipelineID>Step 3: Create a new file
The create_new_file node mimics the arrival of a new file in the local directory by creating a new file in the ec2 instance to test if the StreamSets pipeline is operating as expected
Step 4: Stop the StreamSets Pipeline
The stop_streamsets_pipeline node uses a docker container to log into the AWS EC2 machine and interact with StreamSets using the StreamSets CLI to stop the StreamSets pipeline.
bin/streamsets cli -U https://localhost:18630 manager stop –name <pipelineID>By following similar steps, any tool can be easily orchestrated with the DataKitchen DataOps Platform. To learn more about how orchestration enables DataOps, please visit our blog, DataOps is Not Just a DAG for Data.