The DataOps Factory
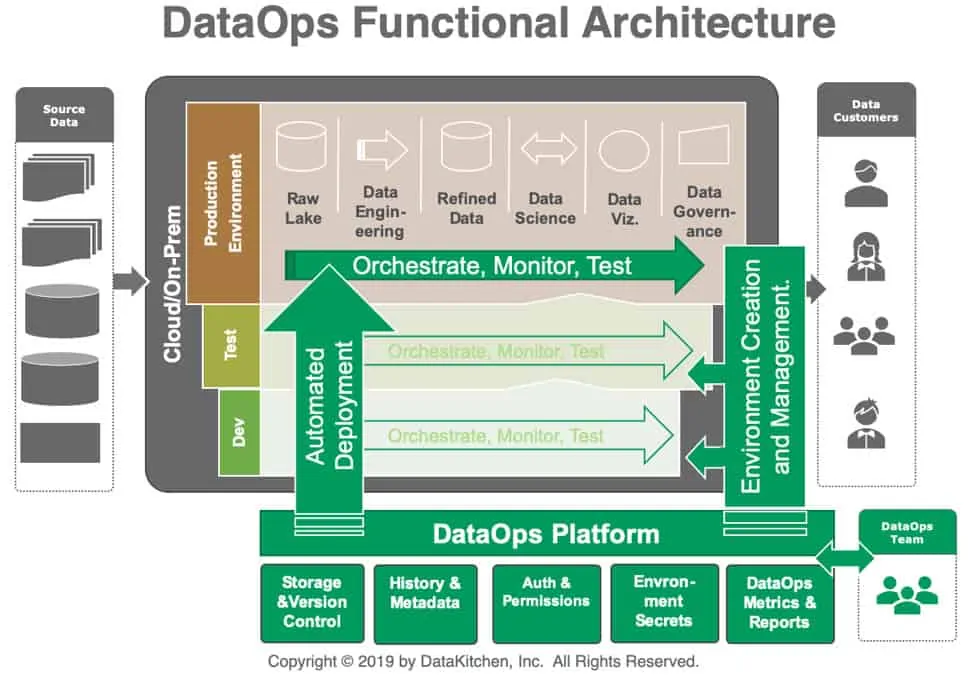
DataOps Automation applies the principles of Agile, DevOps, and lean manufacturing to data analytics. It treats your data operation as a factory, with defined processes, quality gates at every step, and metrics that drive continuous improvement.
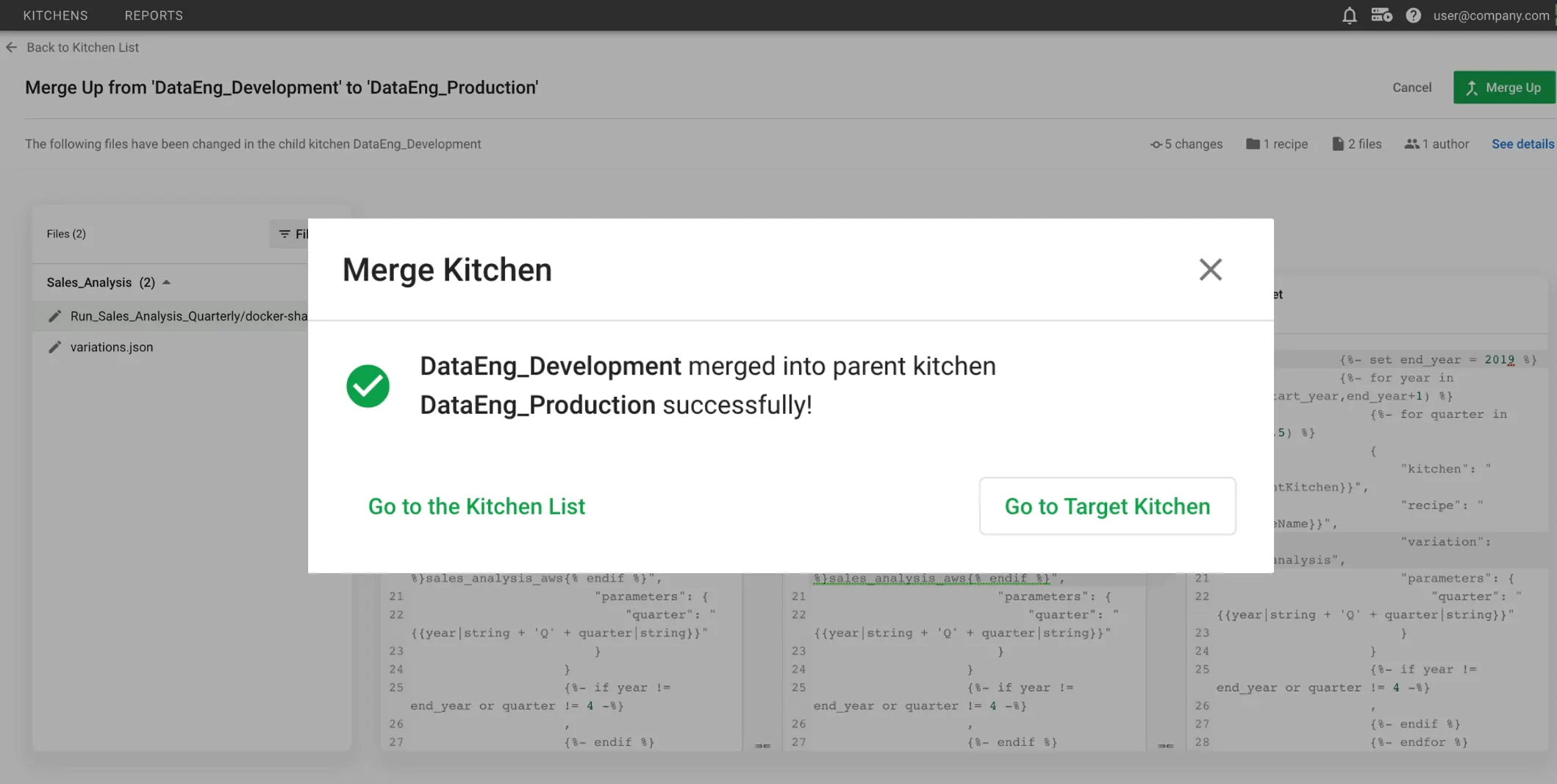
The platform runs two pipelines at the same time: the production pipeline that delivers trusted data to consumers, and the development pipeline where your team innovates and experiments safely. That’s what separates DataOps from traditional data management.
Core Concepts
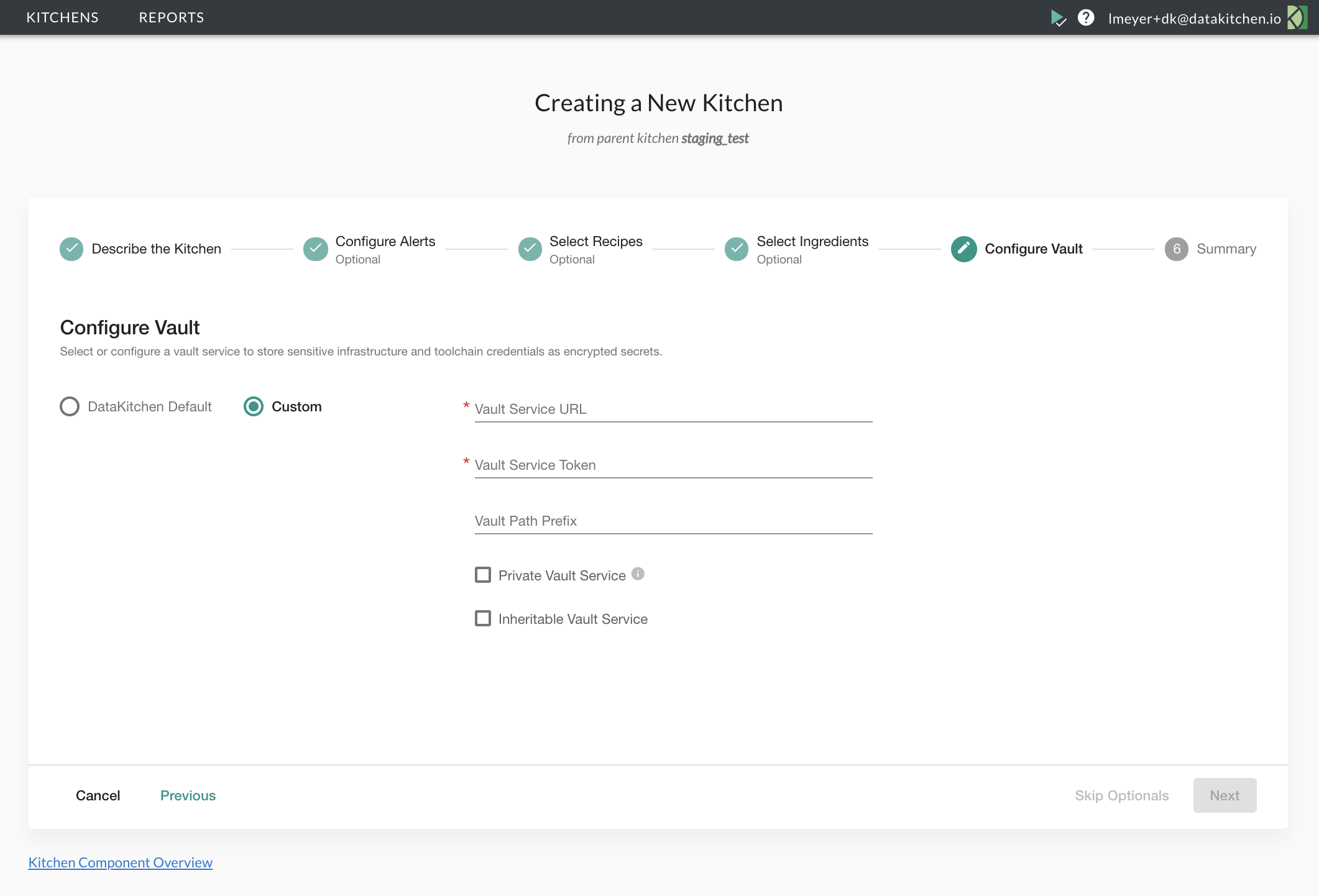
- Kitchens: Isolated workspace environments (like Git branches for your whole data stack)
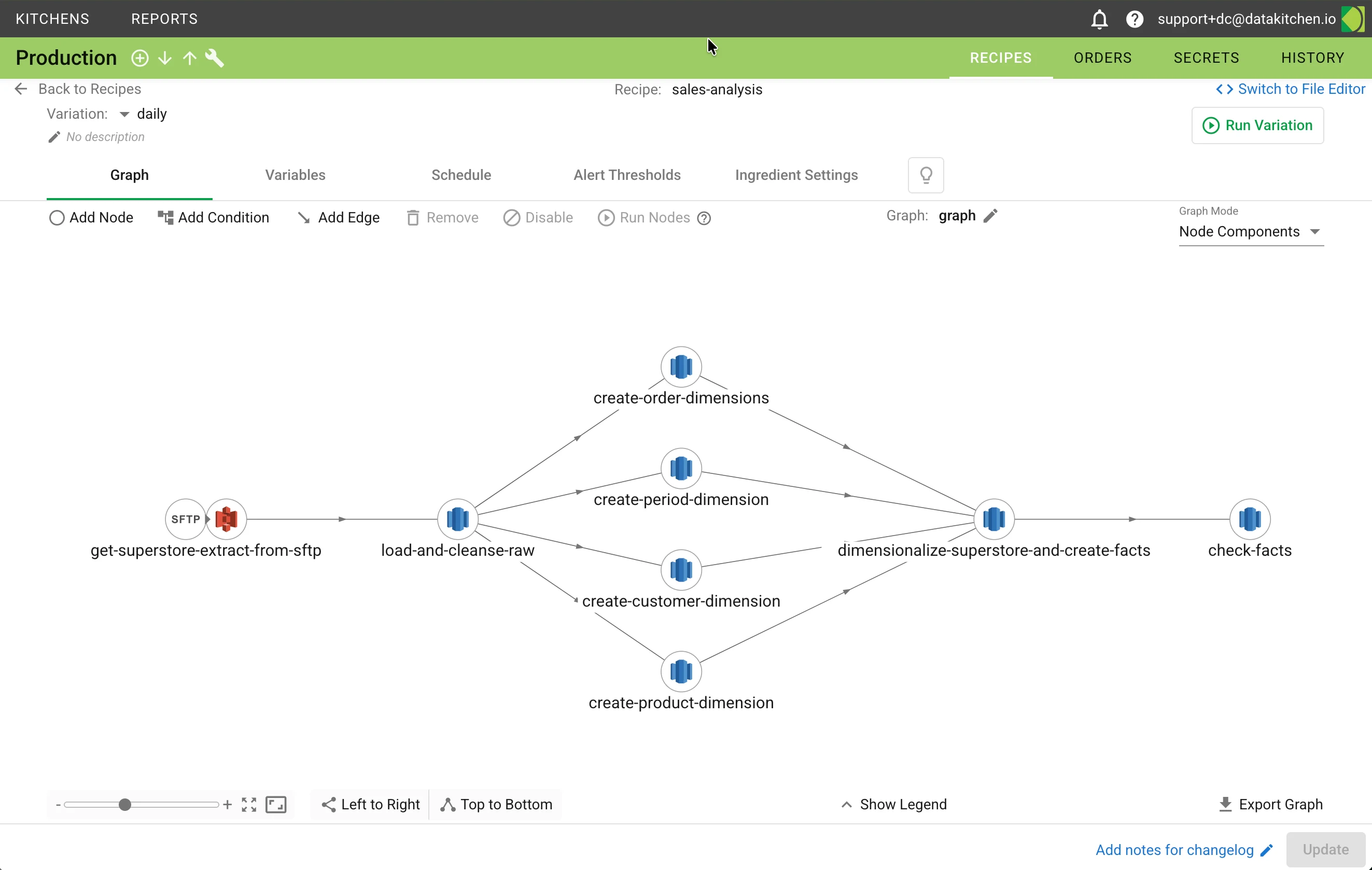
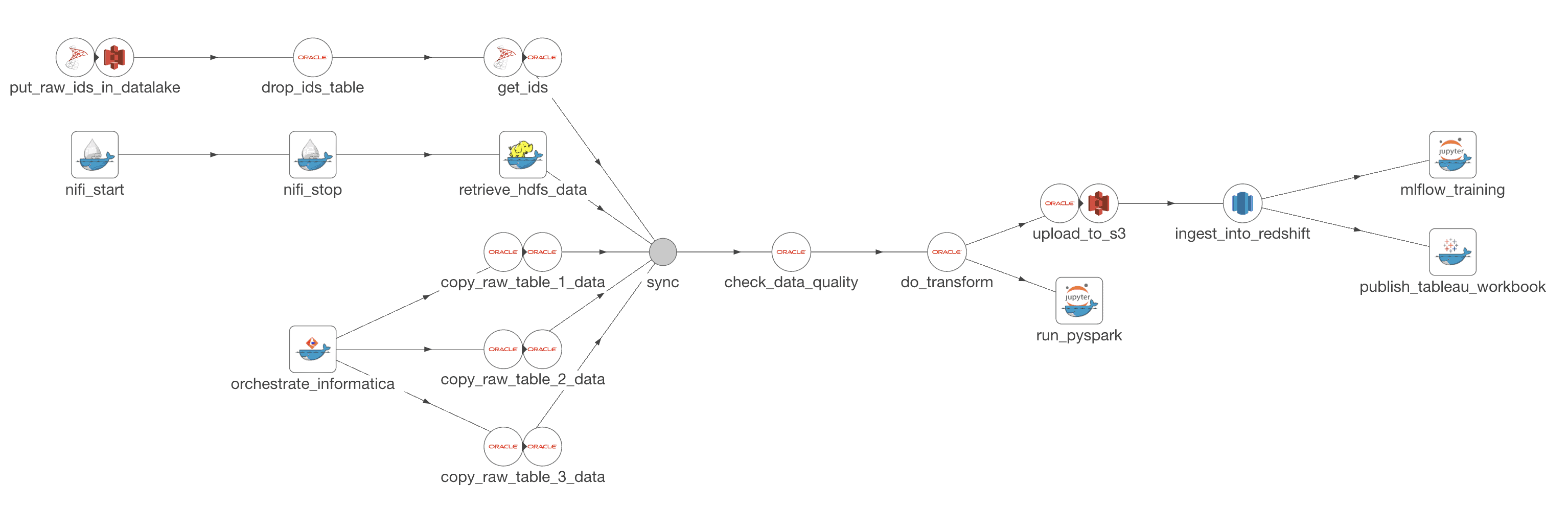
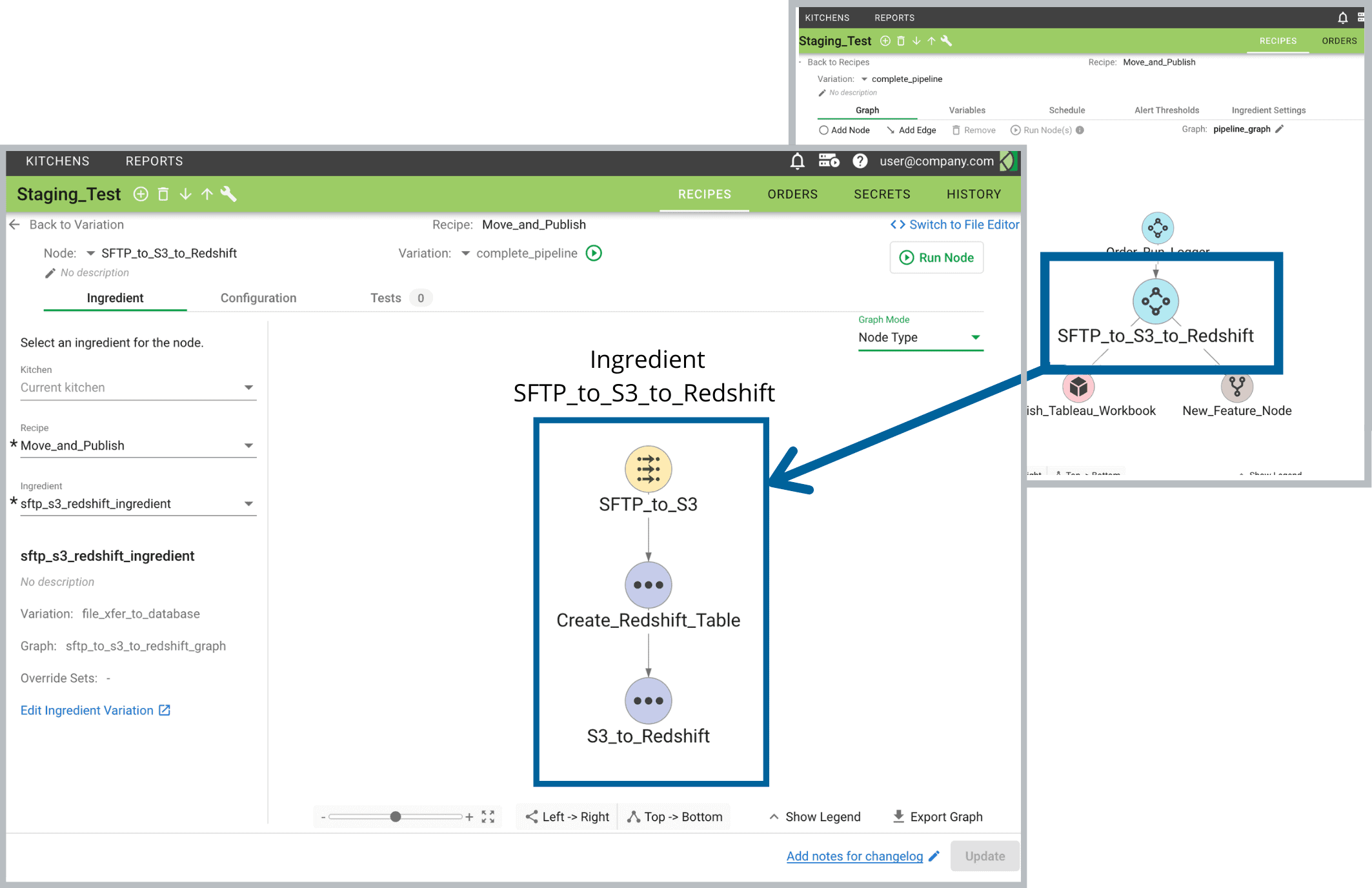
- Recipes: Collections of related data pipelines composed of interconnected nodes
- Variations: Specific pipeline configurations within a recipe for particular use cases
- Ingredients: Reusable pipeline components shared across teams and projects
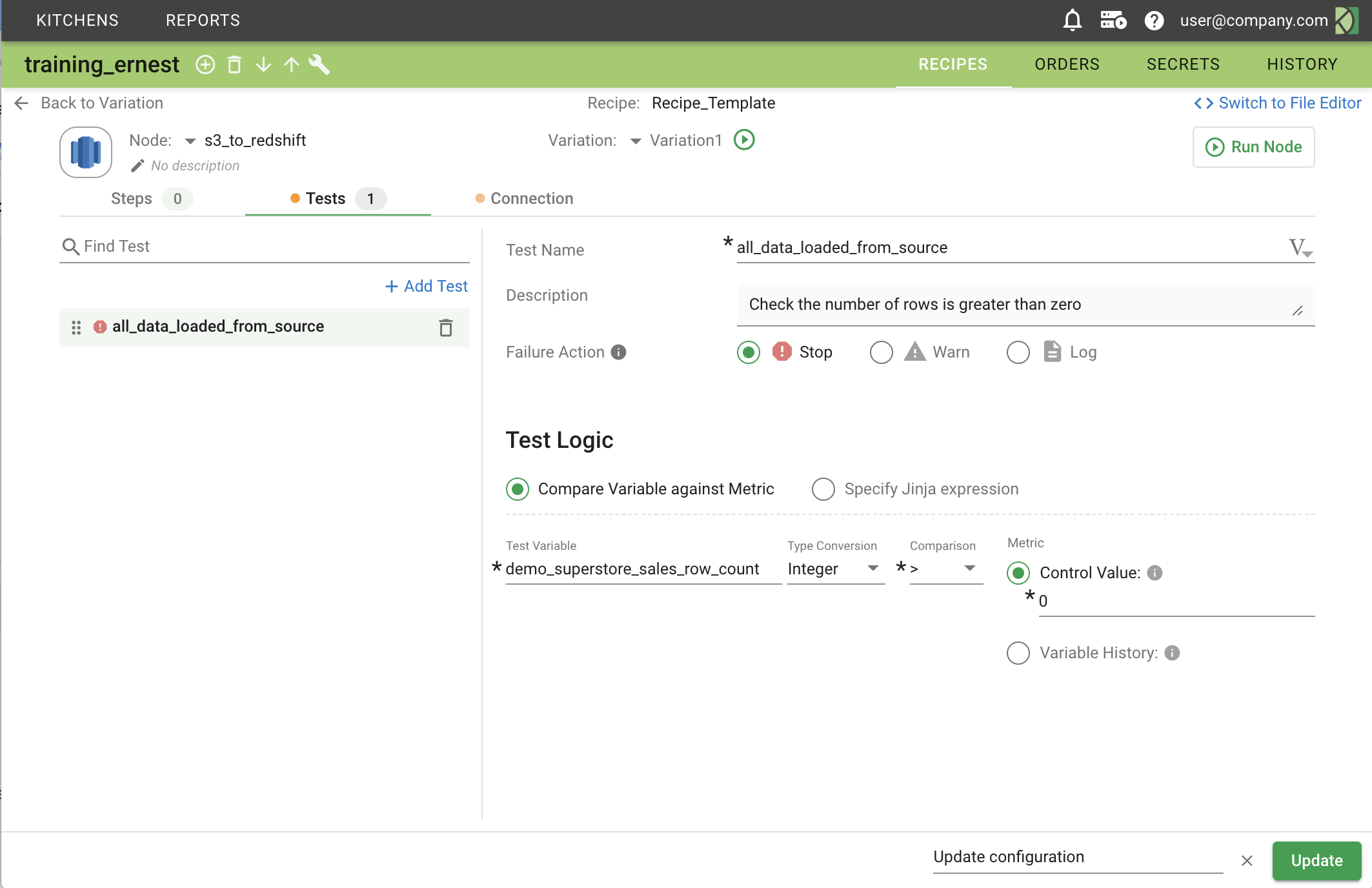
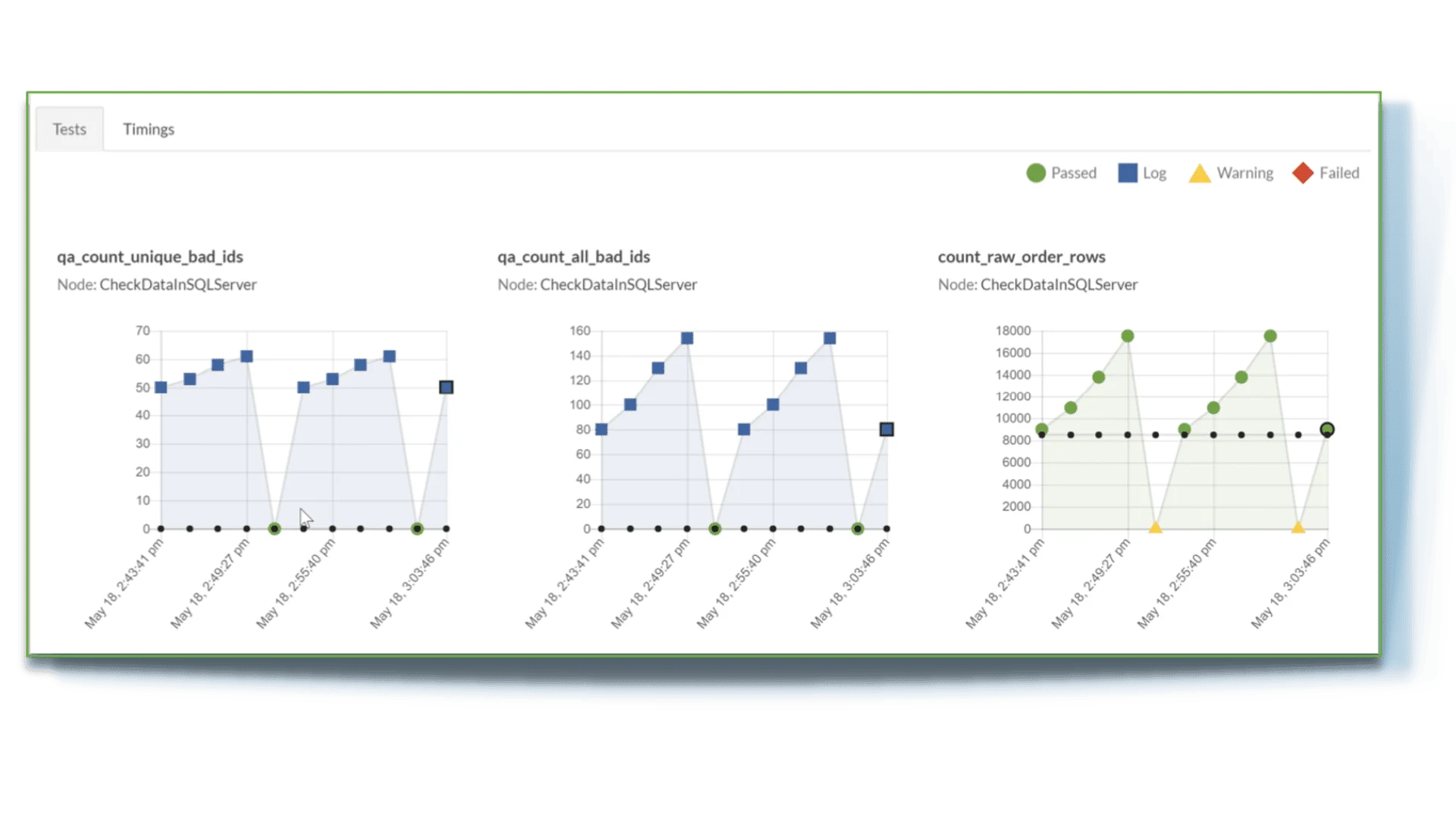
- Orders: Recipe executions with full monitoring, logging, and test result tracking