
DataOps places great emphasis on productivity. Team velocity can improve significantly when the data organization uses tools and methods that promote component reuse. Architecting analytics as microservices is one way to stimulate code reuse. The challenge is that the typical data organization uses so many tools, languages, and platforms — reuse is difficult in a complex technical environment. Containers enable analytics functions to be easily componentized and reused.
What Are Containers?
Containers are a lightweight form of machine virtualization which encapsulates an application and its environment. The container includes all the required libraries, binaries, configuration files – in short, everything that is needed for code to run, bundled together. When an analytics microservice runs in a container, it can be much more easily shared. If a particular piece of source code is needed repeatedly, it’s much simpler to put the logic in a container instead of maintaining separate copies of the code everywhere it is required. When updates are needed, they can be made in one place instead of tracking down copies of the file throughout the enterprise. Container support is integrated into the DataKitchen DataOps Platform. The platform leverages Docker containers as part of its data pipelines (recipes). During data pipeline orchestration, the DataKitchen Platform can quickly spin up a container, execute the application defined inside it, and tear it down when it’s no longer needed.
Advantages of using a container:
- Isolated – the container is a self-contained environment.
- Reproducible – easy to debug
- Reusable – You can use the same container in multiple recipes
Before the advent of containers, data engineers used virtual machines (VM) to address some of the same use cases. VMs each require their own copy of the operating system, whereas multiple containers can run side-by-side on one operating system, reducing resource requirements.
Text Processing Example
A common data engineering problem is pre-processing text files before loading them into a database. For example, a sales data set may indicate prices with a currency sign ($,£,₹). In our use case, suppose we want to move the currency symbol to its own column. This is a classic problem address by Unix shell utilities, and we can make it portable and easily reusable by placing it in a container. The example will take a file from an SFTP server (source), pre-process it, and output it to another file stored in AWS S3 (sink). The GUI of the DataKitchen DataOps Platforms makes creating and using this simple source-sink pattern straightforward and easy.
Source-Sink Pattern
The Source-Sink Pattern takes data from a source and delivers it to a destination. Using the DataKitchen UI, the DataOps Platform handles the transfer of data to and from the container. The data engineer can focus on the transformation logic inside the container. The DataOps Platform makes it simple to define the source and destination endpoints and containerize the transformation code.
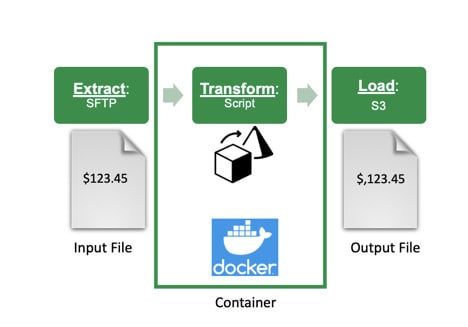
Figure 1 : This simple Source-Sink Pattern uses a container to transform the contents of a file.
Our simple container is based on an ETL operation. The container extracts data from an input file, transforms it, and loads it to an output file. This design pattern facilitates transparency in the pipeline’s operation – it keeps the data at each stage in the ETL pipeline, easing debugging and testing.
Step 1: Data Sources and Sinks
We’ll show how this pattern is defined using the DataKitchen Platform. First, we define an SFTP server connection as our source:
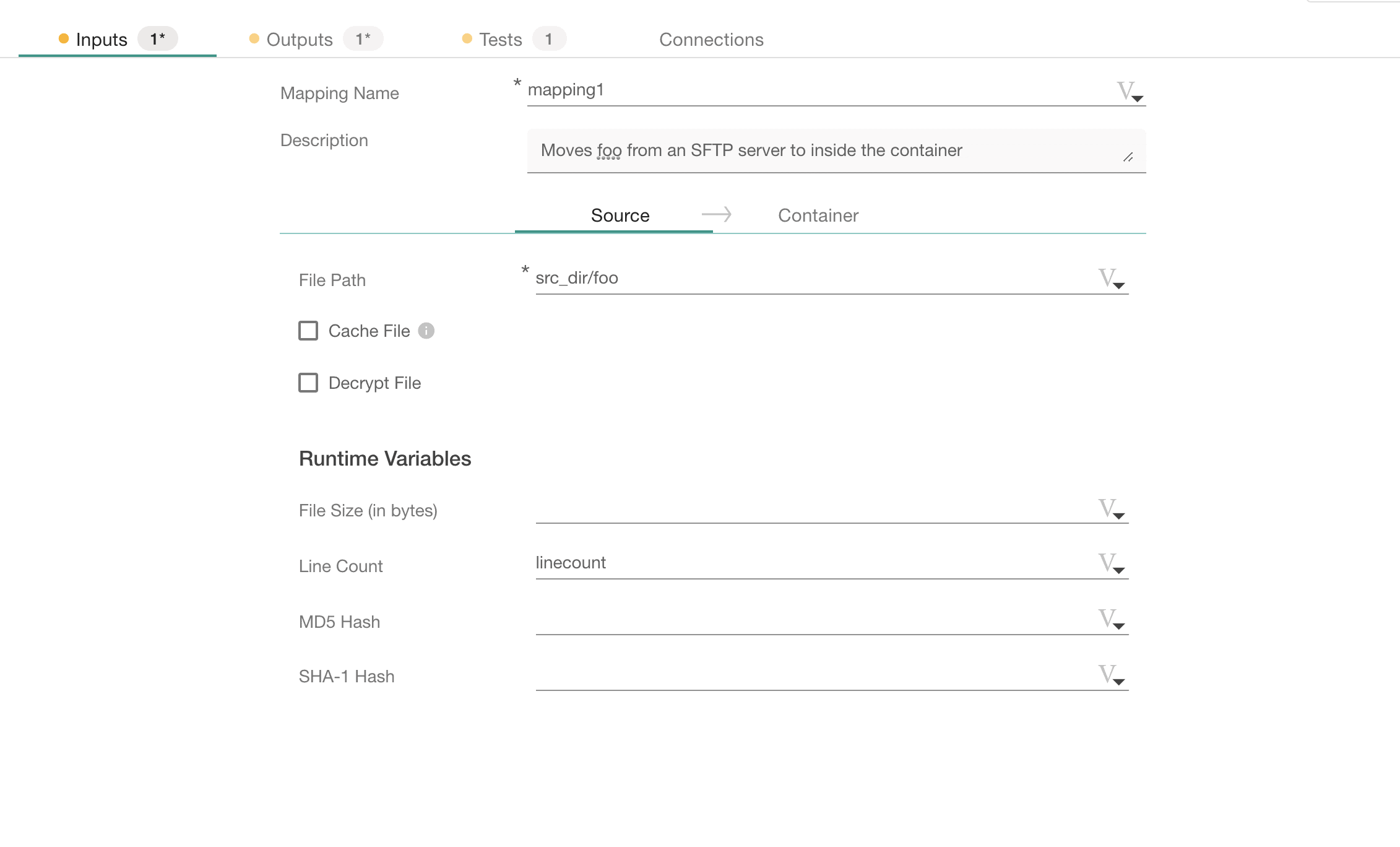 Figure 2 : Using the DataKitchen UI, the user defines a source input for a container. The input tab shows the connector definition.
Figure 2 : Using the DataKitchen UI, the user defines a source input for a container. The input tab shows the connector definition.
Next, we define our sink, which moves the file from the container to S3 storage:
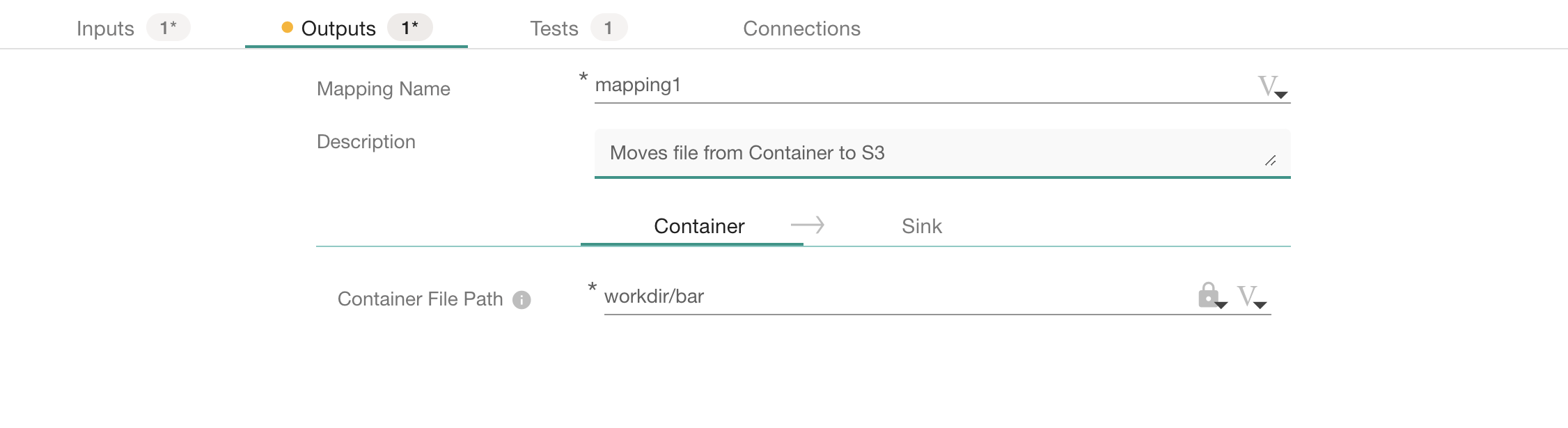
Figure 3 : The DataKitchen UI enables the user to define an output sink for a container. The output tab shows the connector definition.
Step 2: Program
The container can run any code such as a shell or python script. In this case, it runs a Unix sed command, which is an editor that runs on text streams. Team members that are not familiar with sed might look at the command (see screenshot below) and have difficulty understanding it. Also, they may not have access to a Unix machine. With the DataKitchen Platform, this functionality can be easily reused without needing to understand code internals or application environment configuration.
The sed command below will take a string in the form “$123.45” as an input and outputs “$,123.45”. It performs this operation for all rows in the input file. In a comma-delimited file, this effectively moves the ‘$’ to its own separate column.
currency_converter.sh
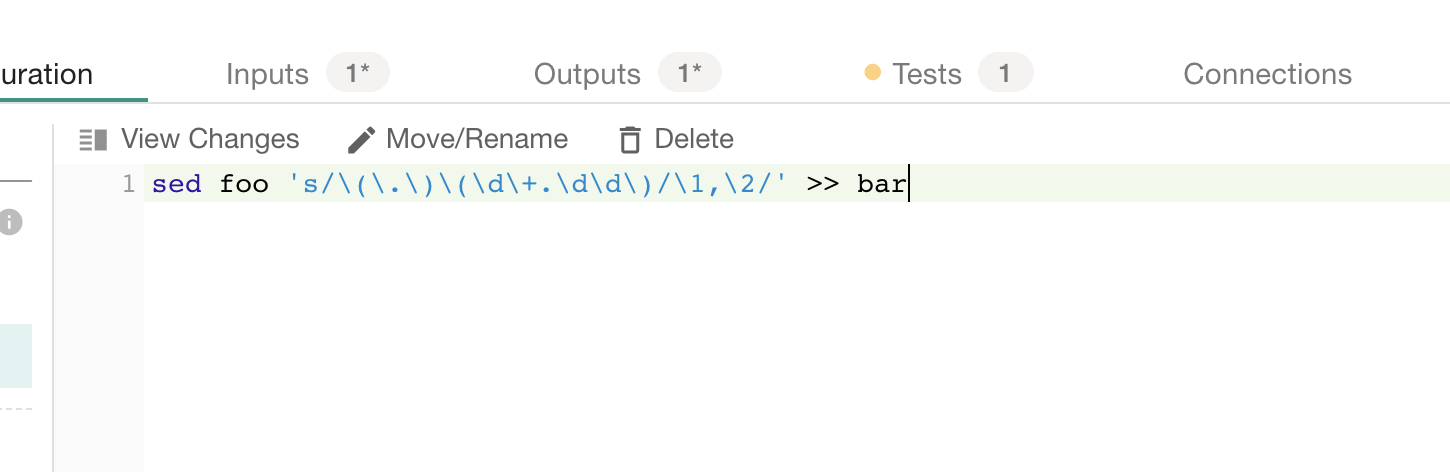
Figure 4: The executable code in the container is a shell script that contains an sed command that transforms the input text stream (file ‘foo’) and deposits the result in a file named ‘bar’.
The UI makes it easy to put the shell script into a container – everything is managed by the DataKitchen Platform. This JSON configuration file tells the container to run currency_converter.sh, the file that will be run by the container.
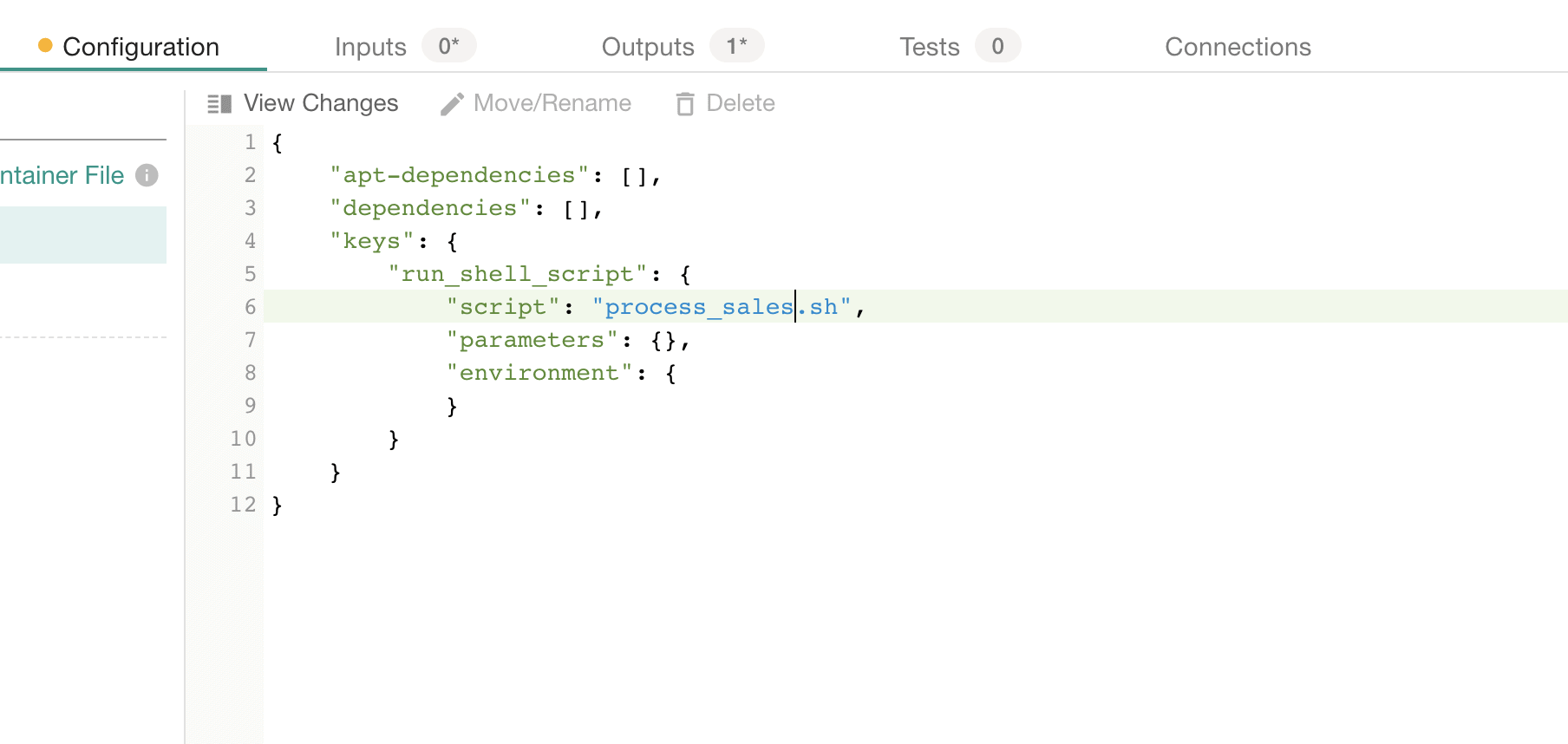
Figure 5: The container node is defined using the DataKitchen UI to run a shell script using a JSON configuration file.
Step 3: Testing
We should also test our file – this allows us to know if there were any problems. The DataKitchen Platform lets you define powerful tests using a simple UI. For example, you should check that you get an expected amount of input data and that you don’t lose rows when we transform our file. The test variable linecount represents the number of rows in the input file.
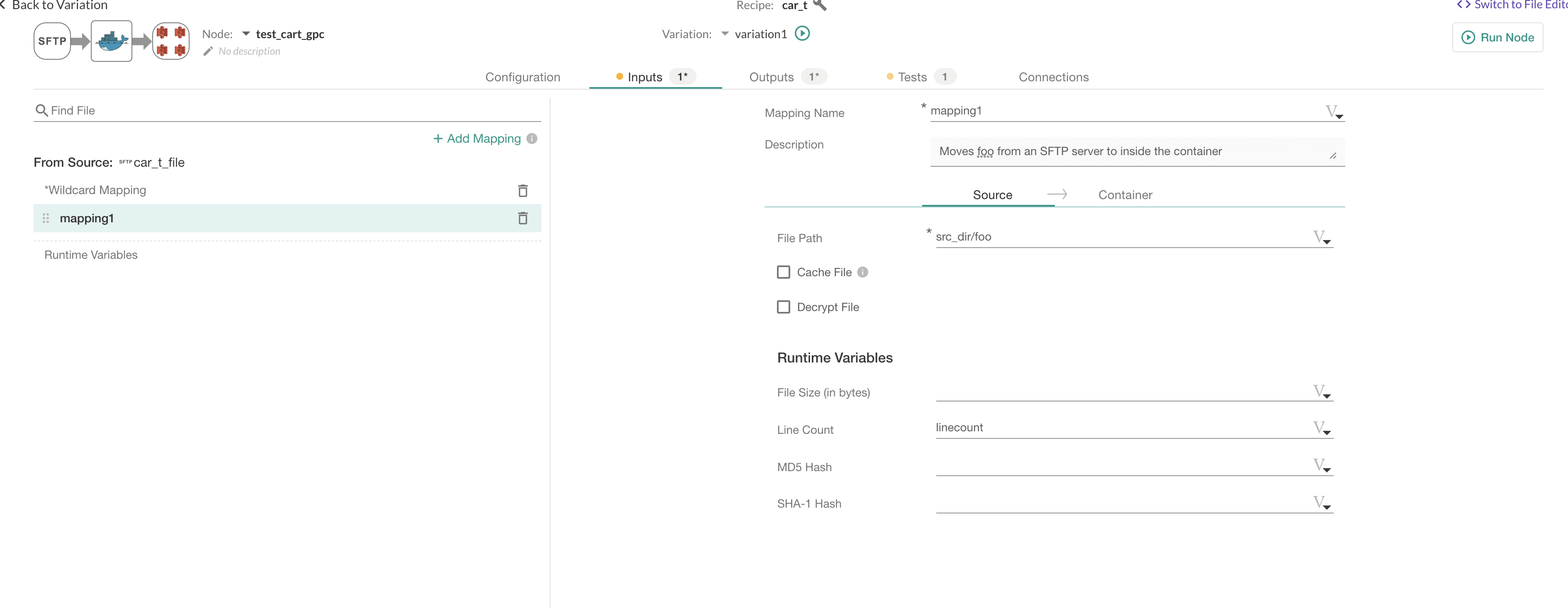 Figure 6: The test logic section in the screen above shows that the line count of the source file must be greater than 100.
Figure 6: The test logic section in the screen above shows that the line count of the source file must be greater than 100.
In the source test (sourcetest), we check that the input file (foo) has at least a hundred rows. If that condition is not true, the test will issue a warning.
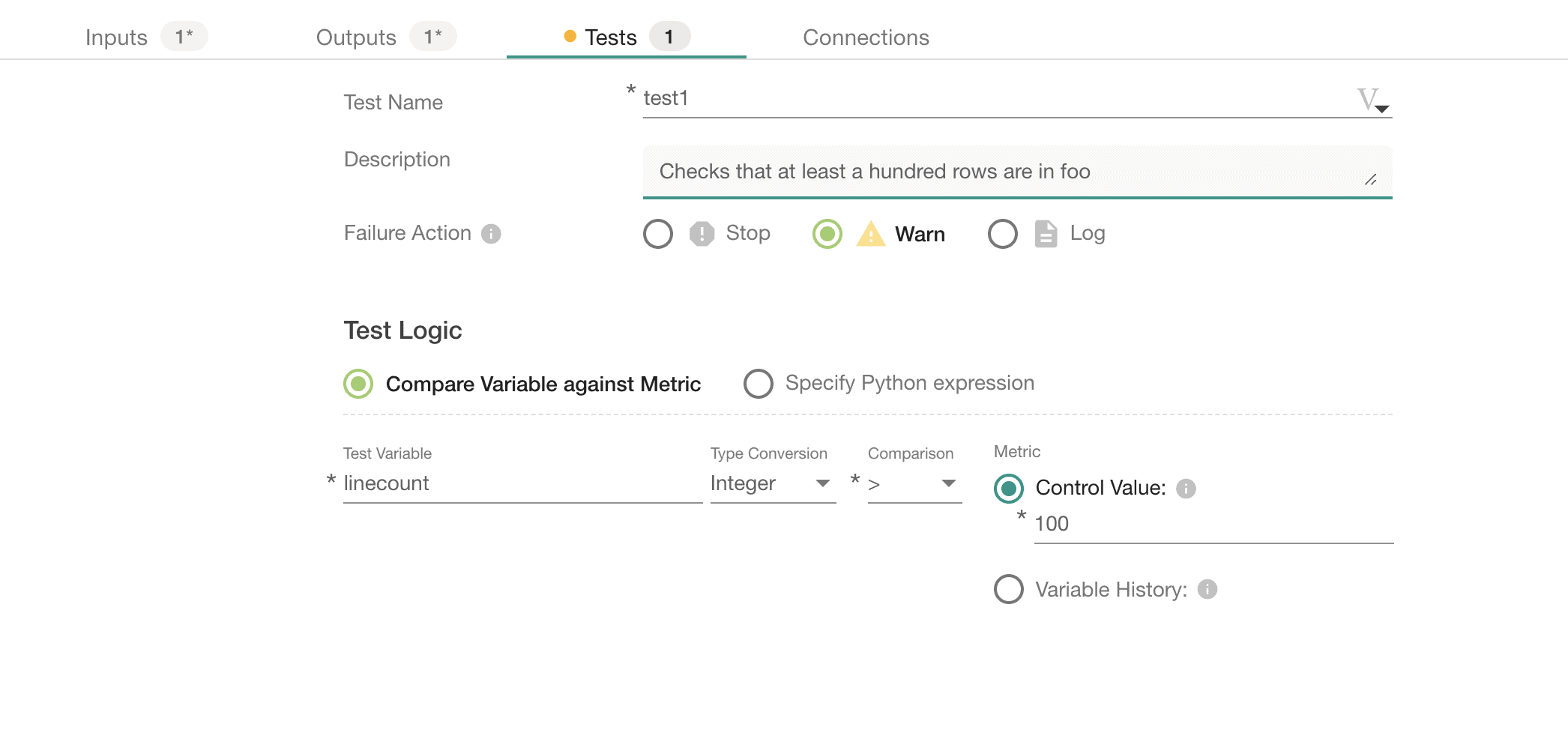 Figure 7: The test logic above shows that the line counts of the input and output files must be equal.
Figure 7: The test logic above shows that the line counts of the input and output files must be equal.
In this sink test (test2), we test that the number of rows in the output file (bar) matches the number of rows in the input file (foo). The “Test Logic” defined above issues a warning if the line count in the output file (linecount_s3) is not equal to the line count in the input file (linecount).
Once the container is set up, it can be run through the DataKitchen UI. Below is a screenshot showing how the order is run.

Figure 8: The DataKitchen UI enables the user to execute orders, which are usually orchestrated data pipelines.
Checking the order status, we can see that the order completed.

Figure 9: After the order executes, the status appears in the order status summary.
The files before and after the transformation show that the operation executed correctly.

Figure 10: File ‘foo’ contents
After the transformation, the currency symbol appears in its own column.

Figure 11: File ‘bar’ contents after the execution of the shell script
Design Pattern
This container is a common design pattern because we have many uses for a file-to-file transformation node. The DataOps Platform makes it easy to modify this node for other requirements: different file names, different sources/targets or different transformation logic. You could replace the sed command with other code and have a totally different processing pipeline. DataKitchen makes it quite simple to create, modify and reuse designs using containers like this source-sink pattern so that users don’t have to worry about tools interfaces, file transfers and keeping multiple copies of the same code synchronized.




