
Data analytics is performed using a seemingly infinite array of tools. In larger enterprises, different groups can choose different cloud platforms. Multi-cloud or multi-data-center integration can be one of the greatest challenges to an analytics organization. DataKitchen works across different tool platforms, enabling groups using different clouds to work together seamlessly. There’s nothing special about clouds – DataKitchen treats on-prem as just another toolchain environment so this discussion also applies to hybrid clouds.
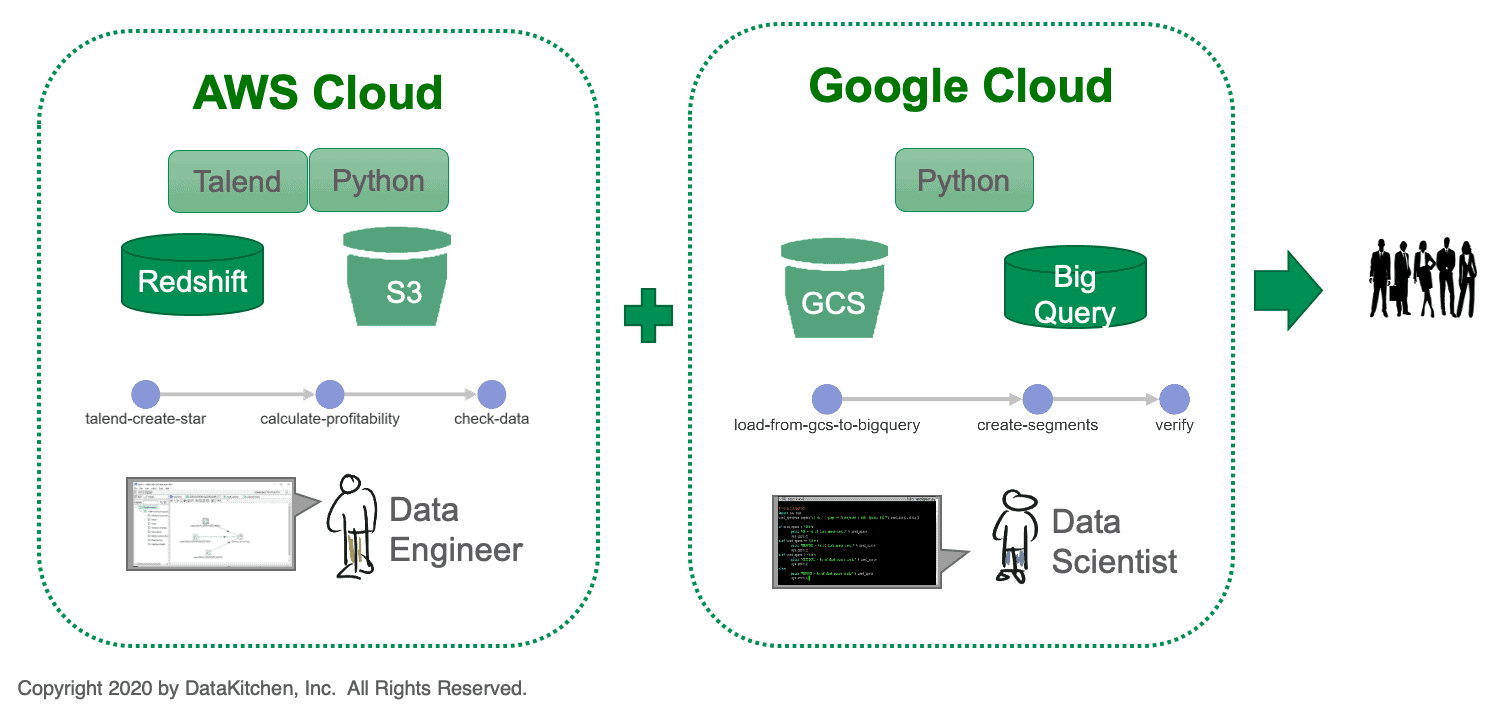
Figure 1: A multi-cloud environment creates challenges for an analytics organization.
We recently encountered an enterprise with two groups that use different cloud platforms (see Figure 1). One group consists of data engineers utilizing tools like Talend, Python, Redshift and S3 on an Amazon (AWS) cloud platform. The second group consists of data scientists who use Google Cloud Storage (GCS), BigQuery and Python on a Google cloud platform (GCP). It’s very difficult to integrate analytics across a heterogeneous environment such as these. Note, we are highlighting Amazon and Google in this example, but the same difficulties hold true for other cloud and on-prem technologies.
In the AWS environment, the data flows through three processing steps. The results are fed to the Google cloud where three more steps are performed before charts, graphs and visualizations are delivered to users. In technology-driven companies, tools, workflows and incentives tend to drive people into isolated silos. It’s very hard to keep two teams such as these coordinated. How do you balance centralization and freedom? In other words, how do you keep control over the end-to-end process without imposing bureaucracy that stifles innovation?

Figure 2: In a heterogeneous architecture, the two halves of the solution must work together to ensure data quality.
Figure 2 illustrates a few challenging aspects of heterogeneous-architecture integration. The two halves of the solution must work together to ensure data quality. Can test metrics be passed from one environment to the other so that data can be checked against statistical controls and business logic? Can the two groups coordinate alerts that notify the right development team of an issue that requires someone’s attention?
The two teams must also engage in process coordination. How do the teams perform impact analysis, i.e., if someone makes a change, how does it affect everyone else? When one team makes an architectural change, is the other team aware? The two teams may have different iteration cadences or business processes, which keep them out of lock step. How can the two groups work together seamlessly while maintaining their independence?
Multi-Cloud with the DataKitchen Platform
The challenges of integrating multiple environments are greatly simplified when using the DataKitchen Platform. DataKitchen creates a coherent framework which interoperates with the two technical environments respectively. The DataKitchen Platform supports orchestrated data pipelines called “Recipes.”
Figure 3 shows a Recipe (data pipeline) that consists of four steps:
- Call-aws – Execute analytics on the AWS platform
- Move-data – move data from AWS to GCP
- Verify-move – test data just moved
- Call-gcp – Execute analytics on the GCP platform
The call_aws and call-gcp nodes are different from the others – they are Recipes that are being used as sub-components of a top-level Recipe. We call these types of Recipes, “Ingredients.” Both call_aws and call-gcp are Ingredients that when called, execute on the respective cloud platforms.
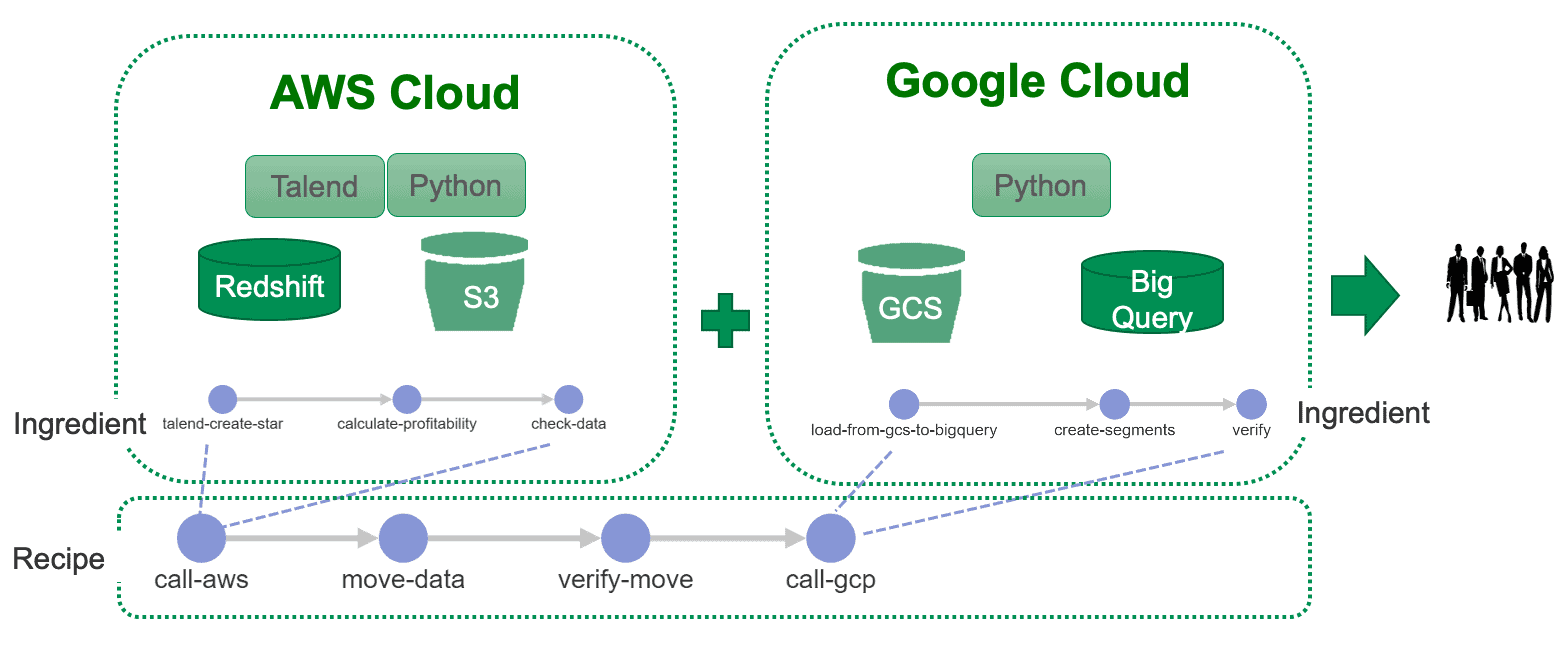
Figure 3: A Recipe that uses Ingredients to execute on respective cloud platforms.
The DataKitchen architecture abstracts the interface to target toolchains. It references the tools in each of the technical environments using variables. During automated orchestration of the pipelines, references to the variables are overridden and diverted to a specific tool instantiation in the correct technical environment. The target environment can then be changed by modifying the overrides. DataKitchen embeds software agents in the technical environments to help facilitate this interface modularity.
DataKitchen executes testing within each Ingredient pipeline and across the cloud environments. Once the top-level Recipe is in place it serves as a robust and modular interface between the two groups. Each group can work independently, focusing on the local call_aws and call_gcp Ingredients respectively. The two groups do not have to understand each other’s toolchain or environment. Data flowing between the two cloud platforms is compartmentalized and error-checked in the move-data and verify-move steps of the top-level Recipe.
The DataKitchen Platform serves as a unifying platform for the two cloud environments. It orchestrates both the local and global data pipelines. It tests data at each processing step and across the end-to-end data flow so that quality is maintained. DataKitchen supports the creation and management of testing across all cloud environments, simplifying end-to-end testing. It liberates the two teams from having to understand each other’s toolchains or workflow processes. With DataKitchen in place, the teams work efficiently and independently, without hindrance from quality, process coordination or integration issues.
To learn more on this topic, read the White Paper, Your Cloud Migration is Actually an Agility Initiative.






