
In a previous blog, we talked about aligning technical environments to facilitate the migration of analytics from development to production. In this post, we will introduce the concept of “Kitchens” and illustrate how they simplify the deployment of data analytics.
In the DataKitchen Platform, Kitchens are workspaces where data professionals work. They contain everything that analytics builders and developers need, including all the components that constitute a complete DataOps innovation and management environment. This includes hardware, software, tools, data, security, sharable services, monitoring and more. We plan to dive into all the features and functions of Kitchens, but first, we need to establish the seamless relationship between Kitchens and technical environments.
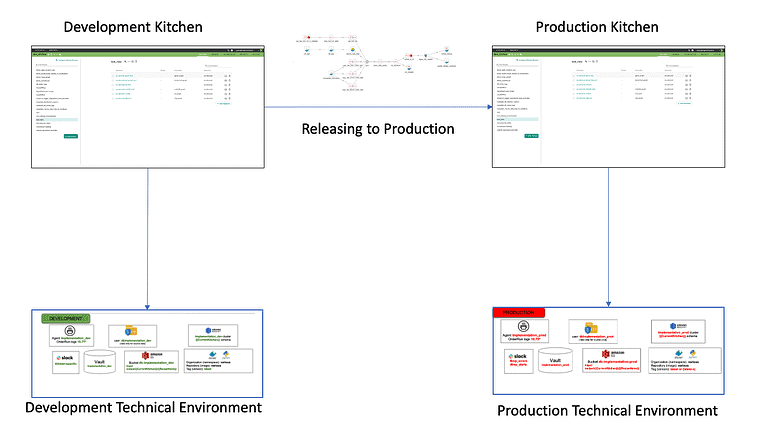
Figure 1: When technical environments match, Kitchens enable analytics to migrate seamlessly – with minimal keyboarding on the part of the data team.
In Figure 1, we show one Kitchen associated with development and one Kitchen pointed at production. As analytics are “released to production” they move from the Kitchen on the left to the right. When executed, the analytics access the technical environment underneath the Kitchen.
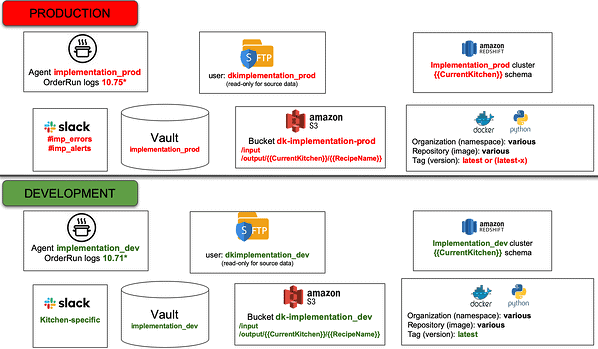
Figure 2: Production and development release environments are aligned to ease the migration of analytics.
Kitchens enable analytics to run and access the toolchain without incorporating non-portable references to the technical environment. References to toolchains are parameterized and can be redirected to point to different target environments. We see in Figure 2 that the production technical environment is referenced as “implementation_prod” and the development technical environment is referenced as “implementation_dev.” Kitchens incorporate references associated with a specific technical environment and decouple the environment association from analytics code. Agents assigned to each technical environment ensure that analytics run on the correct target toolchain.
When analytics run in a development Kitchen, references to the technical environment access “implementation_dev” (bound at compile time). When these analytics move to production, the references are redirected to the “implementation_prod” technical environment. Since the “implementation_dev” and “implementation_prod” technical environments are aligned from a toolchain perspective, no changes to the analytics source files are required. Whether you are working with a single analytics component or a complex series of steps spanning many tools, Kitchens greatly simplify the migration of analytics between technical environments. This is helpful when releasing from dev to production or, when dev needs to reproduce an error encountered in production.
Supporting Multiple Users
Every analytics builder or developer needs a workspace so that they may work productively without impacting or being impacted by others. A Kitchen can be persistent, like a personal workspace, or temporary, tied to a specific project. When multiple Kitchens share a single technical environment, tools are automatically segmented to avoid multi-user conflicts. For example, the technical environments in the figure above contain a Redshift cluster. The Redshift cluster is segmented so that each Kitchen has its own database schema. Kitchens are parameterized so they address the correct Redshift schema.
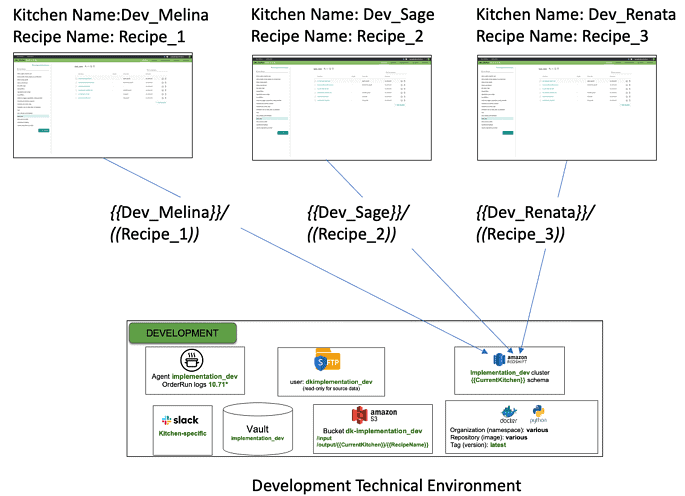
Figure 3: Analytics developers using Kitchens to work separately while sharing a technical environment.
Figure 3 shows three Kitchens for the data scientists Melina, Sage and Renata, who are working on different Recipes (orchestrated data pipelines). The three Kitchens share the “DEVELOPMENT” technical environment. They each have a dedicated database schema within the Redshift cluster, which is accessed using their respective Kitchens. The three users can be productive separately without having to coordinate with each other. All the other tools in the technical environment are similarly segmented. An agent embedded in the technical environment interfaces to the Kitchens, assisting with this segmentation.
Self-Service Environments
In many organizations, workspaces are created individually in response to workspace request tickets. In many organizations, this process can take several weeks (or months). The person tasked with this job often also bears the responsibility for enforcing rules and policies. In an enterprise that uses DataKitchen, Kitchen creation can be set-up as an automated orchestration that instantiates a machine, software, tools, data and all the other resources required for a complete workspace. Policy enforcement can be made more efficient or better yet, just built into the automated workflow. With automated orchestration of Kitchens, team members create workspaces on demand. This “self-service” aspect of DataOps eliminates the time that developers used to wait for systems, data, or approvals. DataOps empowers developers to hit the ground running. This can yield a significant improvement in analytics team responsiveness.
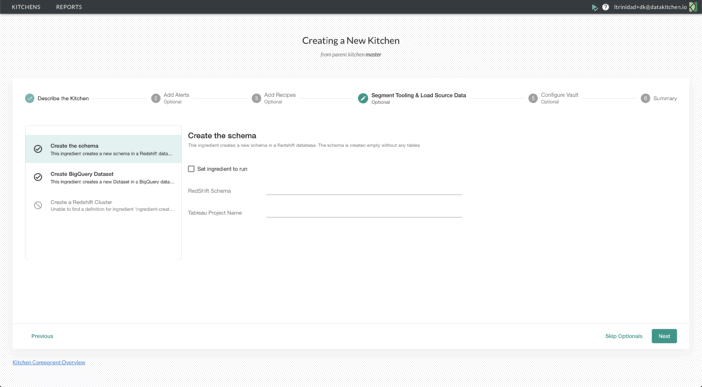
Figure 4: DataKitchen enables builders and developers to create new Kitchens autonomously using a UI.
Next Up in our Kitchen Series
We’ve discussed the relationship between Kitchens and environments and described how multiple Kitchens can share a single technical environment. In our next series of blogs, we will talk about how Kitchens integrate revision control and improve intra-team and inter-team coordination by automating manual steps that detract from productivity.


