So why another manifesto in the world? Really? Why should I care?
About seven years ago, we wrote the DataOps Manifesto. We wrote the first version because, after talking with hundreds of people at the 2016 Strata Hadoop World Conference, very few easily understood what we discussed at our booth and conference session. We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, Data Lake, or Data Science.
So on the flight black back, I wrote the draft DataOps Manifesto and sent it to some people, got some comments, and we put up a webpage. Today we have had over 20,000 signatures, millions of page views, and copycat clones, and it is frequently used as a reference guide. For example, just a few weeks ago, Microsoft announced data fabric, and John Kerski used it to frame up the discussion of how Microsoft data fabric supports DataOps principles. The DataOps Manifesto is a useful set of principles to guide your understanding of these powerful, grounded, industry-spanning ideas on improving technical team productivity, delivery quality, and cycle time in data analytics.
So today, another fundamental idea needs to be defined and given the manifesto treatment: the Data Journey. As an industry, we have a conceptual hole in how we think about data analytic systems. We put them into production but then hope all the steps that data goes through from source to customer value work out correctly. We all know that our customers frequently find data and dashboard problems. Teams are shamed and blamed for problems they didn’t cause. They have problems with the data trapped in existing complicated multi-step data processes they need help understanding, often fail, and output insights that no one trusts. I talk with data teams every few days that have the same “morning dread” I had leading data teams 15 years ago. That feeling that something is going to go wrong, you’ll have no idea how to find it, and fixing it will put off all the other tasks that need to get done.
Marketers and Customer Experience leaders have had a similar experience of dread. They need to learn customers’ interactions with their brand and marketing touchpoints. There is a crazy complexity in the path each person takes via a website, customer service team, and various other brand channels. So how could they give a consistent message? How could they improve service? The idea of a Customer Journey is very simple: a diagram that illustrates the steps your customer(s) go through in engaging with your company, whether it be a product, an online experience, a retail experience, a service, or any combination. The Customer Journey visually represents the total sum of experiences any given customer has with a brand. Automatically tracking the Customer Journey helps to inform marketing strategy and personalization efforts, improves onboarding, giving a clearer understanding of who your customers are and how the company serves them best. Software engineers have adopted a similar idea and called it a User Journey.
So as Customer Journeys have helped tame the complexity, lack of understanding, finger-pointing, and frustrated end customers in the marketing and CX world, the idea of a Data Journey is a method to watch over our data’s complicated paths, avoid problems and errors, stop customer frustration, and increase your productivity and your team’s happiness. It’s Customer Journey for data analytic systems.
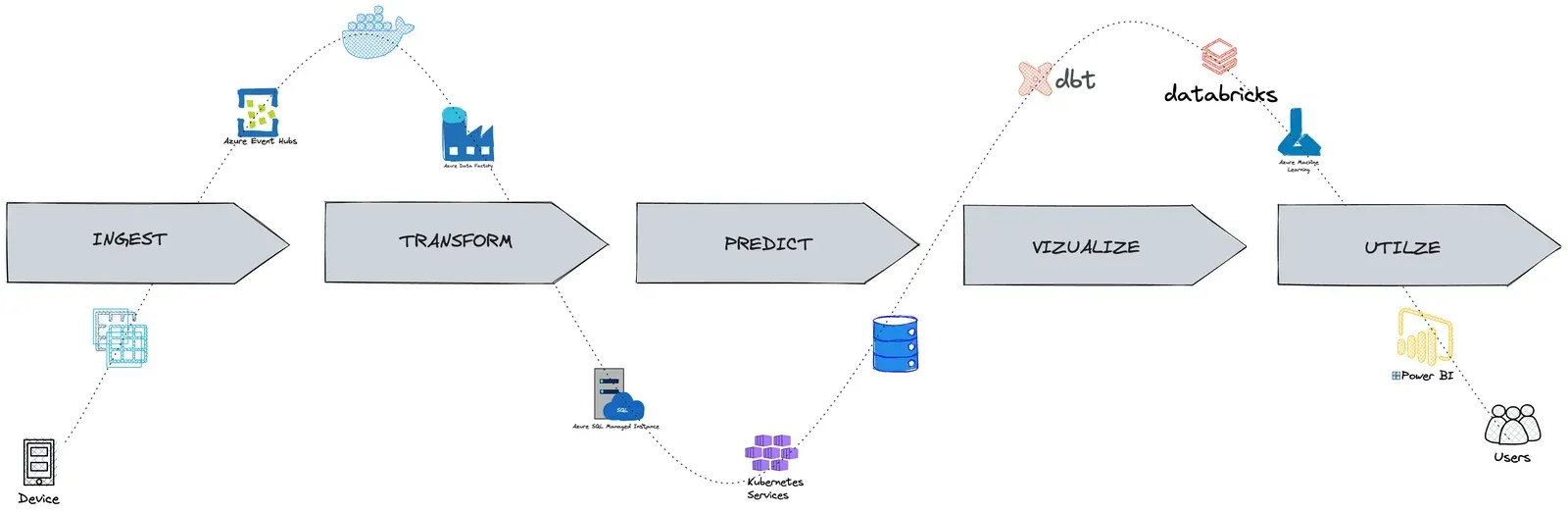
“Data Journey” refers to the various stages of data moving from collection to use in data analysis tools and systems. Much like the goal of a customer journey, a Data Journey should give you a better understanding of how, when, where, and what data flows through your data analytic systems. Data Journeys track and monitor all levels of the data estate, from data to tools to code to tests across all critical dimensions.
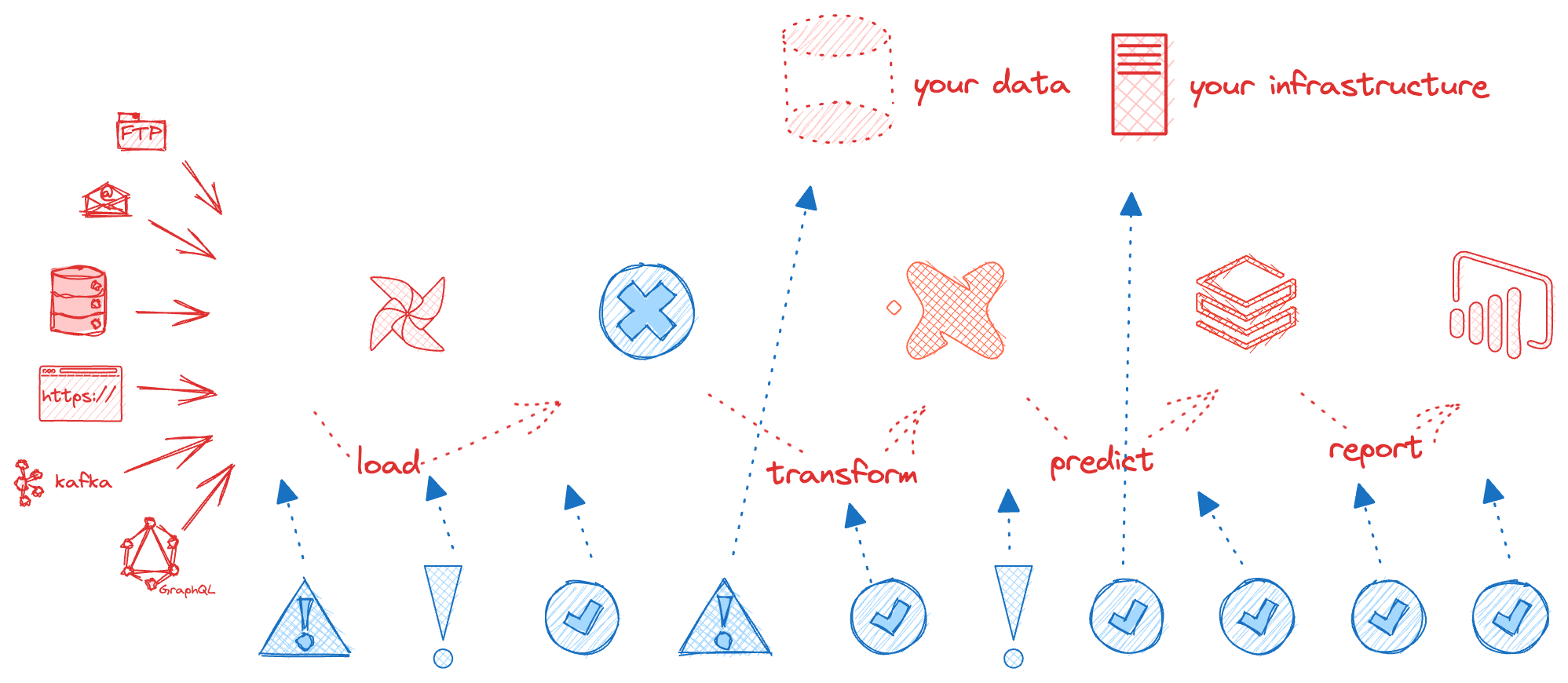
In the data world, we focus a lot on the data. If the data in your database needs to be corrected, has been transformed with errors, or is not clearly understood, then using that data will be a problem. However, you have many data tools in front of that database and behind that database: Talend, Azure Data Factory, DataBricks, Custom Tools, Custom Testing Tools, ETL Tools, Orchestrators, Data Science Tools, Dashboard Tools, bucket stores, servers, etc. Those tools work together to take data from its source and deliver it to your customers. That set of multi-tool set of expectations is a ‘Data Journey ’. The Data Journey concept is about observing, not changing, your existing data estate. Data Journeys track and monitor all levels of the data stack, from data to tools to servers to code to tests across all critical dimensions. It supplies real-time statuses and alerts on start times, processing durations, test results, costs, and infrastructure events, among other metrics. With this information, you can know if everything ran on time and without errors and immediately detect the parts that didn’t.
We continue to over-invest, as an industry, in the tools that run within our data estate. There are dozens of orchestrators, ETL Tools, databases, data science tools, data visualization tools, and data governance tools. Yet we lack a simple concept to understand, analyze, and predict all the myriad paths data takes within those tools. So we are blind to obvious errors and can’t see the effects of errors downstream on our customers. No wonder, according to a study by HFS Research, 75 percent of business executives do not trust their data, and 70 percent do not consider their data architecture “world-class.”
NOTE
<insert obligatory picture of the hundreds of data tool startups or cloud logo explosion here>
People love their tools. Data tools will continue to evolve, and as-built systems will continue to run. The Data Journey Idea is a way to increase understanding, set expectations, and measure results on the complicated data toolchain we work in today.
It’s 22 principles on one static web page. Please take a look.