Introducing DataKitchen’s Open Source Data Observability Software
Today, we announce that we have open-sourced two complete, feature-rich products that solve the data observability problem: DataOps Observervability and DataOps TestGen. With these two products, you will know if your pipelines are running without error and on time and can finally trust your data. In this blog, we peel back the curtain to share the philosophy, journey, and, most importantly, the why behind this significant move.
TIP
What is DataOps Observability?
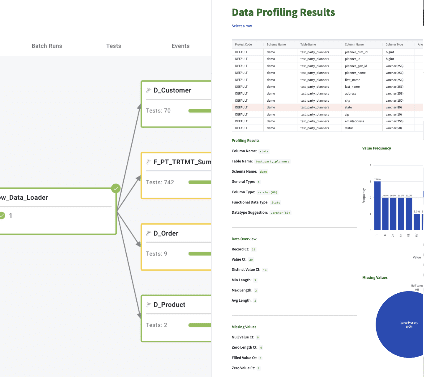
It monitors every Data Journey, from data source to customer value, across every tool, team, environment, and customer so that problems are detected, localized, and understood immediately. Imagine a world where you have end-to-end visibility instantly. That’s what DataOps Observability promises.
TIP
What is DataOps TestGen?
The most effortless way to institute comprehensive, agile data quality testing is to derive actionable information, start testing and measuring immediately, and then iterate, using tests and results to refine. DataOps TestGen is the silent warrior that ensures the integrity of your data. It simplifies data quality test generation and execution, algorithmically crafting validations that ensure you can trust your data every time it’s refreshed in production.
The Open Source Philosophy: Why Take This Road?
We’ve been a profitable customer-funded company for the last ten years. Our goal has always been to get data teams to work more productively, delivering insight with their favorite automated, observed, and trusted tools. When we started, these ideas still needed a name: DataOps. As technical founders, we have seen the challenges teams have trying to implement the DataOps Manifesto’s ideas. Our journey hasn’t been a sprint but a marathon, with varied strategies deployed to embed DataOps into the heart of data teams.
We’ve poured our insights into content, hoping to inspire teams towards DataOps. We’ve written two books, manifestos, and training programs and spoken at hundreds of conferences and podcasts. We attempted to seed DataOps at the CDO leadership level, but the transient nature of senior data leadership roles often left these initiatives adrift. For years, we tried to get teams from senior leaders to adopt DataOps centrally. However, senior data leaders in data teams have a short tenure, 1-2 years, and when they leave, the initiative on DataOps disappears. It’s possible but tricky. From a technology angle, we tried to go from deployment first with our DataOps Automation product – orchestrate, deploy, test, DevOps, everything in one run time abstraction. However, very few people start from a single orchestrator encompassing their entire toolchain. Everyone builds, builds, and builds, then worries about the errors in production and deployment cycle time on days two and three (if at all).
Over the last three years, we’ve invested over $5 million in developing our Data Observability tools. We still hope to make a difference in the dismal lives of data teams by starting their path to DataOps, observing their entire Data Journey, and quickly deploying data quality validation tests.
We’ve realized that a bottom-up approach, starting with the individual, stands a better chance of embedding DataOps into the fabric of data teams than transient leadership mandates, making teams change what they have already built or just talking about these ideas. Open-sourcing DataOps Observability and TestGen are steps towards fulfilling this vision, aiming to alleviate the “morning dread” many data engineers face, haunted by the possibility of errors and the daunting task of resolving them.
We are sharing two full-featured, battle-tested applications with a complete UI and APIs for an individual to use. We are also capitalists, so we have an enterprise version of each tool we think teams and enterprises will find advantageous. Companies like Eisai, BMS, CNH, and others already use it in production today. Our enterprise version is for teams and foundational for enterprises.
Two years ago, we surveyed 700 data engineers and found that 78% found their jobs so dismal they wanted to come with a therapist. We hope that our open-source data observability tools will make a difference in those individual lives.
What Makes These Tools Unique?
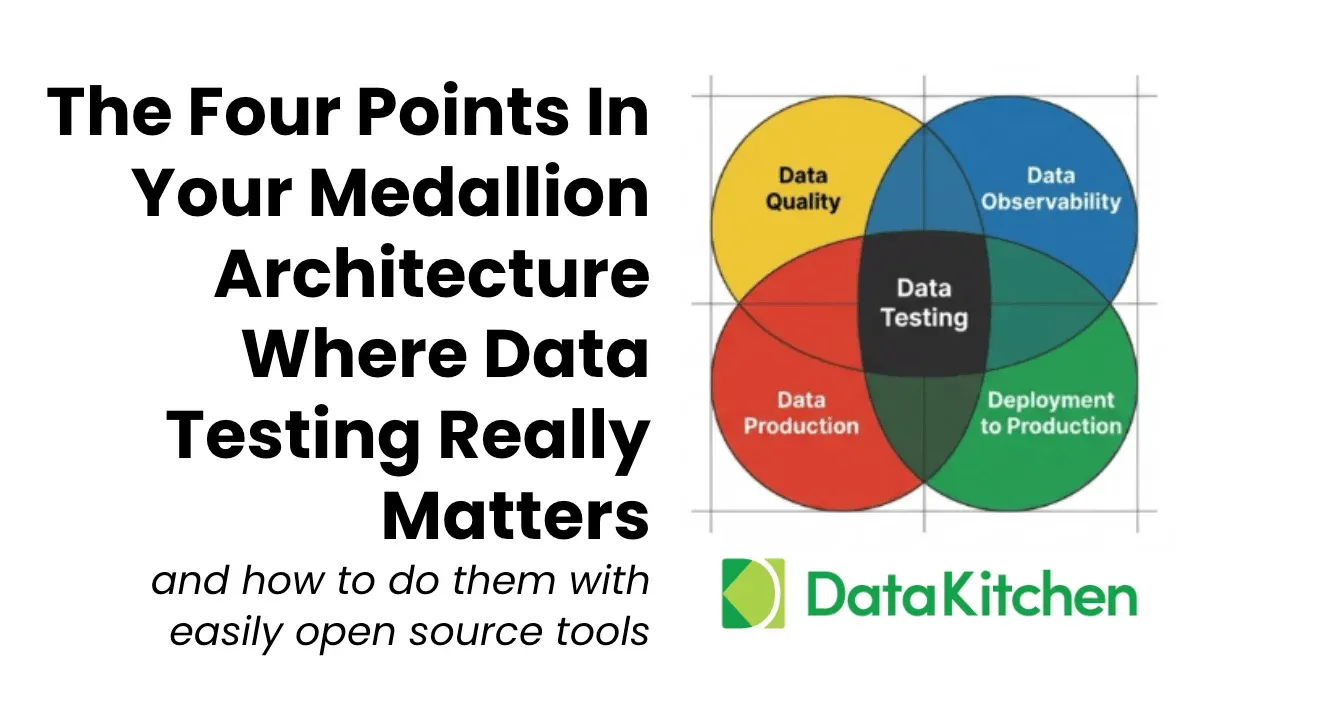
The Data Journey. Plenty of workflow tools run DAGs, steps, and schedules. However, another fundamental idea must be defined and given an open-source treatment: the Data Journey. As an industry, we have a conceptual hole in how we think about data analytic systems. We put them into production, but then we hope all the steps that data goes through from source to customer value work out correctly. We all know that our customers frequently find data and dashboard problems. Teams are shamed and blamed for problems they didn’t cause. They have problems with the data trapped in existing complicated multi-step data processes they need help understanding, often fail, and output insights that no one trusts. A Data Journey is the missing abstraction from our data analytic systems – the tool to say what should b e rather than what will be. It’s not an Airflow DAG, nor is it data lineage. It’s the fire alarm panel for your data and data analytic product process. It’s the mission control panel for your data production.
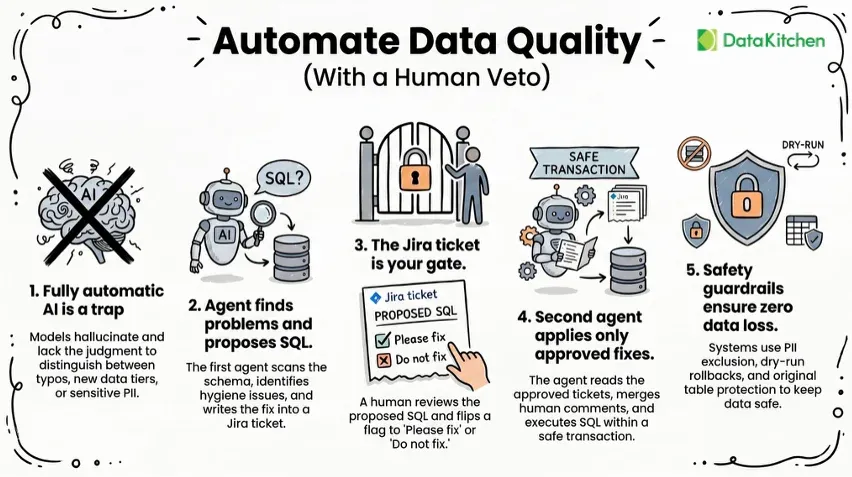
Fully Automated Data Quality Test Generation. We’ve been talking and writing about data quality validation for a decade. We’ve been doing this in practice for almost twenty years. However, I am continually amazed at how few data teams have any data testing in production. They just hope things don’t go wrong. For many years, I had the former software engineer bias – just write the damn data test yourself. But,knowing which test to write is challenging for data engineers. They are crushed with responding to errors, working on new tasks, and staying sane. They need a way to auto-create a test that gives them a high degree of assurance that their data is correct. And a way to configure more tests. And have a single repository of tests that can be co-owned by data specialists and their business customers. DataOps TestGen is not a DSL for data testing or a pick-and-choose library of tests. DataOps Observability saves teams time and accelerates testing and anomaly detection on data.

What are these tools for?
You, the data engineer or data analytic team technical team lead, are our focus. We understand the pressure of errors, the overload of tasks, and the desire for solutions that are quick, comprehensive, and easy to implement. Our open-source tools are designed to offer immediate value, enabling you to tackle specific use cases and start small, scaling as needed. We’ve built integration to tools like DBT, AIrflow, and a dozen other tools that act upon data. We have a rich, simple API and ‘agent framework’ to add new monitoring tools. TestGen supports major SQL databases like Postgres, Snowflake, SQL Server, Synapse, and Redshift, with more coming.
Our Design Criteria: Simplicity and Functionality
Our design ethos aligns with UNIX principles—“Make each program do one thing well.” DataOps Observability and TestGen embody simplicity, flexibility, and expansiveness, catering to every tool and aspect of the data analytic ecosystem. We aim for our open-source tools to be fully functional for individuals. And fit as good citizens in your data estate.
What can I do with these tools?
Like any new idea, the definition of Data Observability is changing. Our goal is to cover all the use cases of monitoring data and your data estate for issues, including:
- Understanding And Check Data Pre-Production: “Patch Or Pushback Data”
- Finding Problems In Constantly Changing Data With Anomaly Detection: “Polling: Arrival Abberation Alerts”
- Locating Problems During Production Before Your Customers: “Production: Check Down and Across”
- Data Observability in Development “Productivity: Regression and Impact Assessment, Data Migration”
An Invitation to Collaborate
As we open the doors to our open-source tools, we extend an invitation to the community. Your feedback, contributions, and insights are invaluable as we evolve these products. Join us on this path, explore our getting started guide, and become part of our Slack community. Together, let’s redefine data observability and ensure that the path to DataOps is not just a vision but a tangible reality for data teams worldwide. It’s simple to install and has a short walk-through that you can try today.