
Everyone wants AI to answer business questions with their data. The reality is most AI assistants built on enterprise data give mediocre, unreliable, or outright wrong answers — not because the AI is bad, but because the foundation underneath it is.
Your AI chatbot is lying to you. Not maliciously. Confidently. It queries your data warehouse, assembles an answer, and presents it with the same tone whether the underlying data is fresh, tested, and correctly joined, or three days stale, never validated, and pulled from a deprecated table nobody deleted in 2021.
This is the AI-on-data problem nobody wants to say out loud: the model is fine. The data underneath it is the disaster. Every hallucination, every wrong answer, every time an analyst says “I don’t trust what the chatbot told me” — that is a data infrastructure failure dressed up as an AI failure.

Everyone assumes AI fails at data analysis because the models are not smart enough. The MIT BEAVER study (September 2024) decisively disproves that assumption. When researchers tested leading LLMs against real enterprise data warehouses, models that had scored above 85% accuracy on standard benchmarks collapsed to nearly zero end-to-end execution accuracy on actual business data. The model did not get dumber. The context disappeared. Enterprise schemas were too complex, business questions required joins across many tables and nested aggregations, and the models had never encountered the private data they were suddenly being asked to reason about. When researchers simply handed the models the correct table and column context, performance recovered sharply. The intelligence was there the whole time. What was missing was the foundation underneath it.
OpenAI’s look insideits internal data agent (January 2026) reveals something subtle but important: raw data alone is not enough to produce useful insights. Their teams do not just query tables; they ask questions that are grounded in context, such as product launches, feature changes, and user behavior patterns, and the system uses that surrounding knowledge to interpret results. The same metric can mean very different things depending on what was happening in the business at the time, which is why simple SQL outputs often fall short. By combining data with context, their approach turns analysis into something closer to reasoning rather than reporting. The result is that the same data that once produced ambiguity now produces insight, dramatically reducing errors across thousands of employees working on tens of thousands of datasets. It highlights a fundamental truth about data engineering: raw data alone is not enough. The intelligence was already there, but without context, it was incomplete. What was missing was the foundation that connects data to meaning.
A comprehensive survey of LLM-based text-to-SQL systems published on arXiv (updated through late 2025) finds that generating accurate SQL from natural language remains a long-standing challenge, specifically because of the complexities involved in database schema comprehension, and that the problem compounds as databases grow more complex. A separate ACM Computing Surveys paper on LLMs for text-to-SQL tasks found that domain-specific knowledge is critical, and that performance degrades significantly without additional SQL knowledge and external commonsense context. A 2025 arXiv paper on long-context LLMs for natural language to SQL demonstrated empirically that additional contextual information about column references, user-provided hints for clarification, and schema metadata all directly improve execution accuracy, with smaller models benefiting the most from richer context. A 2025 survey from the Journal of the American Statistical Association on LLM-based data agents echoes this theme, noting that LLM-powered data science agents have shown significant potential to transform data analysis, but their role depends on how well the system simplifies complex data tasks for users without deep expertise in the underlying schemas.
The gap comes down to three things. Your team does not fully trust the data the AI is querying. The schema the AI navigates is a graveyard of 150 tables, half of them wrong for the question being asked. And the AI has no idea what your business actually means by “equalized prescriptions” or “territory alignment.” It is a guess. It is always guessing.
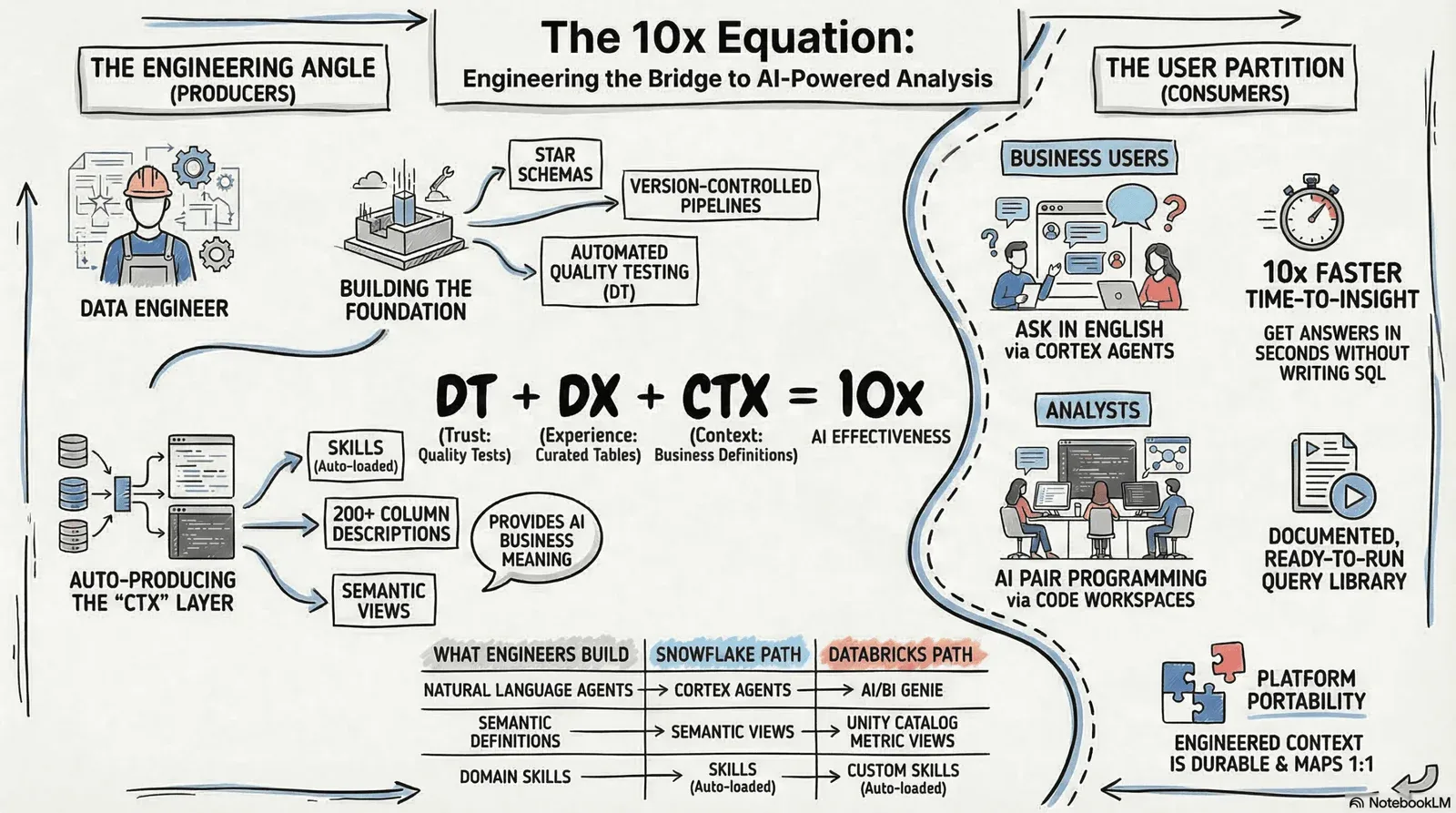
Fix those three things, and the picture changes. Not incrementally. Fundamentally. We call it the 10x equation:
DT + DX + CTX = 10x Faster Data Analyis With AI
Data Trust. Data Experience. Context. This is not a theory. It is a checklist for the infrastructure work that makes AI analysis reliable, accurate, and genuinely useful. This is our experience with customers solving this challenge. Let’s break it down.
DT — Data Trust
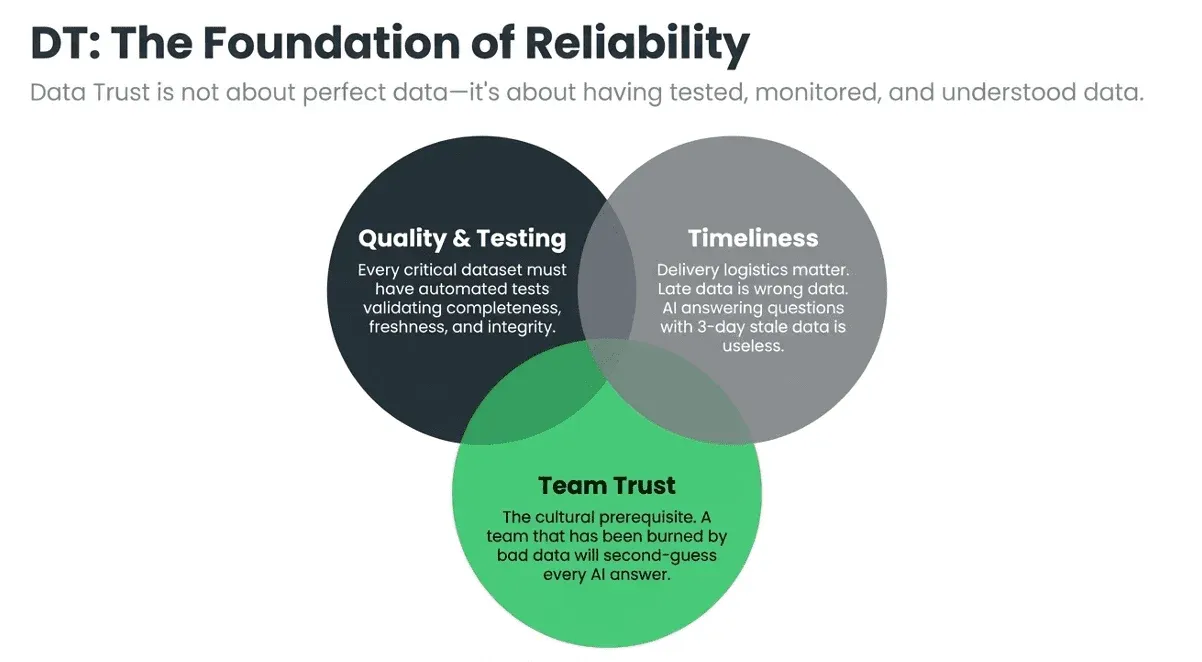
The first term in the equation is the most foundational: your team must be able to trust the data before AI can use it reliably. Data Trust is not about having perfect data — it’s about having tested, monitored, and understood data, delivered to the right people at the right time.
What Data Trust Means in Practice
Data Trust has four components that work together:
- Quality & Testing: Data quality and testing — Every critical dataset has automated tests validating completeness, freshness, referential integrity, value ranges, and statistical distributions. If a column is supposed to have non-null values, there is a test that fails loudly when it doesn’t.
- Timeliness: Arrival time and delivery logistics — The right data arrives on time. Late data is wrong data. If the AI is answering questions about yesterday’s sales using 3-day-old data, every answer is wrong, regardless of the model’s quality.
- Team Trust: Team trust — Humans using AI outputs need confidence that the underlying data is reliable. This is cultural as much as technical. A team that has burned bad data will second-guess every AI answer — often correctly.
- The Intersection: Right data, right quality, right time — Data Trust is the intersection of all three: the right dataset, verified to an acceptable quality threshold, available when the business needs it.
Why This Is the Foundation
AI models are amplifiers. They make whatever is underneath them faster and more accessible. If what is underneath them is untrustworthy data, AI amplifies bad answers at scale and speed. Data Trust is the prerequisite for everything else in the equation.
Tools like TestGen provide over 120 AI-driven data quality tests that can be applied to any dataset. They automatically profile schemas, flag anomalies, and surface data issues before they reach analysts or AI systems. This foundation is the infrastructure of Data Trust.
DX — Data Experience
Even if your data is trustworthy, AI and analysts alike will struggle if the experience of working with that data is confusing. Data Experience (DX) is about making data legible — a schema design that humans and AI can both read, understand, and use without becoming database archaeologists.
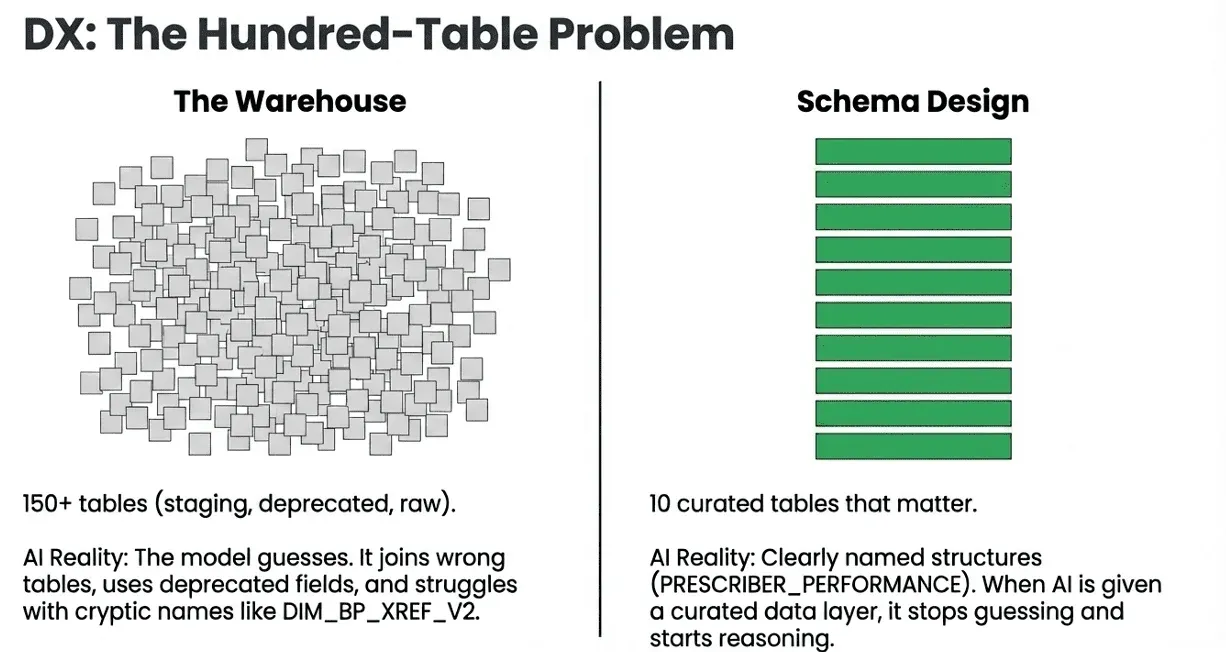
The Hundred-Table Problem
Most data warehouses and lakehouses have accumulated tables over years of work: staging tables, intermediate tables, deprecated views, experimental datasets, and duplicates from three different ETL eras. Nobody deletes anything.
When an AI assistant is given access to a data environment with 150 tables, several bad things happen: The model has to guess which tables are relevant to any given question. It will frequently choose the wrong option, joining tables that are technically related but semantically incorrect. Even when it chooses right, it may use deprecated fields, wrong grain, or mismatched time zones. Performance degrades because the AI explores a vast, confusing space rather than a focused, curated one.
The Solution: Ten Tables That Matter
A good data experience means curating the data landscape. Instead of exposing every table in your warehouse, you build a semantic layer — ten (or twenty, or thirty) clearly named, well-structured tables that represent the core business concepts an analyst or AI needs.
This is not about hiding data. It is about creating a front door. The warehouse can have 150 tables; the AI and the analyst should see the 10 that matter for their domain, with names and structures that make sense.
Good Data Experience looks like: Table names that say what they contain: PRESCRIBER_PERFORMANCE, not DIM_HCP_XREF_V2. Columns named for business concepts: EQUALIZED_PRESCRIPTIONS, not EQ_TRX. Consistent grain and join keys are documented explicitly. No ambiguous foreign keys — if there are multiple ways to join two tables, the right way is marked.
When AI is given a well-structured, curated data layer, it stops guessing and starts reasoning. That is a qualitative shift in output quality.
CTX — Context
Context is the multiplier. It is the difference between an AI assistant that can technically query your database and one that actually understands your business. Context (CTX) is data about data — the accumulated knowledge that turns a generic language model into a domain expert.

Why AI Needs Context, Not Just Data
Here is the core problem. When you connect an AI to a data warehouse, it sees this:
PRODGRP_NO VARCHAR(9)
HCP_ID NUMBER
EQ_TRX NUMBER(38,6)Three columns. Three cryptic names. No business meaning. The AI has no idea what these columns are, what they measure, how they relate to other tables, or what assumptions apply to their values.
Without context, the AI is making educated guesses dressed up as answers.
Apply Context to the same data. Completely different capability. The AI now knows what it’s looking at, how to join it correctly, and what the values mean. Context turns a generic chatbot into a pharma analytics expert.
What Context Includes
Context is a broad category that covers several types of information:
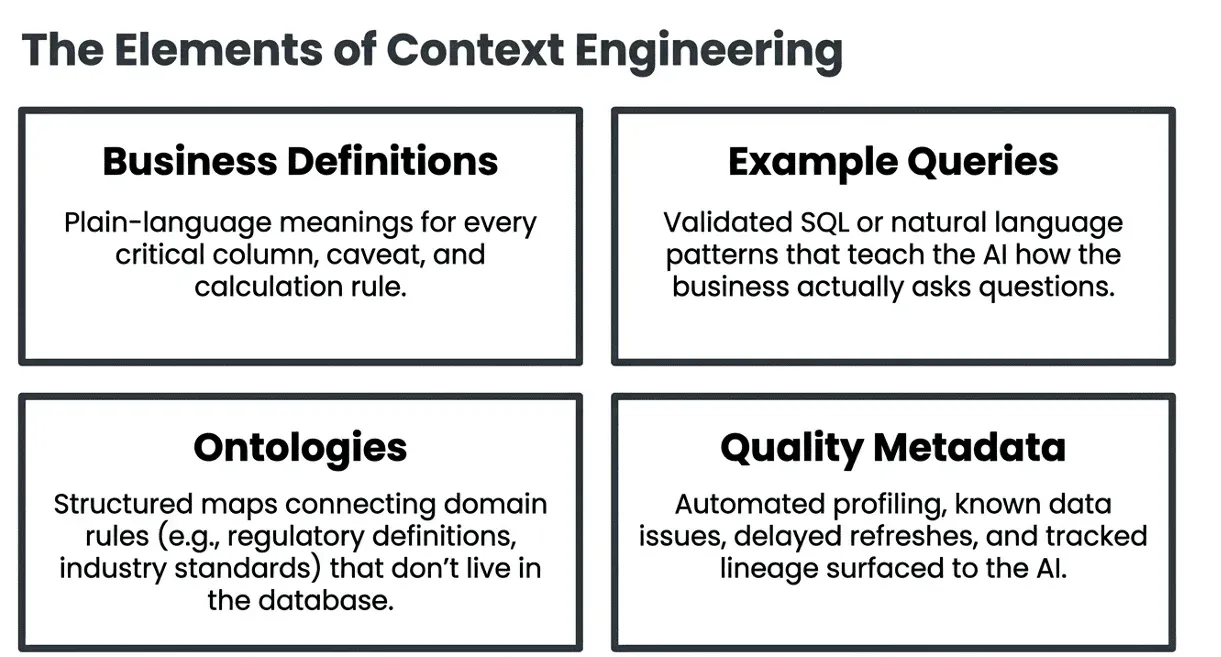
Business Definitions and Column Annotations
Every column that matters should have a plain-language definition, the business question it answers, and any caveats about how it is calculated or when it is valid. This can live in a data catalog, a README, or a structured metadata layer.
Example Queries
One of the most effective ways to provide context is through example queries — SQL or natural-language queries that have been validated and annotated with the correct answer. These help teach the AI how your business asks questions and what proper answers look like.
“What were total equalized prescriptions for product group X in Q3?” → annotated SQL with correct join path.
“Which territories exceeded their prescription targets last month?” → annotated SQL with correct grain and filter logic.
Ontologies and Domain Knowledge
In industries like pharma, finance, or healthcare, there are layers of domain knowledge that aren’t captured in the data itself: regulatory definitions, industry standards, and business rules that arise from how the market operates rather than how the database is structured.
Providing the AI with an ontology — a structured map of how business concepts connect — greatly enhances the accuracy of answers to domain-specific questions.
Data Quality Metadata
Context also includes what you know about data quality. If a specific field has known data issues on certain dates, that counts as context. If a table’s refresh is delayed on Mondays, that is the context. If a column is deprecated and shouldn’t be used for new analysis, that is the context. DataOps Observability automatically surfaces this kind of metadata — tracking pipeline health, data freshness, test results, and lineage — and can feed it into AI context layers so the AI understands what it can and cannot rely on.
Schema Profiling and Lineage
Automated schema profiling captures the statistical shape of your data: value distributions, null rates, cardinality, min/max ranges, and update frequency. Lineage traces the source of data and the transformations it has undergone. Both are essential contexts for an AI that is reasoning about data reliability and joins.
Putting It Together: The 10x Effect
Individually, DT, DX, and CTX each enhance AI-powered data analysis. Together, they create a multiplying effect. A team with Data Trust knows its AI answers are based on trustworthy data. A team with strong Data Experience ensures the AI is working with the correct tables and columns. A team that has invested in Context understands the business well enough for the AI to ask the right questions. The result isn’t just slightly better — it’s fundamentally different. Analysts spend less time validating AI outputs and more time generating insights. Business users feel more confident trusting AI answers and start developing workflows that depend on them.

A Note for Data Engineering Teams
The work described here — building data quality tests, curating semantic layers, writing business definitions, maintaining ontologies — is data engineering work. It is not glamorous. It does not ship in a sprint. But it is the infrastructure on which AI-powered analytics is built.
Every hour invested in DT, DX, and CTX reduces the hours spent debugging AI outputs by an order of magnitude. The equation is as much about return on investment as it is about architecture.
Getting Started
You don’t have to solve all three dimensions at once. Start where the pain is greatest:
Start with DT: If your team doesn’t trust the data, start with DT. Run automated quality tests on your most critical tables. Use TestGen or a similar tool to profile your schemas and surface issues.
Start with DX: If analysts are wasting time navigating a confusing data landscape, begin there. Identify the ten tables that answer 80% of your business questions and build a clean semantic layer over them.
Start with CTX: If your AI gives technically correct but business-wise wrong answers, start with CTX. Write business definitions for your most important columns. Add five example queries. Build a data dictionary for the domain in which your AI operates.
The equation does not require perfection in any dimension. It requires meaningful progress in all three. A little more trust, a cleaner experience, and richer context compound into dramatically better AI-powered analysis.

Real-World Example: Commercial Pharma Analytics on Snowflake & Databricks
The DT + DX + CTX framework is not abstract. Here is what it looks like deployed against a real pharma data environment running on Snowflake, with IQVIA data, field sales teams, and analysts who need answers without writing SQL.
The Architecture: Two Paths, One Foundation
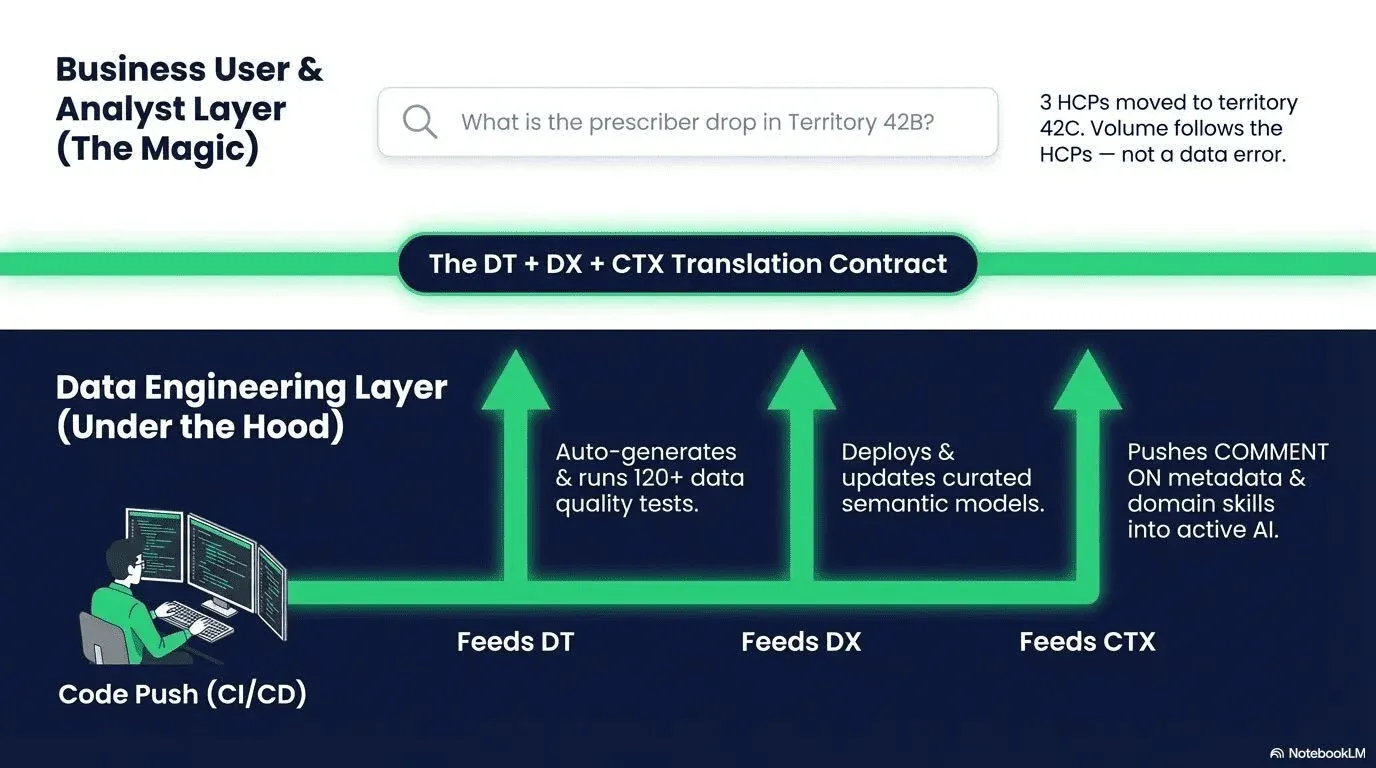
When context engineering is done properly, it enables two distinct AI-powered analytics modes to run simultaneously — both on the same underlying data foundation.
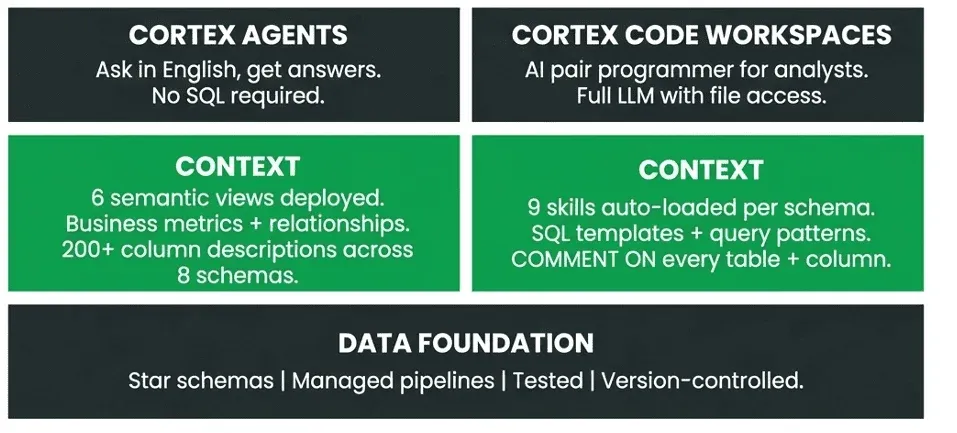
Both paths run on the same data foundation — star schemas, managed pipelines, tested and version-controlled. Context is what makes both accurate. Both paths are running simultaneously on production data.
Example: The Clarity Ticket Agent
With the right data foundation, context, and AI tooling in place, entirely new workflows become possible. Here is one concrete use case: an agent that automatically handles tickets for field data discrepancies.
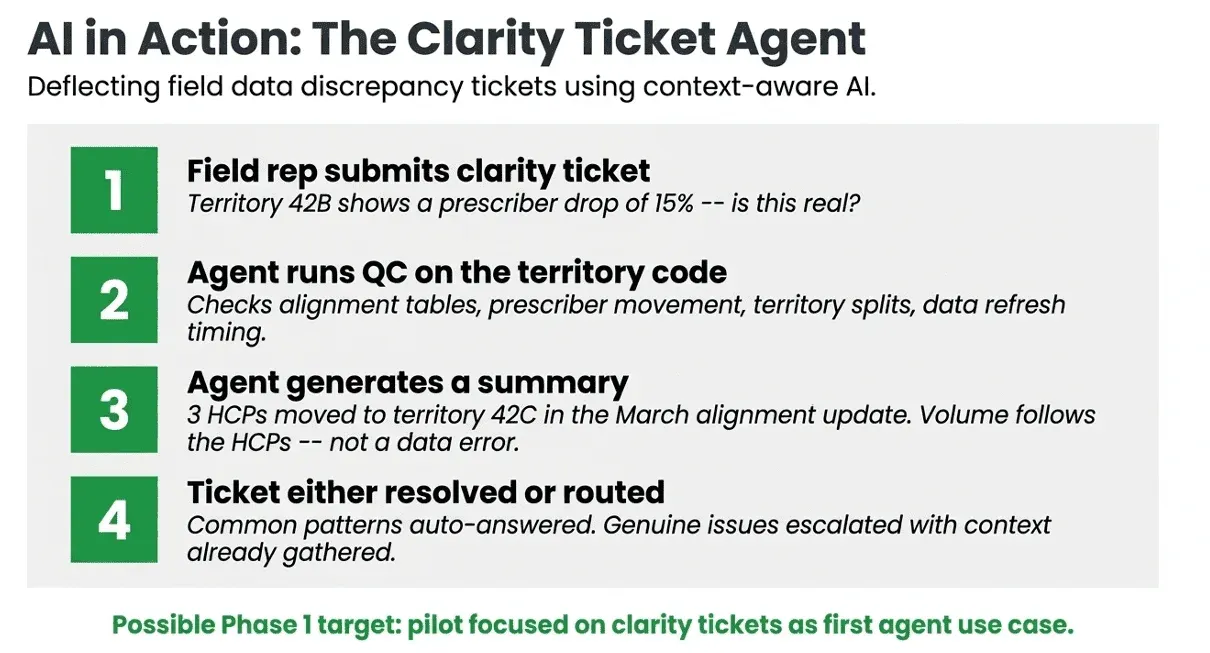
Field reps routinely submit tickets when the data does not match their expectations — a territory showing a sudden drop in prescribers, a product group with anomalous volume. This report does not reconcile with what they see in the field. Today, these tickets are routed to analysts. With a context-aware AI agent, many can be resolved instantly:
This agent is possible only because the data underneath it is trusted (DT), the schema is navigable (DX), and the context layer understands what territory alignment tables mean, how HCP movement is recorded, and what data refresh timing looks like (CTX). Without all three, the agent would hallucinate or confidently give wrong answers.
What the Team Actually Gets
When DT + DX + CTX is in place, the benefits are not uniform across the organization — they are specific to each type of user:

Context Engineering Is Platform-Portable
One important property of the CTX investment is its durability. The context you build — business definitions, semantic views, query patterns, domain skills — maps directly across platforms. If your organization moves from Snowflake to Databricks, or runs both, the content travels with you.
| What We Build | Snowflake | Databricks |
|---|---|---|
| Natural language agents | Cortex Agents | AI/BI Genie |
| Semantic definitions | Semantic Views | Unity Catalog Metric Views |
| Verified/trusted queries | Verified Queries | Trusted Assets |
| AI coding assistant | Cortex Code | Databricks Assistant |
| Domain skills | Skills (auto-loaded) | Custom Skills (auto-loaded) |
| Feedback & observability | AI Observability Events | MLflow Tracing |
Your investment in context engineering is durable. The platform is just where it runs.
Conclusion
The promise of AI-powered data analysis is real. Natural language queries, automated insight generation, and super-powered data analysis — these capabilities are available today. But they only deliver their full value when the data underneath them is trustworthy, legible, and enriched with context.

DT + DX + CTX = 10x is not a slogan. It is a checklist for the infrastructure work that makes AI analysis reliable, accurate, and genuinely useful to the people who depend on it.
The teams that will win with AI are not the ones that deploy the most sophisticated models. They are the ones who do the foundational data work that makes any model effective.
An Addendum for Data Engineering
The 10x opportunity from LLMs is not limited to analysts. Data engineers building pipelines face the same foundational challenge: AI is an amplifier, and if the data flowing through those pipelines is untrustworthy, poorly tested, or missing operational context, it can amplify bad outputs at scale. We have a companion framework for that challenge in The Equation for AI Success: Claude Code (DataOps + FITT + Data Testing) = 10x Data Engineering. Where this post addresses how analysts make their data legible, trusted, and context-rich enough for AI to reason over it reliably, that one addresses how data engineers build the pipelines that make AI safe and productive. The two equations are meant to work together.
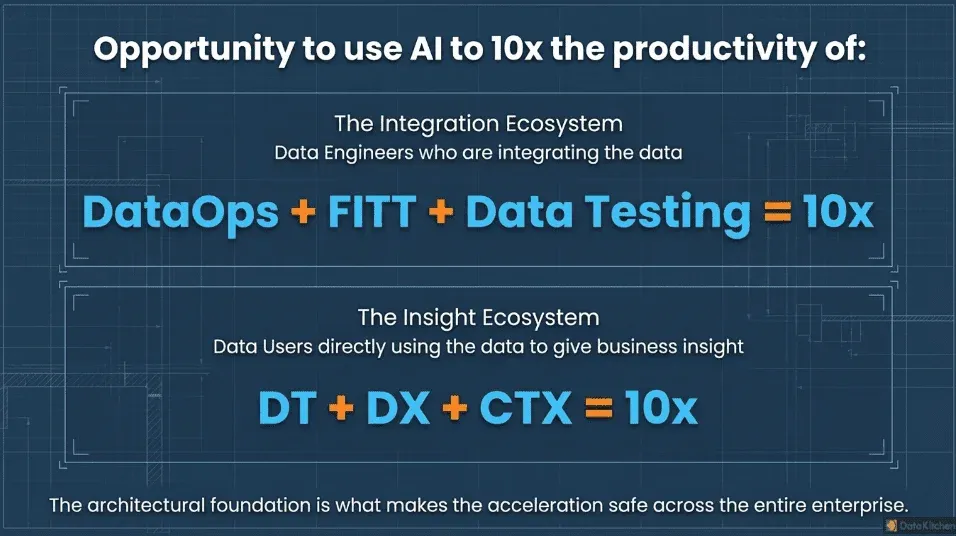
Read the companion piece: The Equation for AI Success: Claude Code + DataOps + FITT + Data Testing = 10x
TIP
Want to learn more? Watch the webinar: Context Engineering for Success In AI Data Analysis



