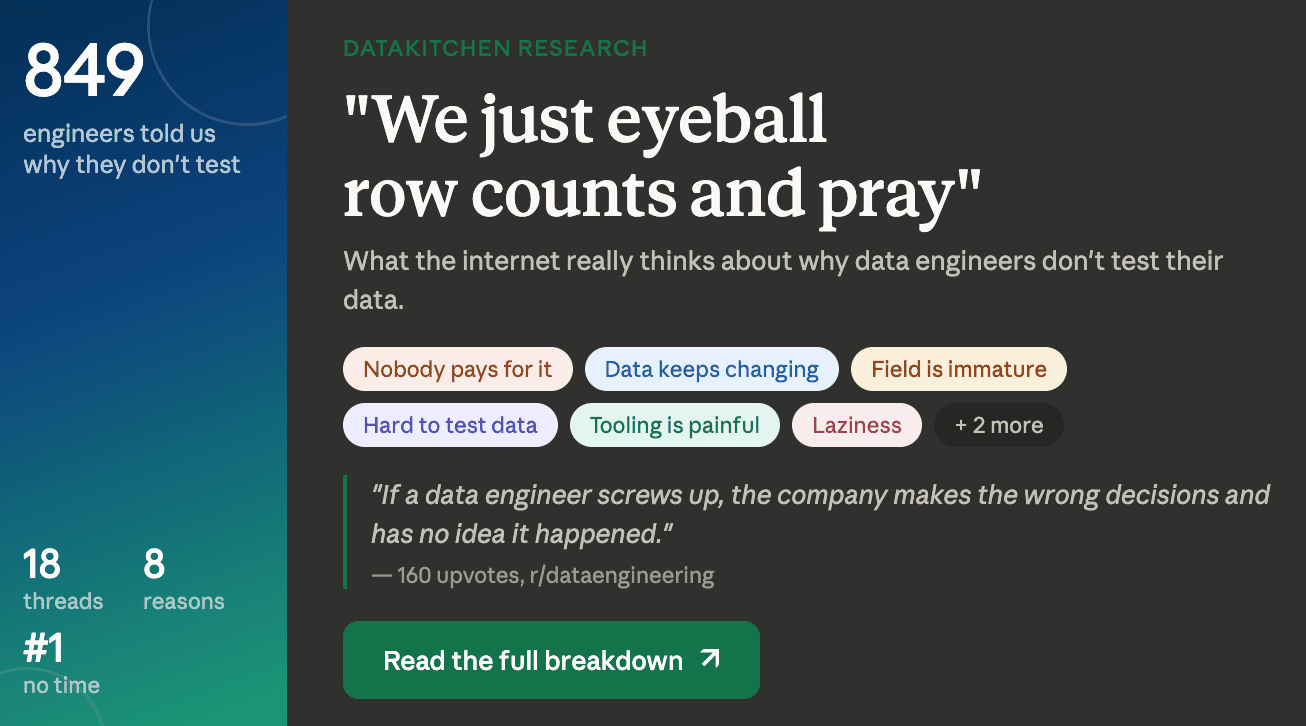
What Internet Communities Really Think About Why Data Engineers Don’t Test
TL;DR: We read 849 comments across 18 community threads on Reddit, Hacker News, Stack Overflow, and the dbt Community Forum. The #1 reason data engineers don’t test: nobody gives them the time. The #2 reason: the data changes faster than the tests can keep up. Here’s the full breakdown, in their own words.
The fastest way to get a data engineer to type a thousand words is to ask them why they don’t write tests.
That is what happened across a series of threads on Reddit, Hacker News, Stack Overflow, and the dbt Community Forum over the past couple of years. The conversations drew hundreds of comments from working data engineers, and what emerged was not a polished conference talk on best practices. It was something far more honest and far more useful: a messy, funny, occasionally brutal group therapy session about the state of quality in data engineering.

A few weeks ago, Gil asked a question, ‘Why Data Engineers Don’t Test?’ and got 50 answers (and was roasted for having ulterior motives). But what if we expand our search? So we asked Claude AI to read every comment across 18 of these threads, for a total of 849 comments. What follows is what the community actually said, in their own words, about why data engineers do not test their data, and what they think might fix it.
The Confession Booth
The most upvoted comment in the first Reddit thread set the tone immediately. User takenorinvalid, scoring 160 points, wrote: “What we do is have no QA framework in place, not realize the data is wrong for months or even years, and then blame each other when it comes out.”
That is not someone being flippant. That is someone describing Tuesday.
The same commenter articulated what might be the single most important insight in all eighteen threads: “Data Engineering is invisible. If a software engineer screws up, the app stops working, and everybody knows it. If a data engineer screws up, the company makes the wrong decisions and has no idea it happened.”
This observation echoed across every platform. On Hacker News, a commenter noted that “the successful operation of a pipeline doesn’t conclusively determine whether the data is actually correct for the end user.” On Reddit, doryllis put it more bluntly: “The biggest danger in data engineering is that no matter how wrong your query or data, if you write it so it works, it returns results. Results, but not necessarily correct ones.”
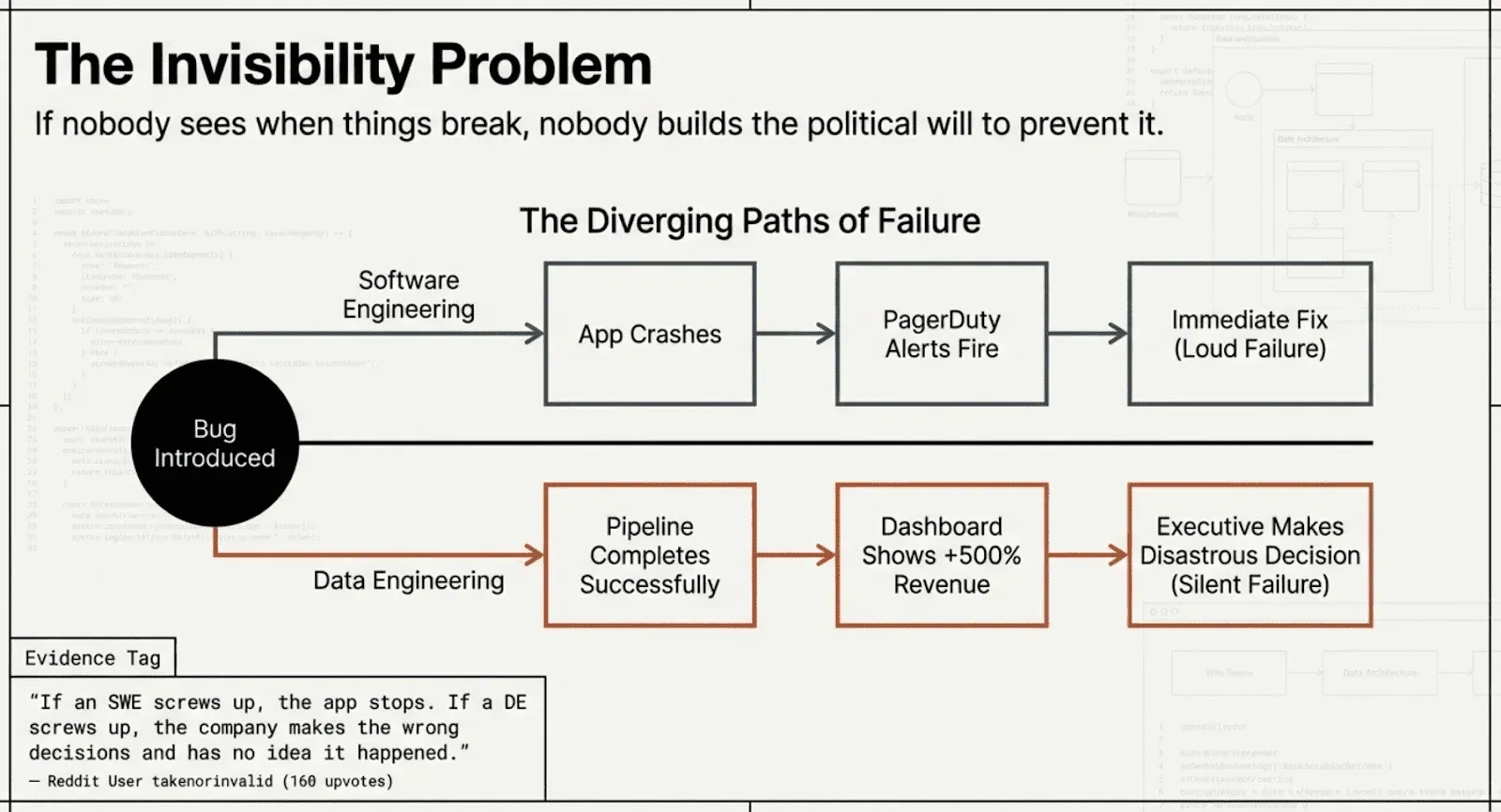
The invisibility problem is not just philosophical. It directly explains why testing gets deprioritized. If nobody can see when things are broken, nobody builds the political will to prevent breakage. On the “There is no data engineering roadmap” Hacker News thread, Simon_O_Rourke nailed this: “if you do an absolutely superb job you end up being largely invisible to the business. Like the very necessary guys who fix the water mains or the sewers, the expectation is that the service/data pipeline/database will be always available, and nobody really cares too much either way once everything’s working as expected.” And steveBK123 added the economic punchline: “DQ is a big part of it as well. Everyone wants it, no one wants to pay the hours/dollars to do it. No one is sure what they want, but probably what you propose is too simple. Can’t AI do it? Etc.”
As user trentsiggy observed on Reddit: “Testing should be non-negotiable. It only becomes negotiable in immature environments.” And then, with the weary realism of someone who has seen a few things: “Sometimes, you have single DEs or a tiny team of them at a company that has drastically underfunded their data needs who are trying to string 40 exec level demands together with bailing twine and duct tape, with an exec team that fires anyone who pushes back against it.”
Data Engineering Is Not Software Engineering, and That Is the Setup
Before we get into the ranked reasons, it helps to understand a point the community made forcefully across every thread: data engineering is simply not software engineering, and trying to port SWE testing practices directly into the data world is a category error.
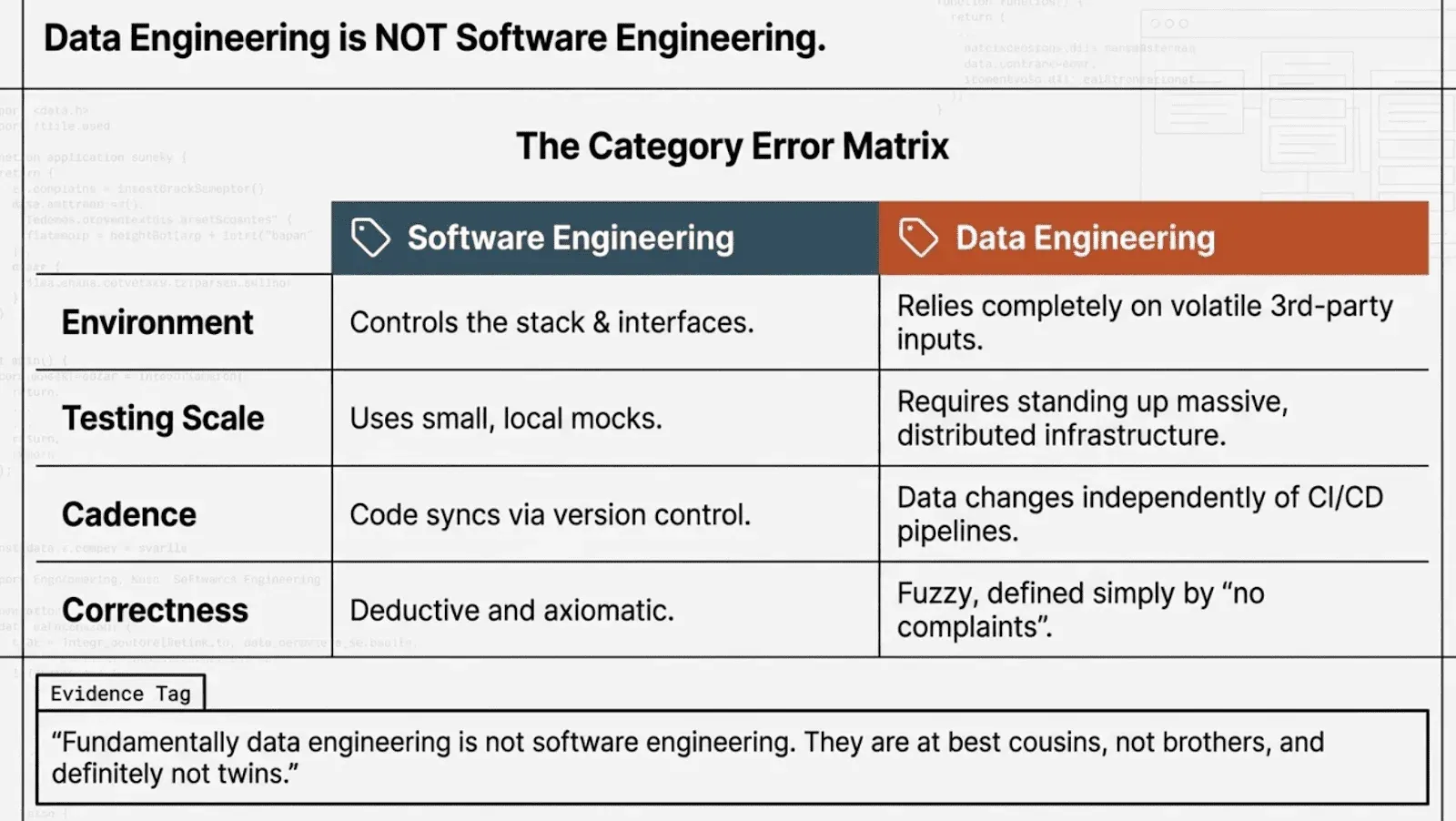
User naijaboiler, with 45 upvotes, put it plainly: “fundamentally data engineering is not software engineering. They are at best cousins, not brothers, and definitely not twins.” MonochromeDinosaur captured the asymmetry: “Testing in SWE is easier because you usually control most of the stack and interfaces. Third party integrations/APIs usually respect their contracts more when it’s webdev related. When you need fixtures and mocks they’re relatively small.” And on Hacker News, azirale painted the full picture: “Imagine if you wanted to test the inputs and outputs of a function you had to stand up an entire infra stack, run the full application, push significant data into it, then run your test.”
That is the context. Now, here is what data engineers say when you ask them specifically why they do not test.
The Eight Reasons, Ranked
Reading across all eighteen sources, the reasons data engineers do not test cluster into a remarkably consistent set of themes. We tagged every comment that cited a reason, counted each comment at most once per reason, and ranked them. The ordering was not subtle.
#1. Nobody will pay for it (40 mentions). This was the runaway winner, and it was not even close. When data engineers explain why they do not test, the answer most often is not technical. It is organizational.
FaithlessnessNo7800 was brutally honest: “we get paid for quick results, not well-developed results. In fact, we’ll get paid more for delivering half-baked pipelines riddled with technical debt because we’re the only ones who can fix it. So, there’s no real incentive to implement solid testing. Plus, stakeholders are rarely willing to pay for it.”

PotokDes pushed back on that logic: “I’ve had to do those investigations under tight SLAs, and I wouldn’t wish that experience on anyone. For me, that’s the strongest reason to invest in good testing: I hate debugging SQL across dozens of models, each with multiple layers of CTEs. It’s a nightmare.” But then FaithlessnessNo7800 came back with the structural problem: “if the decision makers don’t care about it, it will not become an organizational standard. And if there are no obvious incentives to it, only few developers will actually care enough to implement it.”
That exchange captures the whole dynamic. Individual engineers know testing saves time. Organizations refuse to allocate the time to save.
#2. Data and schema change constantly (20 mentions). The “we don’t control the inputs” problem. Several commenters pointed out that the source data itself is a moving target. NaturalBornLucker described the cycle: “there are some unit tests that previous team did but they are already outdated and obsolete and I disabled some of them. It’s like there’s some fine logic and thought in them but all that work is entirely unnecessary. And if one of table schemas is changed they fail and you need new test DataFrames.”
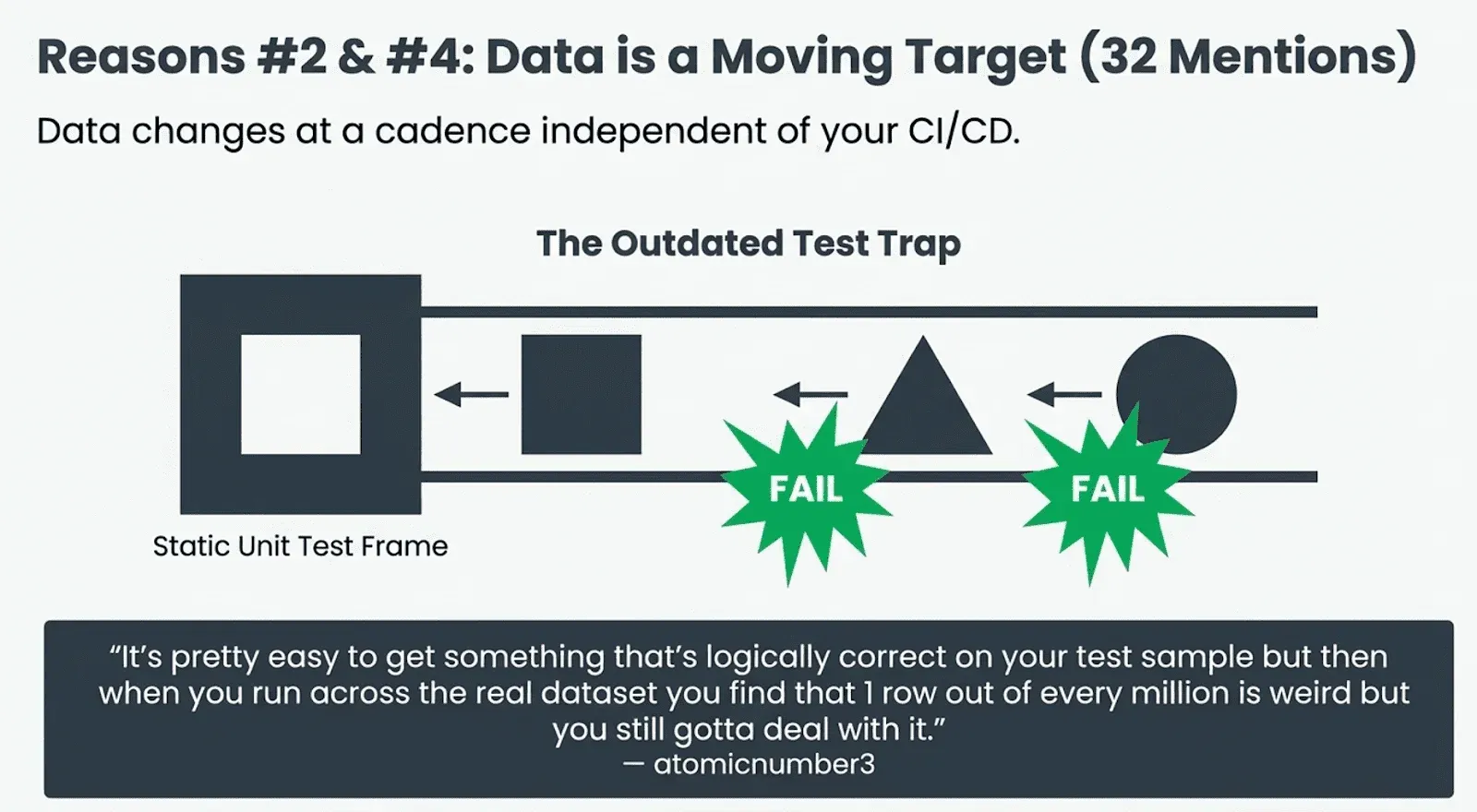
Oh_Another_Thing put it more concisely: “It’s something that changes weekly, the overhead of testing on something that changes every few weeks is too much.”
On Hacker News, a user framed this as the core difference between DE and SWE: “the real problem with testing data engineering is that the data changes at a cadence that is independent to your version control/CI/CD cadence. You can have airtight unit and integration tests that get wrecked when the data schema changes without warning, the distribution of the data shifts, etc.” And atomicnumber3 described the scale problem: “it’s pretty easy to get something that’s logically correct on your test sample but then when you run across the real dataset you find that 1 row out of every million is weird but you still gotta deal with it.”
#3. The field is immature (15 mentions). User RobDoesData, with 160 upvotes, delivered the uncomfortable truth: “Reddit is full of bad engineers is the obvious answer. The more nuanced answer is that data engineering has a track record of being immature and not wanting to learn from SWE.”
User kaalaakhatta, who moved from software testing to data engineering, confirmed: “98% of the people in DE field, don’t care about testing. Basically it’s a habit/mindset built who has worked closely with Testing.”
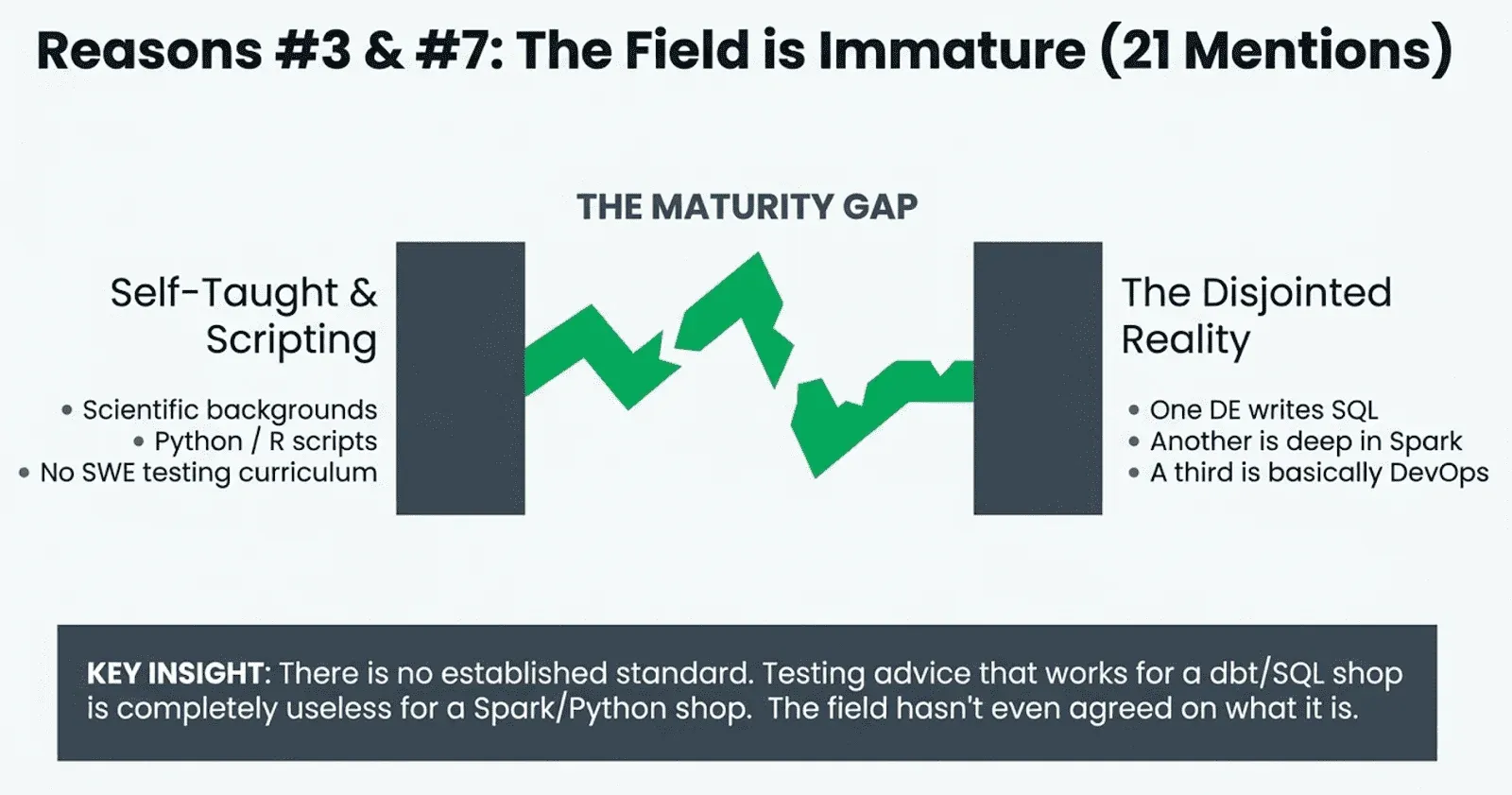
And it is worth noting that “data engineering” is not one job. As PotokDes observed: “you can put a few DE in the same room, and there’s a good chance none of them will fully understand each other. One’s mostly doing SQL transformations, another is deep into Spark, and a third is basically DevOps.” Testing advice that works for dbt/SQL shops is useless for Spark/Python shops. The field has not even agreed on what it is, let alone how to test it.
#4. Data is inherently hard to test (12 mentions). User Outside-Storage-1523: “There are so many business logic inside that if you want to cover all test cases you are going to essentially write a second set of pipelines and see if both have the same outcomes, which is pointless.”
User robberviet summarized it in six words: “You can test code. Data is another story.”
On Hacker News, user snidane argued that data engineering operates in a fundamentally different correctness model: “Data engineering is typically closely aligned with business and its processes are inherently fuzzy. Things are ‘correct’ as long as no people/quality checks are complaining. There is no deductive reasoning. No true axioms. No ‘correctness’. You can only measure non-quality by how many complaints you have received.”
#5. The tooling makes it painful (11 mentions). On Hacker News, the “How do you test SQL?” thread drew 315 comments and 663 upvotes, and the sheer variety of answers revealed a field that still has not settled on basic infrastructure. Some people use DuckDB as a local proxy. Others spin up Docker containers with Postgres template databases. Still others use pgTAP, or pytest harnesses, or Spark sessions with custom dependency injection. One commenter tried to test against Redshift and the top reply was: “try not to cry, cry a lot, and then resolve not to vendor lock yourself to a black box data store next time.”
Even the tools that exist frustrate people. User eccentric2488 wrote of Great Expectations: “Great expectations feels like learning mandarin or a scandinavian language. I want to meet the guy who designed it.” MonochromeDinosaur was harsher: “Great Expectations IMO is garbage it promises a lot but delivers on nothing and you end up with a mess to maintain.”
User SearchAtlantis on Reddit captured the tooling frustration perfectly: “Data Engineers don’t test because the majority of tooling doesn’t functionally allow it.” And on the “There is no data engineering roadmap” HN thread, rectang articulated why SQL itself is part of the problem: “the cultural traditions of testing and validation are underdeveloped because SQL has no core testing story. People count on joins being logically correct, but don’t go to the trouble to prove that true.”
#6. Laziness (11 mentions, tied with tooling). RexehBRS did not mince words: “Another answer… Laziness. ‘I don’t want to write more code’ I’ve heard, from the same people who write hundred line functions doing 13 different things.” NotAToothPaste went further: “No matter the answer, I always understand ‘Testing is not implemented because I don’t know how to make it happen and I am too lazy to learn about it.’”
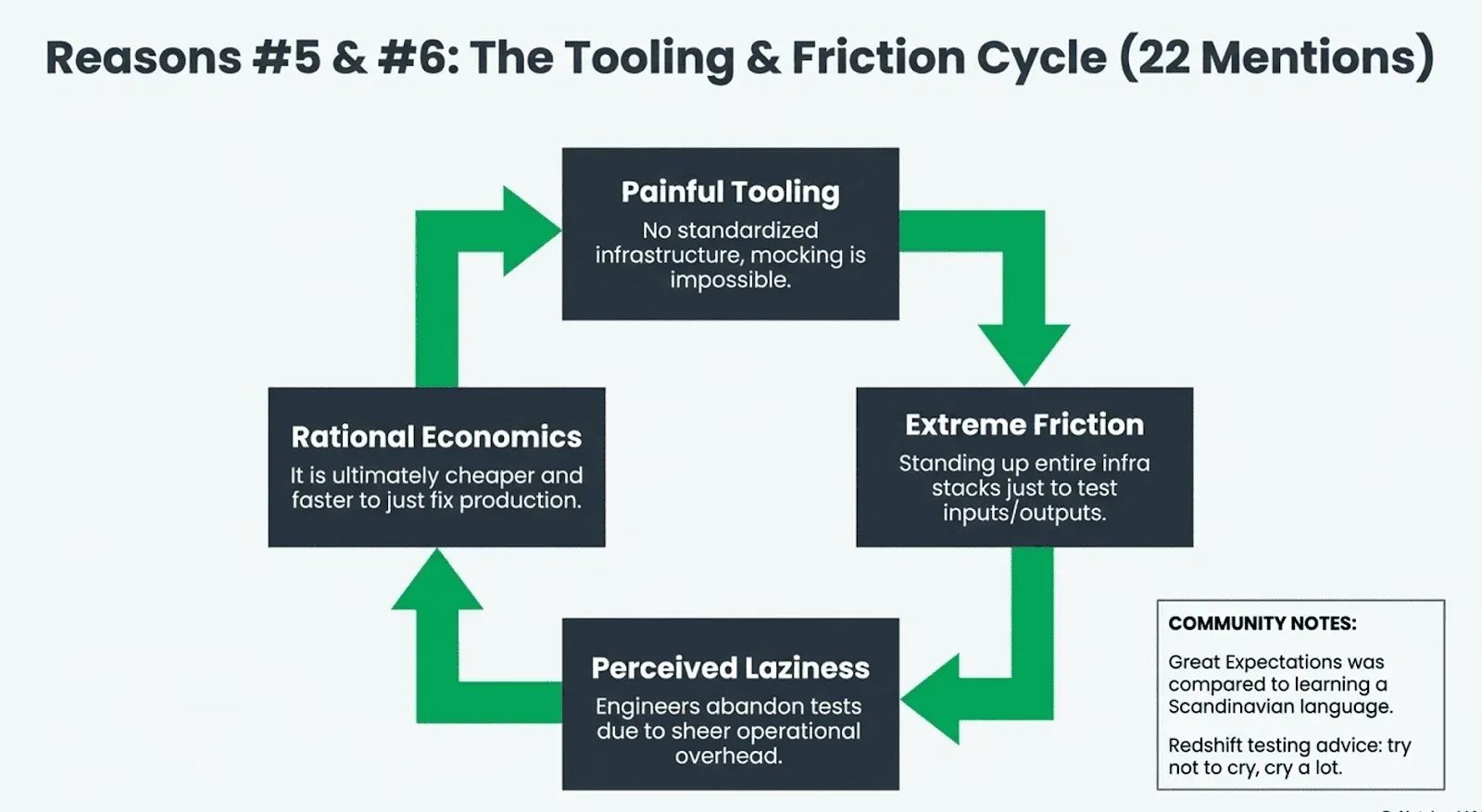
To be fair, what looks like laziness from the outside is often a rational response to the incentive structure described in #1. If you get paid more to fix technical debt than to prevent it, not testing is economically rational behavior. The system rewards it.
#7. They were never trained to (6 mentions). User peter-peta explained: “in scientific, most people not only aren’t software engineers, but most often entirely self-taught programmers, because it’s often not really part of curriculum at university, it’s rather ‘just expected’ that you can manage yourself with Python or R for data related tasks. Thus, many of them just don’t know that something like unit tests etc. exist and are a thing in the first place.”
MonochromeDinosaur expanded on this: “many data engineers are heavily SQL focused and programming is a secondary tool so they’ve simply either never had the means to test things in the way software engineers do or never had to write something larger than an ETL script.” And then the kicker: “it took experience writing actual application code (not scripts) to learn how to deliberately write testable code and not some untestable script kiddie slop.”
#8. Unit tests do not catch the failures that actually hurt (4 mentions). This was the least common reason but arguably the most sophisticated. Jumpy-Possibility754 wrote: “unit tests help but they don’t catch the kinds of failures that actually break things in production. What tends to matter more is data validation layers, pipeline observability, and the ability to replay parts of the flow when something fails mid-chain.”
On the “Evolution of the data engineer role” HN thread, user prions, speaking from experience at Spotify, gave the most detailed version of this argument: “the biggest challenge is the slow and distant feedback loop. The vast majority of data pipelines don’t run on your machine and don’t behave like they do on a local machine. They run as massively distributed processes and their state is opaque to the developer. Validating the correctness of a large scale data pipeline can be incredibly difficult as the successful operation of a pipeline doesn’t conclusively determine whether the data is actually correct for the end user. People working seriously in this space understand that traditional practices here like unit testing only go so far.”

User loudandclear11 was even more direct: “99.9% of your incidents wouldn’t have been saved by a unit test anyway. Take a look at your actual incidents and see what they have in common. That should give an indication on where you should focus your energy.”
On Hacker News, the comment that started the pipeline validation thread said: “Reliably getting data into a database is rarely where I’ve experienced issues. That’s the easy part.” The hard part is knowing whether the data is correct.
What the Community Thinks We Should Do About It
The threads were not just a litany of complaints. Plenty of commenters offered concrete, battle-tested approaches. User anxiouscrimp offered the most concise testing strategy in all 849 comments: “Smash straight into prod. You guys need to live a little.” For the rest of us who prefer to keep our jobs, the community converged on three big ideas.
Test the data, not just the code, and start embarrassingly simple. This was the closest thing to consensus across all eighteen threads. User EarthGoddessDude stated it crisply: “Unit tests != data quality checks.” Unit tests verify that your code does what you intended. Data quality checks verify that the data you received is what you expected. In data engineering, the second category catches far more real-world failures than the first.
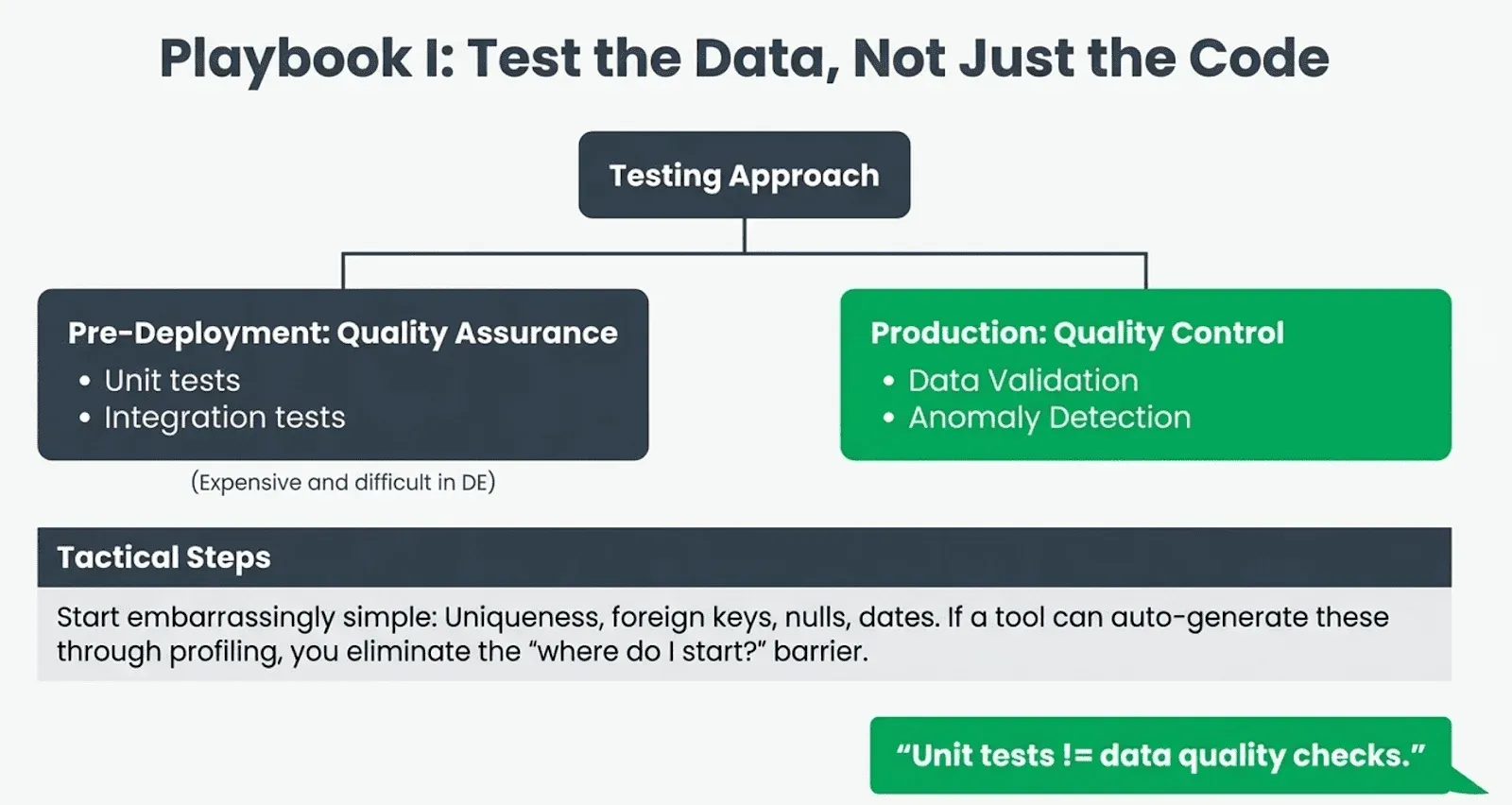
User kenfar laid out the full taxonomy: quality assurance through integration and unit testing (things you do before deployment), and quality control through data validation and anomaly detection (things you do in production). “All of these are important and worth doing,” he wrote, adding the practical caveat: “unit testing SQL transformations is extremely expensive. It takes too much setup, whereas unit testing of python, ruby, java, go, etc is extremely straightforward.”
Where to begin? User kenfar recommended: “I’d start with very obvious and simple items: checks for uniqueness, foreign keys, nulls, appropriate dates. Once that’s in place I’d add reconciliation and anomaly detection checks. Only after that would I consider unit tests for SQL.” User bengen343 described a pragmatic approach that goes one step further: every model gets at least the out-of-the-box dbt tests for uniqueness and not-null, every model exposed externally gets unit tests with CSV seed files for input and expected output, and all of it runs automatically on merge. “The real beauty,” bengen343 wrote, “is that the csv files are part of the repo so if someone makes changes to output models, the person reviewing the merge will see the expected output as the expectations csv needs to be changed as well. So it provides a gut-check.”
Several commenters noted that the biggest barrier is getting started, not maintaining tests once they exist. If a tool can profile your data and auto-generate sensible default tests for nulls, uniqueness, freshness, volume, and schema conformance, it eliminates the “where do I even start?” problem. The community mentioned dbt tests, dbt-expectations, and Elementary.
TIP
Full disclosure: DataKitchen built an open-source tool called DataOps TestGen to solve exactly this problem. It generates data quality tests through profiling and runs ongoing anomaly monitoring so engineers do not have to hand-write every test from scratch. We are biased, but we built it because this same conversation keeps repeating, and the data keeps rotting.
Make the feedback loop faster and make testing a gate. On Hacker News, the top-voted advice from RobinL was: “Try and write any complex SQL as a series of semantically meaningful CTEs. Test each part of the CTE pipeline with an in.parquet and an expected_out.parquet.” The approach uses DuckDB for fast local execution. MonochromeDinosaur prescribed a complementary pattern: “write pure functions, separate I/O from transformations and do unit tests with in-line fixtures using data structures native to the tool you’re using. This is easy because you control the intermediate schemas and state.” User feike on HN described getting 82 integration tests to run in 6.9 seconds using Postgres template databases, creating a fresh database for each test from a template snapshot. The common thread: make testing fast enough that it is easier to run than to skip.
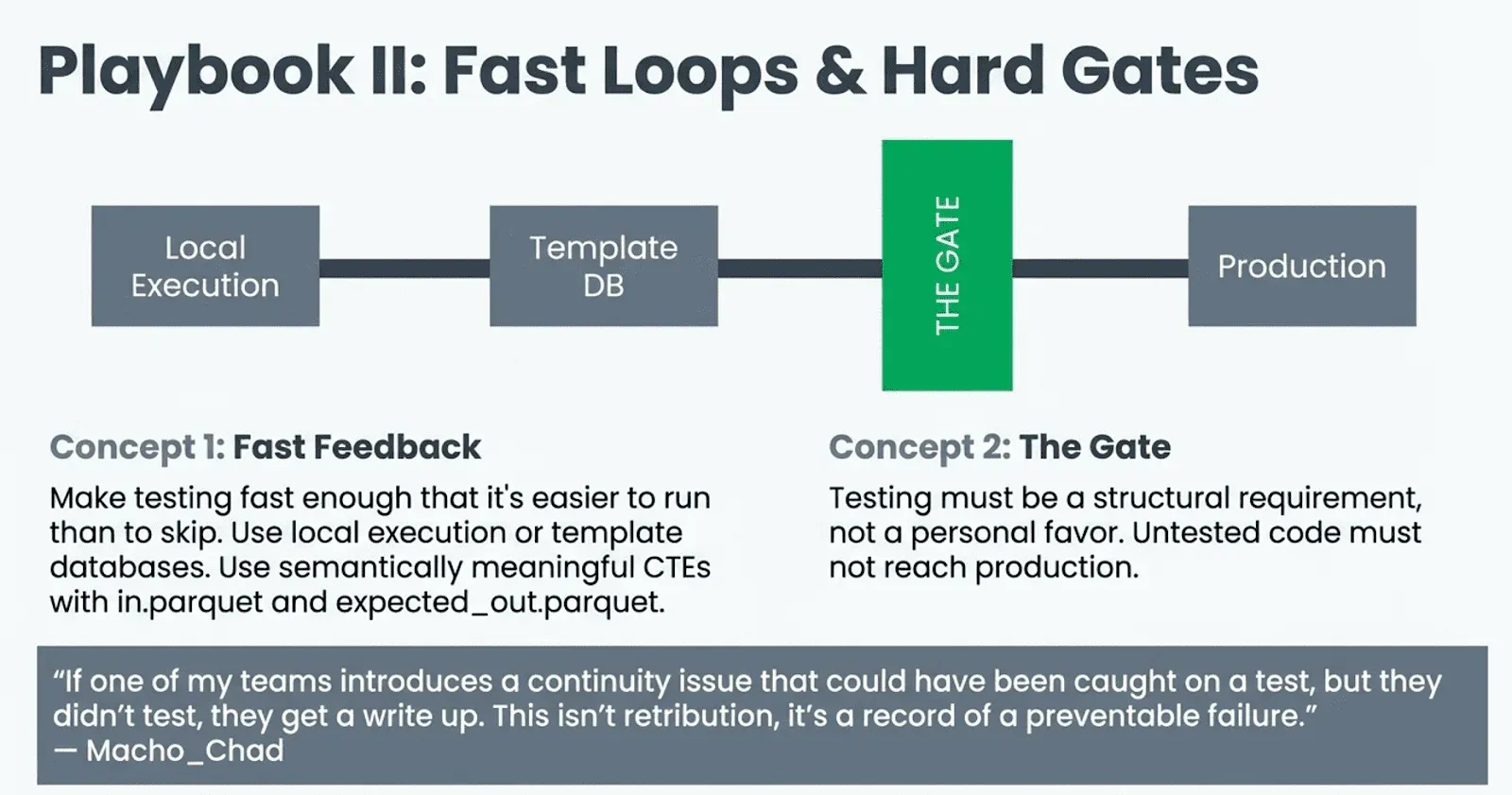
But faster tests only matter if someone actually requires them. User Macho_Chad described an environment where untested code results in a written record of preventable failure: “If one of my teams introduces a continuity issue that could have been caught on a test, but they didn’t test, they get a write up. This isn’t retribution, it’s a record of a preventable failure.” User killerfridge took the same approach with code review: “If they want it to get past code review, it better have greater than 80% coverage, and the tests must pass. It’s amazing how much it’s exposed the poor practices, but also how much it’s shone a light on how much doesn’t actually work properly.”
Stop pretending this is a solved problem. On the dbt Community Forum, the “State of Testing in dbt” thread acknowledged openly that the field is still figuring out what testing should look like for data transformations. One contributor proposed borrowing a formal verification technique from another programming language: define preconditions and postconditions for each model, and prove correctness by showing that any run that starts in a state where the preconditions hold will end in a state where the postconditions hold. The fact that someone felt the need to reach that far outside the data ecosystem for a testing idea tells you how unsettled the question still is.
When You Get Asked, “Where Did This Number Come From?”
Read enough of these threads and a pattern emerges. Data engineers are not anti-testing. They are anti-theater. They have watched SWE teams mandate 80% code coverage on trivial SQL and declare victory while the actual data rots unmonitored in production. They have been told to “just write unit tests” by people who have never tried to mock a Snowflake connection. They have been asked to test against source data that changes schema every other Tuesday with no notice and no contract.
The number one reason data engineers do not test, by a factor of two over all other reasons, is that nobody gives them the time or budget to do it. That is not an engineering problem. That is a management problem. And the number eight reason, the one with the fewest mentions, might be the most important one to sit with: that traditional unit tests simply do not catch the class of failures that actually hurt in data engineering.

But here is the surprising conclusion from the internet’s collective investigation: data engineers do test. They simply do it differently than software engineers expect. They validate assumptions about data. They monitor systems for anomalies. They inspect outputs when logic changes. They write targeted tests for complex transformations. Testing in data engineering is less about proving that code works in isolation and more about ensuring that entire data ecosystems behave reasonably over time. The real question is not whether every possible scenario has been tested. The real question is how much uncertainty an organization is willing to tolerate before it starts verifying the numbers it depends on.
User roastmecerebrally captured the human side of this perfectly. After describing how they implemented validation testing for their warehouse and were “treated like a god,” they added the self-aware punchline: “Sorry, no, I just have anxiety.”
Maybe that is the real answer. The data engineers who test are not smarter or more disciplined. They are just more nervous. And sooner or later, every organization confronts the same moment that turns the nervous ones into the essential ones. An executive opens a dashboard and notices something strange. The numbers look wrong. The room grows quiet.
Someone eventually asks the question that echoes through every data team.
Where did this number come from?
At that moment, testing stops feeling optional.
Appendix: How We Counted
We read every comment across all eighteen source threads and tagged each individual comment that cited a reason for not testing. Each comment was counted at most once per reason, even if it mentioned the reason multiple times. Here is the ranked order by total mentions:
- Nobody pays for it / no time (40 mentions). The runaway winner, showing up in nearly every high-engagement thread. It was not even close. When data engineers explain why they do not test, the answer most often given is not technical. It is organizational. They are not given the time, the budget, or the incentive.
- Data and schema change constantly (20 mentions). The “we don’t control the inputs” problem. Source systems change without notice, schemas drift, and third-party APIs break contracts.
- The field is immature (15 mentions). Culture, legacy systems, silos, and the absence of established practices that SWE has had for decades.
- Data is inherently hard to test (12 mentions). The “it’s not code, it’s state” argument. SQL is declarative; you cannot set breakpoints, and mocking is nearly impossible.
- Tooling is painful (11 mentions). Mocking tables, vendor lock-in, slow feedback loops, and no standardized test infrastructure.
- Laziness and willful neglect (11 mentions). Tied with tooling. Some commenters were blunt about this.
- No training or CS background (6 mentions). Self-taught programmers who never learned testing as a practice.
- Unit tests miss real failures (4 mentions). The sophisticated argument that traditional tests catch the wrong class of errors in data work.

The Stack Overflow threads (sources 9, 14 through 18) were included for completeness but contributed very few reason mentions. They were mostly “how do I do this?” questions with short tactical answers. One thread had zero replies. Another’s top answer listed “stare and compare” as a legitimate testing method. The substantive debate occurred across the four Reddit and four Hacker News threads, which together account for roughly 90% of all reason mentions. The dbt Community Forum threads leaned more toward solutions than complaints.
Appendix: Compared to We Got Roasted On Reddit … Article
There are more reasons in ‘We Got Roasted On Reddit For Asking ‘Why Data Engineers Don’t Test?’ … how does it compare to the eight reasons from our blog post?
The ‘We Got Roasted’ (WGR) article lists these eight reasons:
- Writing good tests is genuinely hard
- No one has thought through what happens when a test fails
- Feature delivery always wins
- Tests rot, and nobody budgets time to maintain them
- You don’t know what to test until it’s already broken
- Nobody senior enough cares until it’s too late
- Catching the error makes it your problem
- At scale, comprehensive testing must fit
Our blog post lists these eight reasons (ranked by mention count):
- Nobody will pay for it / no time (40)
- Data and schema change constantly (20)
- The field is immature (15)
- Data is inherently hard to test (12)
- Tooling is painful (11)
- Laziness / willful neglect (11)
- No training / CS background (6)
- Unit tests miss real failures (4)
Here’s how they map:
| WGR article reason | This blog’s reason | Match type |
|---|---|---|
| 1. Writing good tests is genuinely hard | 4. Data is inherently hard to test + 7. No training | Partial overlap. WGR focuses on the skill of writing non-noisy tests. Our #4 is about data being fundamentally hard to test, and #7 is about not having the training. Both contribute. |
| 2. No playbook for when tests fail | No direct match | New reason. Our threads didn’t surface this as a distinct theme. It’s a genuinely novel insight from the DK thread. |
| 3. Feature delivery always wins | 1. Nobody will pay for it / no time | Direct match. Same reason, same framing. |
| 4. Tests rot / no maintenance budget | 2. Data and schema change constantly | Direct match. Same root cause (upstream changes), slightly different framing (DK emphasizes maintenance cost, ours emphasizes the change itself). |
| 5. Don’t know what to test until it breaks | 7. No training / CS background | Partial overlap. WGR frames it as experiential knowledge. Our #7 frames it as formal training. Both are about not knowing what to test, but for different reasons. |
| 6. Nobody senior enough cares | 1. Nobody will pay for it / no time + 3. The field is immature | Strong overlap. WGR focuses on leadership, not caring until a crisis. Our #1 is the budgetary consequences; our #3 is cultural immaturity. |
| 7. Catching the error makes it your problem | 6. Laziness / willful neglect | Partial overlap, but WGR framing is sharper. What our threads call “laziness” is what WGR’s thread reframes as a rational response to perverse incentives. Our blog actually made this connection in the laziness section. |
| 8. At scale, comprehensive testing must fit | No direct match | New reason. Our threads didn’t have hyperscale commenters (exabyte-per-day). This is a distinct constraint that only applies to very large operations. |
Summary:
- Direct match — 3 (reasons 3, 4, 6)
- Partial overlap - 3 (reasons 1, 5, 7)
- New / not in our blog - 2 (reasons 2, 8)
Two genuinely new reasons from the WGR article that our 18-thread analysis did not surface:
“No playbook for when tests fail.” This is the operational gap: even if you write tests, nobody has decided which ones stop the pipeline, which generate warnings, and who will act on the results. Our blog talked about why people don’t write tests. WGR thread surfaced why people who do write tests still fail.
One reframing that improves on our analysis: WGR’s reason #7, “catching the error makes it your problem,” is a much sharper version of what our threads loosely called “laziness.” The WGR thread names the actual incentive structure rather than the behavior it produces. This blog already connected these two (the sentence “what looks like laziness from the outside is often a rational response to the incentive structure”), but the WGR article gives it its own named reason, which is probably more accurate.
Sales Pitch: This is why we build open-source, full-featured DataOps Data Quality TestGen

We read 849 comments. We counted the reasons. And every single one of them was familiar, because we have been living with these problems for decades.
The number one reason data engineers do not test is that nobody gives them the time. The number two reason is that the data changes faster than the tests. The fifth reason is that the tooling is painful. We built DataKitchen DataOps Data Quality TestGen specifically to dismantle those three barriers, and we open-sourced it because we believed that putting it behind an enterprise paywall would guarantee that the people who need it most would never use it.
Here is how TestGen maps to what the community told us:
“Nobody gives us the time” (reason #1). TestGen eliminates the blank-page problem. You connect it to your database, it automatically profiles every column, and it generates over 120 types of data quality tests without you writing a single line of code. What takes most teams weeks of manual test authorship, TestGen delivers in under an hour. When the number one barrier is time, the only honest answer is to make testing take almost no time at all. It automatically generates dozens of data quality tests with a single click.
“The data changes faster than the tests” (reason #2). Tests rot because they are written against a snapshot of the data from one particular Tuesday. TestGen’s anomaly detection continuously monitors for schema changes, data drift, freshness degradation, and volume anomalies. When upstream data shifts, TestGen catches it automatically rather than waiting for a hand-written test to start throwing false positives that everyone ignores. And because you can reprofile and regenerate tests on a schedule, the test suite evolves with the data rather than decaying behind it.
“The tooling is painful” (reason #5). The community roasted Great Expectations for feeling like “learning Mandarin.” They described elaborate workarounds involving DuckDB proxies, Docker containers, and custom pytest harnesses just to get basic test infrastructure running. TestGen ships with a full UI out of the box. No YAML configuration sprawl. No Jinja macros. No vendor lock-in. It runs queries directly in your database rather than extracting data for testing externally, which means it is fast and stays within your existing security boundary.
“You don’t know what to test until it breaks” (reason #7). TestGen’s dataset screening runs 32 hygiene checks on new data sources before you write a single transformation: invalid formats, leading spaces, mixed data types in a single column, non-standard blanks, and more. These are the silent killers that experienced engineers learn to check for after getting burned. TestGen checks for them proactively, before the burn happens.
“Data failures are invisible until they’re embarrassing” (reason #6 from our follow-up analysis). TestGen generates data quality scorecards that make the state of your data visible to everyone, not just the engineer who wrote the pipeline. When paired with DataKitchen DataOps Observability (also open source), you get a single view of both data errors and pipeline errors across your entire data journey, from source to customer value.
What “open source” actually means here. TestGen is not a freemium teaser with the important features locked behind a paywall. The open-source version is Apache 2.0 licensed, full-featured, and production-ready. It includes the profiling engine, test generation, anomaly detection, dataset screening, the UI, and the scorecards. You can install it today and be running tests against your data within the hour. There is also a free certification course if you want to learn the concepts before you install anything.
For teams that need shared test suites across multiple engineers, collaboration features, and enterprise support,DataKitchen offers flat-rate pricing at $100 per month per user and per database connection, with unlimited tables. No per-table tax. No usage metering that punishes you for testing more. The enterprise version is backed by a team of experienced data engineers who have spent decades building data platforms and who understand the problems described in this article because they have lived through every one of them.
We did not write this article to sell you software. We wrote it because 849 data engineers told us exactly what is broken, and their answers matched everything we have seen in our own careers. TestGen is our answer to their frustration. It is free, it is open, and it works.Try it and tell us what you think.
Appendix: Sources
| # | Community | Topic | URL |
|---|---|---|---|
| 1 | Reddit r/dataengineering | Testing in DE feels decades behind traditional SWE. What does your team actually do? | Link |
| 2 | Reddit r/dataengineering | Why don’t data engineers test like software engineers do? | Link |
| 3 | Reddit r/dataengineering | Why data engineers don’t test: according to Reddit | Link |
| 4 | Reddit r/dataengineering | Your opinion on testing in data engineering | Link |
| 5 | Hacker News | Ask HN: How do you test SQL? | Link |
| 6 | Hacker News | Validating the correctness of a large scale data pipeline | Link |
| 7 | Hacker News | The evolution of the data engineer role | Link |
| 8 | Hacker News | There is no data engineering roadmap | Link |
| 9 | Stack Overflow | How to test (unit test) on the ETL process? | Link |
| 10 | dbt Community Forum | How to get started with data testing | Link |
| 11 | dbt Community Forum | dbt model (think unit) tests POC | Link |
| 12 | dbt Community Forum | Running dbt unit tests in CI/CD | Link |
| 13 | dbt Community Forum | State of testing in dbt | Link |
| 14 | Stack Overflow | How should I perform automated testing of SQL ETL scripts and stored procedures? | Link |
| 15 | Stack Overflow | How To Test Talend ETL | Link |
| 16 | Stack Overflow | ETL and QA testing | Link |
| 17 | Stack Overflow | How do I automate ETL tests on a Data Warehouse project using .NET? | Link |
| 18 | Stack Overflow | What is the best way to test ETLs: Source vs Target data comparison | Link |
Total comments read across all 18 sources: 849.



