
Implementing DataOps requires a combination of new methods and automation that augment an enterprise’s existing toolchain. The fastest and most effective way to realize the benefits of DataOps is to adopt an off-the-shelf DataOps Platform.
Some organizations try to implement DataOps from scratch using DevOps and workflow tools. However, DataOps is not just DevOps for data, and using DevOps tools in the data science and analytics domain will not easily lead to DataOps success. DevOps tools will leave significant gaps in your DataOps processes. Here we describe the important ingredients required for DataOps, without which companies will falter on their DataOps journey.
End-to-End Production Pipelines
There are hundreds of tools for data engineering, data science, analytics, self-service, governance, and databases. Meta-orchestration of the complex toolchain across the end-to-end data analytics process is a crucial element of DataOps.
Think of your analytics development and data operations workflows as a series of steps that can be represented by a set of directed acyclic graphs (DAGs). Each node in the DAG represents a step in your process. In most enterprises, the production and development pipelines respectively are not one DAG; they are a DAG of DAGs. Typically, different groups within the data organization use their own preferred tools. The toolchains may include multiple orchestration tools. It’s challenging for a software engineer, let alone a data scientist, to learn all of the different tools used by the various data teams (Figure 1). Furthermore, orchestration tools do not adequately address the needs of data organizations.
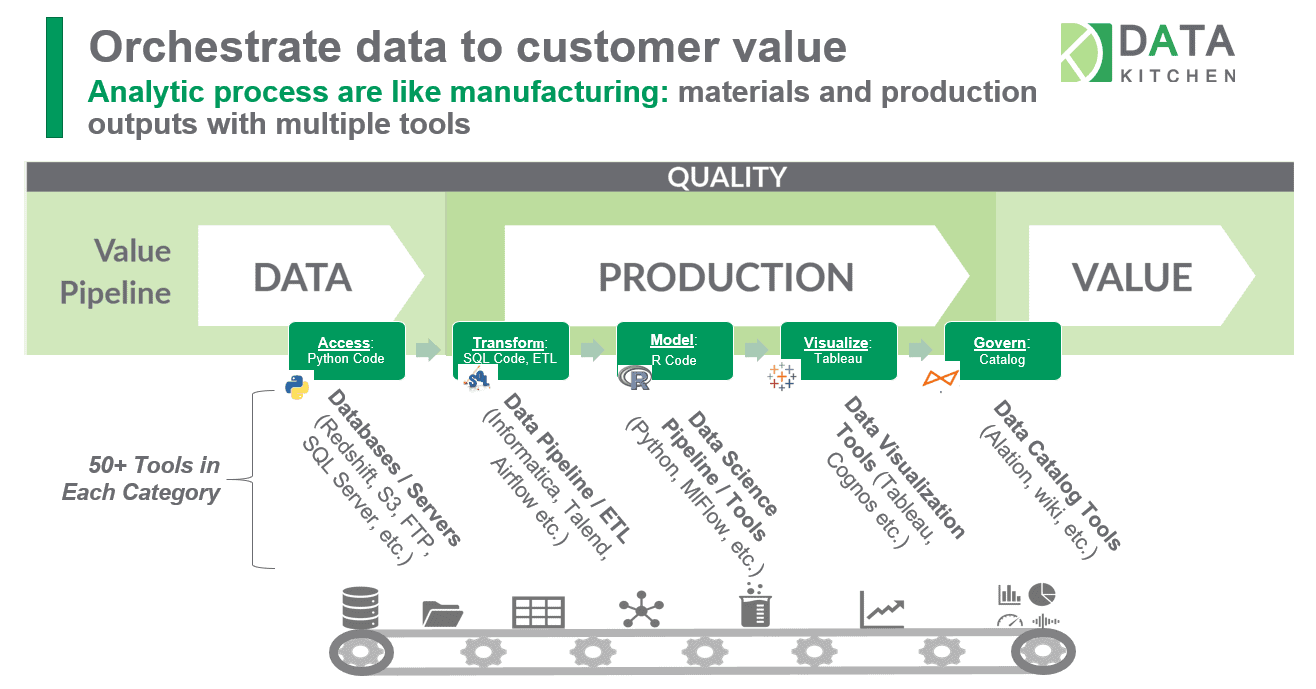
Figure 1: Data operations consists of many different toolchains and pipelines.
DataOps adds tests to the production pipeline to prevent errors from corrupting published analytics. If unit, functional or regression tests are written in a development tools environment different from production, then the tests cannot easily deploy. Popular workflow tools like Airflow, Control-M, or Azure Data Factory lack features that ease the migration of tests used in development into production tests that actively monitor and test your data flows. Seamlessly moving between development and production requires certain capabilities overlooked by typical DevOps tools, such as:
- Built-in connectors to the complex chain of data engineering, science, analytics, self-service, governance, and database tools.
- Meta-Orchestration or a ‘DAG or DAGs’
- Integrated production testing and monitoring
A DataOps platform simplifies test deployment with Recipe tests. Recipes are orchestrated pipelines that easily migrate as a working unit between compatible environments. Tests can be written in a specific tool or, more portably, in the DataOps Platform domain. The DataKitchen DataOps Platform connects to your heterogeneous toolchains and provides a unified environment in which to implement tests. With a common testing environment, test authors don’t have to be experts in each of the various tools and languages that comprise your end-to-end data operations pipelines. The DataOps Platform also enables tests to be added without having to write code; using a UI. For more information, view our webinar, Orchestrate Your Production Pipelines for Low Errors.
Complete Testing and Deployment Pipelines
Deployment of data analytics differs from software engineering deployment. To deploy analytics from development through to production, you need four key components:
- The data you are using for testing
- The hardware/software stacks implementing analytics
- The code you have created
- All the tests that prove success
In DataOps, there are more steps and complexity than in a DevOps ‘build-test-deploy.’ (Figure 2)
A DataOps Platform enables you to extend the concept of ‘DevOps CI/CD’ to meet the needs of data science and analytics teams. It automates environment management, orchestration, testing, monitoring, governance and integration/deployment. Note that orchestration occurs twice in DataOps. DataOps orchestrates data operations and also development sandbox environments, which include a copy of data operations. DataOps executes these functions continuously:
- CE (Continuous Environments)
- CO (Continuous Orchestration)
- CI / CD (Continuous Integration, Deployment)
- CT / CM / CG (Continuous Testing, Monitoring, Governance)
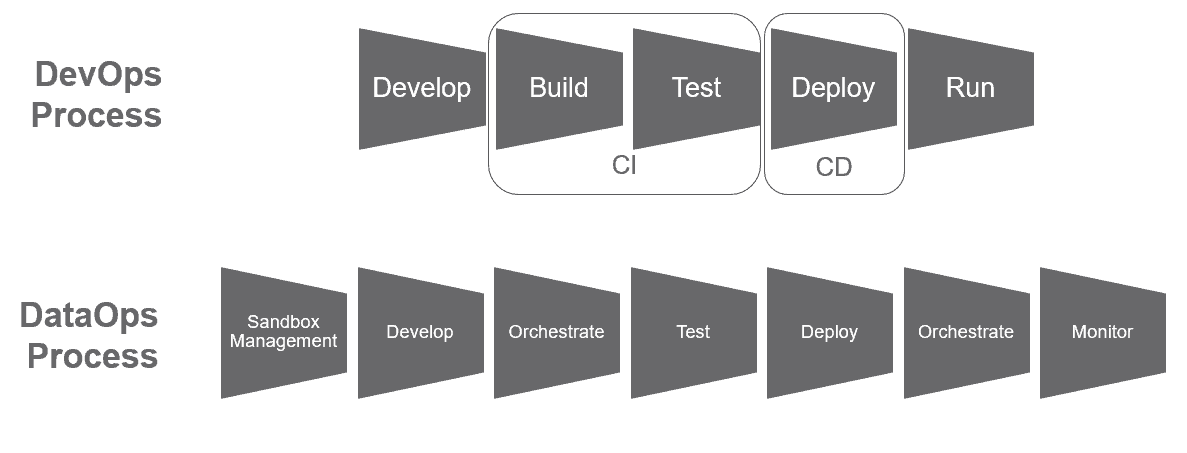
Figure 2: In DataOps there are more steps and complexity than in a DevOps ‘Build, Test, Deploy.’
DevOps CI/CD tools like Jenkins or Azure Pipelines focus on the CI/CD segment of the development pipeline – the build and delivery of code. They orchestrate the software development tools, but not the data toolchains. For more information, view our webinar, Orchestrate Your Development Pipelines for Fast and Fearless Deployment.
Environment Pipelines
Compared to software development environments, creating analytic development environments is complex. The development of new data analytics requires the joining of test data, hardware-software environments, version control, toolchains, team organization, and process measurement. The DataKitchen DataOps Platform uses ‘Kitchens’ to abstract environments that contain all the pre-configured tools, datasets, machine resources, and tests – everything users need to create and innovate. Kitchens provide users with a controlled and secure space to develop new analytics and experiment.
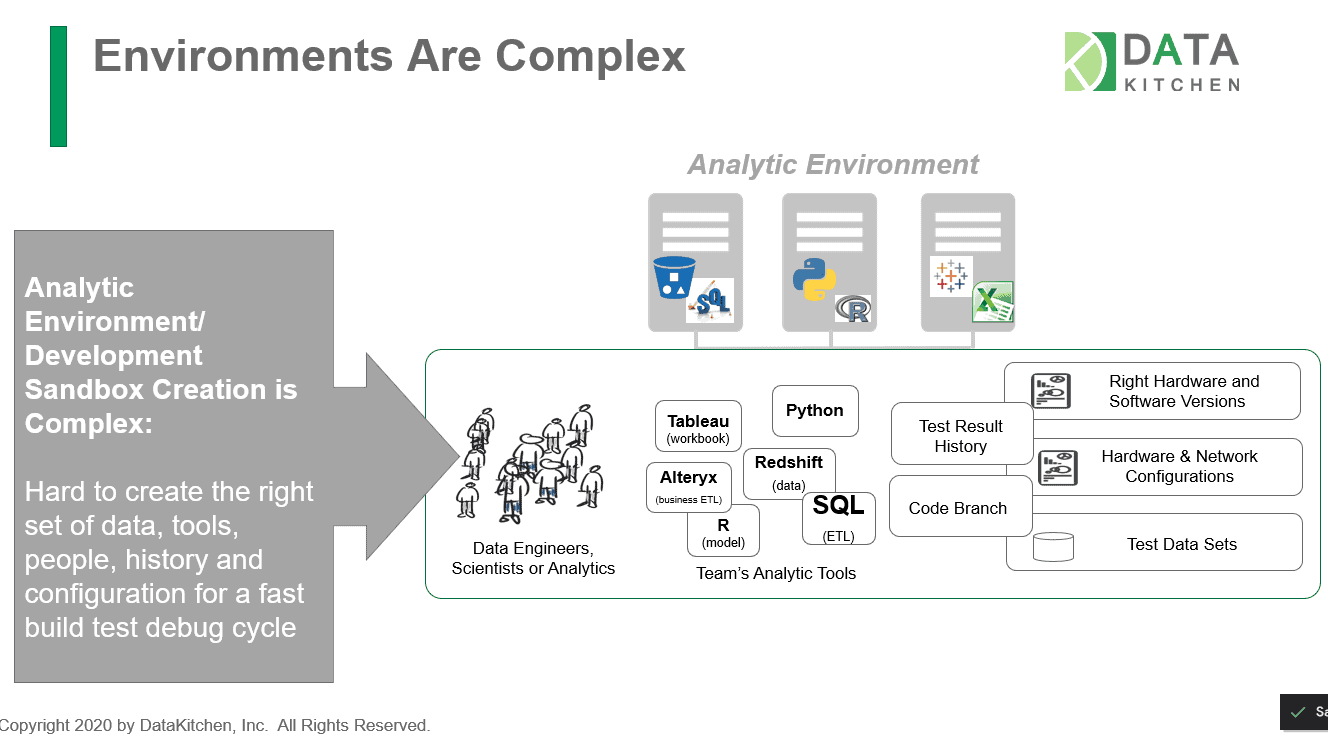
Figure 3: Compared to software development environments, creating analytic development environments is complex.
DevOps infrastructure tools like Puppet, Ansible, or Terraform lack support for self-service, analytics sandboxes. They do not offer:
- Test data management capabilities
- Integration to Git
- Simple wizards enabling data professionals to set up/shutdown/monitor sandboxes on-demand. Sandbox environments include test data, hardware-software environments, version control, and toolchains that are team, organization and process measurement aware
For more information on seamlessly spinning-up and managing repeatable analytics work environments that underpin your data production and development pipelines, see our webinar, Orchestrate Your Environment Pipelines for Reusability and Security.
Complex Team and Data Center Coordination
Data science, engineering, and analytics development and production work often take place across multiple organizations or multiple data centers (Figure 4). A DataOps Platform includes reusable analytics components and pipelines (Ingredients), permission-based access control to infrastructure and toolchains (Vaults), and a multi-agent architecture that facilitates seamless collaboration and coordination between teams working in different locations or environments.
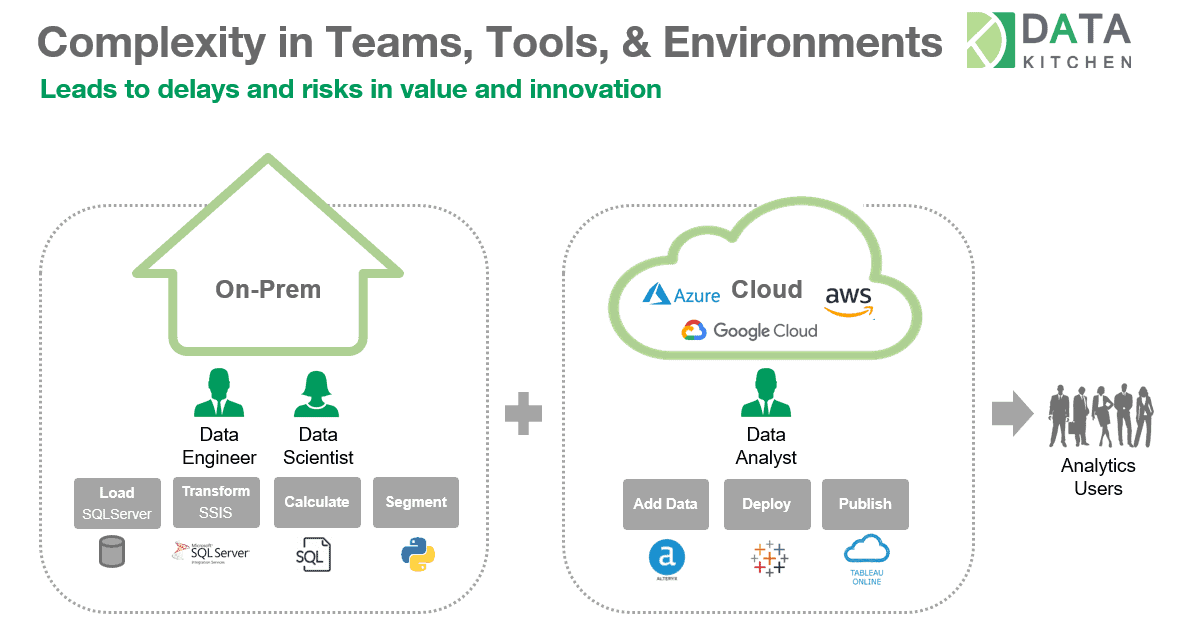
Figure 4: A DataOps Platform enables you to run different elements of together in a single process.
DevOps or workflow tools lack the team and environment awareness necessary to promote reuse:
- A method to create reusable components, share them across the teams, and run the different elements together in a single process, with local control and centralized management and visibility.
- Ability to create, monitor, and remove Self-Service Data Science/Analytics Sandboxes on demand.
For more information on how to create a reliable and agile process for environment creation that balances analytics development productivity and governance with the needs of business users, see the webinar, Achieve Agility and Control with Self-Service Sandboxes.
Design for Data People
Building DataOps capabilities from scratch requires knowledge and management of 7-10 DevOps and workflow tools. This project may be a dream for some, but for others, it’s an indescribable nightmare.
Data people are different from software people. Software engineers embrace complexity and celebrate each new tool. Your average software engineer enjoys unlocking the power of Git, Jenkins, AWS/Azure UI, workflow/DAG tools, testing frameworks, scripting languages, and infrastructure-as-code tools. Mastery of new tools represents career growth for a software developer.
Data professionals want to focus on analyzing data and creating models – learning new tools is a means to an end. Data people prefer a more straightforward set of abstractions and UI to deal with system complexity. While software engineers embrace toolchain complexity, data engineers and data scientists seek to avoid complexity. Self-service analytics users rarely venture outside the safe and ordered confines of a single preferred tool.
Forcing the data team to manage a complex toolchain combining 7-10 DevOps and workflow tools does not provide:
- A simple, straightforward user experience for users that wish to avoid complexity
- The ability to support a full spectrum of users, from the most technical data engineer to the most non-technical self-service user, and enable them to carry out their role in DataOps.
A DataOps Platform brings all of the tools necessary for DataOps into a single coherent platform that allows each user to interact with the toolchain at the level of simplicity or complexity that they desire.
DataOps Process Metrics
DataOps strives to eliminate waste, and DataOps metrics serve as the means to demonstrate process improvements (Figure 5). Teams need to be measured on cycle times, error rates, productivity, test coverage, and collaboration. Metrics drive teams to work in a more agile, iterative, and customer-focused manner. A DataOps Platform saves the run information from every Recipe execution to provide those critical metrics.
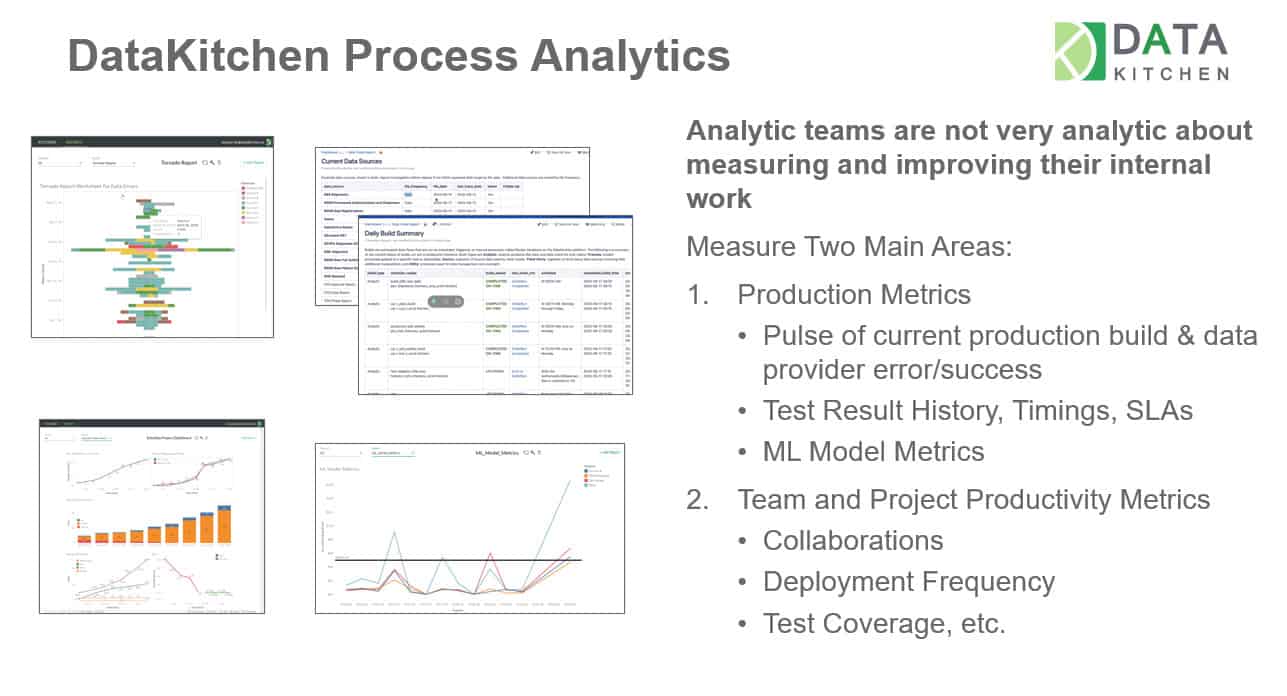
Figure 5: DataOps process metrics
DevOps tools lack explicit capabilities to create and store metrics, including:
- Process lineage: An integrated store of history of all processing, including test results, timing, and code/configuration.
- DataOps process analytics reports and datamart.
Build vs. Buy?
Despite the difficulties discussed above, some data teams still consider implementing DataOps from scratch by building a system from a dozen DevOps and workflow software components. These endeavors nearly always stumble. Developing, debugging and maintaining a DataOps system itself tends to become a major bottleneck and source of unplanned work. A team might begin with big dreams but stop with a few unit tests in development, a manually-tended Jenkins deploy, and lots of glue code on Airflow, or Talend, or data factory – falling far short of a broad and robust DataOps implementation. The software industry has coined the terms “wagile” or “scrum-fall” to describe a failure to properly apply the Agile Manifesto principles. Ultimately what matters to data teams is rapid deployment, reducing errors, end-to-end collaboration, and process metrics. The faster a team advances to focusing on these process improvements, the more likely it will sustain momentum and attain DataOps excellence. Adopting a purpose-built DataOps Platform from DataKitchen can save your team significant time and frustration (Figure 6).
In competitive markets, the most innovative companies will be those that can quickly adapt to rapidly evolving market conditions. The data teams that adopt DataOps and produce robust and accurate analytics more quickly than their peers will power strategic decision-making that sustains a competitive advantage. The DataKitchen DataOps Platform can jumpstart your DataOps initiative and more quickly bring the benefits of rapid and robust analytics to your users and decision-makers.
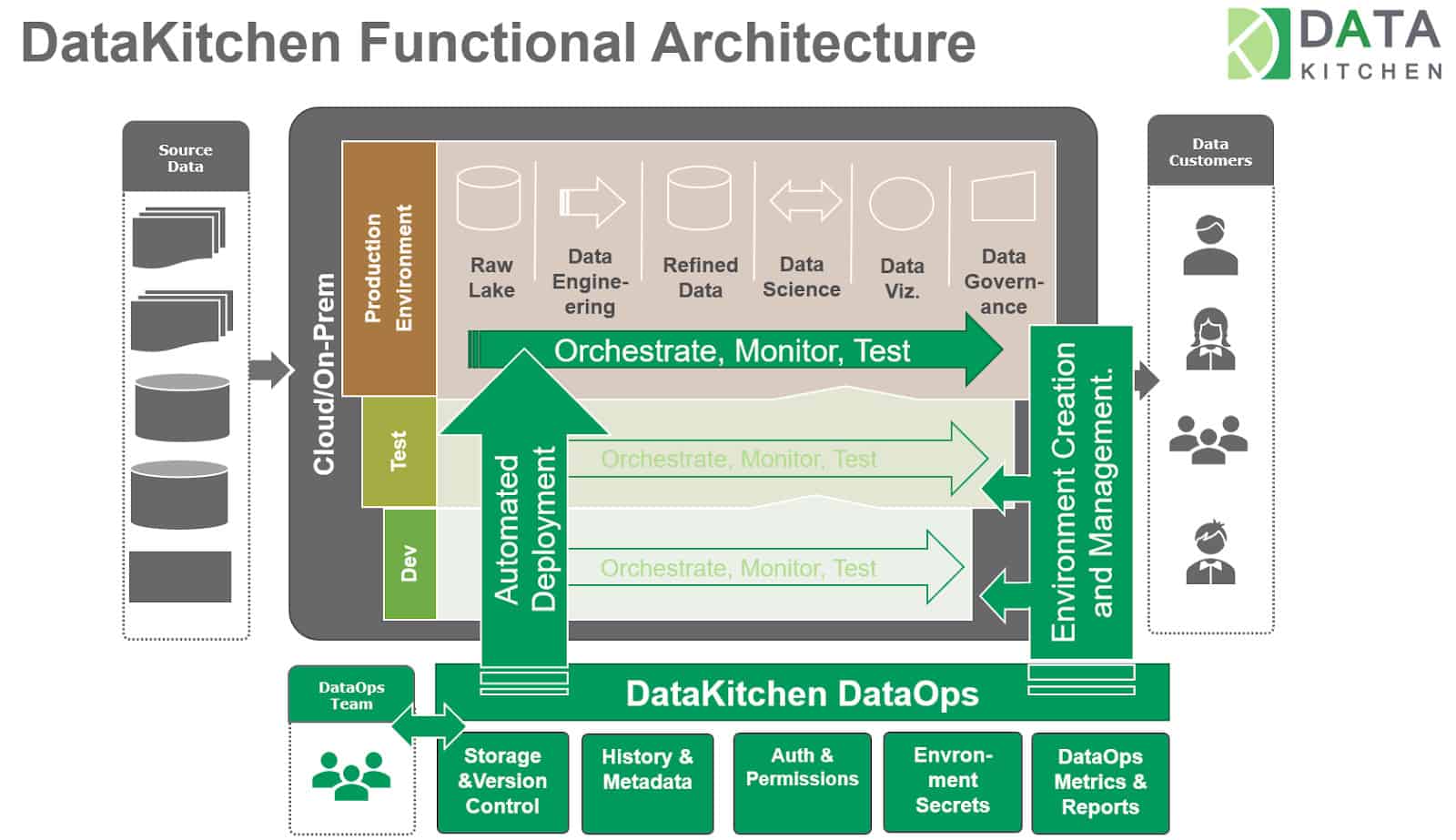
Figure 6: The DataKitchen DataOps Platform eliminates waste from the processes that manage integration, development and operations.
Comparison of Approaches for DataOps Implementation
| DataOps Process | DevOps Tools | DataOps Platform |
|---|---|---|
| End-to-End Production Pipelines | ||
| Orchestration | x | x |
| - Meta-Orchestration | x | |
| - Connectors to your complex data analytics toolchain | x | |
| - Integrated testing and monitoring | x | |
| Development Pipelines | ||
| - Continuous Integration/Deployment (CI/CD) | x | x |
| - Continuous Meta-Orchestration (CO) | x | |
| - Continuous Environments (CE) | x | |
| - Continuous Testing and Monitoring (CT/CM) | x | |
| - Continuous Governance (CG) | x | |
| Environment Pipelines | ||
| - Test data management capabilities | x | |
| - Git integration | x | |
| - On-demand infrastructure | x | |
| Collaboration and Coordination | ||
| - Ability to create, share, and run reusable components | x | |
| - Meta-orchestration across environments, teams, locations | x | |
| - Single process with local control, centralized management, and end-to-end visibility | x | |
| - Ability to create, monitor and remove analytic sandboxes on-demand | x | |
| User Interface/Complexity | ||
| - Designed for data professionals and non-technical people | x | |
| Process Metrics | ||
| - Process lineage | x | |
| - Process analytic reports | x | |
| - Datamart | x |



