The “Right to Repair” Data Architecture with DataOps
We’ve been attending data conferences for over 20 years. It has been common to see presenters display a data architecture diagram like the (simplified) one below (figure 1). A data architecture diagram shows how raw data turns into insights. As the Eckerson Group writes, “a data architecture defines the processes to capture, transform, and deliver usable data to business users.”
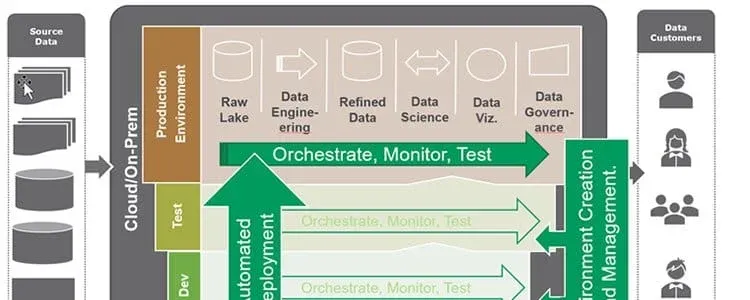
In our canonical data architecture diagram, data sources flow in from the left and pass through transformations to generate reports and analytics for users or customers on the right. In the middle, live all of the tools of the trade: raw data, refined data, data lakes/warehouses/marts, data engineering, data science, models, visualization, governance and more. Tools and platforms can exist in the cloud or on premises. Most large enterprise data architectures have evolved to use a mix of both.
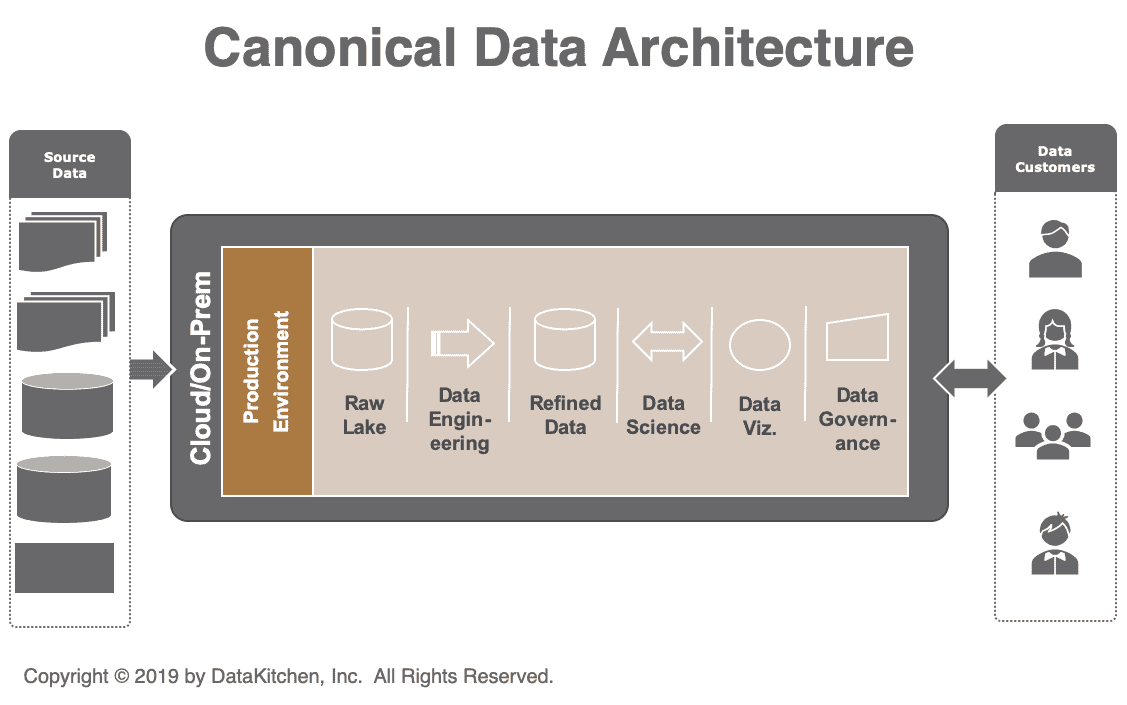
Figure 1
When data professionals define data architectures, the focus is usually on production requirements: performance, latency, load, etc. Engineers and data professionals do a great job executing on these requirements. The problem is that the specifications don’t include architecting for rapid change.
Take this example. Mobile phone designs increasingly locate batteries in fixed locations underneath sensitive electronics. In many cases, batteries can no longer be easily accessed and replaced by a consumer. The “Right to Repair” movement advocates for policies that enable customers to fix the things that they own instead of throwing them away.
When managers and architects fail to think about architecting the production data pipeline for rapid change and efficient development, it is a little like designing a mobile phone with a fixed battery. You can end up with processes characterized by unplanned work, manual deployment, errors, and bureaucracy. It can take months to deploy a minor 20 line SQL change.
Building a data architecture without planning for change is much worse than building a mobile phone with a fixed battery. While mobile phone batteries are swapped every few years, your analytics users are going to want changes every day or sometimes every hour. That may be impossible with your existing data architecture, but you can meet this requirement if you architect for it. If data architectures are designed with these goals in mind, they can be more flexible, responsive, and robust. Legacy data pipelines can be upgraded to achieve these aims by enhancing the architecture with modern tools and processes.
A DataOps Data Architecture
Imagine if your data architects were given these requirements up front. In addition to the standard items, the user story or functional specification could include requirements like these:
- Update and publish changes to analytics within an hour without disrupting operations
- Discover data errors before they reach published analytics
- Create and publish schema changes in a day
If you are a data architect yourself (or perhaps you play one), you may already have creative ideas about how you might address these types of requirements. You would have to maintain separate but identical development, test, and production environments. You would have to orchestrate and automate test, monitoring, and deployment of new analytics to production. When you architect for flexibility, quality, rapid deployment, and real-time monitoring of data (in addition to your production requirements), you are moving towards a DataOps data architecture as shown in figure 2.
The DataOps data architecture expands the traditional operations-oriented data architecture by including support for Agile iterative development, DevOps, and statistical process control. We call these tools and processes collectively a DataOps Platform. The DataOps elements in our new data architecture in figure 2 are shown in shades of green.
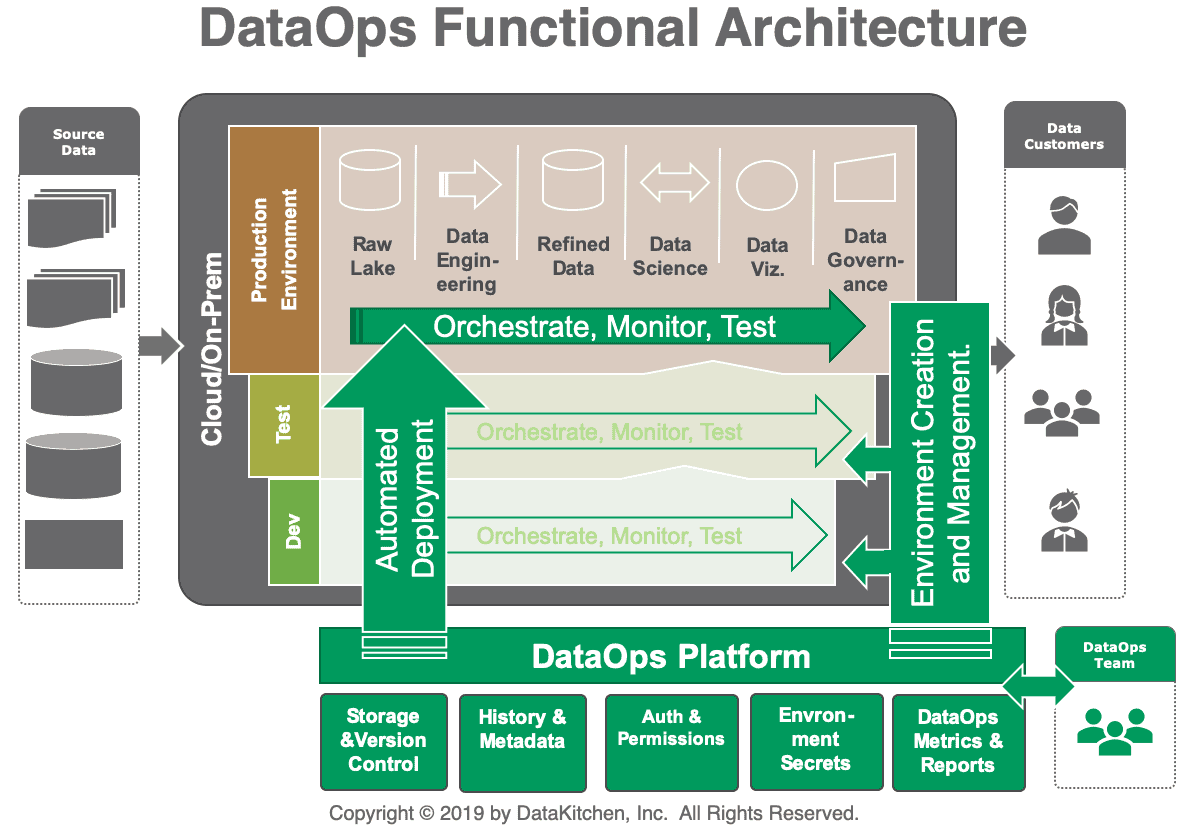
Figure 2: DataOps Functional Data Architecture
Breakdown of the DataOps Architecture
The DataOps architecture contains support for environment creation and management. This enables separate development, test, and production environments, which in turn support orchestration, monitoring, and test automation. The software automates impact review and new-analytics deployment so that changes can be vetted and published continuously. Agents in each environment operate on behalf of the DataOps Platform to manage code and configuration, execute tasks, and return test results, logs, and runtime information. This enables the architecture to work across heterogeneous tools and systems. The DataOps Platform also integrates several other functions which support the goal of rapid deployment and high quality with governance:
- Storage /Revision Control — Version control manages changes in artifacts; essential for governance and iterative development. (example: git, dockerhub)
- History and Metadata — Manage system and activity logs (example, MongoDB)
- Authorization and Permissions — Control access to environments (example: Auth0)
- Environment Secrets — Role-based access to tools and resources within environments (example: Vault)
- DataOps Metrics and Reports — Internal analytics provide a big-picture assessment of the state of the analytics and data team. We call this the CDO Dashboard. (example: Tableau)
- Automated Deployment — This involves moving the code/configuration from one environment (e.g., a test environment) to a production environment. (Examples: Jenkins, CircleCI)
- Environment Creation and Management — treat your infrastructure as code be able to create places for your team to do work with all the required hardware, software, and test data sets they need. (example: chef, puppet, etc.)
- Orchestrate, Test, Monitor — As your pipelines are running, orchestrate all the tools involved, test and monitor, and alert if something goes wrong. (examples, Airflow, Great Expectations, Grafana, etc.)
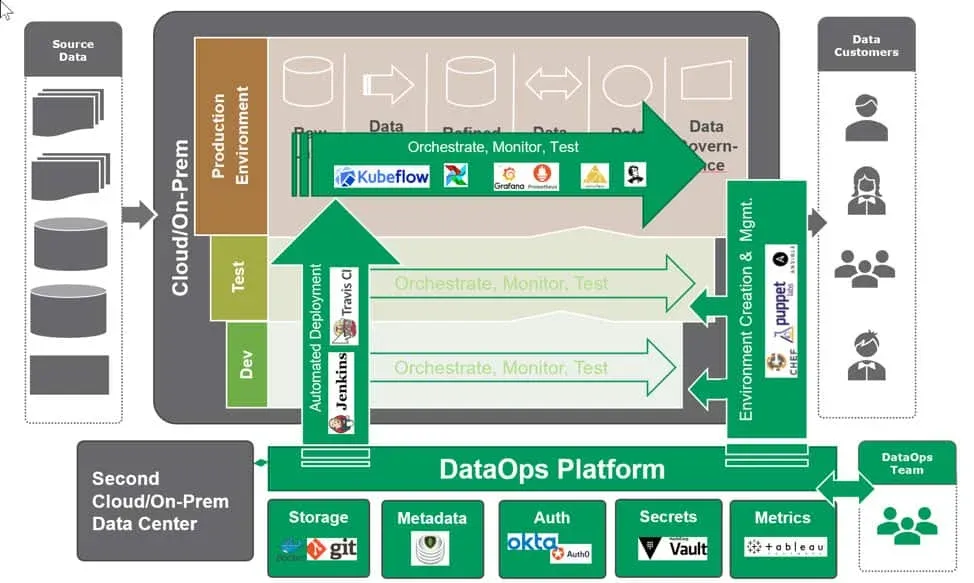
Figure 3: DataOps Data Architecture with Examples
Multi-Location DataOps Data Architecture
Companies are increasingly moving their work from on-premises to the cloud. Enterprises are choosing to have multiple cloud providers, as well. As a result, your data analytics workloads can span multiple physical locations and multiple teams. Your customers only see the result of that coordination. How can you do DataOps across those locations and teams and not end up with a ” Data Ooooops ”? Think of a “hub and spoke” model for your DataOps Data Architecture. As shown in figure 4, the DataOps Platform is the hub for your distributed sites engaging in development and operations. Testing is also coordinated between the sites.
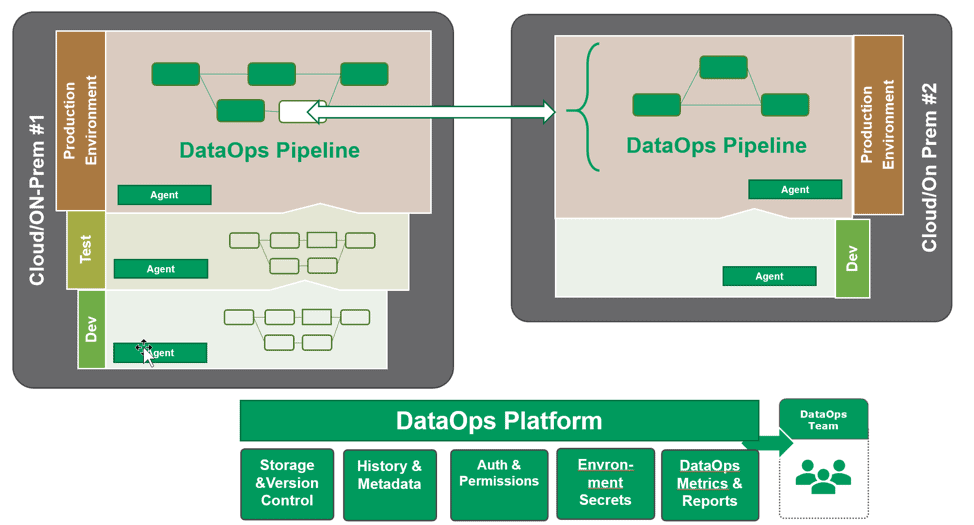
Figure 4: Multi-location DataOps Data Architecture with Examples
Building DataOps Into an Existing Data Architecture
Whether your current data architecture is on-prem or in the cloud or a mix of both; whether you have a standard environment or live in a multi-tool world, you can evolve your system to incorporate DataOps functionalities. You can build a DataOps Platform yourself or leverage solutions from the vibrant and growing DataOps ecosystem. DataOps can help you architect your data operations pipeline to support rapid development and deployment of new analytics, robust quality, and high levels of staff productivity.
You have the “Right to Repair” your data architecture — design for it!


