
Data teams today face a harsh reality: frequent pipeline failures, reactive fixes, and poor data quality often lead to bad decisions. Just when we thought we understood our data challenges, Large Language Models (LLMs) radically expand the use and scope of data … and not for the better. Still, hope remains with proven DataOps practices and open-source tools.
Introduction: Life in the Data Trenches
For many data teams, the day-to-day experience has become an unproductive mix of firefighting and frustration. We’re constantly reacting to broken pipelines, dealing with data quality issues only after they’ve caused problems downstream, and settling for data that’s “good enough” because we lack the time and resources to make it better. This situation was already challenging enough, but the introduction of Large Language Models has added entirely new dimensions to our struggles.
The promise of DataOps offers a way forward. By applying proven principles from agile development, lean manufacturing, and DevOps automation, we can restore sanity to our data stacks and dramatically improve the quality of both our traditional analytics and our emerging LLM-powered insights. This isn’t just about adopting new tools; it’s about fundamentally rethinking how we approach data quality and pipeline reliability in an age where AI is becoming ubiquitous.
The LLM Revolution: A Double-Edged Sword
Large Language Models have burst onto the scene with incredible capabilities, but they’re also making the existing mess in data and analytics teams much worse. We’re witnessing two simultaneous phenomena that are reshaping how organizations interact with data.
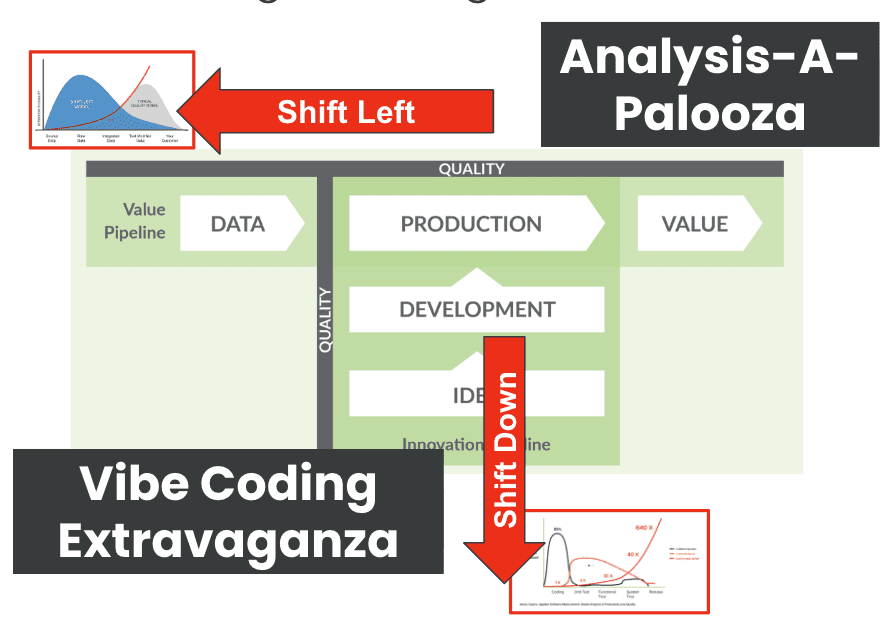
First, there’s what we might call “Analysis-A-Palooza.” More people in more roles are now taking data directly to LLMs for analysis. Marketing managers who previously relied on pre-built dashboards are now uploading CSV files to ChatGPT or Claude. Sales representatives are asking AI to analyze their pipeline data. Executives are querying financial data using natural language. This democratization of data analysis sounds wonderful in theory, but it dramatically increases the need for extensive data quality controls. Every table, every column, every data point could be fed into an LLM, exponentially expanding the surface area for possible data quality issues.
Second, we’re experiencing a “Vibe Coding Extravaganza.” The barrier to writing code has effectively broken down. Business analysts are using AI assistants to craft SQL queries. Product managers are generating Python scripts. Even executives are creating data transformations using LLMs. While this democratization of coding skills seems empowering, it results in more code being developed and deployed by people who might not fully grasp the implications of what they’re building. This amplifies the critical need for end-to-end regression testing and thorough data quality coverage.
Ye Olde DataOps
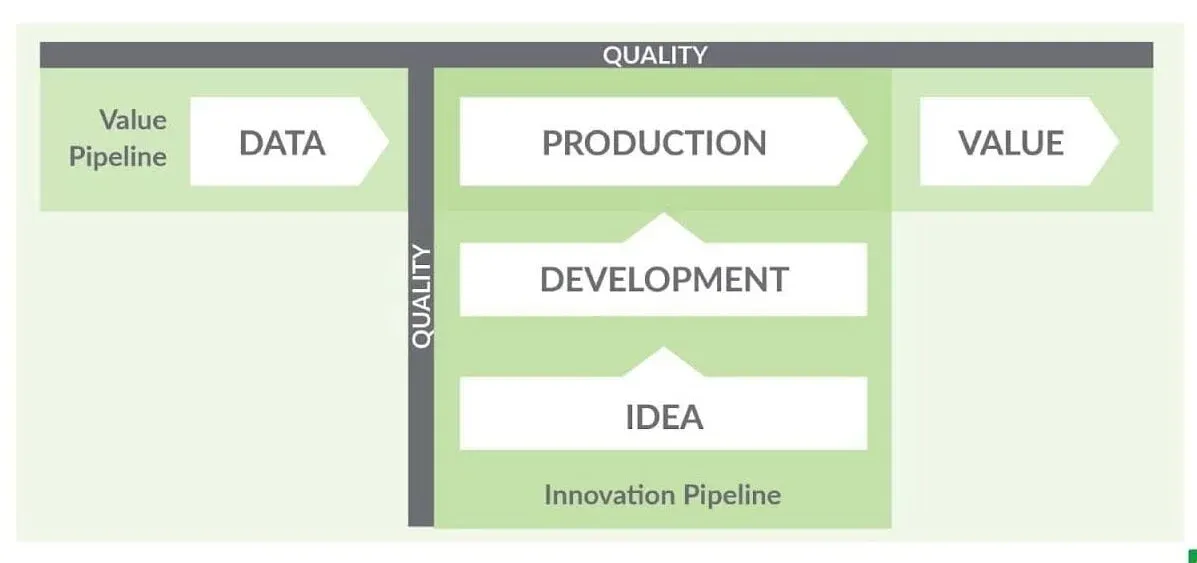
Before we dive deeper into how LLMs are changing the game, it’s essential to understand the DataOps framework that provides our foundation for addressing these challenges. DataOps recognizes two key pipelines in any data organization: the Value Pipeline and the Innovation Pipeline.
The Value Pipeline represents the flow from raw data through production systems to delivered value for customers and stakeholders. This is where your ETL processes, data warehouses, and reporting systems live. It’s the backbone of your data operations, and any failure here directly impacts business operations.
The Innovation Pipeline represents the journey from ideas through development to production deployment. This pipeline is where new analytics capabilities are born, tested, and refined before being promoted to production. The key insight of DataOps is that these two pipelines must be managed with equal rigor, with quality gates at every stage.
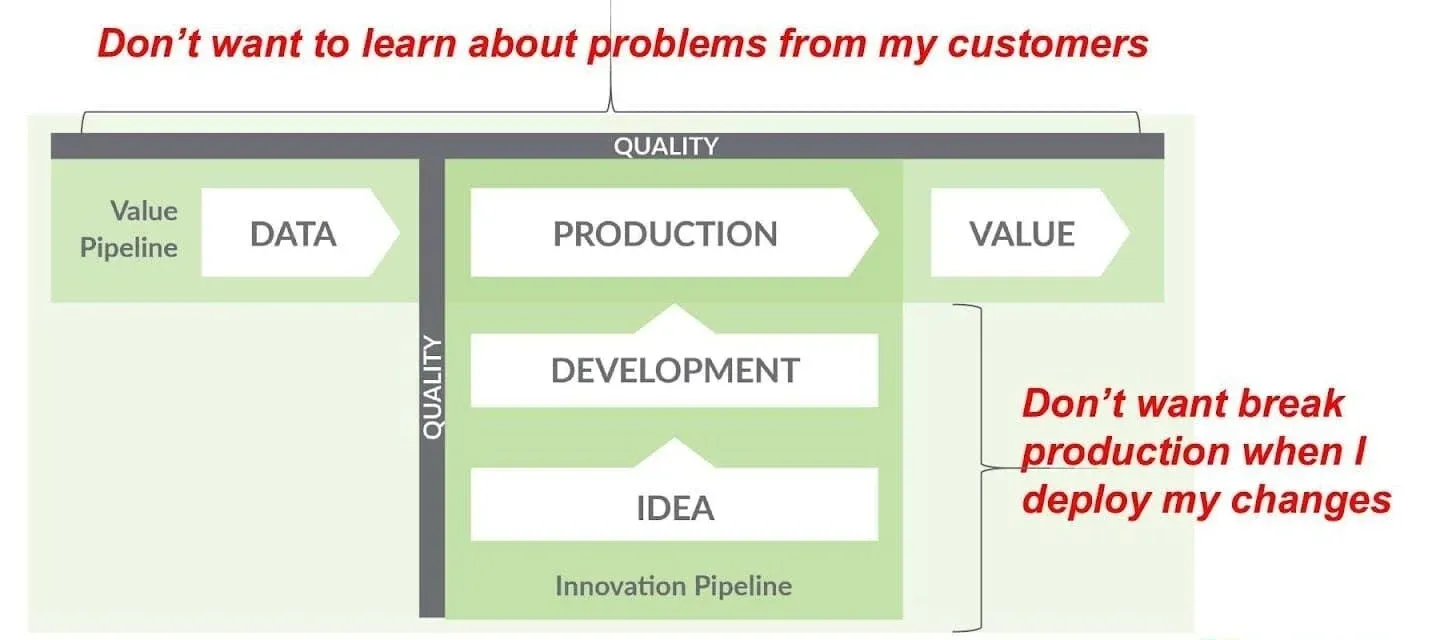
What DataOps helps you avoid is learning about problems from your customers, which is both embarrassing and expensive. It also prevents the all-too-common scenario of breaking production during deployments. By implementing proper testing and monitoring throughout both pipelines, you can catch issues early when they’re cheap and easy to fix.
Welcome To The ‘Analysis-A-Palooza:’ LLMs Directly Analyzing Data
The proliferation of AI and LLM usage across organizations has fundamentally changed the data quality equation. Previously, data teams could focus their quality efforts on critical datasets and key metrics that powered executive dashboards and operational reports. They knew which tables mattered most and which columns were actually being used. This allowed for targeted quality efforts on high-impact data.
That comfortable situation is now history. With LLMs, users are analyzing data from every corner of the data warehouse. That obscure table from a system sunset three years ago? Someone just fed it to ChatGPT for historical analysis. Those columns that were supposedly “just for reference”? They’re now being used to train custom models. Every single piece of data in your organization has become potentially critical.

This dramatic expansion of the data usage surface area means we need a fundamentally different approach to test coverage. Manual testing strategies that might have worked when we had a dozen critical tables simply don’t scale when an AI model can access every table and column at any time. Organizations need comprehensive test coverage across all levels and zones in their databases and data lakes. Every table should have tests for consistency, volume, freshness, and schema. Every column should be monitored for quality drift. Every significant business metric needs domain-specific validation.
The challenge becomes even more complex when you consider that different LLM use cases may interpret data quality issues differently. A null value that’s acceptable for a summary report might cause an LLM to hallucinate wildly. A slight schema change that goes unnoticed in traditional analytics could completely break an AI model’s ability to process information correctly.
How Using LLMs To Analyze Data Compounds Data Quality Challenges
Here’s a sobering reality that many organizations are just beginning to grasp: LLMs don’t magically fix insufficient data; they amplify its impact. Consider a typical scenario where your data is 80% correct and your LLM is 80% accurate. Simple multiplication tells us that your expected output accuracy drops to just 64%. This compounding effect means that data quality issues that might have been tolerable in traditional analytics become catastrophic when fed through AI systems.
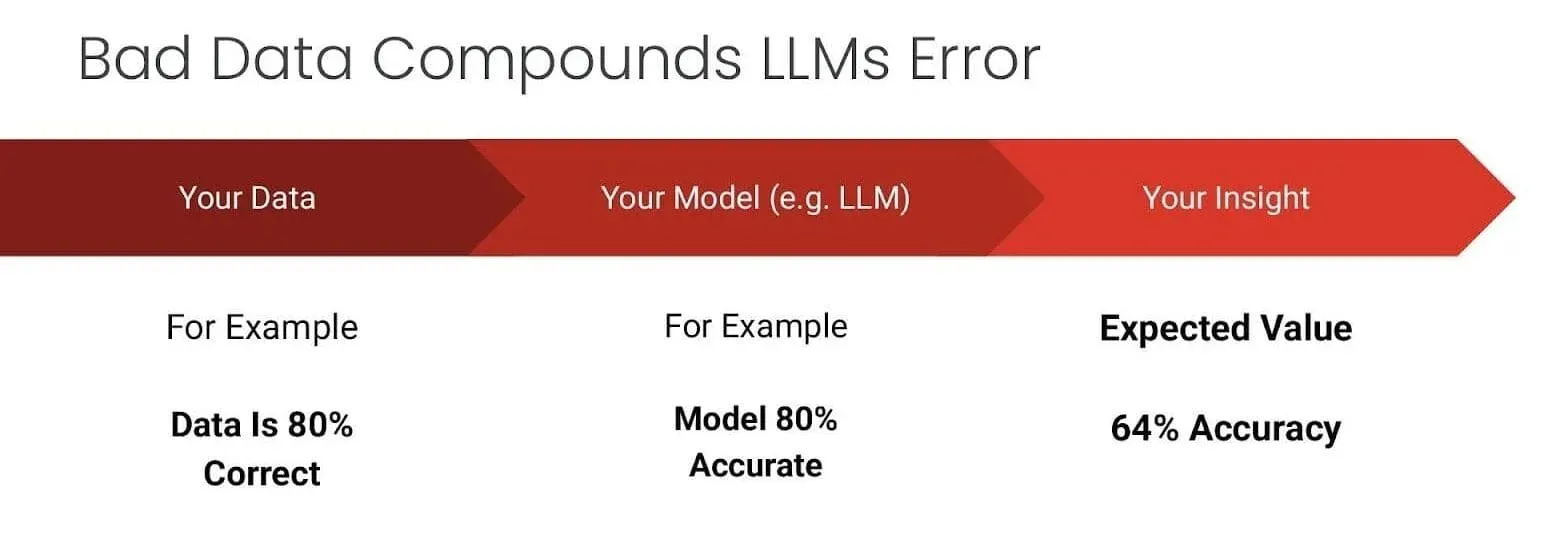
The implications are significant. Is that customer segmentation with a few misclassified records? When an LLM uses it to create personalized marketing campaigns, those mistakes can multiply across every piece of generated content. Is that a financial dataset with some missing values? When an AI analyzes it for strategic insights, those gaps can lead to fundamentally flawed recommendations.
This multiplication effect makes the traditional “we’ll fix it if someone complains” approach to data quality completely untenable in the age of AI. We need proactive, comprehensive data quality strategies that catch issues before they’re amplified by machine learning models or gobbled up by an LLM.
Data Quality Test Coverage Reduces Problems Created By LLM-Wielding Analysts
The explosion of LLM adoption has fundamentally changed the stakes for data quality test coverage. When organizations feed untested data directly into LLMs for analysis, they’re essentially compounding two layers of uncertainty: the inherent probabilistic nature of LLM outputs and the unknown quality issues lurking in their data. LLMs can’t distinguish between accurate and corrupted data – they’ll confidently analyze incomplete datasets, outdated records, or incorrectly transformed fields as if they were pristine. This creates a hazardous scenario where sophisticated-sounding AI analysis masks underlying data problems, leading to decisions based on what appears to be cutting-edge intelligence but is actually sophisticated garbage. The hallucination problem that already plagues LLMs becomes exponentially worse when the training or analysis data itself contains errors, duplicates, or inconsistencies. The shift-left approach to data quality – testing data as early as possible in the pipeline rather than waiting until it reaches production – becomes critical when that production endpoint is an LLM that will amplify any data issues into convincing but flawed narratives.
TIP
Automated Test Coverage Is Essential. Open Source DataOps Data Quality TestGen provides quick and easy test coverage.
Comprehensive test coverage acts as the critical safety net between raw data and LLM consumption. By implementing thorough validation checks across data pipelines – including schema validation, referential integrity tests, statistical distribution monitoring, and business rule verification – organizations can ensure that LLMs work with trustworthy inputs. This means testing not just the final data products, but every transformation step, every join operation, and every aggregation that shapes the data before it reaches the AI system. To achieve meaningful coverage, data teams typically need at least 2-3 quality tests per column and table. For a typical analytics database with hundreds of tables and thousands of columns, this translates to thousands of individual tests – a scale that’s impossible to achieve through manual test creation. This is why automated test generation tools have become essential, using profiling and machine learning to automatically suggest and create appropriate tests based on the data’s characteristics, historical patterns, and detected anomalies.
Inadequate test coverage for LLM-driven analysis risks catastrophic, often invisible, business impacts, such as AI making recommendations based on duplicate, stale, or incomplete data, presented with false authority. Adopting a shift-left approach catches issues cheaply at the source. Modern, automated data quality tools can rapidly profile data and generate tests, providing the necessary coverage density for LLM readiness. Conversely, robust, automated testing enables confident LLM scaling, with quality gates preventing bad data from propagating into AI outputs. Investing in comprehensive, automated testing not only prevents costly errors but also accelerates AI adoption by ensuring a solid data foundation.
Welcome To the Vibe Coding Extravaganza
We’ve entered what might be called the “Vibe Coding Era,” a fundamental shift in who creates code and how it’s created. The evolution is striking. We’ve moved from the “Deep Nerd Coding Era” of the 70s-90s, where programming required deep technical knowledge and manual consultation, through the “TechBro Coding Era” of the 2010s and 2020s, dominated by Stack Overflow and search-driven development, to today’s “Everybody Codes Era” where natural language prompts generate functional code.

This democratization seems wonderful at first glance. Business users can now create their own data transformations. Analysts can write complex SQL without years of training. Managers can build Python scripts to automate their workflows. But this explosion of citizen developers brings serious challenges.
Consider how LLMs approach SQL generation. Recent benchmarks using Spider 2.0, a comprehensive test suite for SQL generation, reveal sobering limitations. Even the most advanced models struggle with real-world database queries. Spider 2.0-Snow peaks at just 59.05% accuracy, while Spider 2.0-DBT tops out at a mere 39.71%. These aren’t edge cases or particularly complex queries; they’re representative of actual business questions that organizations need to answer daily.
The fundamental issue is that LLMs can generate syntactically correct SQL that looks perfect but fails spectacularly when run against actual data. They don’t understand your specific data models, business rules, or the inevitable quirks and exceptions that exist in every real-world database. They can’t intuit that the “customer_type” field uses different codes in different tables, or that certain date ranges have known data quality issues.
This gap between apparent capability and actual performance creates a dangerous situation. Users gain false confidence from AI-generated code that works on sample data but breaks in production. They create tables and transformations that appear functional but introduce subtle errors that compound over time. They build analytics pipelines that seem sophisticated but lack proper error handling, testing, or documentation.
Metadata Context: Not A Miracle Cure For Vibe Coding
The key to improving LLM performance in data tasks lies in providing proper context. AI generates code that looks right but fails because it lacks an understanding of your actual data ecosystem. It doesn’t know about your business logic, data relationships, or the countless unwritten rules that govern your data.
“Data Context” formalizes this hidden knowledge, making it accessible to AI systems. This includes data profiling information that reveals actual value distributions and patterns, data catalog entries that document business meanings and relationships, data quality test results that highlight known issues and constraints, and institutional knowledge about how data should and shouldn’t be used.

When LLMs have access to this context, their accuracy improves dramatically. Instead of guessing that a field contains customer IDs, they know the exact format and valid ranges. Instead of assuming standard SQL will work, they understand which database-specific syntax to use. Instead of treating all data as equally reliable, they can account for known quality issues.
However, context isn’t a miracle cure. Even with perfect context, we should expect more code to be created by more people, and much of it will be of lower quality than what experienced developers would produce. This reality makes comprehensive testing and monitoring even more critical.
Shift-Down Regression Testing Makes Vibe Coding Sustainable
Just as shift-left principles tell us to catch data quality issues early in the data pipeline, “shift-down” principles tell us to catch code and logic errors early in the development process. The economics are equally compelling. Issues caught during development might take minutes to fix. The same issues discovered in production could require hours of debugging, data cleanup, and stakeholder management.
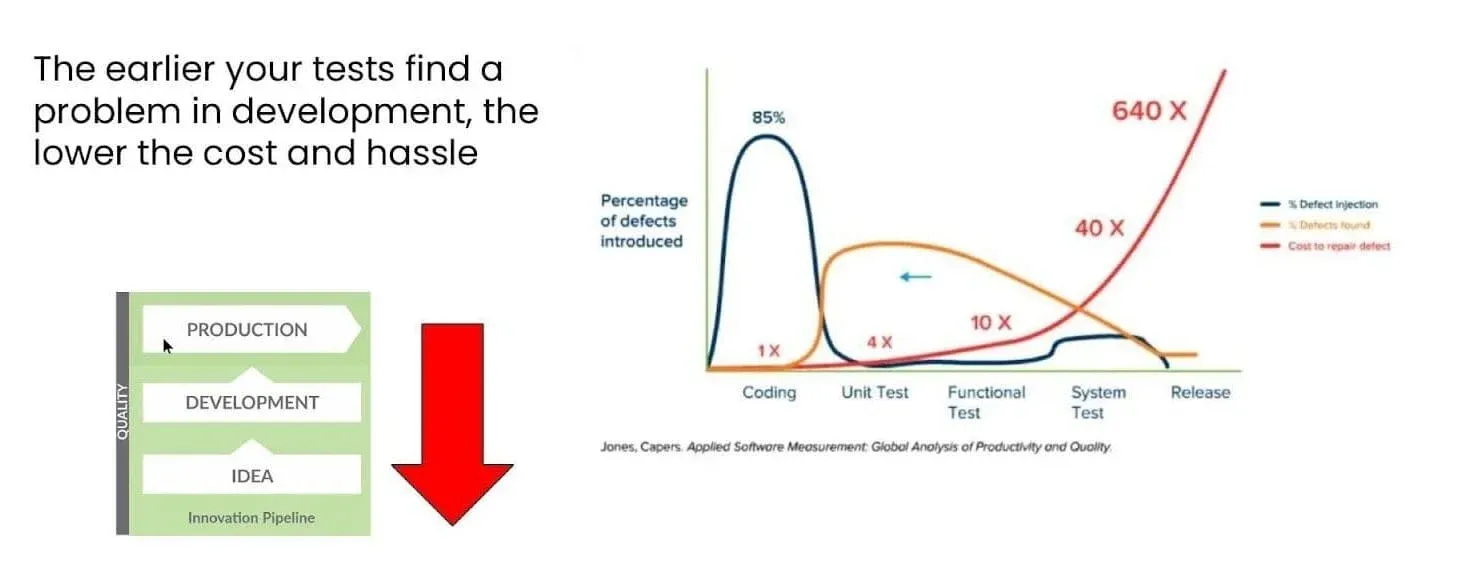
This shift-down approach requires comprehensive end-to-end testing environments that allow developers to validate their changes before promotion to production. It means having test data that accurately represents production scenarios. It requires automated testing frameworks that can validate not just code syntax but actual business logic and data transformations.
In the age of vibe coding, where an AI might generate dozens of SQL queries in an afternoon, manual code review and testing simply don’t scale. Organizations need automated regression testing that can validate every change across the entire data pipeline. They need development environments that closely mirror production to catch integration issues. They need testing frameworks that can validate not just whether code runs, but whether it produces correct results.
Vibe Coding Demands Comprehensive Test Coverage
The path forward requires implementing comprehensive test coverage across both data and code. This isn’t just about adding a few unit tests or spot-checking critical tables. It requires a systematic approach that covers every layer of the data stack.
For data quality, organizations need automated test generation that can create thousands of tests across all tables and columns. Manual test writing doesn’t scale when dealing with modern data volumes. A junior operator using automated tools can generate 2,500 tests in two steps that would take a trained data engineer over seven months to create manually.
For code quality, especially in the era of AI-generated code, organizations need regression testing that validates the entire data pipeline from source to consumption. This includes testing data access layers, transformation logic, model code, visualization updates, and report generation. Every component that touches data must be validated.
The key insight is that testing can no longer be an afterthought or a “nice to have” when time permits. In a world where LLMs are increasing both data usage and code creation, comprehensive testing becomes the foundation of reliable data operations.
Conclusion: When Everyone Uses An LLM, Only DataOps Thinking Will Tame The Beast
The challenges we’ve discussed require new tools designed specifically for the AI age. Traditional data quality tools that spot-check a few tables won’t suffice when every piece of data might be fed into an LLM. Traditional code review processes break down when AI can generate more code in an hour than a human can review in a day.
Modern data quality platforms need to provide AI-powered test generation that can automatically create comprehensive test suites across entire data estates. They need anomaly detection that can identify issues without explicit rule definition. They need data profiling that goes beyond simple statistics to understand the actual behavior and relationships.
Apply DataOps Principles for Success In The LLM Age
The solution to the Analysis-A-Palooza and Vibe Coding Extravaganza isn’t to restrict LLM usage or return to centralized data control. The democratization of data analysis and code creation is here to stay, and organizations that embrace it while managing its challenges will have a significant competitive advantage.
The path forward requires embracing DataOps principles while adapting them for the AI age. This means implementing shift-left data quality practices that catch issues at the source before AI systems amplify them. It means adopting shift-down testing approaches that validate code and transformations in development before they impact production. It means comprehensive test coverage that accounts for the dramatically expanded surface area of data usage. It means providing rich context to AI systems while maintaining robust validation of their outputs.

TIP
Next Step: Test Coverage is enabled by Open Source Tools like DataKitchen’s DataOps Data Quality TestGen, and Shift Down With DataKitchen’s Open Source DataOps Observability
Organizations that successfully navigate this transition will find themselves with data operations that are more robust, scalable, and valuable than ever before. They’ll be able to leverage the full power of LLMs while maintaining data quality and reliability. They’ll empower citizen developers while preventing chaos in production systems.
The integration of Large Language Models into data operations represents both an enormous opportunity and a significant challenge. LLMs are making our existing data quality and code quality issues worse by amplifying their impact and dramatically expanding who interacts with data and how they do it. But by applying DataOps principles, implementing comprehensive testing strategies, and adopting tools designed for the AI age, organizations can turn this challenge into a competitive advantage.
The key is to stop treating data quality and data observability as optional, nice-to-have add-ons and start treating them as fundamental requirements for AI success. Just as you wouldn’t feed your body junk food and expect optimal performance, you can’t feed your AI systems low-quality data and expect reliable insights. By focusing on data quality early, reducing testing gaps, and ensuring comprehensive coverage across your entire data estate, you can ensure your AI systems receive the high-quality, nutritious data they need to thrive.
TIP
Want to learn more? Watch the webinar: Data Quality, DataOps, and Large Language Models



