In the Olympic quest for data quality, the Medallion Data Lakehouse Architecture is the ultimate marathon, where data teams strive to go beyond the Bronze and Silver to take the Gold. Each stage represents a new data accuracy and quality challenge; the Medallion architecture combines raw, cleansed, and analysis-ready data in a powerful three-tier system. However, ensuring data quality at every layer is a challenging feat. Just as elite athletes rely on rigorous training and constant feedback to reach peak performance, data teams need a flexible, iterative approach to spot and address quality issues early. Adopting a DataOps mindset transforms data quality into a dynamic, continuous process, allowing teams to improve incrementally through feedback loops and adapting to issues. This approach empowers individuals across the organization to champion data quality, enabling a fast-paced yet precise journey toward excellence. In this data quality race, DataOps makes data quality testing a natural, built-in practice, laying a foundation for constant refinement and ensuring that data teams remain on track to win Gold in accuracy, reliability, and organizational trust.
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer? How do you get both speed of execution and accuracy of testing? Read more to find out!
Bronze, Silver, and Gold – The Data Architecture Olympics?
The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment. This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority.
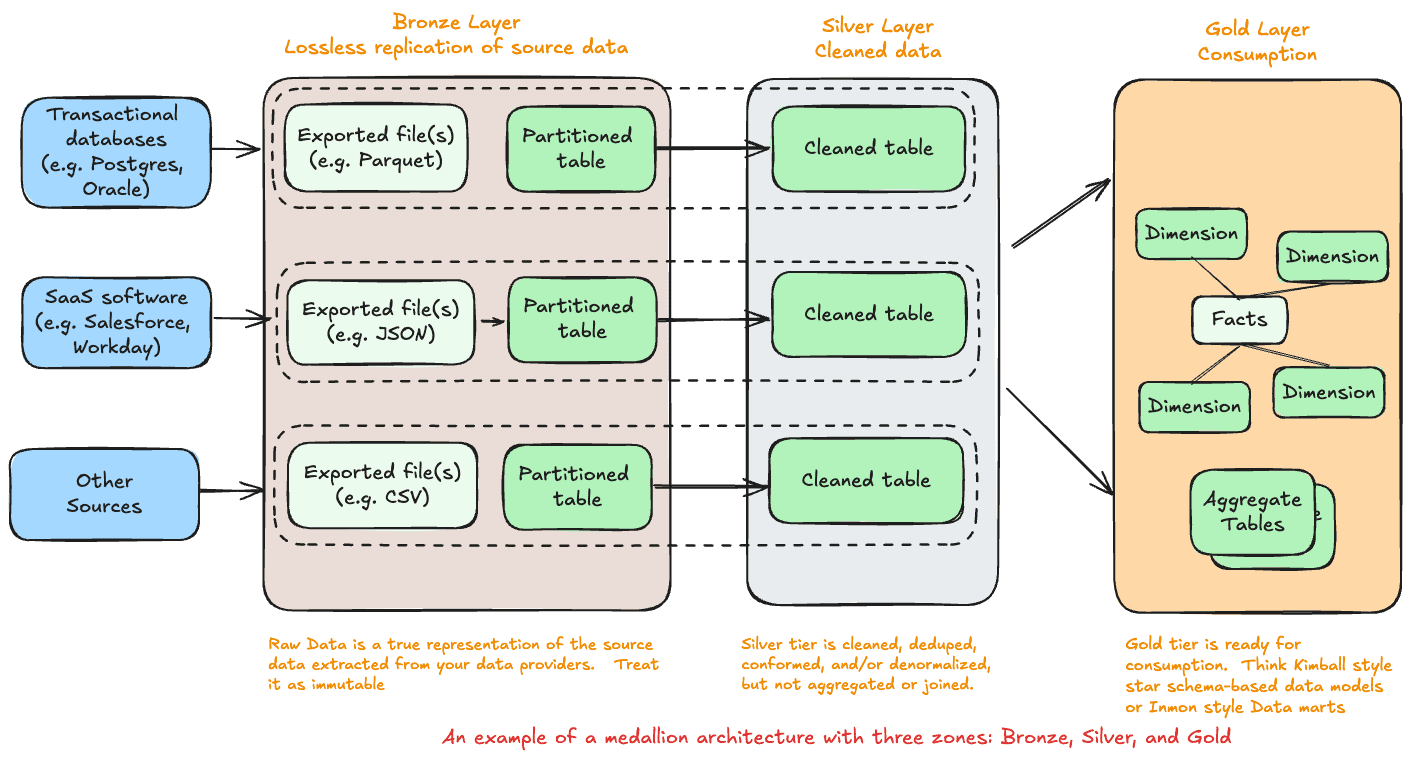
The Bronze layer is the initial landing zone for all incoming raw data, capturing it in its unprocessed, original form. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. By storing data in its native state in cloud storage solutions such as AWS S3, Google Cloud Storage, or Azure ADLS, the Bronze layer preserves the full fidelity of the data. This raw, historical archive is essential for traceability and allows data engineers to load new data into the lakehouse incrementally through batch uploads or real-time streaming. While the Bronze layer doesn’t offer the cleanliness or standardization necessary for analysis, it is a critical foundation upon which the Silver and Gold layers are built. Bronze layers can also be the raw database tables. Bronze layers should be immutable.
Next, data is processed in the Silver layer, which undergoes “just enough” cleaning and transformation to provide a unified, enterprise-wide view of core business entities. This stage involves validation, deduplication, and merging of data from different sources, ensuring that the data is in a more consistent and reliable format. For instance, records may be cleaned up to create unique, non-duplicated transaction logs, master customer records, and cross-reference tables. The Silver layer aims to create a structured, validated data source that multiple organizations can access. This intermediate layer strikes a balance by refining data enough to be useful for general analytics and reporting while still retaining flexibility for further transformations in the Gold layer. Expect the schema to be similar but not the same as the Bronze layer. Alternatively, the Data Vault methodology can be applied to the Silver layer, where data is transformed into Hubs, links, and satellites.
Finally, the Gold layer represents the pinnacle of the Medallion architecture, housing fully refined, aggregated, and analysis-ready data. Data is typically organized into project-specific schemas optimized for business intelligence (BI) applications, advanced analytics, and machine learning. Whether it’s customer analytics, product quality assessments, or inventory insights, the Gold layer is tailored to support specific analytical use cases. This layer is often characterized by de-normalized, read-optimized tables that minimize the need for joins and are structured according to data warehousing methodologies, such as Kimball’s star schema or Inmon’s data marts. When data reaches the Gold layer, it is highly curated and structured, offering a single version of the truth for decision-makers across the organization.
We have also seen a fourth layer, the Platinum layer, in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. We recently talked with one company whose Data Journey is a path from SAP & Teradata to ADLS (Bronze/Silver/Gold) and finally to Synapse for usage.
The Medallion architecture offers several benefits, making it an attractive choice for data engineering teams. By preserving raw data in the Bronze layer, organizations have a historical archive they can revert to, ensuring transparency and traceability. The structured flow through Silver to Gold allows flexibility in handling new transformations and aggregations. At the same time, the Gold layer’s “single version of the truth” makes data accessible and reliable for reporting and analytics. However, this architecture is not without its challenges. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines. For businesses requiring near-real-time insights, the time taken to traverse multiple layers may also introduce delays.
Moreover, implementing Medallion architecture involves sophisticated configuration and careful management of changes across all layers, which can complicate day-to-day operations. Finally, the challenge we are addressing in this document – is how to prove the data is correct at each layer.? How do you ensure data quality in every layer?
The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment. By methodically processing data through Bronze, Silver, and Gold layers, this approach supports a variety of use cases. It provides a structured path from raw data to actionable insights, although it requires careful planning and consideration of specific business needs and data quality.
Data Quality Challenges That Cause You To Lose The Medallion Race
In a Medallion architecture, while the structured progression of data through Bronze, Silver, and Gold layers is designed to enhance organization, numerous data quality challenges can still arise, particularly once the architecture is in production. These “Day 2” production quality assurance (QA) issues can disrupt customer satisfaction, introduce inaccuracies, and ultimately undermine the value of analytics. Data engineering teams must understand these problems and incorporate mechanisms to detect and mitigate them. Key challenges include identifying the problem type and finding each issue’s root cause and layer before your customer finds it for you and your team!
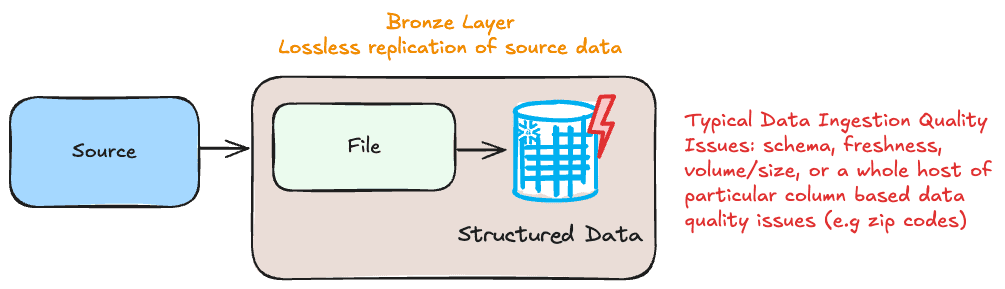
One common problem in production environments is when data fails to load correctly into one or more layers of the architecture, causing interruptions across the data pipeline. For instance, suppose a new dataset from an IoT device is meant to be ingested daily into the Bronze layer. Still, due to connectivity issues or file format mismatches, the load fails. This failure can cascade to the Silver and Gold layers, where downstream dependencies on the raw data prevent those layers from updating accurately. Such issues often go unnoticed until a user or analyst reports missing information in a dashboard or report, by which point the delay has already impacted business decision-making. You have typical data ingestion layer challenges in the bronze layer: lack of sufficient rows, delays, changes in schema, or more detailed structural/quality problems in the data.
Data missing or incomplete at various stages is another critical quality issue in the Medallion architecture. In a Silver layer, for example, merging and deduplication processes rely on complete records to create clean datasets for analysis. Suppose a batch from a transactional system only loads partial records into the Bronze layer due to truncation or data source issues. In that case, the Silver layer can inadvertently generate incomplete or inaccurate views. For instance, a table that shows customer purchase histories could display partial transaction data, leading analysts to underestimate sales or misinterpret customer behavior. Similarly, downstream business metrics in the Gold layer may appear skewed due to missing segments, which can impact high-stakes decisions. Routine checks for row counts, null values, and integrity constraints can help detect missing data early in the pipeline.
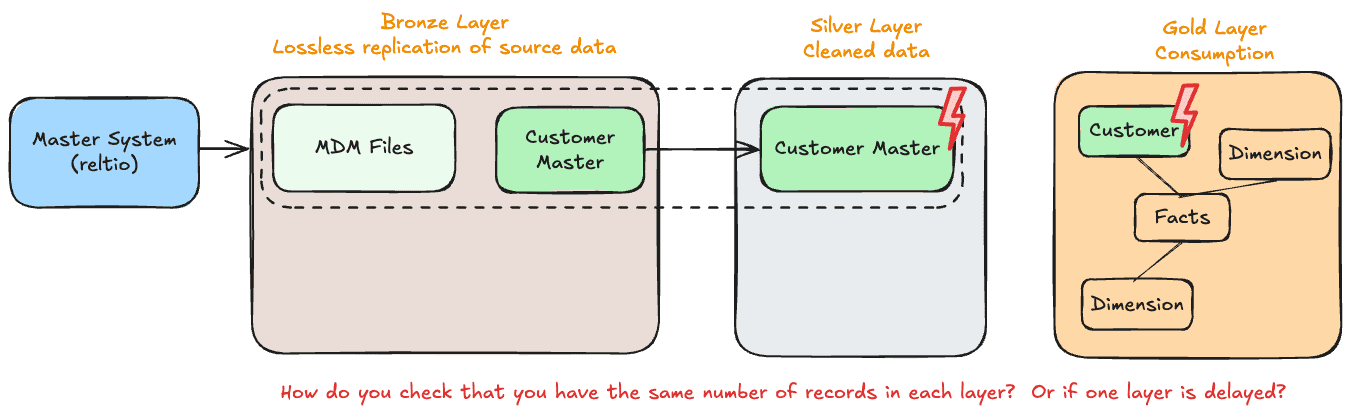
Another common issue is data arriving late, which is particularly challenging in real-time or near-real-time systems. When data from various sources does not reach the Bronze layer on time, it can lead to stale insights and missed opportunities in the Gold layer, especially for time-sensitive applications like inventory tracking or marketing campaigns. For example, if data about online customer interactions is delayed due to source system lags, the Gold layer’s customer segmentation analysis may fail to reflect recent behavior, leading to irrelevant or poorly targeted campaigns. Late data can also create mismatches in time-based aggregations and reporting, where analytics teams might unknowingly operate on outdated information.
Detailed Data Quality issues are another recurring challenge in the Medallion architecture. In the Silver layer, the transformation processes required to standardize, deduplicate, and validate data can inadvertently introduce new quality problems, such as data type mismatches, improper joins, or invalid replacements. When moving data from the cleaned and enriched Silver layer to the ready-for-consumption Gold layer. An operation to merge customer data across multiple sources might incorrectly aggregate records due to mismatched keys, leading to inflated or deflated metrics in the Silver layer. Issues can propagate unnoticed to the Gold layer, where they can alter the final analytical outputs.
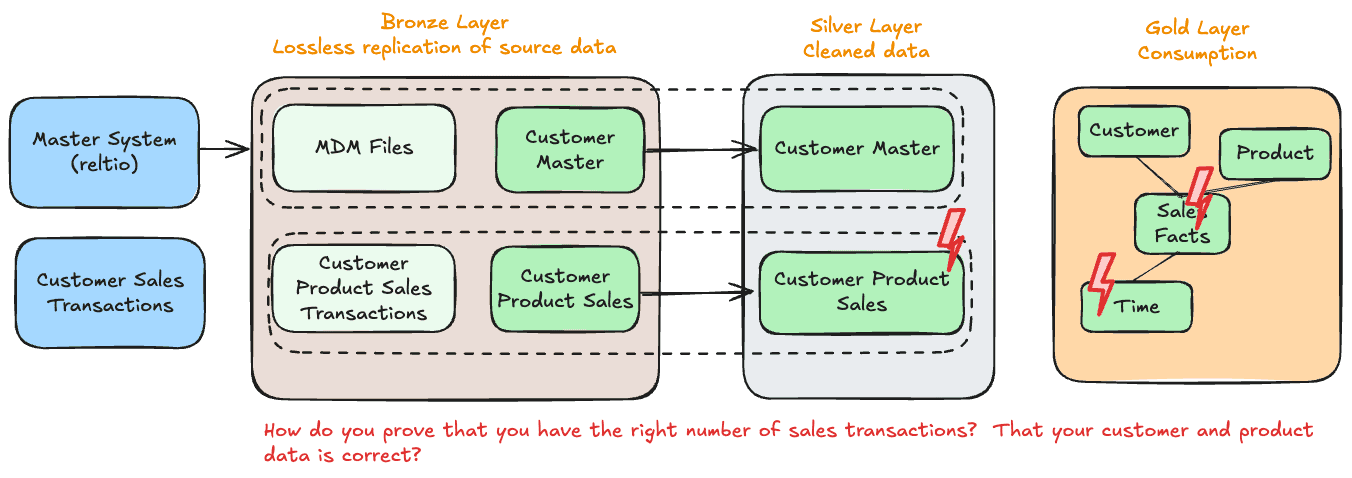
In production environments, these issues require proactive data quality monitoring and quick response capabilities to ensure that data flowing through the Medallion architecture remains accurate, timely, and complete. By incorporating automated alerting systems, regular QA checks, and well-defined SLAs for data loading, data engineering teams can better manage Day 2 production challenges, helping to preserve the integrity and reliability of their analytical outputs.
Get Off The Blocks Fast: Data Quality In The Bronze Layer
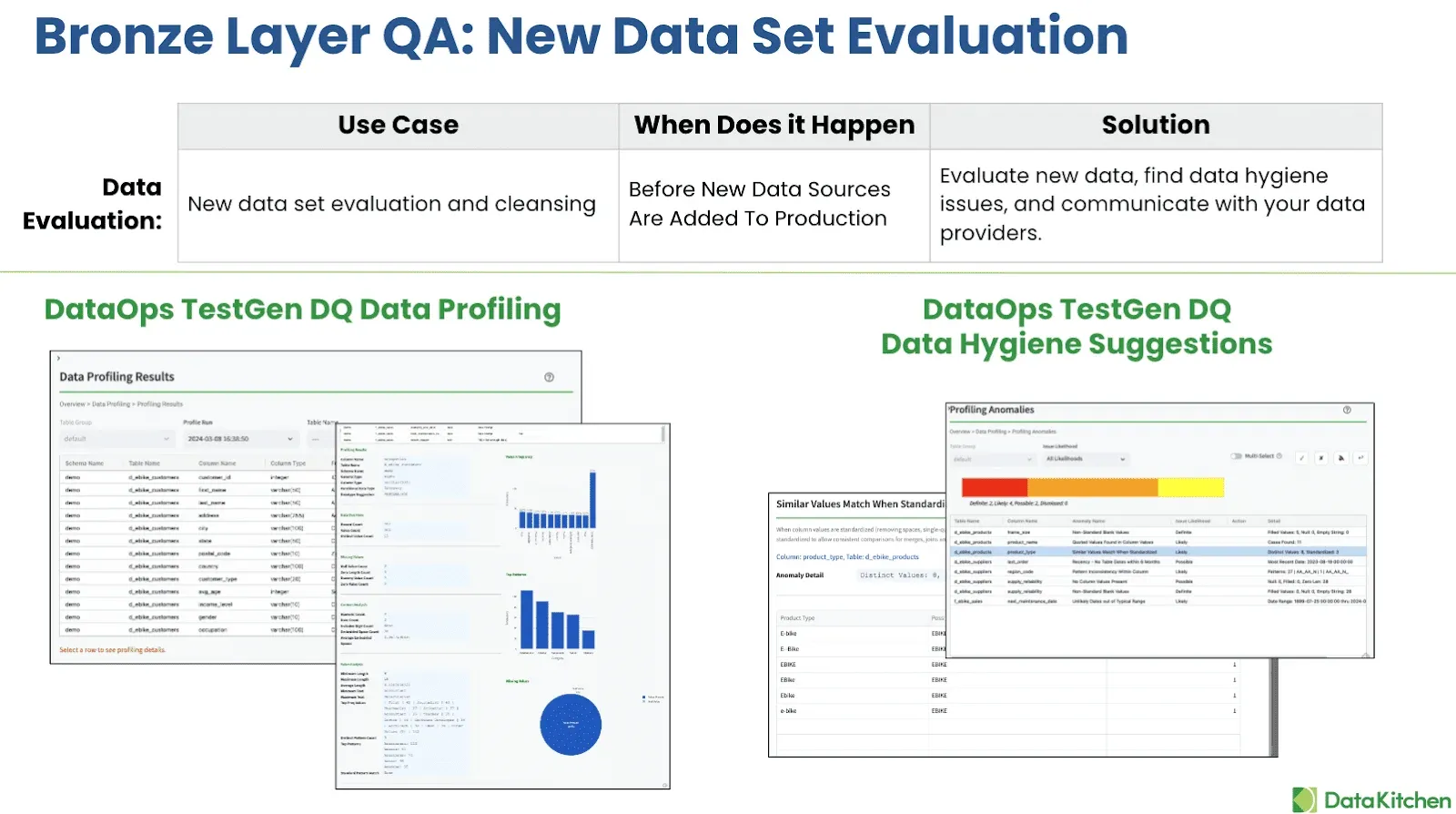
Effective Production QA techniques begin with rigorous automated testing at the Bronze layer, where raw data enters the lakehouse environment. The first part of Data Quality (DQ) training focuses on onboarding new datasets, which includes evaluating and cleansing them before they progress through the pipeline. This process involves detailed data profiling and column-by-column hygiene checks, which help detect hidden issues like null values, incorrect formats, and unexpected duplicates that can undermine data accuracy. During this phase, data teams must decide whether to patch problematic data, push back to data sources for corrections, or pass it through if it meets quality standards.
As data ingestion transitions to a continuous flow, the second part of DQ training equips engineers to monitor schema consistency, row counts, and data freshness, ensuring data integrity over time. This involves setting up automated, column-by-column quality tests to quickly identify deviations from expected values and catch emerging issues before they impact downstream layers. Four key areas for data quality check during continual data updates are:
- Freshness Anomaly Checking (did we get something new): Freshness data ingestion tests and anomaly checks help ensure that new data is consistently being ingested by verifying date-related metrics in a dataset. These tests include checking that recent dates are within expected ranges, distinct date counts have not dropped, and that date boundaries, such as future and minimum dates, align with the baseline data.
- Volume Anomaly Checking (did we get enough): Volume data ingestion tests and anomaly checks ensure that sufficient new data is being ingested by comparing current record counts and distributions against baseline expectations. These tests include verifying that record counts haven’t dropped, are within an acceptable range, and that records exist consistently across daily, weekly, and monthly intervals.
- Schema Anomaly Detection (does it fit): Schema data ingestion tests and anomaly checks verify that incoming data aligns with expected formats and values defined by the baseline schema. These tests include validating that values match specified lists, patterns, or formats (such as email or addresses) and ensuring no truncation occurs in alphanumeric or decimal values.
- Data Drift Checks (does it make sense): Is there a shift in the overall data quality? These checks include identifying shifts in averages, detecting outliers, monitoring variability changes, and verifying that minimum values, missing data percentages, and uniqueness rates align with established baselines.
 |  |
|---|
Tools like DataOps Data Quality TestGen can be leveraged to automate test generation, making it easier for data teams to implement robust QA checks. For those looking to deepen their expertise, obtaining certification in data observability and data quality testing can further enhance their skills and proficiency. The certification program offered by DataKitchen provides a structured approach to mastering these concepts, enabling QA teams to uphold high data quality standards in production environments. For more information, check out the certification at DataKitchen’s website.
Run With Excellence: Data Quality in The Silver Layer
Testing the Silver layer in a Medallion architecture is crucial for maintaining high data quality, as this is the stage where raw data from the Bronze layer is cleansed, validated, and transformed into a standardized format for broader organizational use. Since this layer serves as a centralized source of trusted data, it’s essential to perform comprehensive quality checks to ensure data consistency and reliability. One of the fundamental steps in validating Silver layer data is conducting table-by-table count matching. This involves checking that the number of records aligns with expectations and matches prior ingestion records, preventing discrepancies that could indicate data loss or duplication.
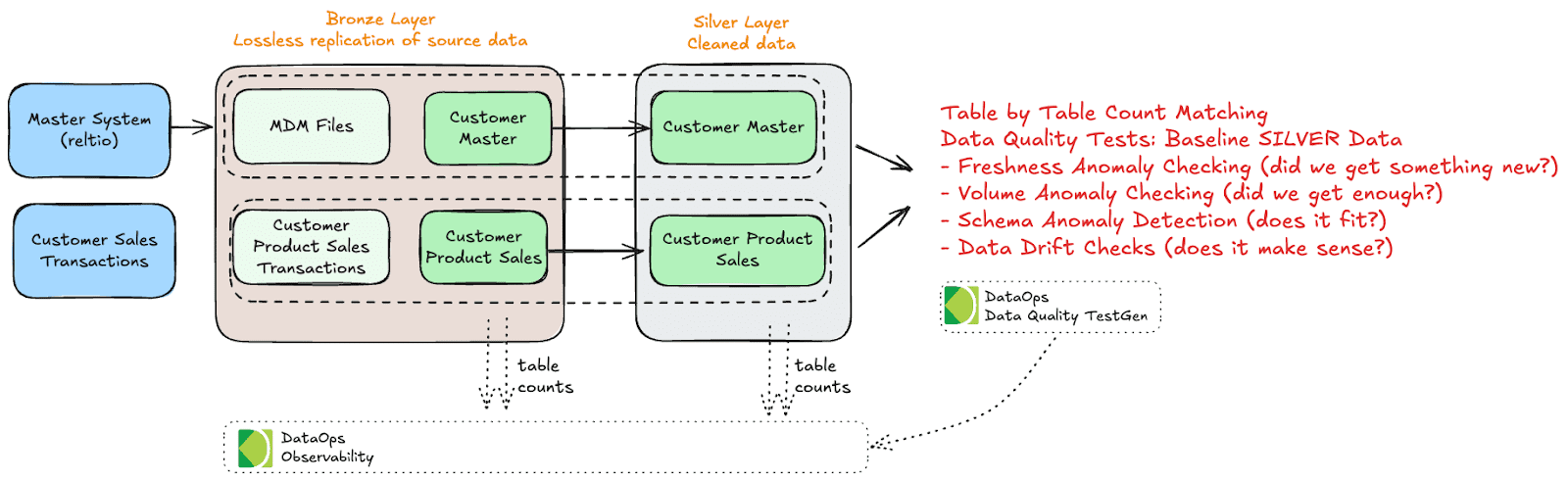
Beyond record counts, several vital data quality tests should be part of Silver layer validation. Freshness anomaly checks verify that the data is current by confirming recent updates or additions, ensuring that the Silver layer reflects the latest information from the Bronze layer. Volume anomaly checking ensures that enough data is being ingested, flagging instances where data might be missing due to issues in the upstream ingestion process. Schema anomaly detection helps verify that data structures align with expected formats, preventing schema mismatches that could cause issues during data processing. Finally, data drift checks examine whether the statistical properties of the data have significantly shifted compared to historical baselines, which can help identify unexpected changes or trends that may affect data accuracy or stability.
All these checks are similar to the Bronze layer, so you have two options. One option is to copy all these tests from the Bronze layer to the Silver layer and then run them in the Silver. This works if your schemas/ddl in each layer are precisely the same. Another option, if the Silver schema is not the same as Bronze, is to re-generate all your tests (using a tool like DataOps DQ TestGen) baselined in the Silver data. This creates a test set based on the silver schema, allowing you to catch data quality variance. Every time you receive an update of the data, running these checks can ensure the data is correct even if the schema differs slightly from the bronze layer.
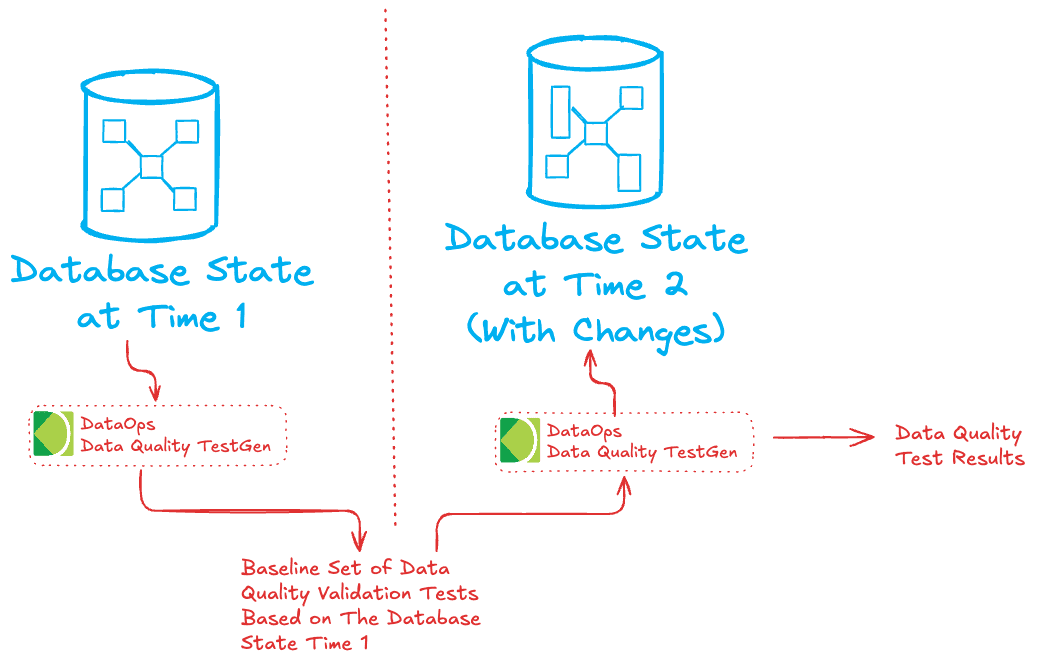
When implementing these tests in the Silver layer, two main approaches can be taken depending on the level of control over the ingestion process. If you can modify or control the ingestion code, data quality tests, and validation checks should ideally be integrated directly into the process. Running these tests immediately upon data arrival ensures that issues are detected early, minimizing the impact on downstream processes. Alternatively, suppose you do not control the ingestion code. In that case, a practical approach is to set up periodic polling of the Silver layer database to run data quality tests and check for anomalies at scheduled intervals. Regular polling helps identify issues without direct integration into the ingestion code, providing a safeguard to maintain data quality across the Silver layer. This same choice works on any layer: Bronze, Silver or Gold.
Break The Ribbon With Gold Layer Data Quality
In the Gold layer of a Medallion architecture, data quality testing takes on a business-centric focus, as this layer is arranged explicitly in an analysis-ready schema design to support decision-making and reporting. Quality checks in the Gold layer ensure data consistency and integrity and validate that the data accurately reflects critical business metrics and entities. One of the primary testing methods involves count matching between the Gold and Silver layers for each essential business entity or dimension, such as the number of customers, transactions, or products. By verifying that the counts in the Gold layer align with those in the Silver layer, data quality teams can ensure that no data has been lost or inaccurately aggregated in the final transformation stages.
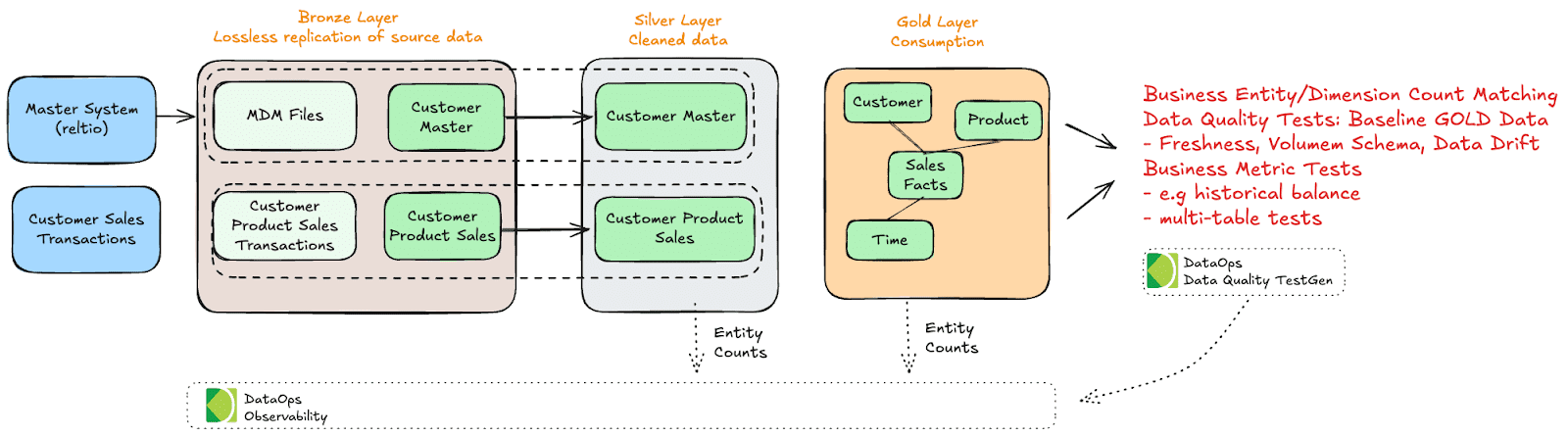
In addition to entity count matching, baseline data quality tests are performed to check for freshness, volume, schema consistency, and data drift in the Gold layer. The Gold layer is most likely to have a unique schema. So, like in the other layers, you need to baseline your test creation in that Gold schema. This creates a test set based on the Gold schema, allowing you to catch data quality variance. Running these checks every time you receive an update of the Gold data can ensure the data is correct.
Furthermore, business metric-specific tests are crucial in the Gold layer, as this layer often consolidates data across multiple tables and sources to produce metrics for business analysis. These tests validate that calculated metrics—such as the number of products sold per region, customer retention rates, or historical balances—are consistent with expectations and historical trends. Multi-table checks are also essential, verifying the consistency of relationships and aggregations across various tables and ensuring that complex business metrics are accurately represented.
Help The Referee With Data Quality Scores
Medallion Architecture and Data Quality Scoring introduce an approach to evaluate and improve data quality at each layer—Bronze, Silver, and Gold—enabling organizations to make data quality an actionable metric that drives better organizational outcomes. In a Medallion architecture, data progresses through these layers, with each stage representing a higher level of cleanliness, enrichment, and readiness for analysis. Data engineering and quality teams can continuously monitor, compare, and improve data quality by applying a scoring system to each layer. This ensures that the final, analysis-ready Gold layer meets the organization’s highest accuracy, completeness, and reliability standards.
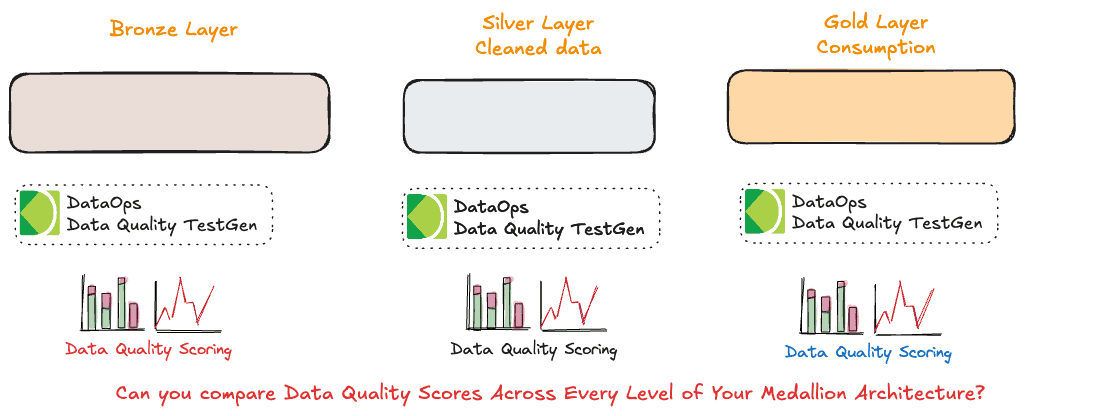
In the Bronze layer, data quality scoring focuses on foundational aspects, as this layer contains raw, unprocessed data. Scores are typically based on attributes like completeness (e.g., missing values), freshness (e.g., data recency), and schema conformity (e.g., alignment with baseline structures). A high score at this stage indicates that raw data is being captured accurately and is ready for cleansing and transformation in the Silver layer. Low scores here can highlight data source issues, prompting corrective actions upstream to ensure better data quality early in the pipeline. Comparing Silver layer scores with Bronze helps identify the efficiency of cleansing and transformation processes. If Silver scores do not significantly improve over Bronze, it may indicate gaps in data processing, pointing to areas where further data enrichment or error-handling routines are needed.
In the Gold layer, where data is fully prepared for analysis, quality scores primarily focus on business relevance, metrics accuracy, and decision-making readiness. Scoring in this layer includes checks on aggregated metrics, consistency in multi-table relationships, and stability of key business indicators like sales performance or customer segments. Since this layer is closest to end-users, a high score in the Gold layer is critical for building organizational trust in data-driven insights. By comparing Gold layer scores with Silver, teams can evaluate whether transformation processes have effectively prepared data for high-stakes analysis. Additionally, discrepancies between Silver and Gold scores can reveal issues like flawed aggregations or business logic misalignment.
Win the Gold With DataOps Data Quality
In a Medallion architecture, maintaining data quality must be a continuous and iterative process that can be challenging to address through traditional, upfront planning approaches—defining all data quality requirements upfront often results in missed issues that only surface later, causing costly delays or setbacks. By adopting a DataOps approach, data quality becomes a dynamic cycle that allows teams to improve and refine data through iterative feedback loops incrementally. This approach maximizes speed while not compromising accuracy, enabling data engineers and quality specialists to identify and correct issues early on. DataOps Data Quality in a Medallion architecture emphasizes empowering individuals within the organization who, while they may not have direct authority, can influence and drive change.
An iterative DataOps cycle starts with measuring data to establish a baseline, followed by evaluating data quality through scoring systems that assess key metrics like accuracy, completeness, and consistency. Using these scores, teams can generate or improve data quality tests tailored to specific issues, such as missing values or anomalies, making quality monitoring proactive and targeted. Continuous data quality scoring then provides ongoing insights, tracking improvements and highlighting areas that need attention. Ultimately, the DataOps approach allows organizations to get data quality processes working quickly and then iterate and improve over time. Documentation and analysis become natural outcomes, not barriers to progress. By starting with testing and measurements, even before standards are fully established, organizations can build a foundation for continuous improvement. The faster the iteration, the more organizations learn, refine their processes, and elevate their data quality standards.
No one likes their customer to find data errors. Data testing in a Medallion architecture is essential for maintaining high data quality across each layer, ensuring that data becomes progressively cleaner, more consistent, and analysis-ready. While this architecture provides a structured path from raw to refined data, pinpointing and troubleshooting errors can make it more challenging as data traverses multiple layers. Quality testing at every stage—Bronze, Silver, and Gold—not only helps catch issues early but also minimizes the risk of data inconsistencies surfacing in customer-facing insights. After all, having a customer uncover a data error is always embarrassing and potentially damaging, so rigorous quality assurance within the Medallion architecture is critical. By prioritizing thorough testing and continuous monitoring, data teams can uphold data integrity, fostering trust in data across the organization.
Start The Race Today With Open Source Tools
DataKitchen provides two open-source tools to help with the DataOps approach to Data Quality and DataOps Observability. They are feature-rich, have a friendly user interface, and are available to use immediately:
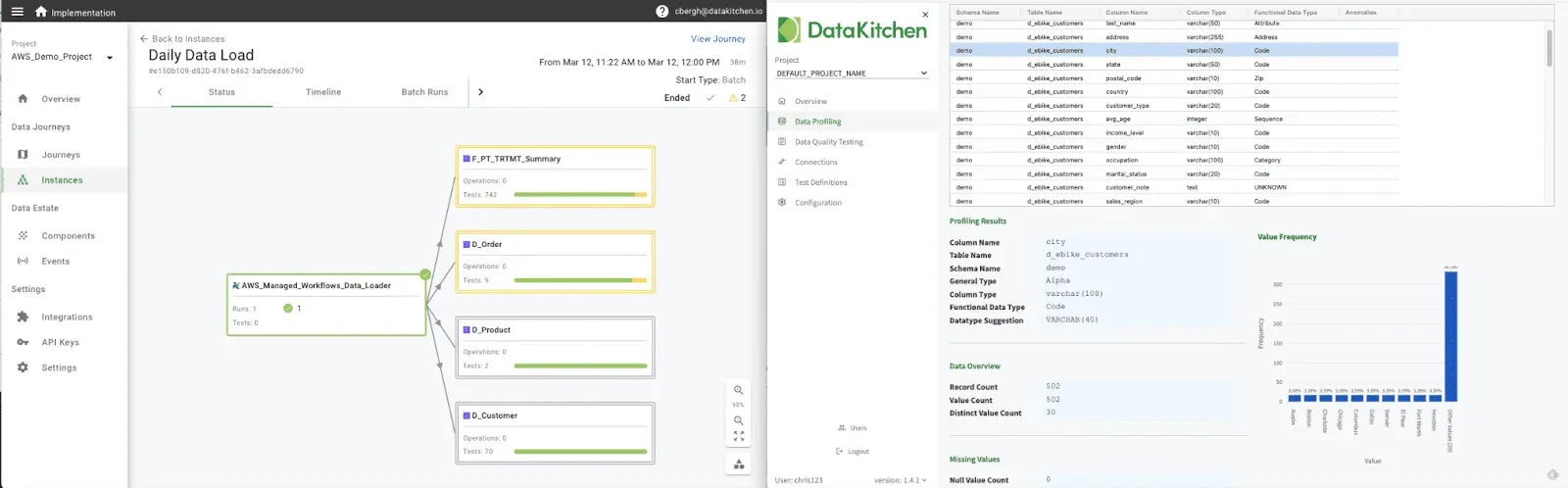
DataOps Data Quality TestGen is a data quality verification tool that does five main tasks: (1) data profiling, (2) new dataset screening and hygiene review, (3) algorithmic generation of data quality validation tests, (4) ongoing production testing of new data refreshes (5) continuous periodic monitoring of datasets for anomalies, and (6) Data Quality Scoring. (GitHub)
DataOps Observability monitors every tool used in the journey of data from data source to customer value, from any team development environment into production, across every tool, team, data set, environment, and project so that problems are detected, localized, and understood immediately (GitHub).