
You’re a small pharma company. Maybe you’ve got one or two assets, maybe you’re a few quarters out from your first commercial launch, maybe you’re staring down a PDUFA date and trying to figure out how thin you can run the burn until then.
The macro picture is not friendly.
The FDA is slower than it used to be. After the 2025 cuts, roughly 3,500 staff left the agency, and biotechs are missing meetings, missing deadlines, and pushing trials. If your runway assumes a clean approval timeline, you’re underwriting a risk you can’t control.

The pricing picture is worse. The White House is projecting $529 billion in savings over ten years from most-favored-nation pricing. The administration says it expects similar agreements with most manufacturers of sole-source brand-name drugs. Seventeen big pharma firms have signed. Richard Pops, now chair of the Midsized Biotech Alliance of America at Alkermes, has said a sloppy MFN law could “inadvertently take out” companies like his. That means companies like yours, too.
The ZS Pharma outlook for 2026 names the squeeze. Lower prices. Higher tariffs. Less NIH and FDA capacity. Tighter VC. The big players need to cut $32 billion in expenses by 2030. The small players don’t have that kind of slack.
So your job for the next 12 to 24 months is to stay alive without going nuts. Keep the powder dry. Don’t burn the runway on a CRO bill, a consulting retainer, or a five-figure-a-month data stack that produces decks nobody reads.
Two problems are hitting at the same time
Your CEO wants AI fast. Your CCO wants the launch to hit its numbers. Your data team has never launched a brand before. None of that works without two things happening at once.
Data engineering has to ship fast with a tiny team. The data underneath your AI tools has to be ready, or the chatbot guesses and is confidently wrong.
Most vendors do one or the other. ZS and Beghou provide analytics consulting, billed at $300 per analyst per hour. Accenture and Deloitte each have a 30-person data engineering team. The Snowflake and Databricks partners know the platform. AI-first vendors sell the chatbot on top. Nobody does both halves.
Move from extractive consulting to AI engineering
We use AI to do data engineering 10x faster. Our engineers run Claude Code inside our DataOps + FITT + Data Testing framework. The AI writes the SQL transforms and the data quality tests. Our DataOps Observability tool watches the pipelines and triages failures. Our engineers focus on the parts AI can’t do: deciding what to build, designing the right data shape, and talking to your team.
This is why 1.5 of our engineers built the entire Cobenfy launch data platform at Karuna over two years. Most pharmas would staff that work with 10 engineers. Field reporting was ready six months before launch.

At Celgene, seven of our engineers supported a $10 billion-a-year commercial portfolio. That was pre-AI. With Claude Code in our stack now, we can do it twice as fast with half the staff.
TestGen generates 120+ AI-driven data quality tests against any pharma dataset. DataOps Observability watches every pipeline. Both Apache 2.0. Both yours without us. We use FITT data architecture, so the platform doesn’t break at 2 am the night before a board meeting.
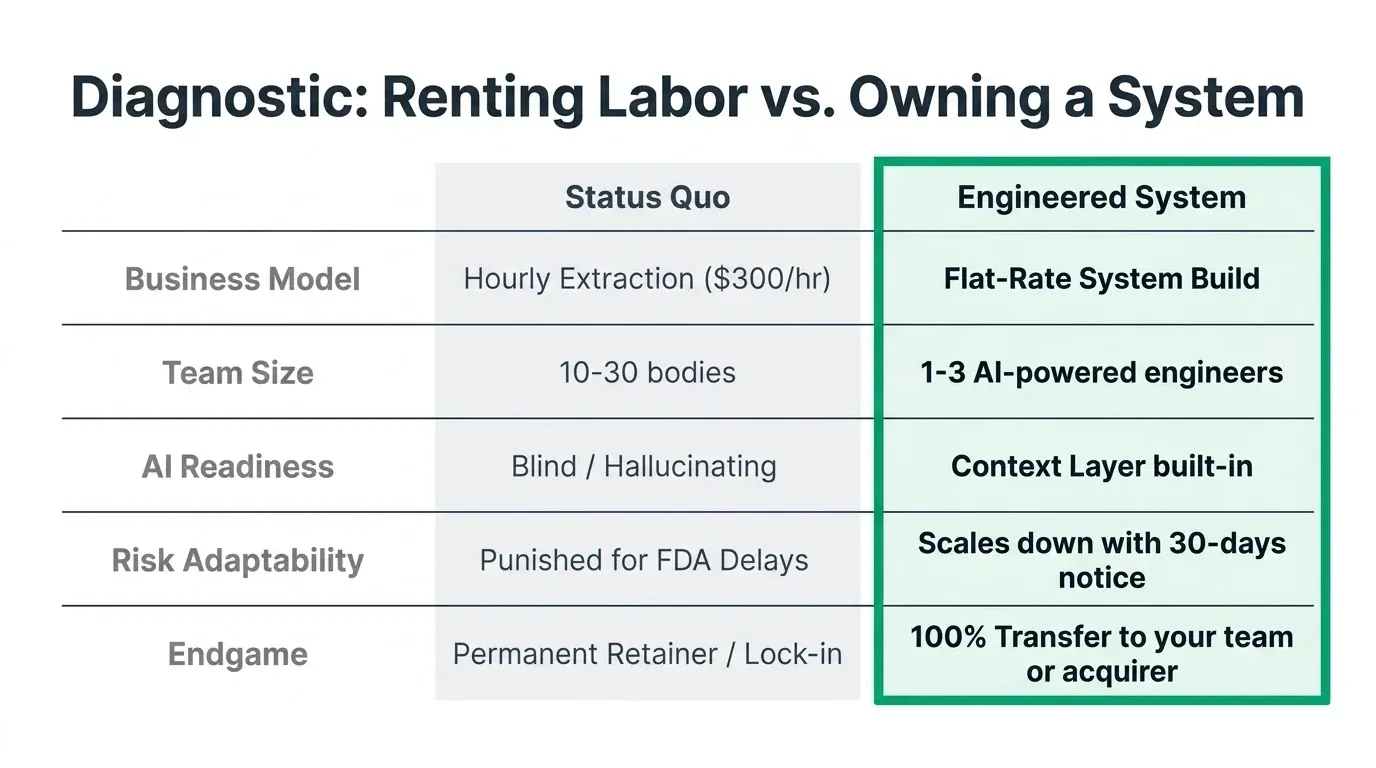
Typical staffing is one to three of our engineers. Flat monthly rate, set at scoping.
AI-ready data on your side
Your CEO wants a Snowflake Cortex or Databricks Genie chatbot included in the launch-readiness deck. Fine. Here’s what nobody is telling them.
When MIT’s NLP group tested leading text-to-SQL models against the Spider 2.0 benchmark of real enterprise databases, accuracy dropped from over 85% on academic benchmarks to under 20% on real warehouses. The model wasn’t broken. The proble was that the data underneath it had no context. Commercial pharma data is the worst version of this. Your warehouse has 150 tables. Half are deprecated. The right join between specialty pharmacy and claims depends on a payer hierarchy that lives in someone’s head. EQ_TRX, NRx, formulary, ALPD, SOB, 852, 867. The AI doesn’t know any of it. It guesses, and it’s confidently wrong. Your CEO sees it, loses faith, and your budget gets cut next quarter.
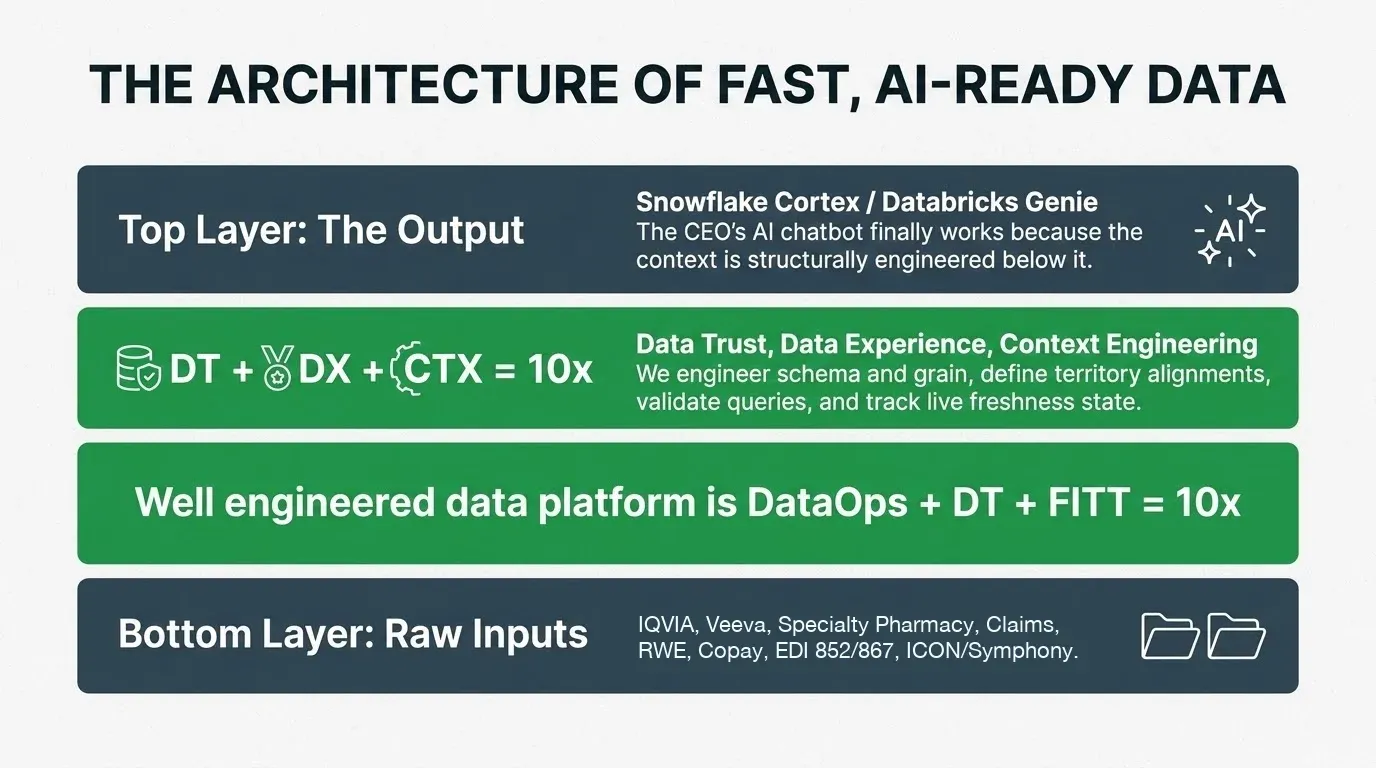
We engineer the context layer your AI tools need. Schema and grain. Business definitions for equalized prescriptions, territory alignment, and payer hierarchy. Validated example queries. Live freshness state on every IQVIA or ICON/Symphony refresh.
We’re building this layer for a major pharma on Snowflake Cortex and Databricks Genie right now, covering specialty pharmacy and claims data for a recent launch. We work with the data you have: IQVIA, ICON/Symphony, Veeva, specialty pharmacy, medical claims, NPP, RWE, copay, EDI 852/867. No learning curve. Our Commercial Data and Analytics Platform for Pharma is built for this.
The framework is DT + DX + CTX = 10x. Data Trust + Data Experience + Context Engineering. Published. Open.
Your analysts get their week back
Picture your senior analyst on Monday morning. The brand team wants a revised forecast by Wednesday. Before she can touch the model, she reconciles last week’s IQVIA refresh against claims, chases down why a payer name came through three different ways, and rebuilds a territory roll-up because someone changed the alignment file on Friday. By Wednesday, she’s done the cleanup. The forecast slips to Friday.
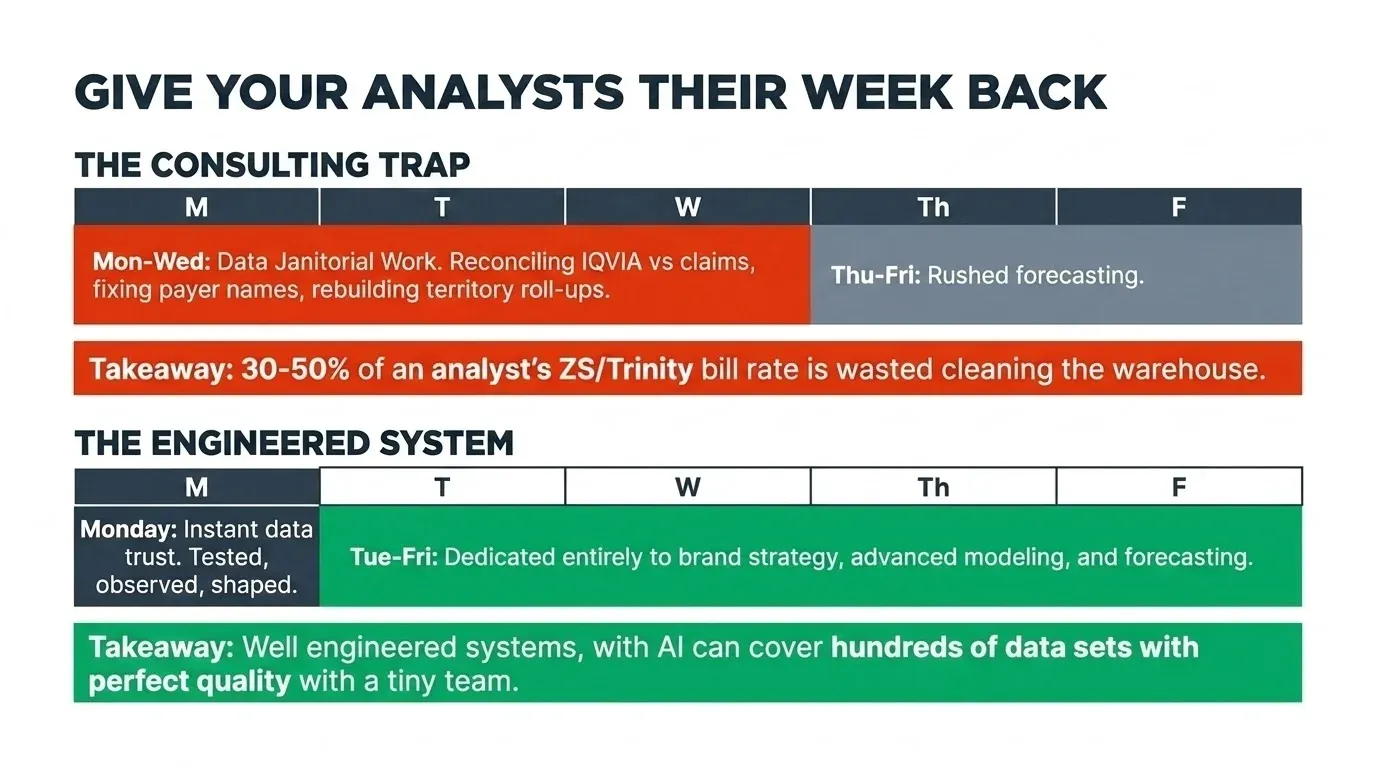
That’s 30 to 50 percent of your analyst bench dedicated to data janitorial work. At your fully loaded ZS or Trinity bill rate, that’s the line item that should fund the brand instead of cleaning the warehouse.
When the data below is tested, observed, and shaped to answer the questions analysts are asked, the time comes back. At Celgene, 10 to 12 analysts covered hundreds of datasets without missed SLAs because the engineering layer held up.
Engineer your way to cost savings and a scalable future
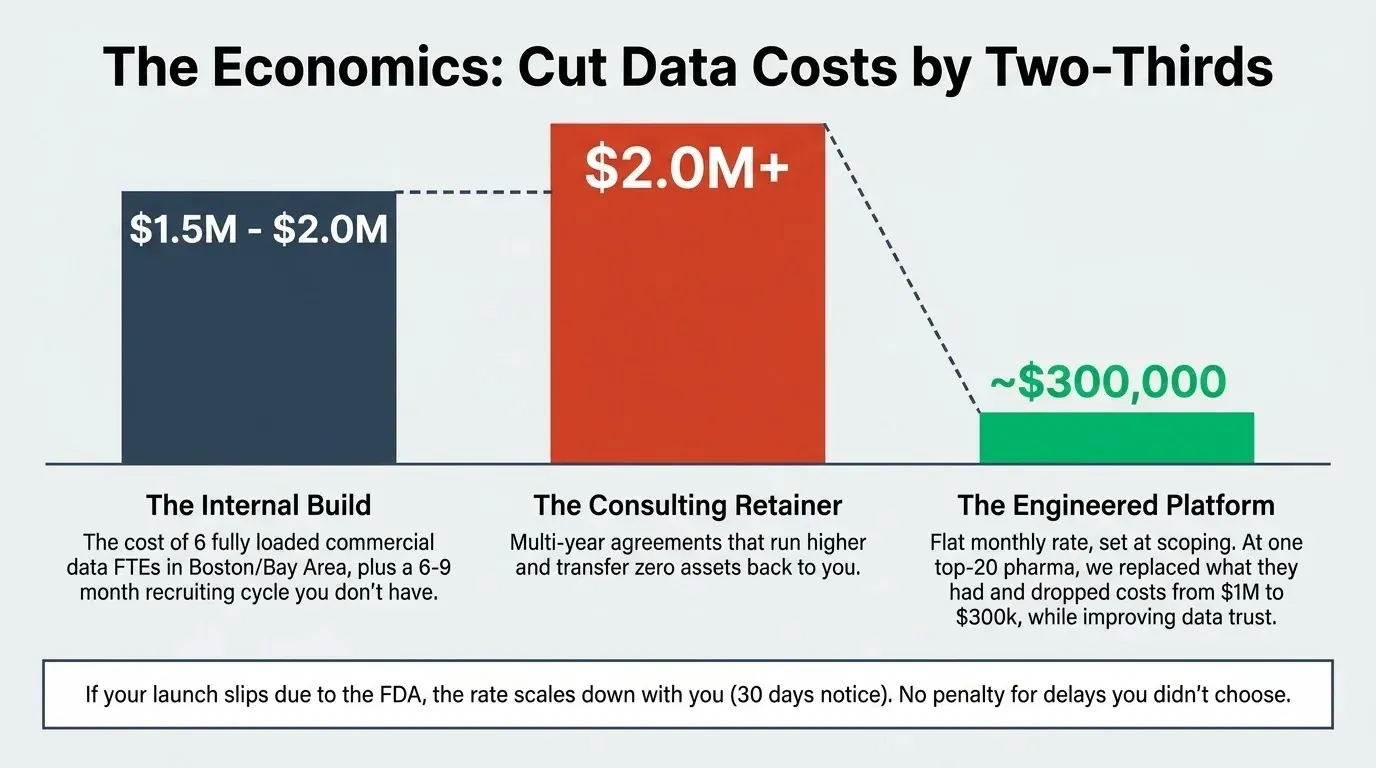
At one pharma company, we replaced what they had and cut their data costs by two-thirds. From $1 million a year to $300,000. Same people getting the answers they needed. Better answers, because trust went up.
Flat monthly rate, set at scoping. We work in your cloud. The code is in your repo.
The CFO comparison: six commercial data FTEs fully loaded in Boston or the Bay Area runs $1.5M to $2M a year, plus a six to nine-month recruiting cycle you don’t have. A multi-year analytics consulting agreement runs higher and never transfers anything back to you. We come in under both numbers. The platform belongs to you when we leave.
If your launch slips, the rate scales down with you. Thirty days’ notice. No penalty for an FDA delay you didn’t choose.
Trust, speed, value, and yours
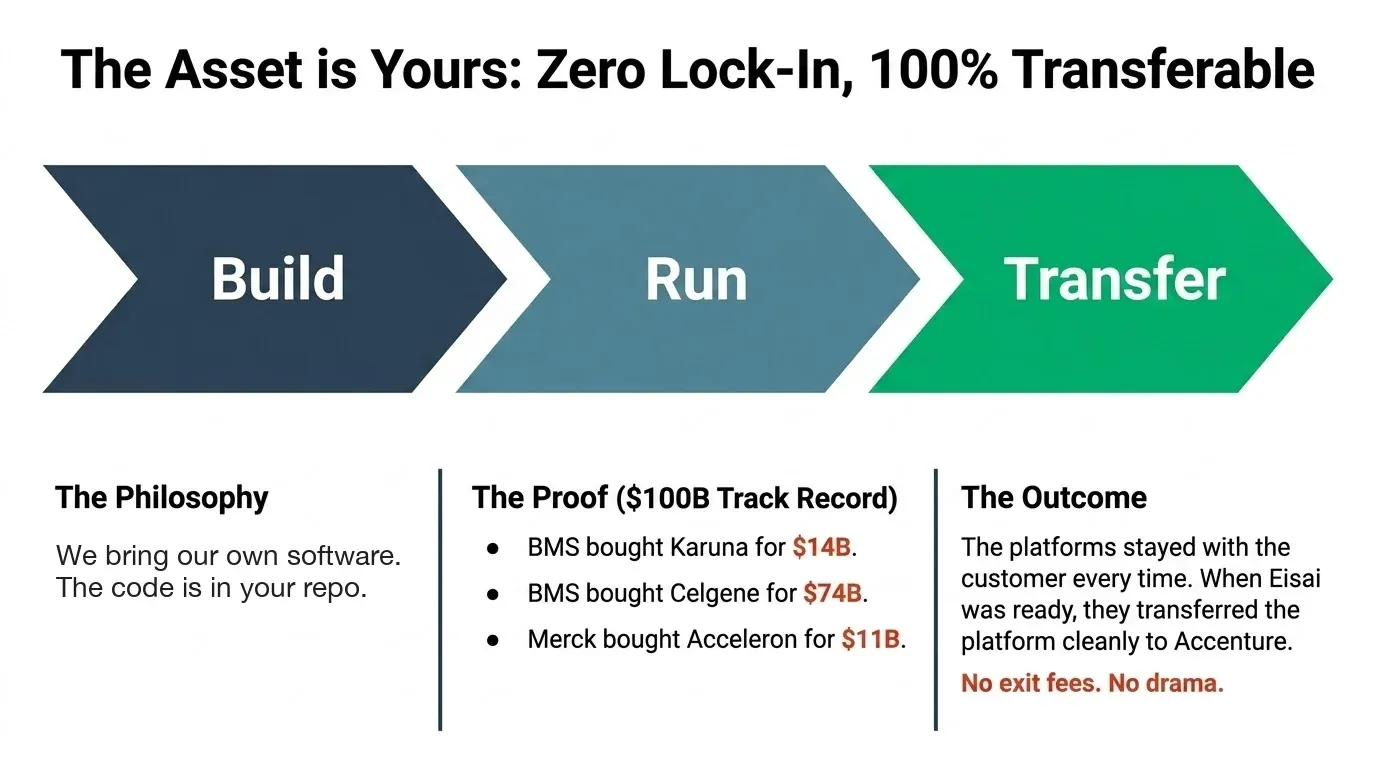
Three of our customers were acquired by top-five pharma for $100 billion combined. BMS bought Karuna for $14 billion. BMS bought Celgene for $74 billion. Merck bought Acceleron for $11 billion. The platforms stayed with the customer every time. Eisai transferred the platform to Accenture cleanly when they were ready.
41 people from five companies have worked safely on the same data for seven years. Still in production. 253,485 lines of code. 594 automated tests. TestGen catches errors before they reach production.
Field reporting ready six months before launch, every time. First star schema in four weeks. First AI context layer in six. Full launch report set six months before go-live. The drug launch case study walks through one end-to-end.
The platform sits in your cloud. The code is in your repo. We transfer when you want. To your team. To Accenture. To your offshore center. No lock-in. No exit fees. No drama.
Every dollar you don’t spend on data consulting is runway
We’re a data engineering services company backed by an open source product. We send pharma data engineers, not generic consultants. We bring our own software and we work in your cloud.
If you want to read first, start with the $100 billion acquisition story or the drug launch case study. They cover the work in more detail than this post can.
If you want to talk, we can have two meetings to see if we’re a good fit. First meeting, 30 minutes. You describe the launch, the team, the data sources, the timeline, and the AI pressure from above. We tell you whether we’re a fit. If we’re not, we say so and recommend who is. Second meeting, 60 minutes. We walk through one of your data sources end to end on your screen. We show what testing, observability, and context engineering look like on it. We show what your AI tool would answer if it were pointed at the right shape of data.
After that, if you want, there’s a paid two-week scoping engagement. You walk away with a working context layer over one of your data sources, an AI-readiness scorecard, and a sized proposal. If you don’t move forward, the work is yours.
Every $700,000 you don’t spend on data consulting is runway. The company that survives the next two years is the one that wasn’t running a fat back-office to begin with.
If your launch is 12 to 24 months out and you want to know what your data and AI bill could look like at one-third the run rate, book the 30-minute call. The math is the conversation.



