
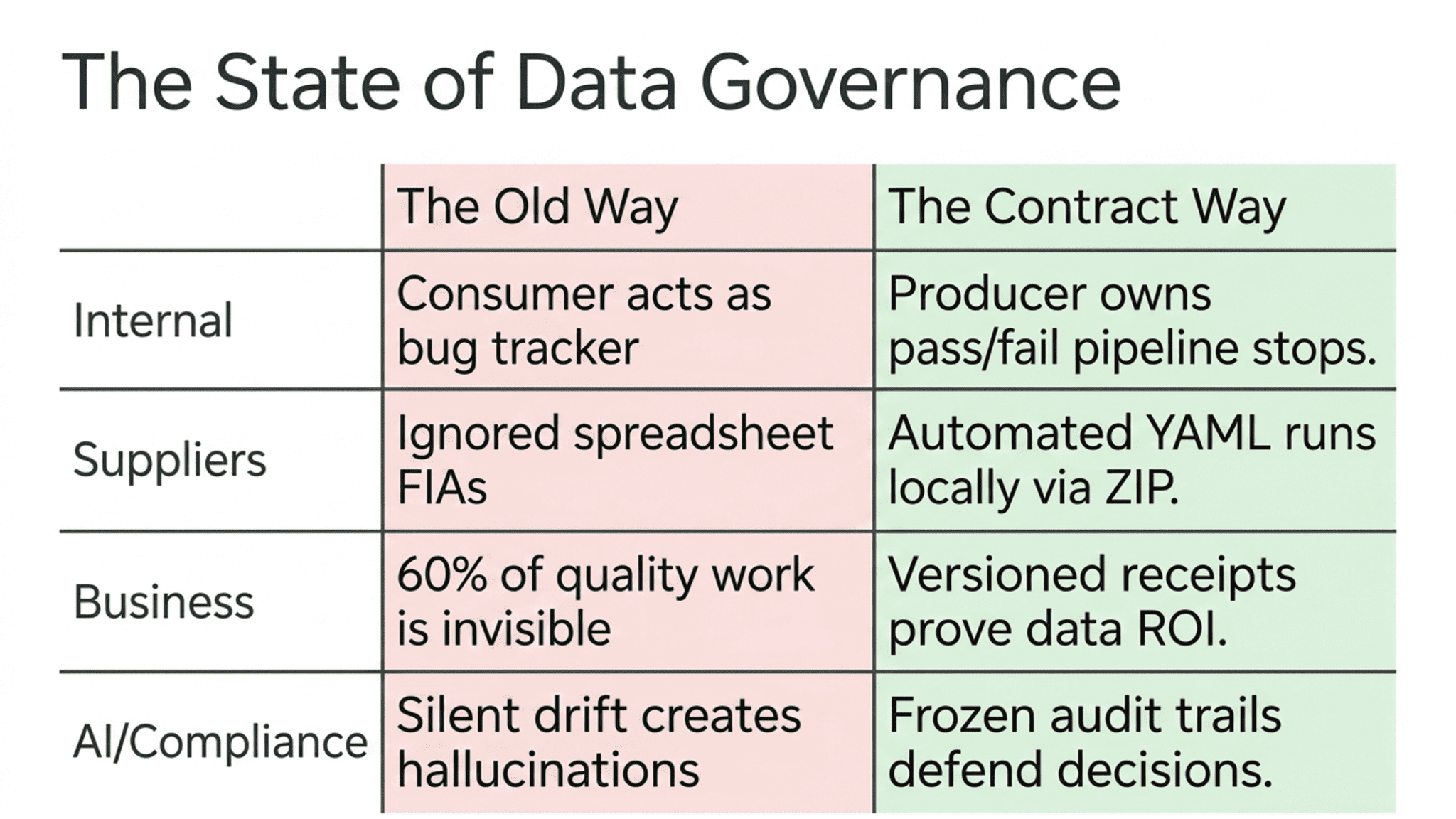
You engineer data. Others bet their decisions on it. Then something breaks, and suddenly everyone is in a blame session. With a real data contract, that meeting lasts five minutes. Without one, it drags on for an hour, and you still walk out losing.
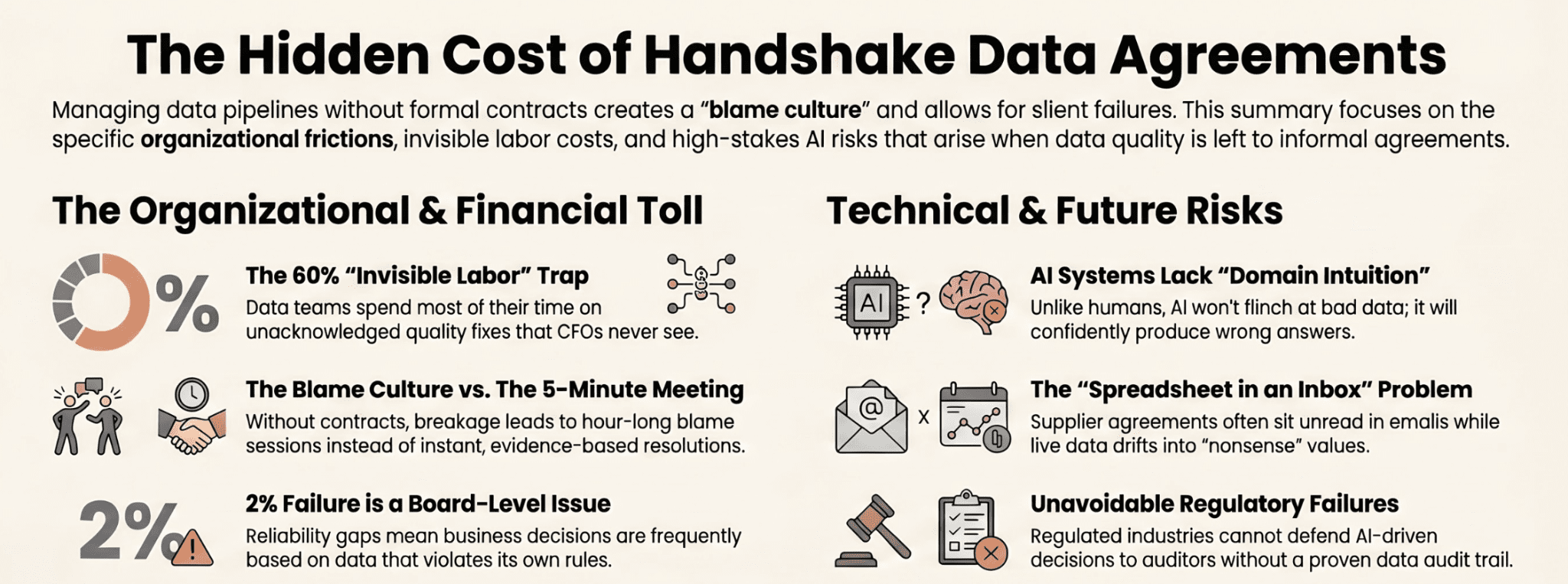
A contract is a promise with consequences.
A data contract is not documentation. It is not a Confluence page. It is not a spreadsheet someone sent you in an onboarding email.
A contract is a promise with consequences. Someone commits to delivering data in a specific shape, at a specific cadence, within specific bounds. If they don’t, something happens—a pipeline stop—an alert fires. A file gets rejected. The receiving team doesn’t spend their Tuesday chasing ghosts.
The consequence is what makes it a contract. Without teeth, it’s a decoration. The data tests are the teeth.
That’s the whole idea. A written, versioned agreement about what a dataset should look like, paired with tests that prove whether it currently meets that agreement. Column types, null rates, row counts, value ranges, freshness, the whole picture. It lives as a YAML file, or in a tool like TestGen, or both. What matters is that it’s real, testable, and dated.
One more thing to get right up front. A contract only works if the person on the other end can actually run it. If your supplier has to buy a SaaS license to comply with your contract, they won’t. If your downstream team has to file a procurement request to check their input, they won’t. The contract must be accompanied by a tool that the other party can install and run without signing anything. We’ll come back to this.
Here is why you want one.
Reason 1: Prove your own output is clean before it goes out the door
You’re exporting five tables and three hundred columns to a partner on Friday afternoon. You’re ninety percent sure it’s fine. Ninety percent is not what you want to bet your Monday morning on.
With a contract, you set the terms once. Then you add a test node at the end of your pipeline that runs the contract against the tables before the export fires. If the data doesn’t match, the export doesn’t ship. You get a green stamp before you press send.
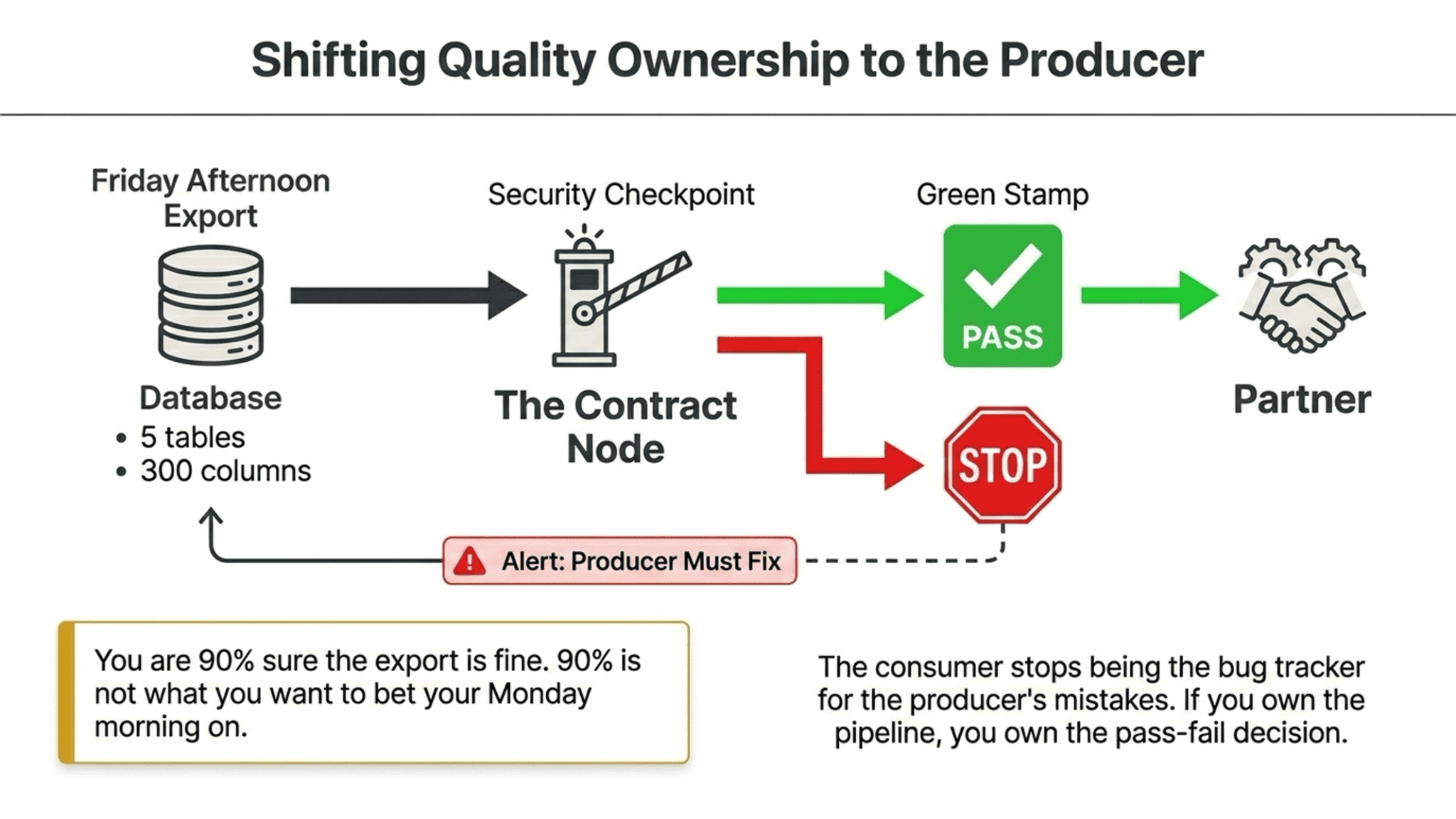
The contract is a structural shift worth naming. Quality ownership moves to the producer, where it belongs. The consumer stops being the bug tracker for the producer’s mistakes. If you own the pipeline, you own the contract, and the contract owns the pass-fail decision.
You can also hand the contract to the receiving team as a spec sheet. They know exactly what they’re getting. When their BI developer asks, “Are the order IDs always non-null?” you point at the contract and say, “Yes, and here’s the test that proves it ran green last night.”
Reason 2: Hold your suppliers to what they promised
The other side of the same coin. You receive data from a vendor every week. The vendor sent you a file interchange agreement when you signed the contract. That FIA is a spreadsheet sitting in someone’s inbox. Nobody has looked at it in eight months. The vendor’s data has drifted in three different ways, and nobody noticed until a dashboard started showing nonsense.
Take that FIA and convert it to a YAML contract. Claude Code can do this in about two minutes. Import it into TestGen. Now every new delivery from that vendor runs against the contract automatically. When something drifts, you get a line-item report showing exactly which term failed, and you send that to the vendor. The conversation goes from “your data seems off” to “row 47 of your schedule promised a non-null ship_date and twelve percent of rows are null this week.”
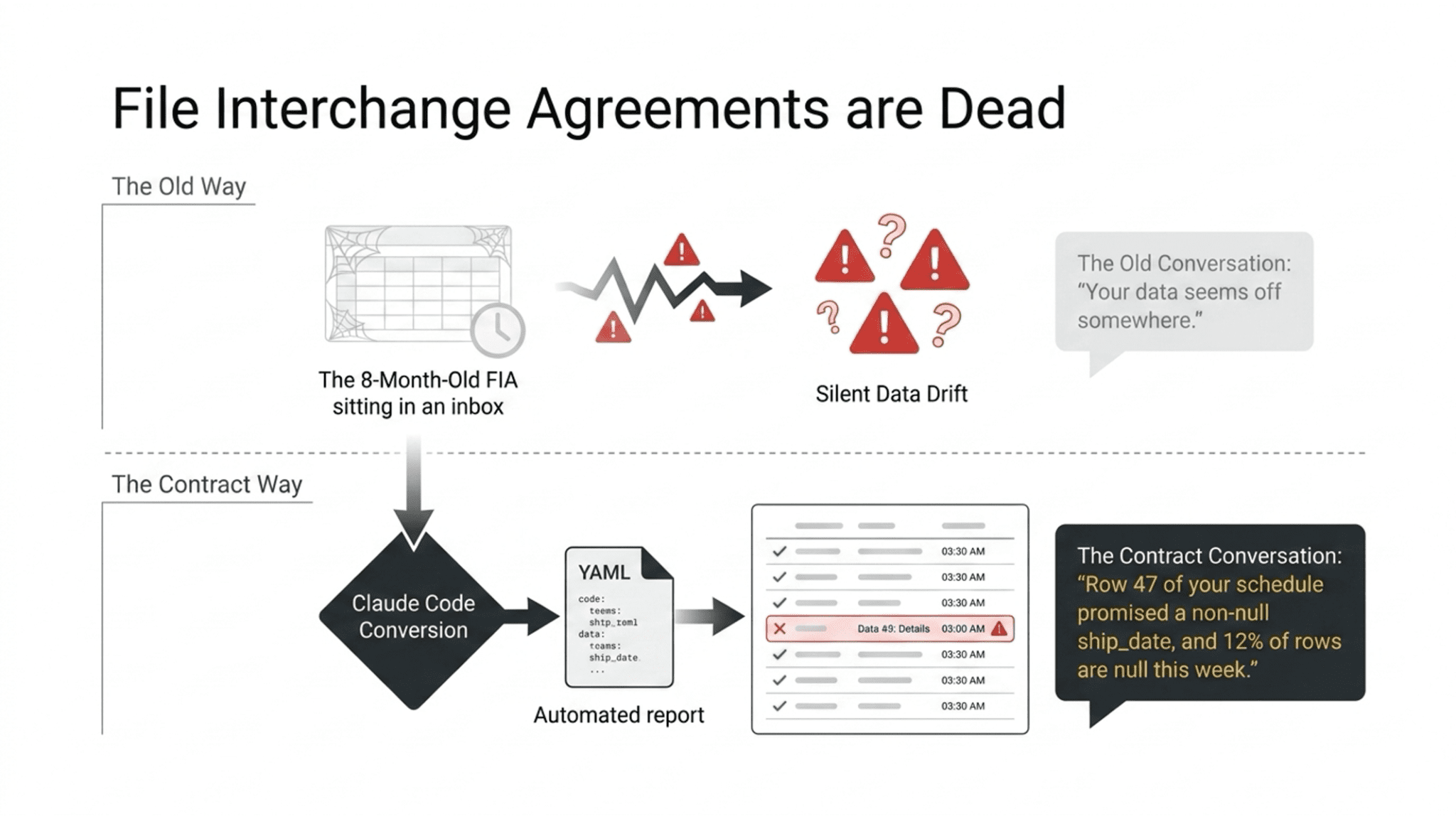
Now here’s the part that makes this actually work. TestGen is open source. Free. No account required. So the move is not “please adopt our data quality platform.” The move is this: you send your supplier a ZIP file containing the tool and a YAML contract, and tell them to run it before they ship the next load. They install it on their machine or their build server in five minutes. They run it. It passes, or it fails. If it fails, they fix the data. You never see a broken file.
That is the unlock. Most data quality tools are SaaS. You can’t hand a SaaS product to a supplier and tell them to comply. They won’t sign up, they won’t expose their data to your vendor’s cloud, and procurement won’t let them. Open source is how the contract actually travels. It’s how the other side of the handoff gets to participate without having to negotiate a contract of their own.
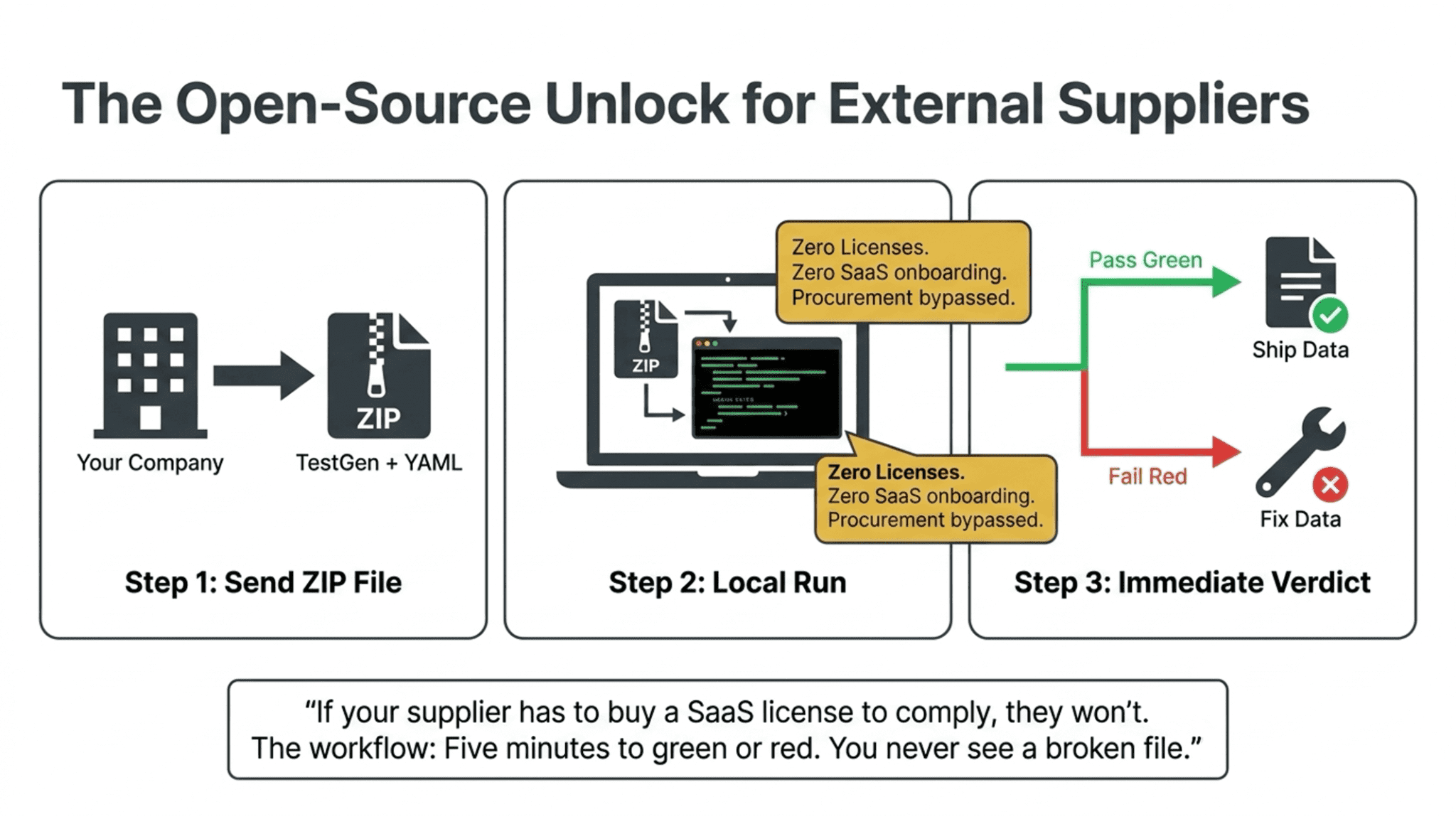
Our consulting team deals with data suppliers who routinely send us garbage. We’re handing them open-source TestGen, along with a contract, and telling them to run it before they ship to us. If it doesn’t pass, we don’t accept the file. That’s the whole workflow. Zero licenses. Zero onboarding. Five minutes to green or red.
Reason 3: Show the business what your data work is actually worth
This is the one nobody talks about, and it’s the layer of governance that gets your next round of headcount approved.
You spend sixty percent of your time on quality work that is invisible to the people who pay for it. You catch bad joins, you reject duplicate orders, you handle schema drift, you babysit the third-party feed that breaks every other Thursday. None of that shows up in a quarterly review. The CFO sees a dashboard and assumes it happened on its own.
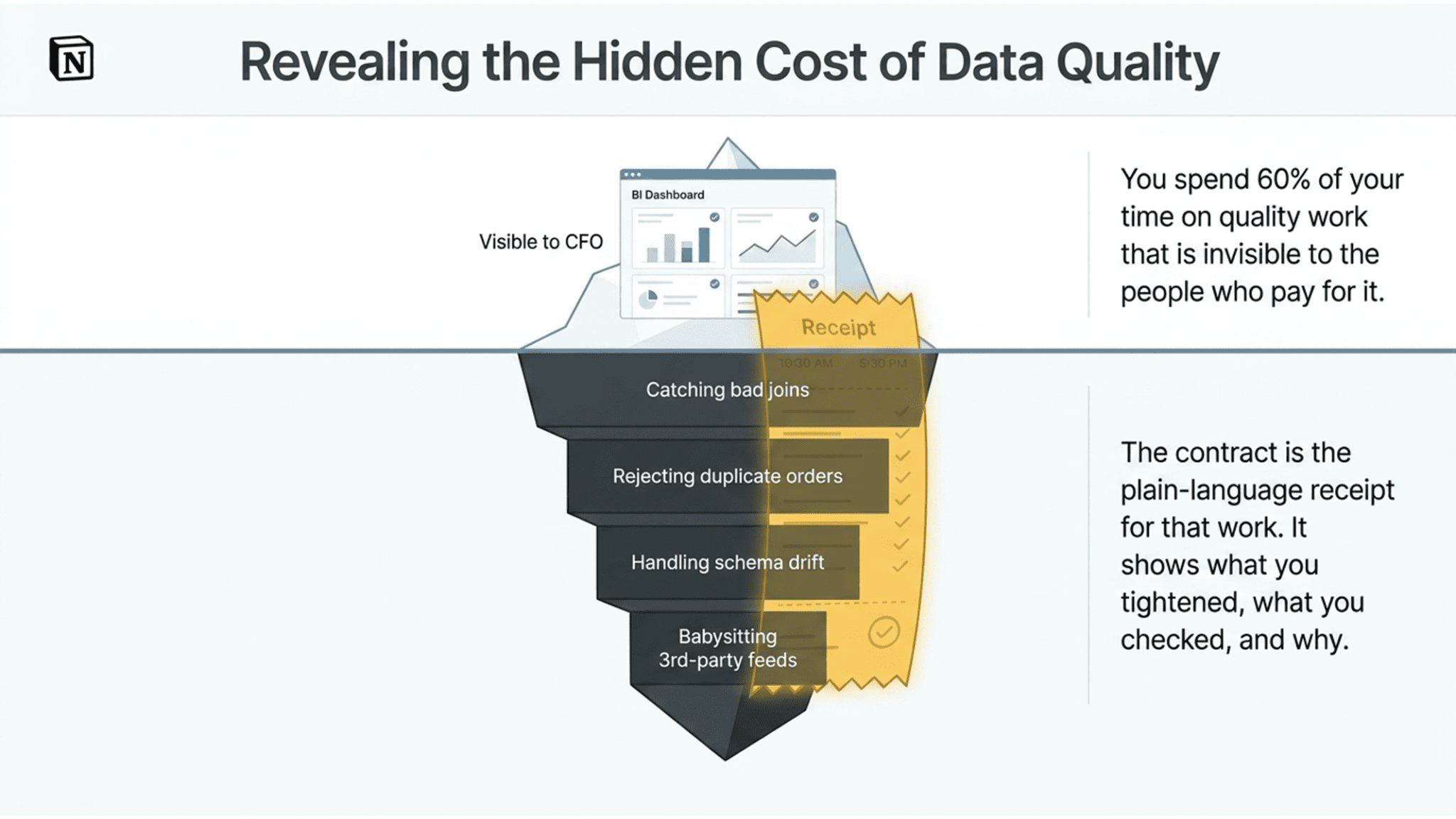
A contract is the receipt for that work. It lists every quality check. It shows when it ran. It shows pass/fail over time. The version history shows what you added, what you tightened, and why. When your data steward sits down with a business owner, the contract is the artifact they point at. Not your SQL. Not your test suite config. The contract, in plain language, with terms a business person can read.
Here’s the move that matters for anyone looking to advance this work. Engineering reports “our pipelines ran at 98% reliability this quarter.” The CFO hears that and says, “Fine, moving on.” But the same number means something different when you read it against the contract: two percent of the business decisions this quarter ran on data that broke its own stated rules. That’s not fine. That’s a board-level sentence. Contracts give you both readings from one source of truth, and the second reading is the one that gets budget approved.
Several teams using our software have told us flat out: they want a contract specifically to show that their work is valuable to an organization that governs by contract. They’re not wrong. If your company runs on written agreements everywhere else, it should run on written agreements for data, too.
Reason 4: Your AI systems will not survive without contracts
AI is the reason that will matter most over the next three years, and it’s the one most teams are not ready for.
When a human analyst gets bad data, they usually catch it. Something looks off. The number doesn’t match last quarter. The trend breaks in a way that doesn’t make sense. Humans have domain intuition, which is a safeguard against weird input.
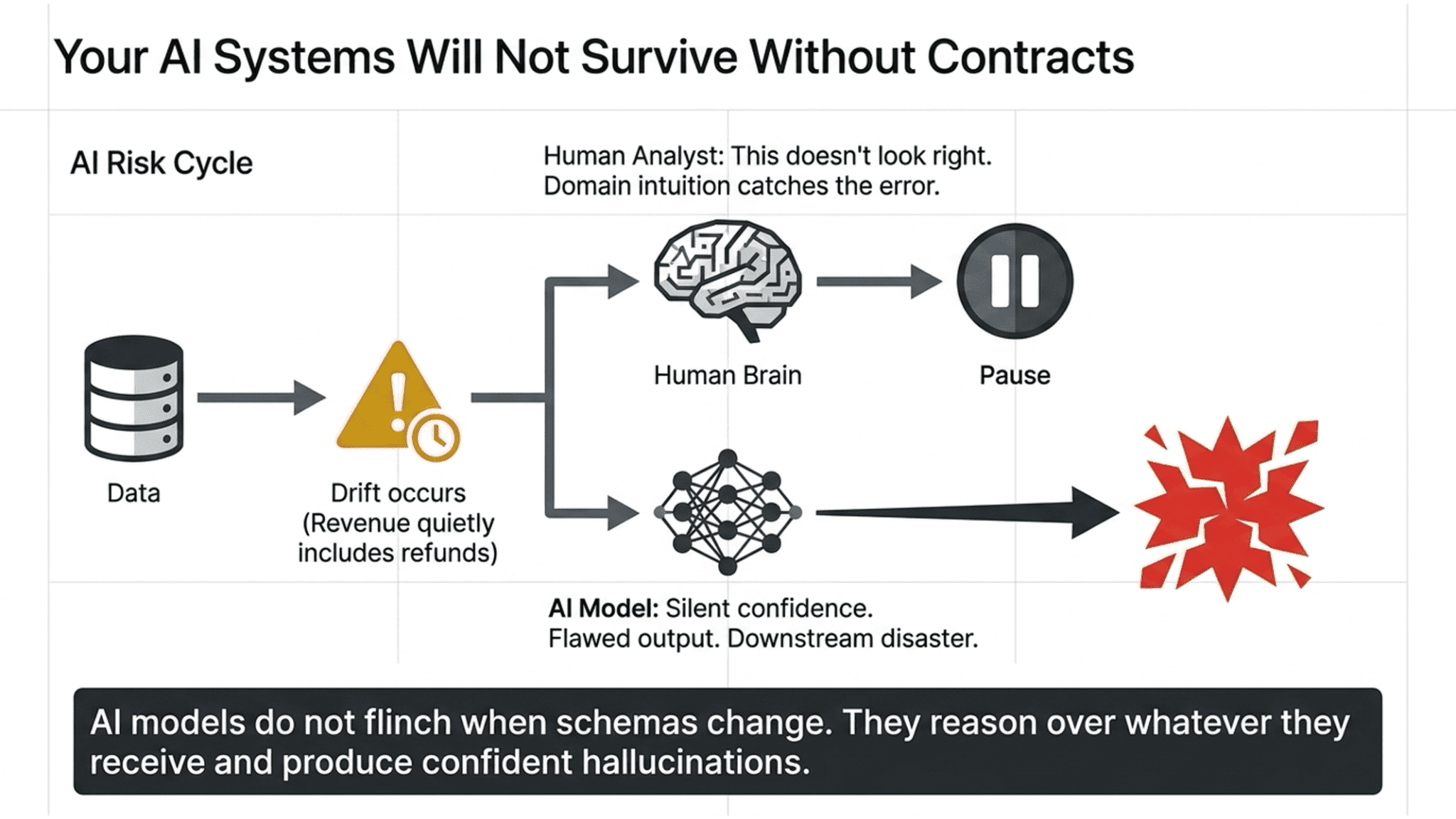
AI systems have no such safeguard. A model does not pause to say, “This doesn’t look right.” It reasons over whatever it receives, produces a confident answer, and the downstream workflow acts on it. An agent reading your customer table will not flinch when the schema changes. A forecasting model will not notice that the revenue column quietly started including refunds two weeks ago. The output will still look plausible. It just won’t be right.
Data contracts are no longer optional for any team putting AI into production. The contract is the upstream instrument that specifies the inputs the AI system can trust. Without one, you’re running models on data that could drift at any moment, and you will not know until a customer calls or a regulator shows up.
For a pharma company, a bank, an insurer, or anyone else running in a regulated environment, this is the whole ball game. You cannot defend an AI-driven decision to an auditor if you cannot prove that the data going in met a stated standard. The contract is that proof. It’s the audit trail for every automated decision your systems made last quarter.
If you’re a CDO thinking about where contract infrastructure fits on next year’s roadmap, this is the forcing function. Your AI spend is going up. Your tolerance for silent data failures is decreasing. Contracts are what sit between those two lines.
What a good contract actually looks like
Short answer: it follows a standard, it’s versioned, and it’s enforceable.
The open standard is the Open Data Contract Standard (ODCS), maintained by Bitol under the Linux Foundation AI & Data. It covers the fundamentals, schema, quality rules, servers, and compliance sections you need. Use it. Don’t invent your own format, because then you can’t share contracts with anyone who isn’t using your tool.
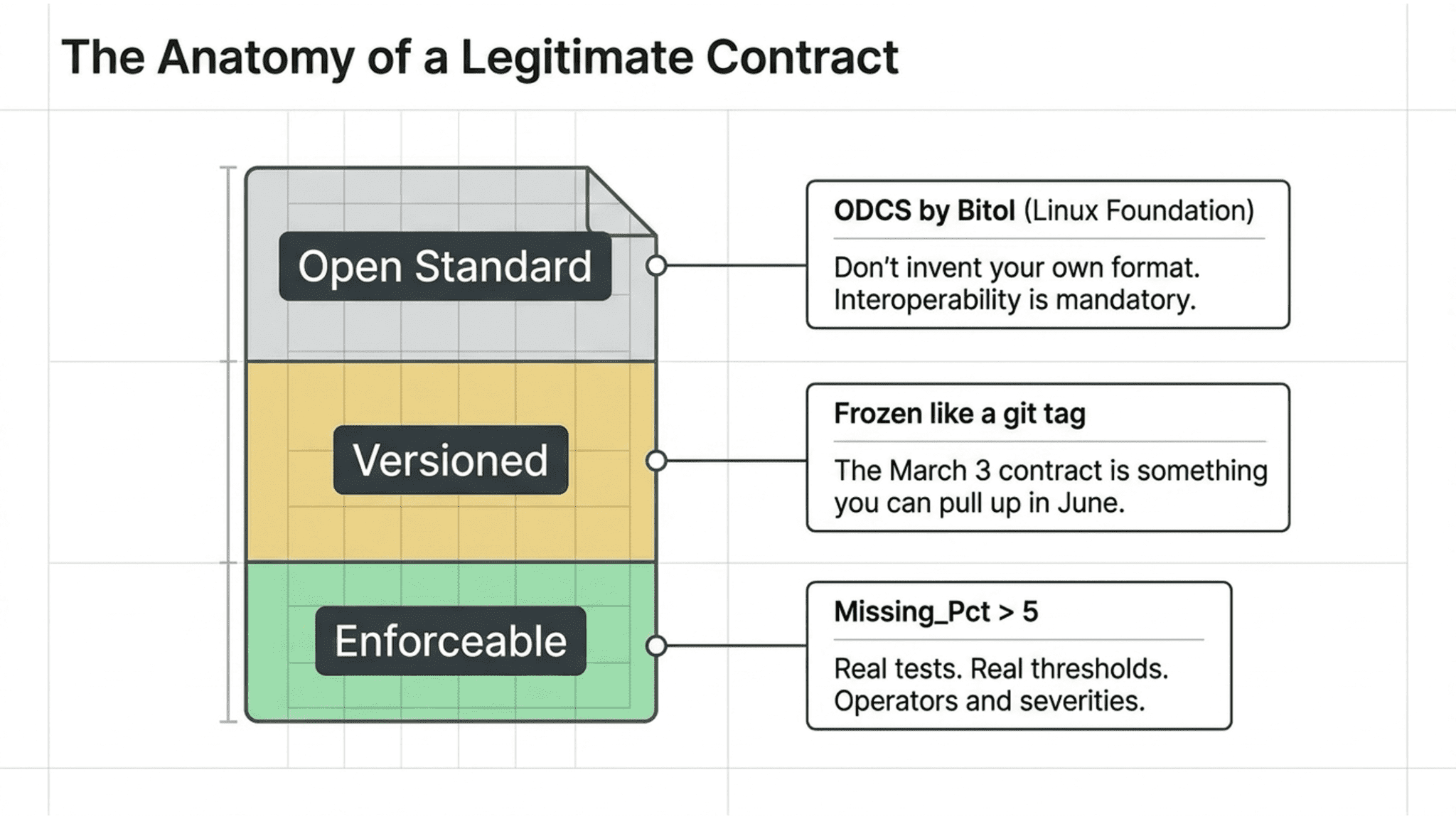
Versioned means every saved contract is a named, frozen point in time, like a git tag. The March 3 contract is something you can pull up in June when someone asks what we agreed to back then.
Enforceable means there are real tests behind every term. Not “the column should be clean.” A threshold. A metric. An operator. A severity. If Missing_Pct > 5, the test fails. That’s a term worth having.
How TestGen does this (arriving May 2026)
Data Contracts is a new feature arriving in TestGen across May and June of this year. Remember: TestGen is open source and free. You can run it yourself, hand it to a supplier, or install it in an airgapped environment. No license, no seat count, no SaaS signup. That’s the whole point: two paths, same destination.

Path one: You already have tests in TestGen. You group the relevant test suites, click New Contract, and TestGen builds the ODCS YAML for you and pairs it with a snapshot suite that freezes those tests at that version. From then on, you run the snapshot whenever you want to check compliance. You can export the YAML to share or export an XLSX file for an interchange agreement to hand to a partner.
Path two: You start with a supplier’s spec or an existing contract. You import the YAML (Claude can help you convert a spreadsheet into ODCS format), TestGen creates the tests, and you run them against the incoming data. Or, if you have no spec at all, you load the data into a table, let TestGen profile it, and generate a contract from the profiling results. The data itself writes the first draft of the contract.

Either way, the contract can be edited in the UI. Your data steward and the business owner can see it, comment on it, and agree on it without reading a line of SQL.
Want early access? Get in touch, and we’ll put you on the list.
Stop being the one who checks other people’s work
Here’s the cleanest way to use this, and it’s the move we’re betting on with our own suppliers.
You can install open-source TestGen on your side, point it at every delivery, run the contract, and catch the problems after they arrive. That works. It’s already better than what most teams do today.
But the better move is to stop being the one who checks. Hand the tool and the contract to the supplier. Tell them: here’s open-source TestGen; here’s the contract; you’ll have it running in 10 minutes. Run it before you ship. If it passes, ship. If it fails, fix it before you ship. Stop being a loser.
Now the burden lives where it belongs. The supplier is responsible for the quality of what they send. You stop playing goalie. The contract is the same either way, but the work of checking moves upstream to the only place it can actually prevent the problem. That’s the whole shift. The reason it works is that TestGen is free and runs anywhere, so there’s no excuse and no friction on the other side.
Ten minutes to set up. Zero dollars. One yes-or-no answer before every delivery. If a supplier won’t do that, you’ve learned something important about the supplier.
Start with one contract.
Pick the export you’re most nervous about shipping, or the supplier who sends you the most garbage, or the AI pipeline that is one schema change away from embarrassing you. Write one contract. Run it for a month. Watch what happens to the conversations you have about that data.
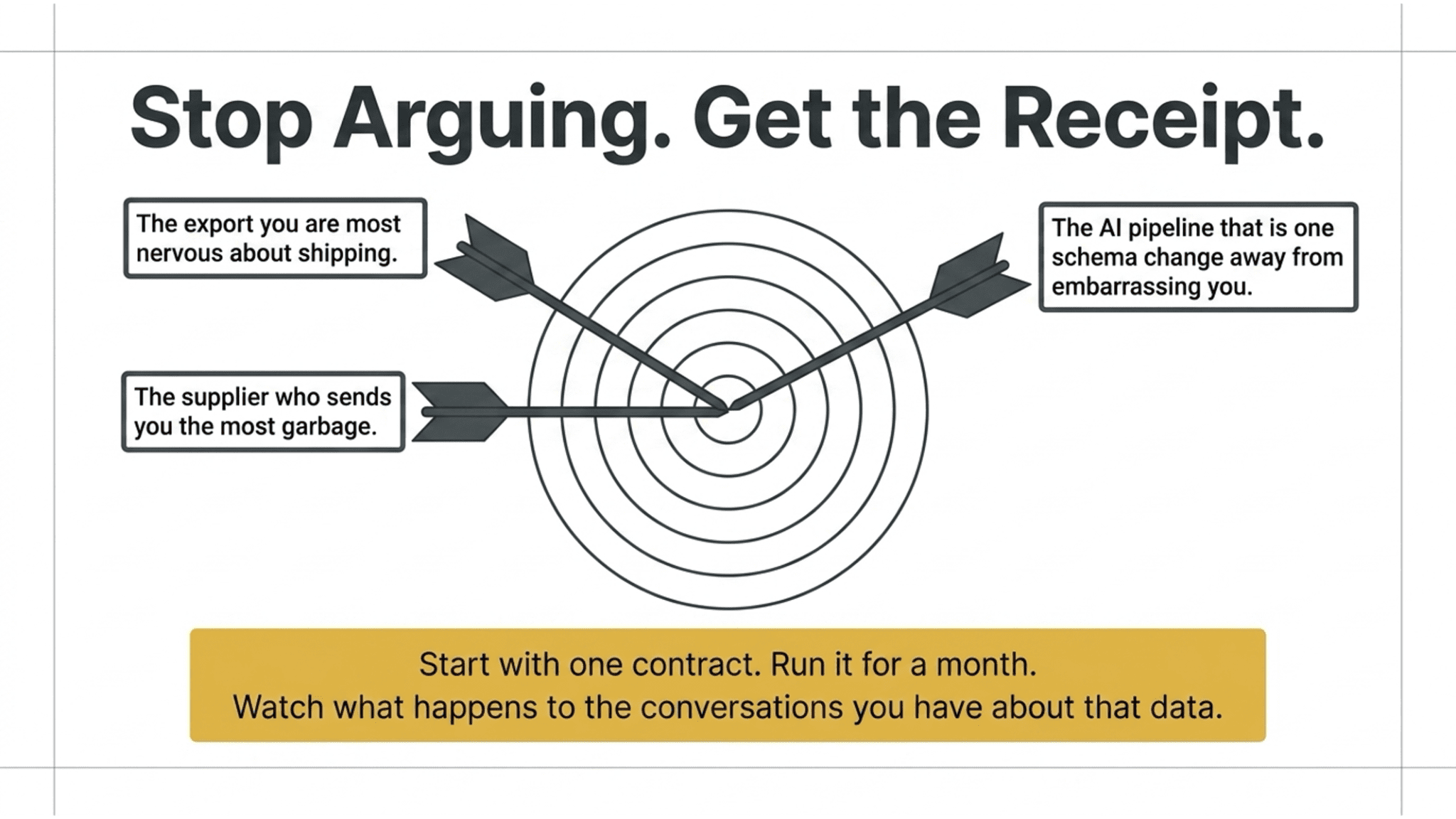
You’ll stop arguing about whose fault it was. You’ll have the open source receipt.







