
Last week’s webinar, presented by Christopher Bergh, CEO and Head Chef at DataKitchen, explored the impact of newly released open-source software tools on data operations and analytics. The event was an informative session that dove deep into the functionalities and applications of these tools within the broader scope of DataOps.
Christopher Bergh began by discussing the motivation behind creating and open-source these tools. He highlighted that the proliferation of data and complex toolchains often leads to inefficiencies and errors within data teams. These challenges stem from what he called the “little box problem,” where numerous discrete components in cloud environments like Azure or Amazon and team structures lead to siloed operations. This fragmentation can often result in data errors, delays, and increased operational burdens that are painfully visible to customers.
The philosophy of DataOps, as Bergh explained, is fundamentally about shifting focus from immediate, day-one production pressures to a more strategic view of data operations that emphasizes continuous improvement and error reduction. He emphasized that the key benefits of adopting DataOps practices include reducing errors in production, increasing the rate at which modifications can be implemented, and enhancing overall productivity and trust within data teams.
Central to the webinar was a detailed exploration of DataOps observability and testing tools that DataKitchen has developed. These tools, now open-sourced, are designed to provide detailed oversight and operational checks throughout the data lifecycle. Bergh provided a walkthrough of the DataOps TestGen and DataOps Observability tools. He demonstrated their capabilities in real-time data and data tools monitoring.
He explained how these tools integrate seamlessly with existing databases and infrastructure, offering a layer of intelligence and automation that can significantly alleviate common data management pain points.
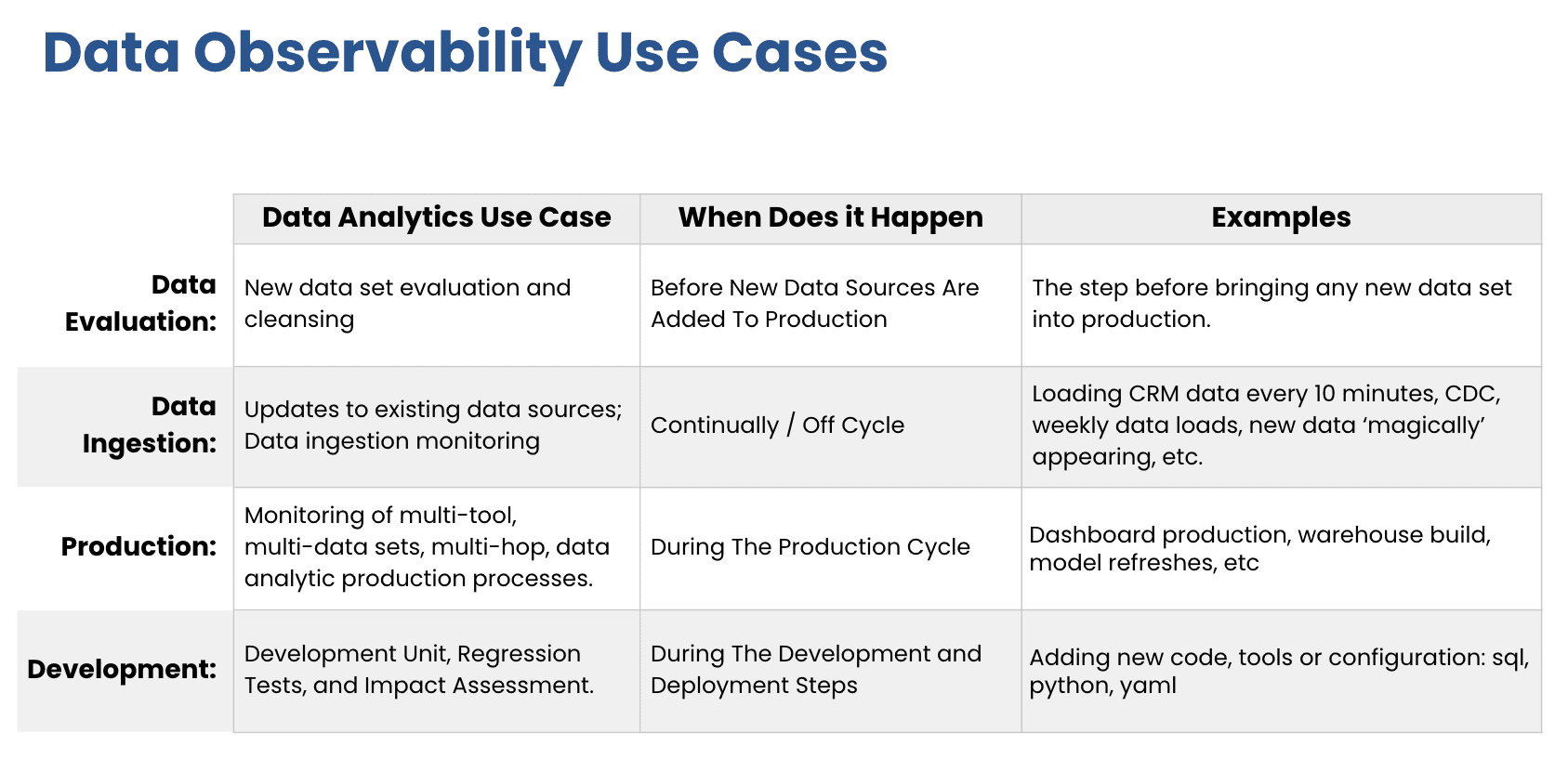
One of the more technical segments of the presentation involved demonstrating the actual use of these tools through a series of detailed examples. Bergh showed how data profiles could be automatically generated and tested against various operational characteristics to identify anomalies quickly. He also discussed how these tools could be used in various real-world scenarios, such as integrating new data sources, monitoring ongoing data transformations, and ensuring the accuracy of data outputs in analytical dashboards.
Throughout the session, Bergh emphasized the importance of making these tools open source. He argued that open source is not just about offering these tools for free but is part of a broader strategy to foster a community around robust DataOps practices. By making these tools accessible, DataKitchen hopes to encourage a bottom-up adoption of DataOps methodologies, leading to more sustainable and error-free data management practices across the industry.
The webinar concluded with a Q&A session where Bergh addressed specific technical questions from the audience, providing deeper insights into the configuration and scalability of the tools. He also discussed future enhancements and the company’s roadmap for supporting the growing DataOps community.
The webinar provided a comprehensive overview of DataKitchen’s new open-source offerings and detailed how these tools can facilitate more effective data management practices. The discussion highlighted the potential of DataOps to transform data management from a reactive, error-prone process into a strategic, error-free engine driving business success.
TIP
You can watch the webinar and download the slides here.
Watch the webinar
Fill out the form to view the full on-demand session.



