Data Products Are a ‘How,’ Not a ‘What.’
When data team leaders hear “data products,” they immediately think of the stuff they produce: dashboards, datasets, models, and warehouses—but focusing on the ” what ” completely misses the massive shift that data products really represent. The truth is, data products aren’t about what you create, but ” how ” you build, maintain, and continually improve your data assets to deliver value to customers.
The Traditional Misconception
The current discussion around data products, as reflected in countless articles and even AI-generated definitions, tends to describe them as “reusable, trusted, and well-defined data assets—such as a dataset, metric layer, feature set, or dashboard—that is designed, built, and managed like a product.” This definition gets us halfway there, but it still emphasizes the artifact rather than the approach.

When we think about data products merely as components or deliverables, we fall into the same trap that has plagued data teams for decades: the project mindset. This perspective leads us to view our work as a series of discrete efforts with defined endpoints, budgets to meet, and boxes to check. However, this approach fundamentally misaligns with how modern organizations need to utilize data for a competitive advantage.
Understanding the Product Mindset
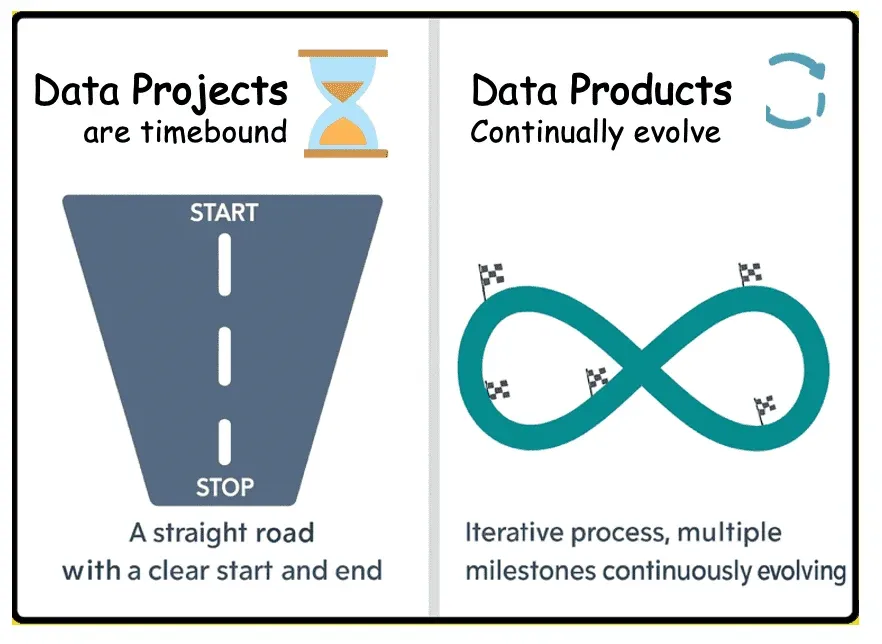
The shift from projects to products represents a fundamental change in how we approach data work. Unlike projects, which have a clear beginning and end, products are living entities that evolve continuously in response to user feedback and changing business needs. This isn’t just semantics—it’s a complete reimagining of how data teams operate.
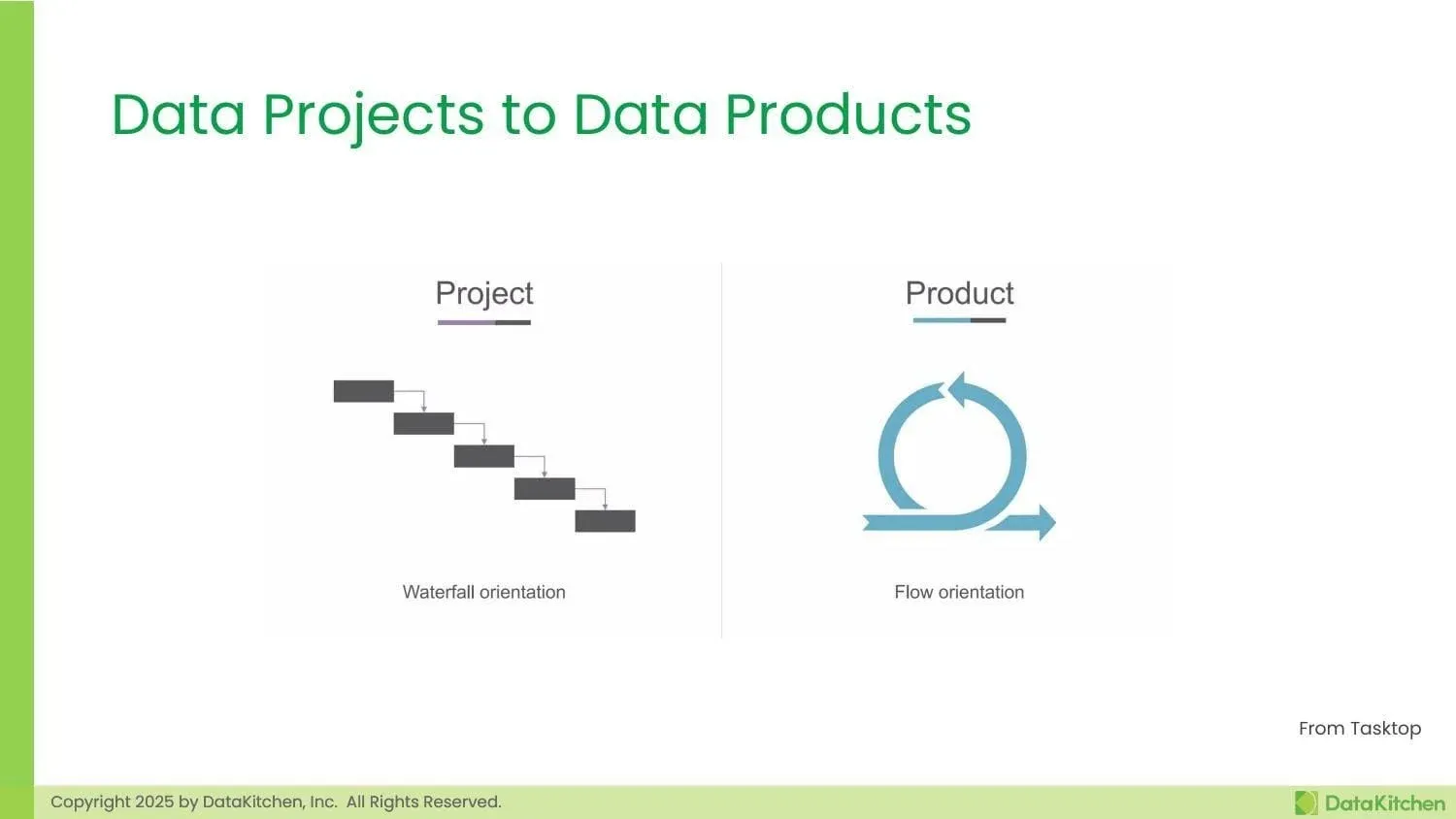
In the project world, we follow a waterfall orientation where work flows sequentially through stages. Teams are brought to specific projects, often creating silos and handoffs that slow down delivery and reduce quality. The focus becomes meeting deadlines and staying within budget, rather than delivering ongoing value to users.
IMPORTANT
The ‘thing’ that is in a data product could be any deliverable your team does. Defining the requisite components of data products is like counting angels on a pinhead.
In contrast, the product approach creates a continuous flow of value. Work is brought to stable teams who own their products end-to-end. These teams measure success not by whether they delivered on time, but by whether their users are satisfied and receiving value. The product mindset embraces iteration, learning, and continuous improvement.
The Software Engineering Parallel
This transformation in data isn’t happening in isolation. It mirrors a revolution that already transformed software engineering over the past two decades. Software teams have transitioned from DevOps to DataOps, from monolithic architectures to domain-driven design, and from project-based delivery to product-driven thinking. Now, these same principles are revolutionizing how we approach data and analytics.

Consider how software teams transformed their practices: Test-driven development evolved into data-driven testing. Observability became data observability. Event-driven architectures evolved into streaming and Kappa architectures. APIs transformed into data contracts. Each of these transitions represents not just a technology change, but a fundamental shift in thinking about how we deliver value.
Data Products Are Never ‘Done’
One of the most crucial aspects of the product mindset is understanding that data products are never “done.” This might feel uncomfortable for teams accustomed to celebrating project completions, but it’s actually liberating. Instead of rushing to meet an arbitrary deadline with a potentially suboptimal solution, teams can focus on iterative improvement, learning from each release to make the next one better.
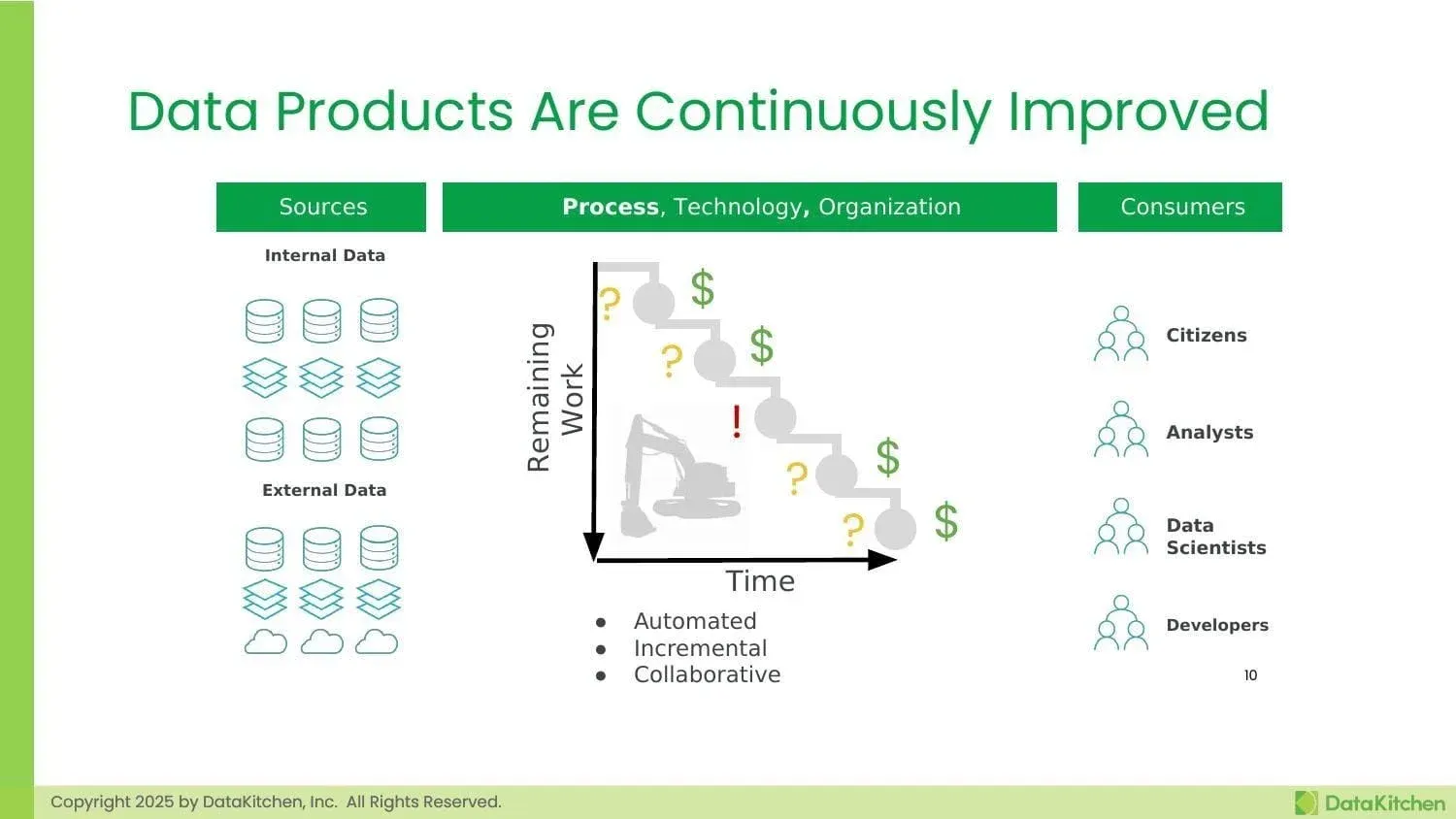
This continuous improvement approach yields measurable benefits: faster releases of analytics products, increased team learning, better insights, and ultimately, faster delivery of value from your data investments. Teams operating in this mode don’t just deliver once and move on—they establish feedback loops with their users, monitor usage patterns, and continuously refine their deliverables. With the traditional project approach, you may invest heavily up front with uncertain returns. With the product approach, you can start small, prove value quickly, and scale based on actual user adoption and feedback. Each iteration builds on the last, creating compound returns on your data investments.
Maximizing Data Team Flow
The ultimate goal of adopting a data product mindset is to maximize the flow of value to your customers. This isn’t just about moving faster—it’s about creating a sustainable and predictable delivery of high-quality data deliverables that users actually want and use.
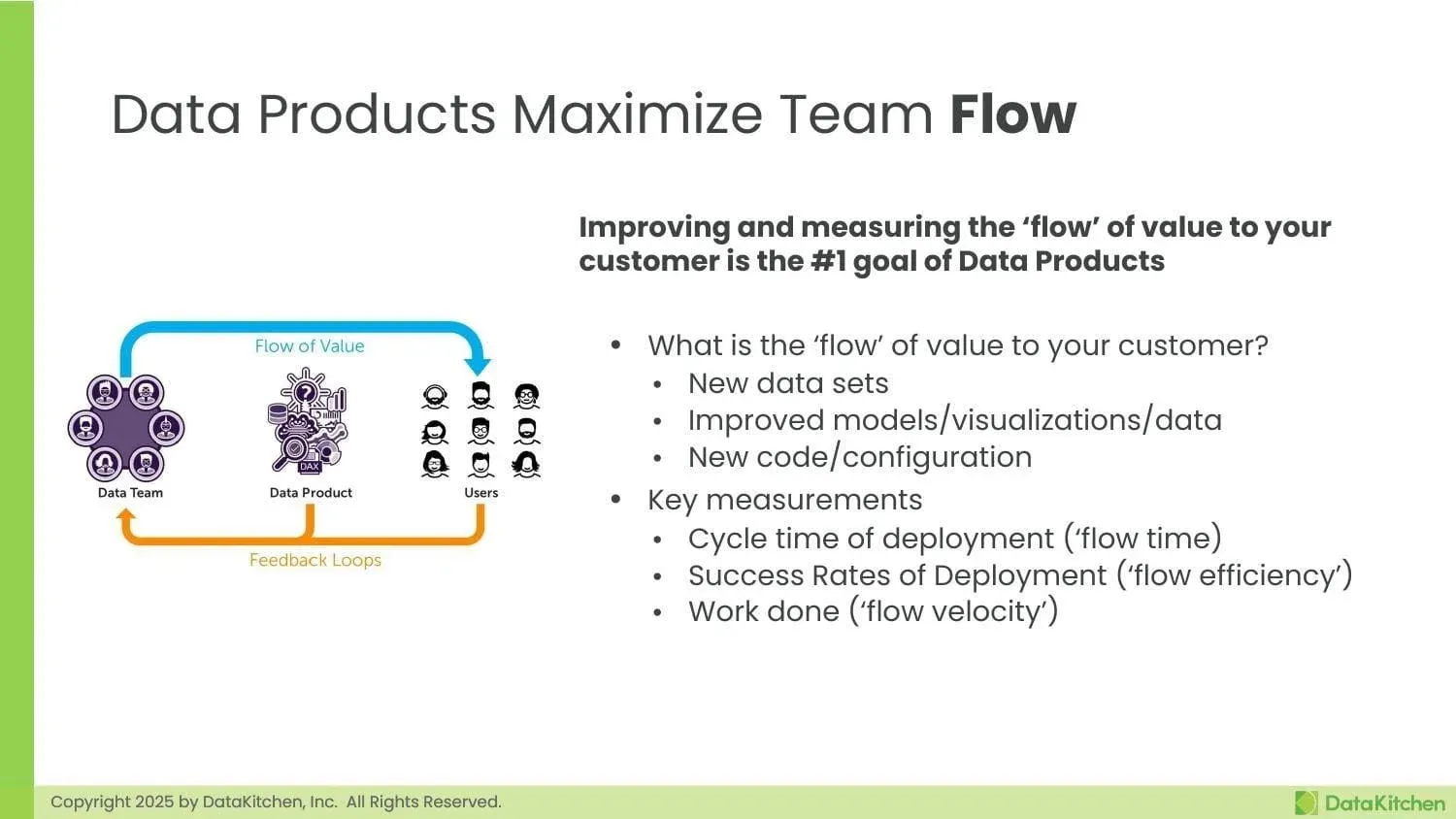
Flow encompasses several key dimensions. Flow time measures how quickly you can deliver new capabilities from idea to production. Flow efficiency tracks your success rates, ensuring that the work you do actually reaches users rather than getting stuck in approval processes or failing in production. Flow velocity measures the volume of valuable work completed, helping teams understand and improve their capacity over time.
These metrics matter because they directly correlate with business value. Reducing flow time means faster response to market changes. Improving flow efficiency means less wasted effort and more predictable delivery. Increasing flow velocity means more value delivered to users over time.
The Wrong Way: Labor-Intensive and Waterfall
Many organizations still approach data products incorrectly, treating them as large, monolithic efforts driven primarily by IT teams. This approach is characterized by heavy manual processes, long delivery cycles, and a disconnect between what’s built and what users actually need.
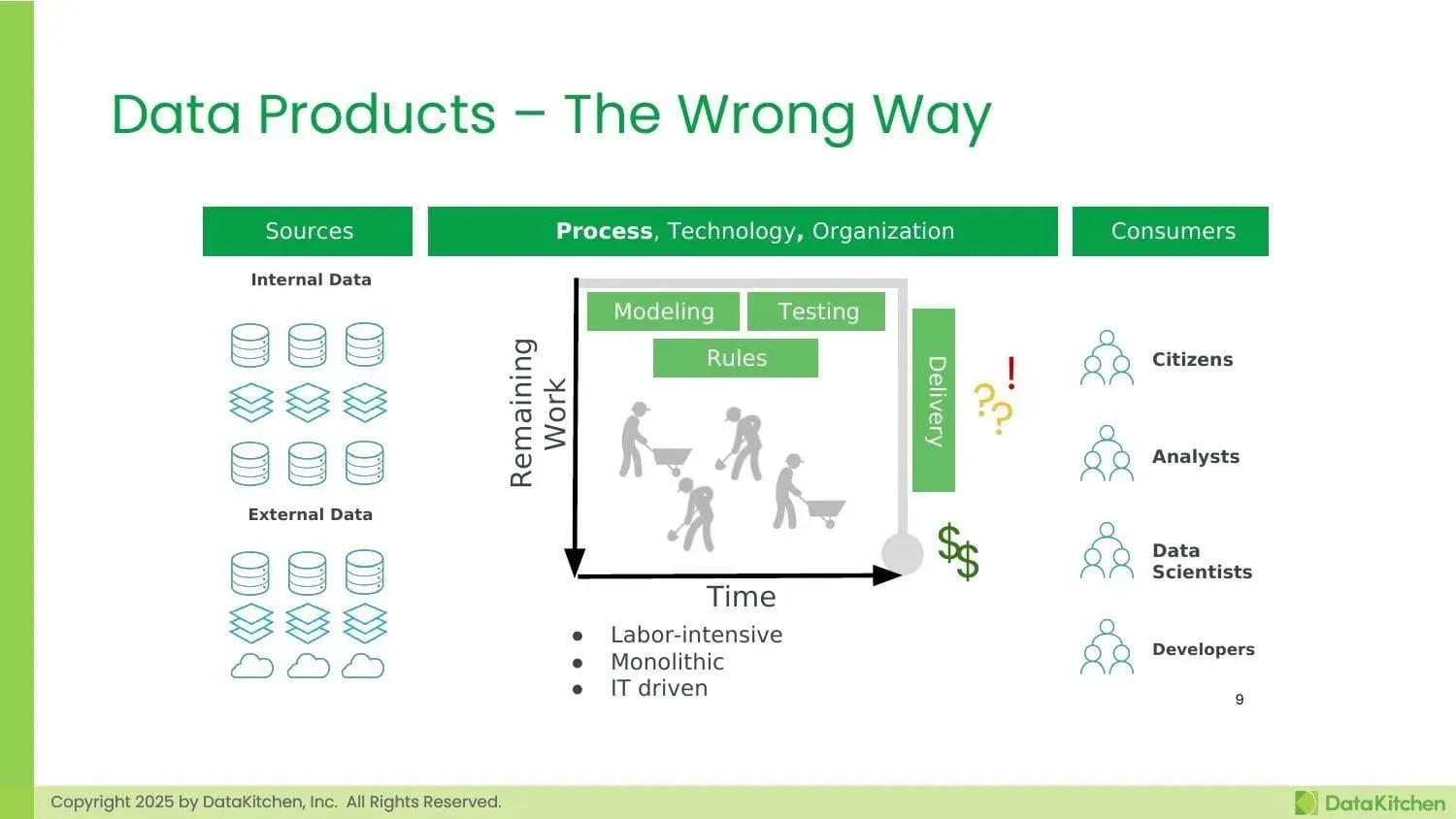
In this model, work flows slowly through various stages—modeling, rules definition, testing—with significant manual effort required at each step. The result is uncertainty about the timeline, cost, and whether the final product will actually meet user needs. Teams operating this way often find themselves in a reactive mode, constantly fighting fires rather than proactively improving their products. And many times, they miss the mark on what their users actually need.
IMPORTANT
“Our project was a success; we followed our SLDC and got an award.” Yeah, but did the customer use it? Did they find it valuable?
The Right Way: Automated, Incremental, and Collaborative
The product approach completely transforms this dynamic. Instead of significant, risky releases, teams deliver minor, incremental improvements continuously. Automation replaces manual processes wherever possible, freeing teams to focus on innovation rather than maintenance. Most importantly, the approach is inherently collaborative, bringing together data engineers, analysts, scientists, and business users to pursue shared outcomes.
This collaborative approach extends beyond just the data team. Product thinking requires close partnership with users, regular feedback sessions, and a willingness to pivot based on what you learn. It means treating your internal data consumers as valued customers whose satisfaction determines your success.
Making the Transition
Transitioning from a project to a product mindset isn’t just about adopting new tools or processes—it’s about fundamentally changing how your organization thinks about data and information. This shift requires leadership commitment, cultural change, and sometimes, investment in new capabilities.
Start by identifying a small, high-value use case where you can demonstrate the product approach. Choose something with engaged users who can provide regular feedback. Build a cross-functional team that can own the deliverable from end to end. Establish clear metrics for success based on user outcomes rather than delivery milestones.
As you begin delivering value through this approach, use your success to build momentum. Share your learnings broadly and celebrate not just releases, but also improvements in your flow metrics. Help other teams understand how the product mindset can enable them to deliver more value with less stress and uncertainty.
The DataOps Foundation
While the product mindset is primarily about approach rather than technology, having the proper technical foundation certainly helps. This includes capabilities for continuous integration and deployment, automated testing, monitoring and observability, as well as robust data governance. Embracing a DataOps approach, which applies agile and DevOps principles to data management, can significantly enhance this foundation. DataOps fosters collaboration between data engineers, data scientists, and other stakeholders, streamlining the entire data lifecycle from data ingestion to consumption. The goal is to create an environment where teams can safely and quickly iterate on their products without fear of breaking critical systems.
Measuring Success Differently
In the product world, success metrics shift dramatically from project metrics. Instead of asking “Did we deliver on time and on budget?” we ask “Are our users successful? Are they recommending our team to others?” This shift in metrics drives a shift in behavior, focusing teams on long-term value rather than short-term delivery.
Establish metrics that matter. This might include data quality scores or business-specific metrics, such as “time to insight” or “decisions influenced.” Make these metrics visible to your team and stakeholders, creating transparency around the value you deliver.
Your Path Forward with DataKitchen
Making this transformation from projects to products, from “what” to “how,” isn’t a journey you have to take alone. DataKitchen specializes in helping organizations adopt DataOps practices that enable the product mindset for data teams. Our consulting services can help you assess your current state, design your transformation roadmap, and build the capabilities you need to succeed.

Through our open-source tools and proven methodologies, including our FITT (Functional, Idempotent, Tested, Two-Stage) Data Architecture framework, we provide the technical foundation and practical guidance needed to make this shift successfully. We’ve helped dozens of organizations transform their data teams from cost centers to value drivers, from project factories to product organizations.
Whether you’re just beginning to explore the product mindset or looking to accelerate your existing transformation, DataKitchen can help. Our Open Source Software and consulting services provide the tools, processes, and expertise you need to build data products that deliver continuous value to your users. We understand that each organization’s journey is unique, and we tailor our approach to meet you where you are, helping you get where you need to go.
The shift from thinking about data products as a “what” to understanding them as a “how” is more than just a philosophical exercise—it’s a practical transformation that can dramatically improve your team’s effectiveness and job satisfaction. By embracing the product mindset, you’re not just changing how you deliver data assets; you’re changing how your organization creates value from its data. The question isn’t whether to make this shift, but how quickly you can begin the journey. Give us a call!