
The rise of Large Language Models (LLMs) such as GPT-4 marks a transformative era in artificial intelligence, heralding new possibilities and challenges in equal measure. LLMs have the potential to revolutionize how we interact with data, automate processes, and extract insights. However, the foundation of their success rests not just on sophisticated algorithms or computational power but on the quality and integrity of the data they are trained on and interact with. This brings us to the crucial concept of a “Data Journey” — a comprehensive framework that ensures data quality from its inception to its final use in LLMs.
Retrieval-Augmented Generation: Enhancing LLMs with Targeted Data
Retrieval-augmented generation (RAG) is a methodology where an LLM generates outputs based on the input prompt and leverages an external database or repository of information. This approach allows LLMs to pull in relevant data when needed, enriching the model’s responses more accurately and contextually.
The process typically involves:
- Query Formation: The LLM receives a query or prompt and understands the context.
- Retrieval of Relevant Data: The system searches a vector database to find pertinent information to augment the LLM’s response.
- Embedding: The retrieved data is encoded into embeddings that the LLM can interpret.
- Response Generation: The LLM uses the original prompt and the supplementary information to generate a comprehensive and relevant response.
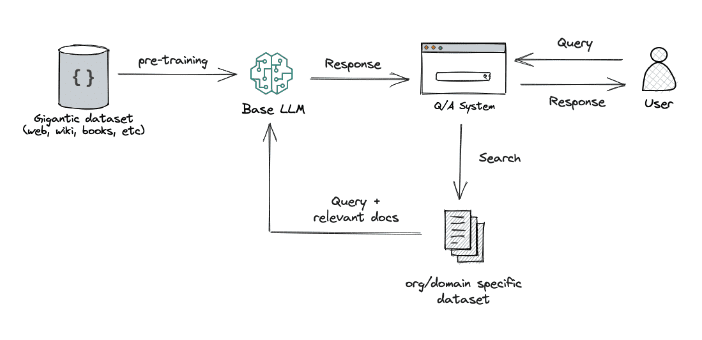
The Role of Data Journeys in RAG
The underlying data must be meticulously managed throughout its journey for RAG to function optimally. This is where DataOps comes into play, offering a framework for managing Data Journeys with precision and agility. DataOps ensures that the data retrieved is relevant, high-quality, and up-to-date.
The journey of each data unit, from source data to vector embeddings to being a part of the LLM’s response, must be traceable and transparent. This transparency enables trust in the system and allows for the refinement of inputs and processes, ultimately leading to more reliable and accurate outputs.
The Imperative of Data Quality Validation Testing
Data quality validation testing is not just a best practice; it’s imperative. This process involves rigorous checking and rechecking of data at every stage of its journey to ensure that it meets predefined standards of accuracy, consistency, completeness, and relevance. For LLMs, which rely heavily on the nuances of the data they’re fed to generate coherent and contextually appropriate responses, even minor discrepancies in data quality can lead to significant errors in output.
Validation testing is a safeguard, ensuring that the data feeding into LLMs is of the highest quality. It also provides a mechanism for continuous improvement, allowing data scientists and engineers to identify and rectify issues before they impact the model’s performance.
Trust as the Cornerstone of Success
Drawing a parallel to the auto-pilot systems in aircraft, the effectiveness of LLMs is deeply rooted in trust. Just as pilots rely on auto-pilot technologies because they understand how they work and trust the data fed into them, data engineers and business leaders must foster a similar level of trust in LLMs. This trust hinges on the quality of the input data and the transparency of the Data Journey.
Challenges in Developing Reliable LLMs
Organizations venturing into LLM development encounter several hurdles:
- Data Location: Critical data often resides in spreadsheets, characterized by a blend of text, logic, and mathematics. Feeding this unstructured data into LLMs without proper contextualization risks creating noise instead of clarity.
- Data Connectivity: Mergers and acquisitions complicate data integration, making it challenging for LLMs to consolidate data across disparate systems.
- Blind Spots: A lack of comprehensive understanding of available data assets and their value can hinder the accuracy of LLM models.
- Contextual Relevance: Ensuring the data fed into LLMs is contextually relevant is paramount. Without this, LLMs cannot reliably interpret or generate meaningful outputs.
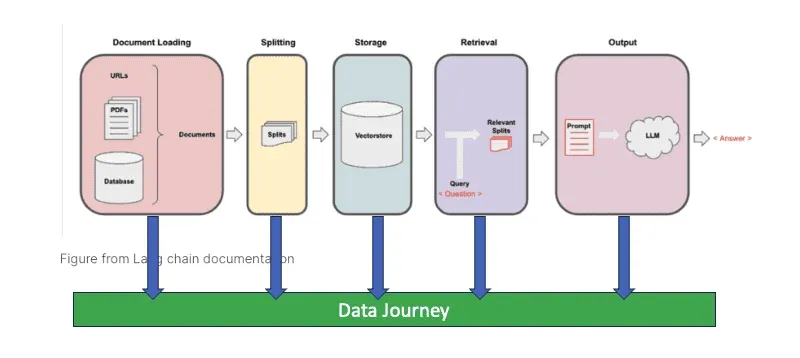
Multi-Tool Data Journey Observability in RAG Architecture
Integrating Retrieval-Augmented Generation (RAG) with LLMs introduces a new dimension to Data Journey complexity. RAG enhances LLMs by dynamically pulling in external data to inform responses, thereby requiring the model to generate content based on its training and incorporate up-to-date, relevant information from outside sources. This process necessitates an even greater level of Data Journey observability, ensuring that the retrieved data is accurate, contextually appropriate, and seamlessly integrated with the model’s outputs.
In this context, multi-tool Data Journey observability becomes crucial. It involves using various tools and technologies to monitor and manage data flow through its lifecycle, particularly regarding the retrieval and integration processes unique to RAG. This observability ensures that data scientists and engineers have a clear view of how data moves, transforms, and is utilized across different platforms and models, enabling them to identify and address issues in real-time.
Embracing DataOps for Enhanced Data Journey Management
The complexity of managing Data Journeys, especially in RAG and LLMs, underscores the importance of embracing DataOps principles. DataOps provides a framework for automating and optimizing data workflows, emphasizing collaboration, monitoring, and continuous improvement. By adopting a DataOps approach, organizations can enhance their Data Journey management, ensuring that data is not only of high quality but also that its flow is efficient, transparent, and aligned with the needs of LLMs and other AI models.
Conclusion
The journey toward deploying effective and reliable LLMs is challenging but offers significant rewards. A well-structured Data Journey ensures the quality and reliability of the data feeding into LLMs, laying the groundwork for trust and efficacy in AI-driven processes. As data engineers and technology leaders navigate this landscape, staying informed and proactive in data management practices is paramount.
For organizations looking to explore innovative solutions and best practices in data management for LLMs, DataKitchen offers a suite of products designed to empower data operations with enhanced data quality, observability, and operational efficiency. Visit DataKitchen’s website to learn more about how your organization can benefit from implementing a comprehensive Data Journey in your LLM projects.



