
Why Data Quality And Data Observability Tools Cost So Much (And Why That’s Ridiculous). You’re paying enterprise prices for commodity algorithms. Here’s what’s really going on.
We understand the struggle. Data pipelines fail, dashboards go stale, and someone in finance spots the problem before you do. Suddenly, you’re firefighting instead of building. Data observability tools promise to fix this. Sounds great, right?

Then you see the price tag: $50,000, $100,000, sometimes north of a million dollars a year.
For what, exactly? Let’s talk about what you’re actually paying for, and why the pricing in this market has gone completely off the rails.
Want to watch instead of read? Watch the on-demand webinar
Part 1: The Dirty Secret of Data Quality and Data Observability Pricing
Enterprise data quality and data observability vendors have figured out the perfect scam: charge you more every time you try to do the right thing.
Per table. Per row. Per “credit.” Per whatever made-up unit lets them bill you into oblivion.
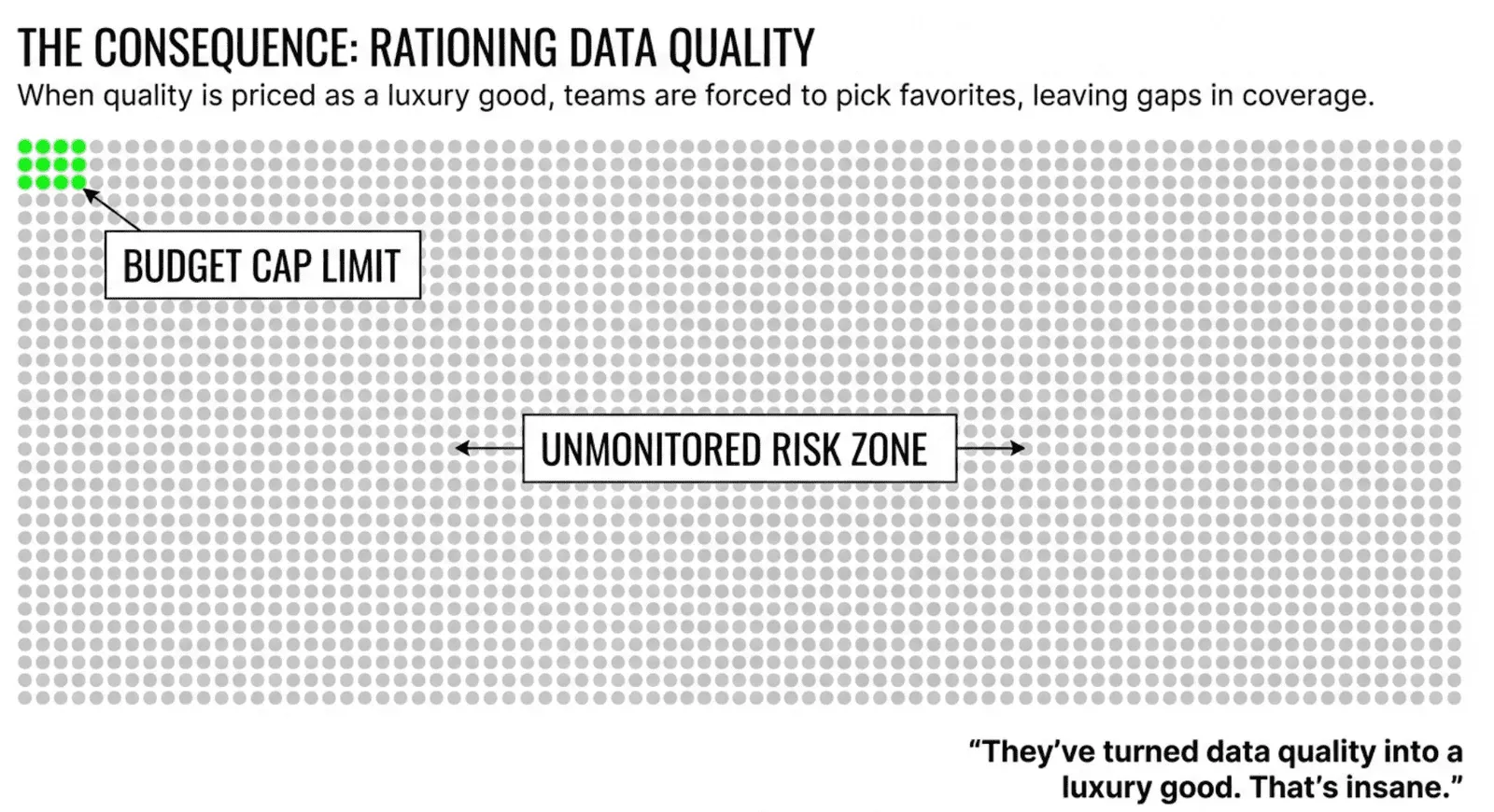
Got 10,000 tables? Congratulations. You now need a six-figure budget just to find out whether your data is broken. So you don’t test everything. You pick favorites. You cross your fingers. And when bad data sneaks through the tables you couldn’t afford to monitor? That’s your problem, not theirs.
They’ve turned data quality into a luxury good. That’s insane.
Data quality isn’t a premium feature. It’s not a luxury. It’s the bare minimum for trusting your analytics, your ML models, your dashboards, your decisions. The idea that teams should ration their data quality coverage like wartime bread is absurd.
It’s All Commodity Code Under the Hood
Here’s something vendors don’t like to discuss: every data observability tool runs on the same basic time-series anomaly detection algorithms, e.g., Facebook’s Prophet orARIMA. Some combination of similar methods. There is no secret sauce. Time-series anomaly detection is still an active area of research in universities, and no vendor has cracked something the academic community hasn’t already published.
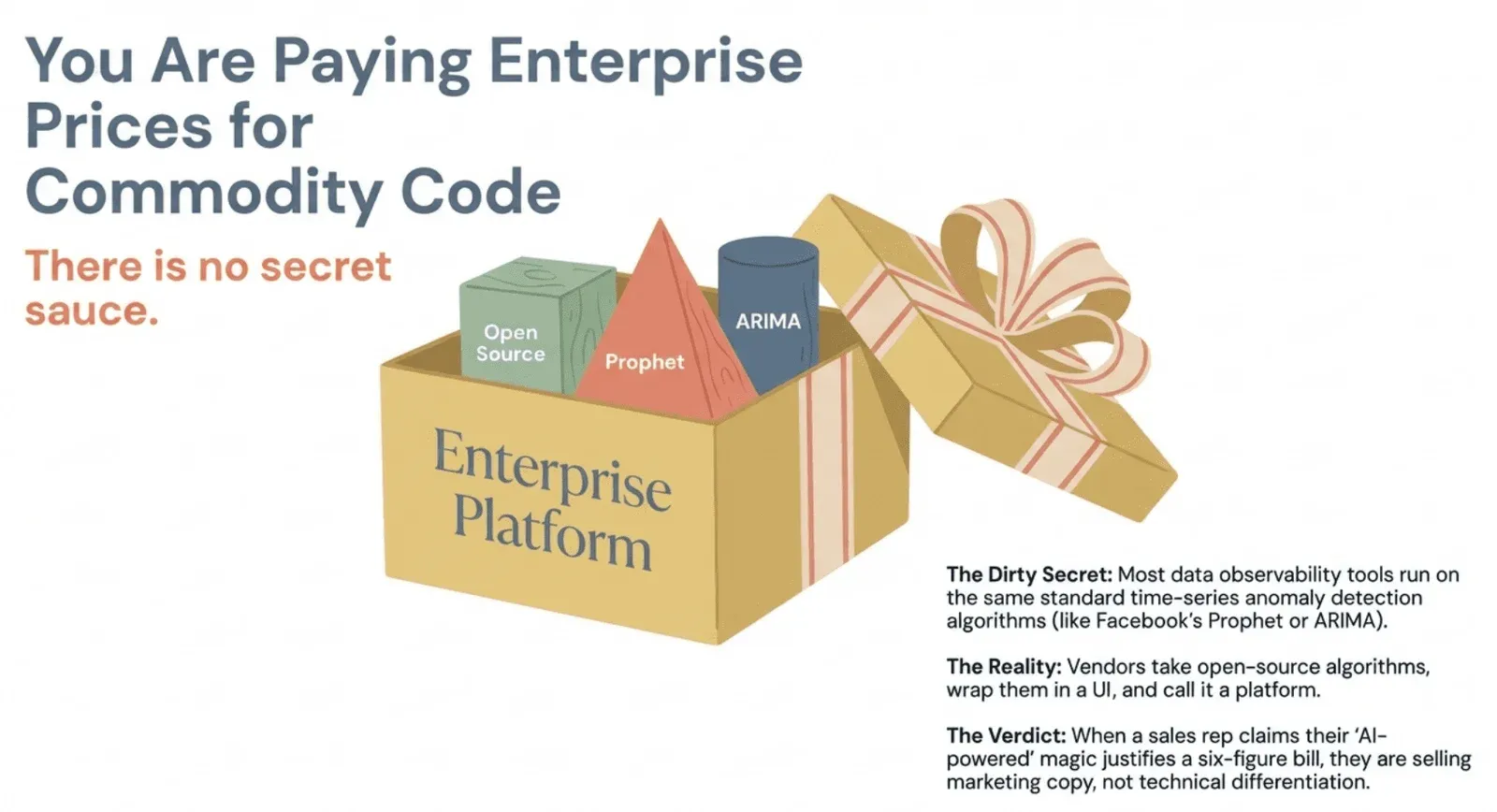
Most of these tools take open-source algorithms, wrap them in a nice UI, and call it a platform. That’s the product. That’s data observability.
Does it work? Sure, it can catch issues. But when a sales rep tells you their “AI-powered” platform justifies enterprise pricing because of proprietary magic, they’re selling you marketing copy, not technical differentiation.
The Real Reason for the Price Tags: Venture Capital Math
If the technology is a commodity, why are prices so high? Because vendors need to charge hundreds of thousands of dollars a year. Their investors expect them to hit $100 million or more in revenue. The pricing isn’t based on cost to serve or value delivered. It’s based on what VCs need to see on a spreadsheet.

Even if you’re getting a discount today, a price hike is coming. Look at what happened with dbt and Fivetran. One Reddit user put it plainly: “We are experiencing a huge spike (more than double) in monthly costs following the March 2025 changes, and now with the January 2026 pricing updates.” Every year brings a new price increase, and pay-per-usage models make it worse. Your costs rise automatically as your data grows.
The data engineering community has caught on. As one practitioner warned: “You need to keep an eye on how costs grow as your usage increases.” This isn’t paranoia. It’s pattern recognition from people who’ve watched their bills double and triple.
Most vendors lure you in with friendly pricing, then jack up rates once your data pipelines depend on them. Just ask a Fivetran or dbt customer what their bill looked like in year one versus year three.
What It’s Actually Like to Use These Tools
The gap between the sales pitch and operational reality comes up constantly when practitioners speak honestly. One data engineer shared their experience on Reddit: “My personal experience working at a fintech startup leveraging Monte Carlo is that it has a lot of beneficial features but it’s overly complex for use across the organization (the DE team found it useful), prohibitively expensive if you want to cover your entire infrastructure, and takes a dedicated effort (at least a month for us) to get the alerting to a manageable state to avoid alert fatigue.”
Think about that. Even at a well-funded fintech, the tool was too expensive to cover the full cost of their infrastructure. The team spent a month tuning alerts to avoid being buried in noise. Only the data engineering team found it useful. Not the analysts, not the business users, not the broader organization that was supposed to benefit from better data quality.

Another engineer was more direct: “It’s expensive as golden shit. If your company has money to throw around, go with it. If not, there are better ways to spend cash.”
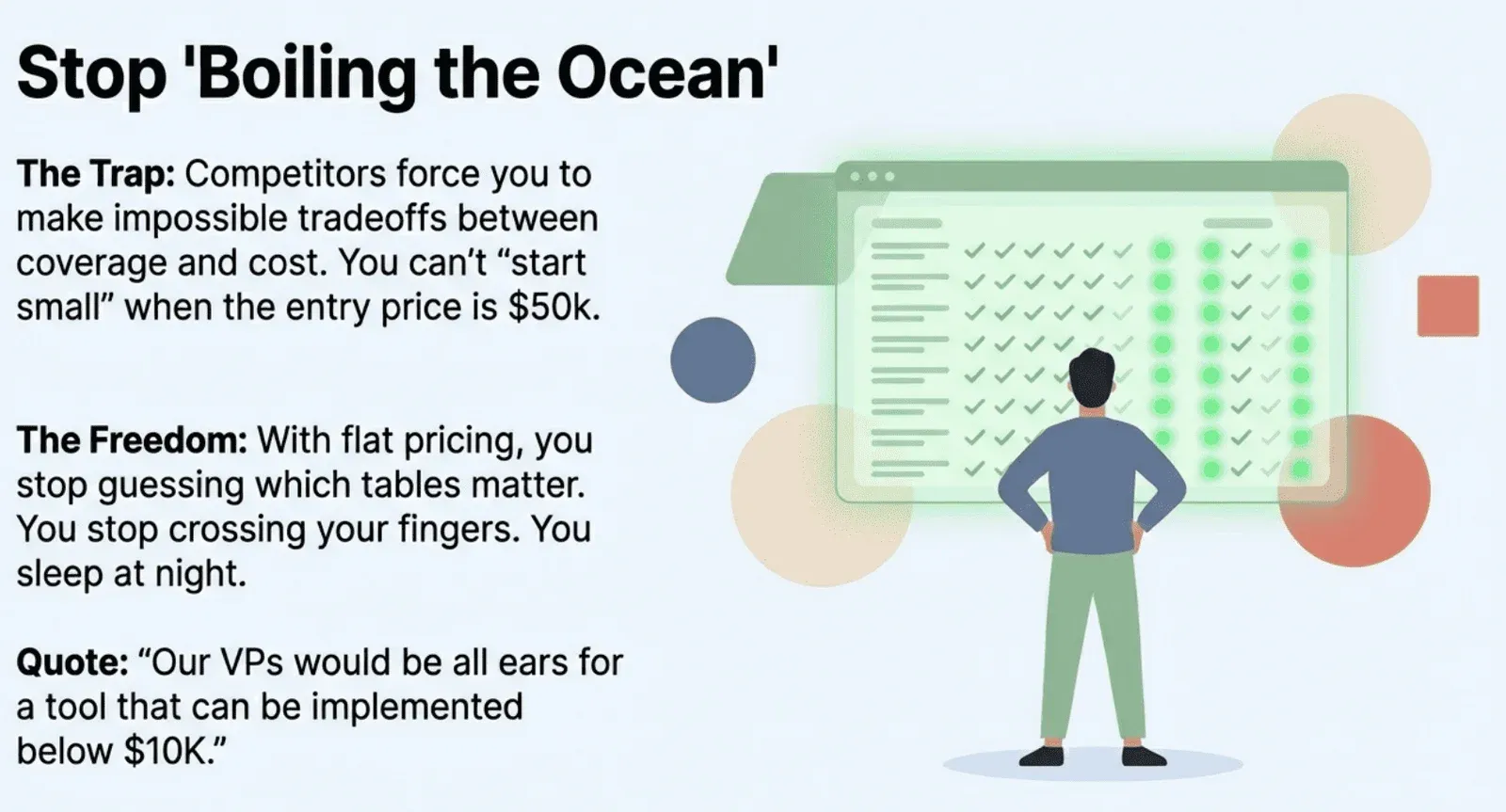
These prices create a strategic problem. As one frustrated practitioner explained: “Boiling the ocean: we understand not to implement it slowly, but the DQ tool is priced too high to go slow on value realization. They want a proven main player tool that can be implemented below $10K and ramps up when we need it. Our VPs would be all ears.”
Best practice says start small, prove value, then expand. But these tools are priced for big, enterprise-wide commitments from day one. You can’t start small and grow. You either overpay before proving ROI, or you walk away entirely.
Who Actually Needs Six-Figure Observability?
To be fair, there are scenarios where expensive tools might make sense. As one Redditor noted: “If your data team has more than 10ish people and you spend more than 30% of your time on quality issues, it’s likely worth investigating.”
Notice those qualifications: more than ten people, spending over 30% of your time on quality fires. That describes a large team drowning in data problems.
What about the majority of teams? Four to eight people, real quality issues, but no way to justify $80,000? The current market has essentially abandoned them.
Usage-Based Pricing Is a Disaster Waiting to Happen
One of our customers is a small company with 400 employees and a data team of six people. She has 1,000 tables in her main application and another 500 in a data warehouse. Soda Data would cost her $750 per month base plus per-table fees that add up to nearly $12,000 per month. That’s over $150,000 per year. DataKitchen costs her $9,000.
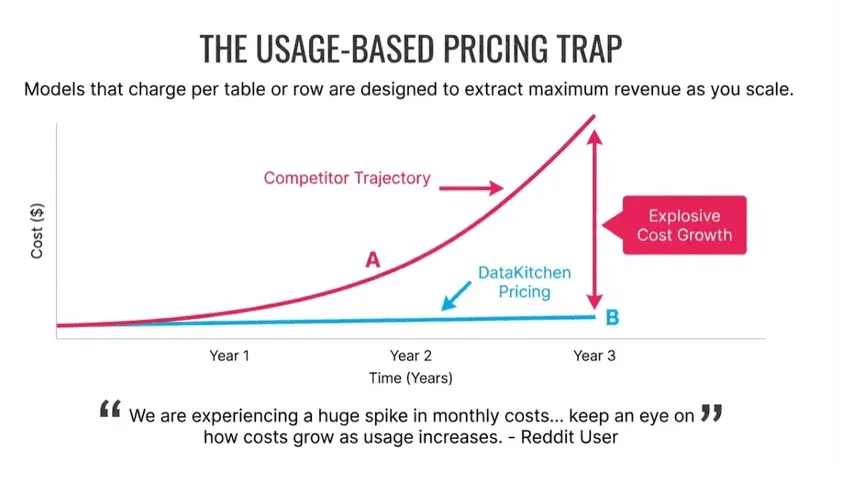
Why the difference? Soda just raised a new round of venture capital in April 2024. They have investors to satisfy. Prices will rise.
There are more than 50 companies offering data quality data observability tools, backed by over half a billion dollars in investment. They’re all waiting for you to buy, then raise prices to hit their growth targets.
With per-table pricing, your bill grows linearly (or worse) with your data. With flat pricing, you can actually afford to monitor everything. You stop guessing which tables matter. You stop crossing your fingers. You sleep at night.
What Data Observability Should Actually Cost
So what’s a reasonable price? Not $100,000 a year. Not a million dollars. For a small team of 4 people with a few databases, it should cost $0 or at most $9,000- $10,000 per year. That price should include support, updates, and a real partnership with your vendor. No extra charges for adding tables. No penalties for running more tests. Everything is included in a flat price.

This isn’t wishful thinking. The economics support it. The algorithms are open source. Cloud computing is cheap. The high prices are due to the business model, not the technology.
You should be able to detect broken pipelines for $100 per month, not $100,000 per year. The technology exists. The market just hasn’t caught up.
Part 2: A Better Way: DataKitchen’s Sane Pricing
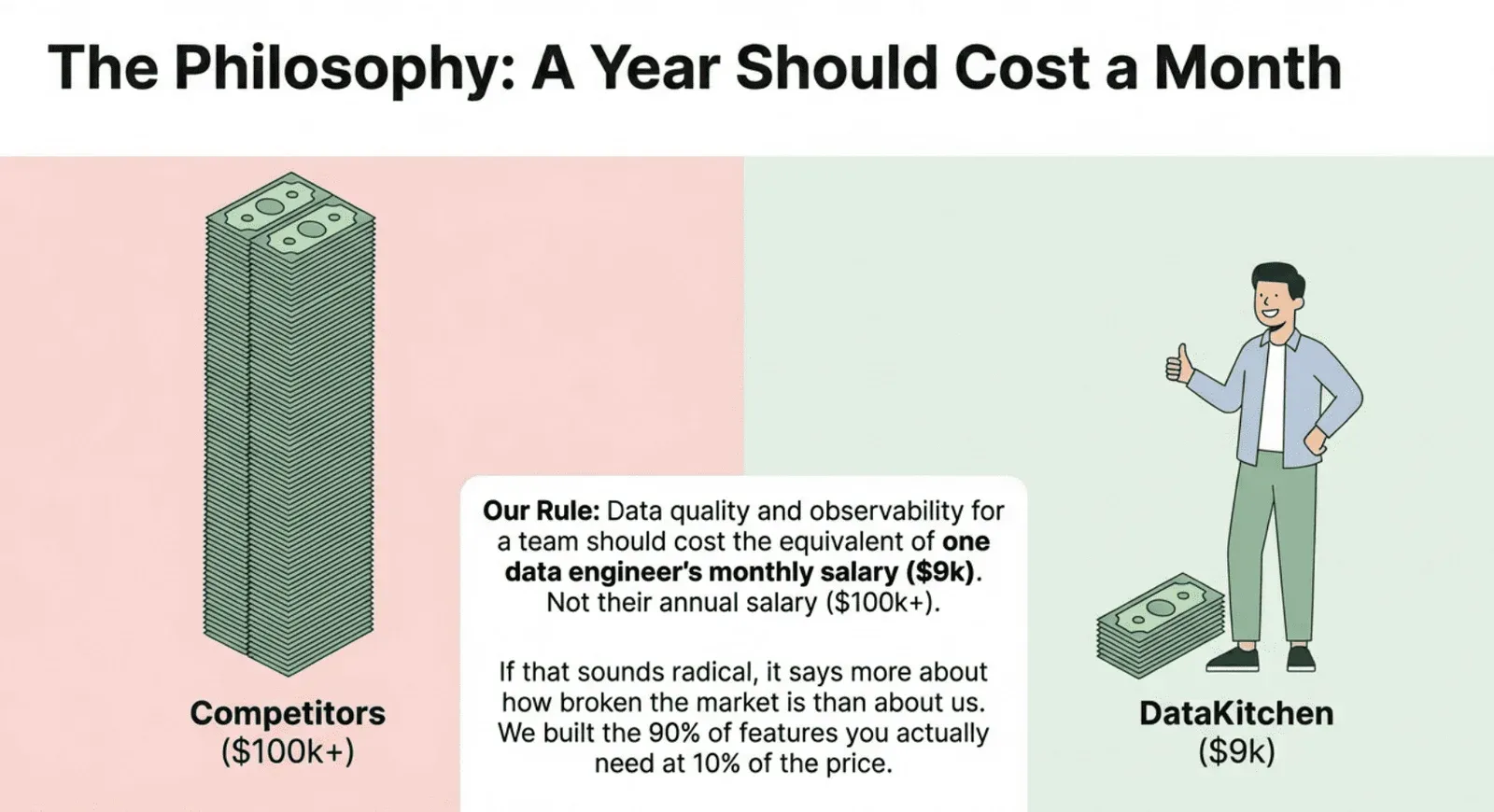
Here’s what we believe: data quality and observability for a small team for an entire year should cost the equivalent of one data engineer’s monthly salary.
Not their annual salary. One month.
If that sounds radical, it says more about how broken this market is than about us.
Buy from a profitable, independent company. Don’t pay the “VC squeeze.” We’ve been profitable for 12 years. We built our tools from the profits of our data engineering consulting work because we needed something that actually worked. We don’t have venture investors demanding growth at all costs, so there’s no pressure to raise prices every year.
We built the 90% of the features you need at 10% of the price.
Two Tools. One Mission: Trust Your Data.
We built two Apache 2.0 open-source tools that cover the full picture of data reliability
TestGen validates your actual data: schema changes, null rates, duplicates, referential integrity, sand tatistical anomalies. Observability monitors your pipelines, transformations, and orchestration tools to catch failures before they cascade downstream.

Together, they answer two questions every data team needs answered: Is my data correct? And did the processes that created it run properly?
Pricing That Doesn’t Punish You for Scaling
Most vendors structure pricing to extract maximum revenue as you grow. More tables mean more money. More tests mean more money. That model forces you to make impossible tradeoffs between coverage and cost.
We think that’s backwards. Here’s our pricing:
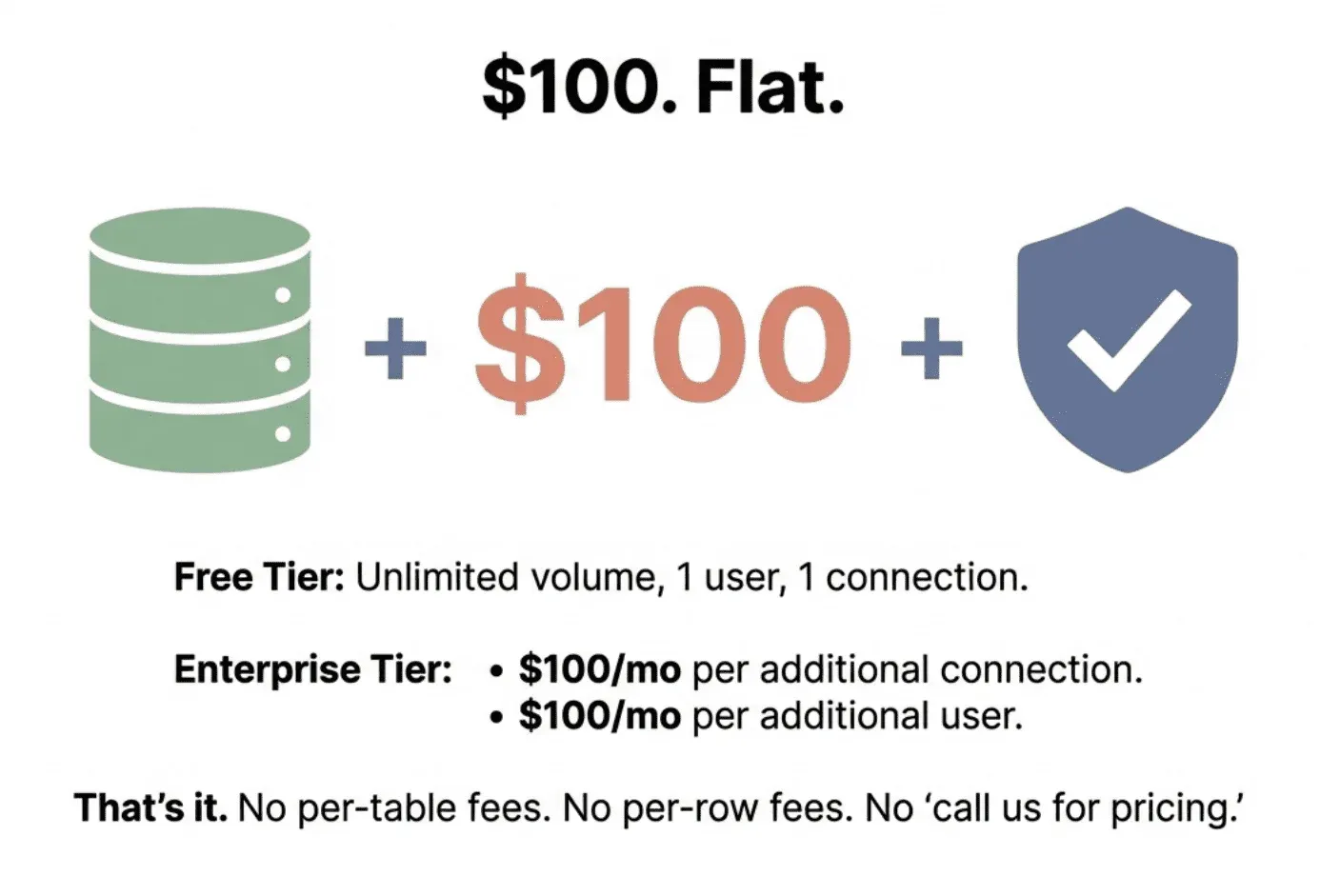
That’s it. No per-table fees. No per-row fees. No credits that run out at the worst possible time. No “let’s schedule a call to discuss pricing.”
A team of four people with three databases and unlimited tables pays less than $9,000 a year. Test every table. Run every check. Your price stays the same whether you have 100 tables or 100,000.
Why We Can Offer This When Competitors Charge 10x More
The answer is simple: DataKitchen has been profitable for 12 years. We developed TestGen and Observability for our consulting work because we needed solutions that were effective and reasonably priced. We don’t have venture investors demanding we become a unicorn. We just need to build something useful and run a sustainable business.

That means no pressure to raise prices every year. No incentive to add per-table fees that punish you for growing. No need to optimize for investor returns instead of customer value.
Built by data engineers, for data engineers. Open-source core. Predictable enterprise pricing when your team needs it.
The Market Is Ready for Change
The data observability market is ripe for disruption because current pricing has lost touch with reality. Open-source alternatives are getting better. Teams are building lightweight in-house monitoring solutions. Sooner or later, someone was going to offer real observability at prices that don’t require board approval.
We decided to be that someone.
Until the rest of the market catches up, question any vendor who can’t explain their pricing simply. Ask about price increases for existing customers. Demand transparent pricing that doesn’t penalize you for adding tables or running more tests. And remember what you’re actually buying: commodity algorithms with a nice interface. Set your expectations accordingly.
Use TestGen In Production Today
If you’re tired of being told that data quality and data observability require a six-figure investment, give open source TestGen a try. Use it in production yourself. If you want to do more, then start using the enterprise version

No credits. No gotchas. No “let’s schedule a call to discuss pricing.”
Test everything. Pay almost nothing.
Frequently Asked Questions, TLDR;
1. Most observability tools use commodity algorithms. There’s no technical reason for enterprise pricing.
2. High prices are driven by venture capital math, not actual value or cost to serve.
3. Usage-based pricing is designed to extract more money as you grow. Flat pricing lets you actually cover your infrastructure.
4. A year of data quality should cost a month of a data engineer’s salary, not their annual salary.
5. Affordable, open-source, low-risk alternatives exist. You don’t have to play the enterprise game.




