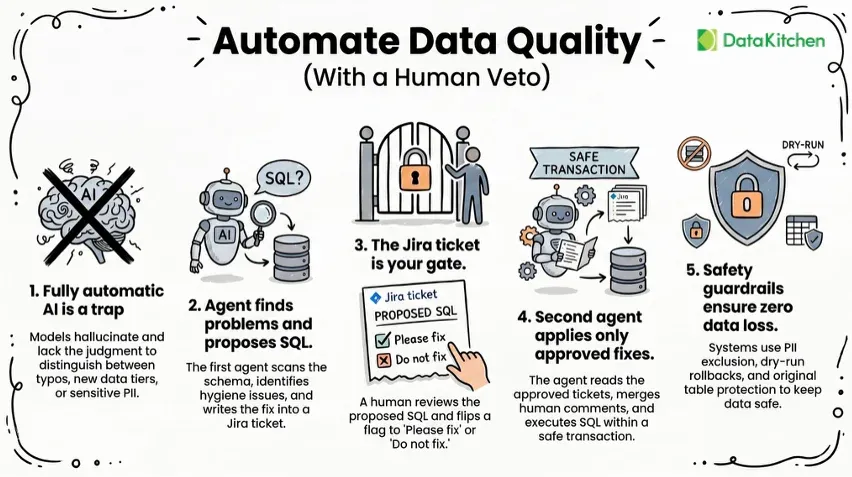
In the first part of this series, we explored the Seven Deadly Sins of Data Quality, focusing on the individual behaviors that sabotage data teams: shame, denial, avoidance, passivity, laziness, gluttony, and ignorance. But here is the uncomfortable truth that nobody wants to talk about: even if every person on your data team somehow conquered their personal demons tomorrow, you would still have a data quality problem. The issue is not just about people. It is about how organizations structure their teams, define success, and approach the very nature of data work itself.
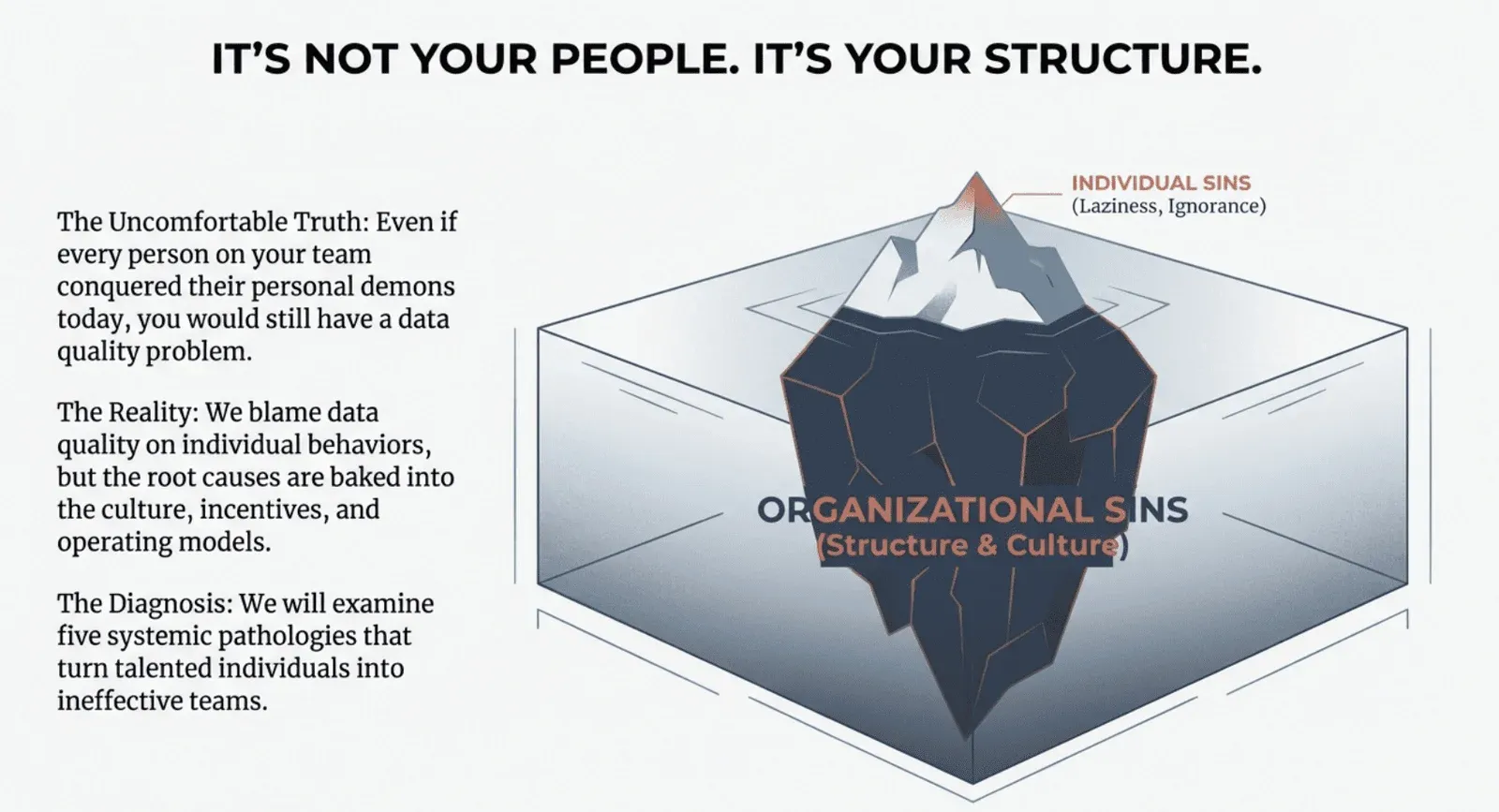
Organizational sins are more challenging to diagnose and even more complex to fix because they are baked into the culture, the incentive structures, and the operating models that everyone takes for granted. These are the systemic dysfunctions that turn talented individuals into ineffective teams and promising initiatives into expensive disappointments. In this follow-up post, we examine five organizational sins that plague data teams: low relational coordination, blame culture, data blindness, project thinking, and lack of process curation. Recognizing these patterns is the first step toward building data organizations that actually work.
Sin One: Low Relational Coordination
Data organizations face unique challenges in fostering positive interaction and communication, as tools and workflows often promote isolation. Groups that should be partners working toward shared objectives often behave more like warring tribes competing for resources and pointing fingers when things go wrong. As explored in Warring Tribes into Winning Teams, geographical, cultural, and language barriers compound with technology-driven silos to create what management scientists call low relational coordination. The data engineers, analysts, scientists, and business users who need to collaborate seamlessly instead operate in isolated bubbles, communicating through emails and handoffs rather than a genuine partnership.
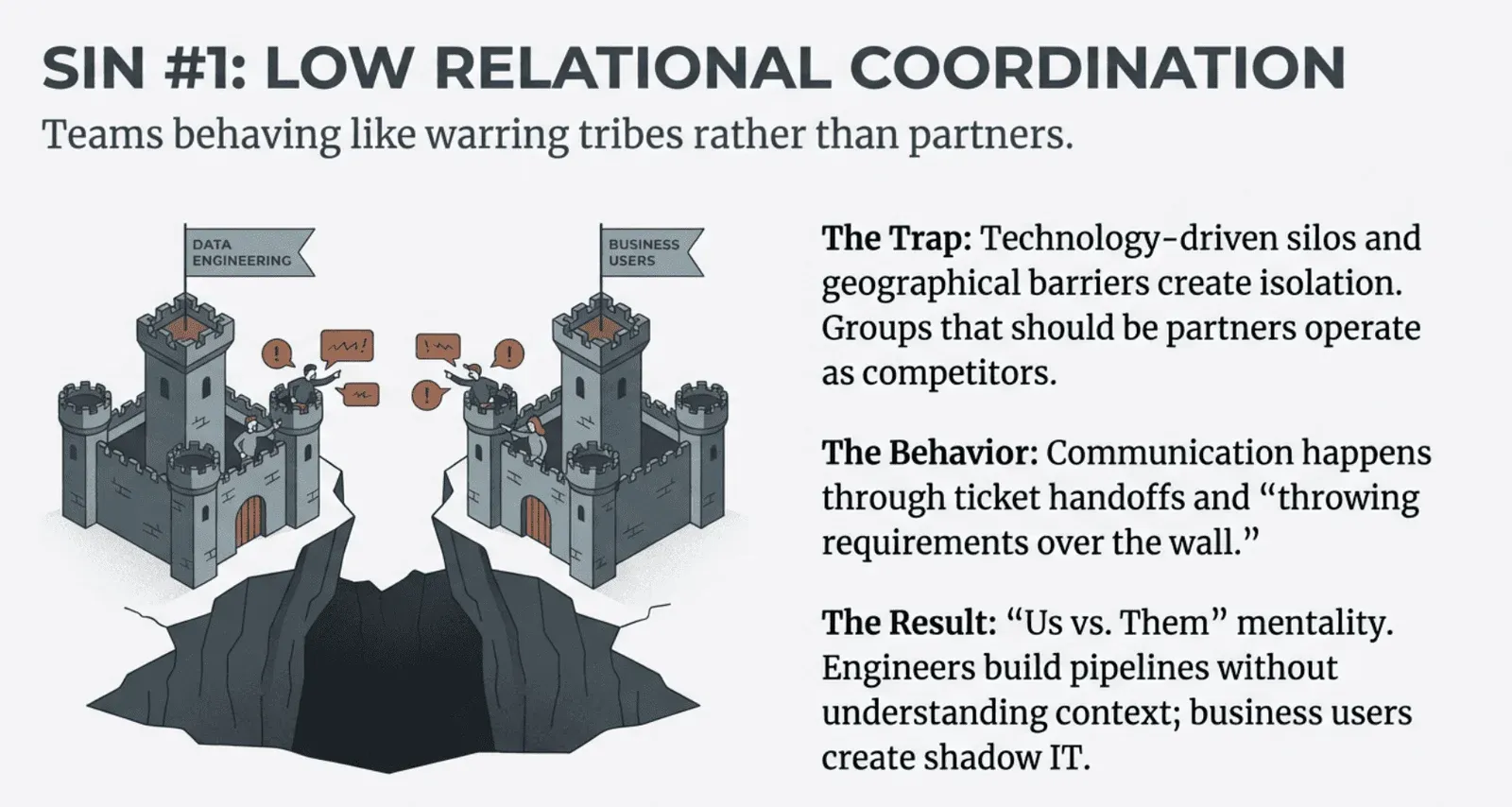
The consequences ripple through every aspect of data operations. Analytics cycle times stretch as teams wait for responses from groups they barely know. Data quality suffers because no one has visibility into the entire pipeline. Governance becomes a bureaucratic exercise rather than a shared commitment. Employee retention plummets as talented people tire of fighting the same battles over and over. The solution requires more than better communication tools. Organizations must restructure their workflows to build strong role relationships and coordination that enable high performance. DataOps provides a framework for doing exactly that, using automation and process design to facilitate rather than hinder the communication between groups.
Sin Two: Blame Culture
In the world of data and analytics, one skill stands timeless and universal: the art of blaming someone else when things go sideways. As satirized in The Art of Data Buck-Passing 101, data teams have elevated finger-pointing to a dark art form. When data issues surface, development teams blame QA. QA blames operations. Operations blames the data providers. Everyone invokes the sacred incantation of “garbage in, garbage out” while carefully positioning themselves outside the blast radius. The Spiderman pointing meme has become the unofficial mascot of data team retrospectives.

This blame culture is not just demoralizing; it is organizationally corrosive. When people fear being blamed for problems, they stop looking for problems. They push untested code to production because once it is deployed, someone else becomes responsible. They craft emails that document decisions in ways designed to deflect future accountability rather than facilitate current collaboration. The energy that should flow into fixing root causes instead flows into constructing elaborate defenses. Breaking this cycle requires shared visibility into data pipelines, clear ownership models, and a cultural shift from “who broke it” to “how do we prevent it from breaking again.” Until organizations address the blame game directly, they will continue playing it.
Sin Three: Data Blinders
Most data teams are data-centric rather than process-centric, and this distinction has profound implications for their effectiveness. As described in Are You Process-Centric or Data-Centric?, data-centric teams perceive complexity as directly proportional to the number of tables they manage. Their databases feel like mysterious, daunting black boxes full of tables updated at seemingly random frequencies by processes that are unknown or uncontrolled. Data engineers in these environments frequently respond to quality issues without direct control over the processes that cause the errors. They are held responsible for data problems but cannot actually fix or influence the pipelines that create them.
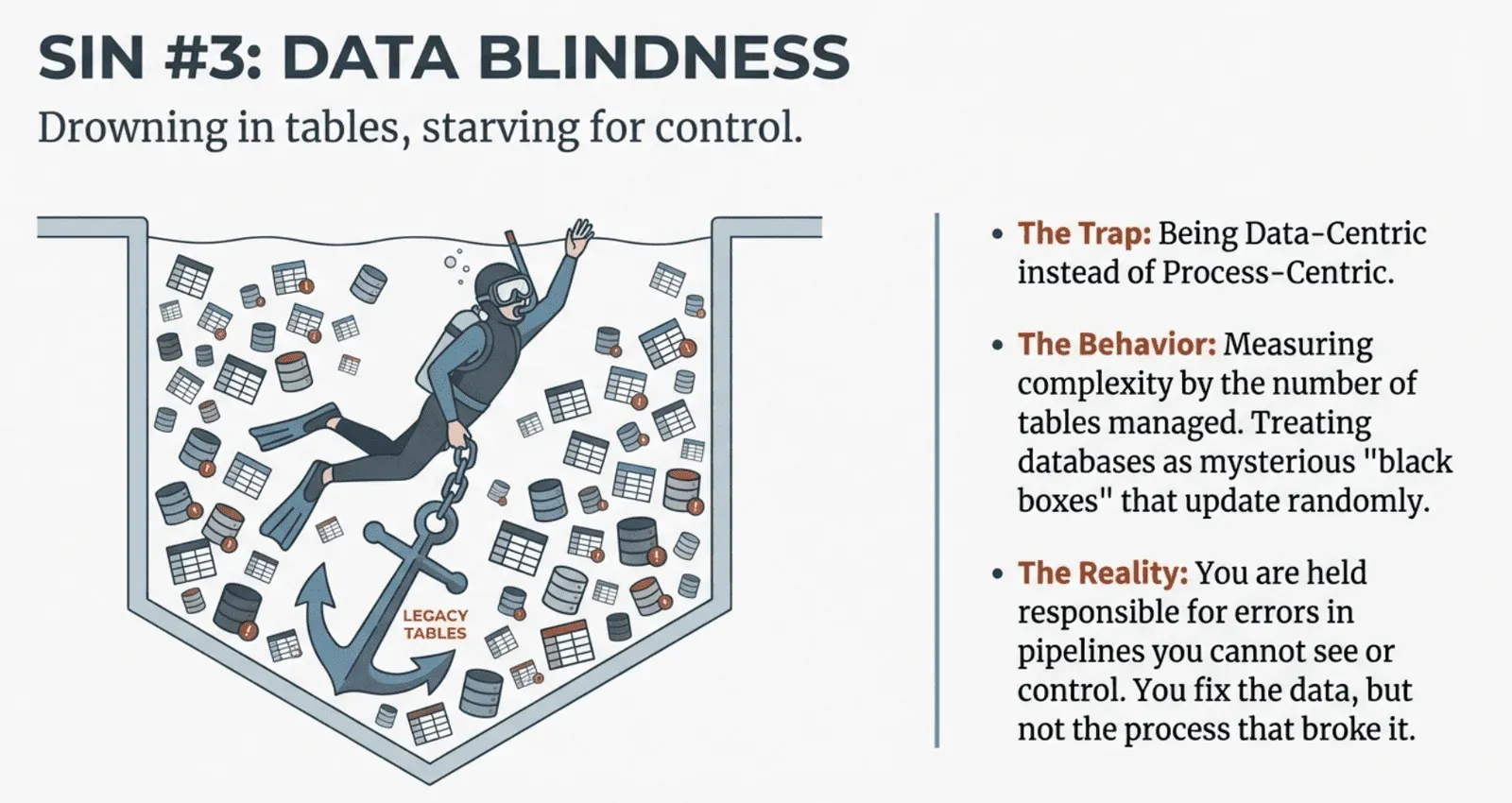
Process-centric teams operate completely differently. They focus on orchestrating and automating workflows, recognizing that robust, well-managed data processing pipelines inevitably yield reliable, high-quality data. Rather than focusing on individual tables, these teams allocate resources to ensure each pipeline is transparent, thoroughly tested, and easily deployable. They treat their pipelines as cattle, not pets, enabling them to quickly diagnose and rectify issues at the process level rather than getting lost in individual data table anomalies. The shift from data-centric to process-centric thinking is achievable, but it requires leadership commitment to unified orchestration, process transparency, and rigorous adherence to DataOps principles.
Sin Four: Project, Not Product Focus
When data team leaders hear “data products,” they immediately think of the stuff they produce: dashboards, datasets, models, and warehouses. But as argued in You’re Thinking About Data Products All Wrong, focusing on the “what” completely misses the massive shift that data products really represent. The truth is that data products are not about what you create but how you build, maintain, and continually improve your data assets to deliver value to customers. When organizations think about data products merely as deliverables, they fall into the same trap that has plagued data teams for decades: the project mindset.

In the project world, workflows progress through stages in sequence. Teams are assigned to specific projects, creating silos and handoffs that slow delivery and degrade quality. Success is measured by whether the project was delivered on time and within budget, not by whether users actually found it valuable. The product approach transforms this dynamic entirely. Instead of significant, risky releases, teams deliver minor, incremental improvements continuously. Work is brought to stable teams who own their products end-to-end. Most importantly, the approach recognizes that data products are never “done.” This continuous improvement mindset yields measurable benefits: faster releases, increased team learning, better insights, and ultimately faster delivery of value from data investments.
Sin Five: Lack of Process Curation
There is a quiet crisis happening in data organizations everywhere. It occurs when brilliant analysts independently solve the same problem in three different ways, when data scientists struggle to reproduce each other’s work, and when a single “simple” metric like Monthly Recurring Revenue has five competing definitions scattered across the organization. As detailed in Process Guardianship: The Most Valuable Data Engineering Work You’re Probably Not Doing, the absence of deliberate process curation means that business logic lives everywhere and nowhere. Metrics, models, calculations, and code are scattered across SQL scripts, Jupyter notebooks, Looker reports, Python models, and Excel macros, with no one taking responsibility for consolidating them into a unified, tested, production-grade system.
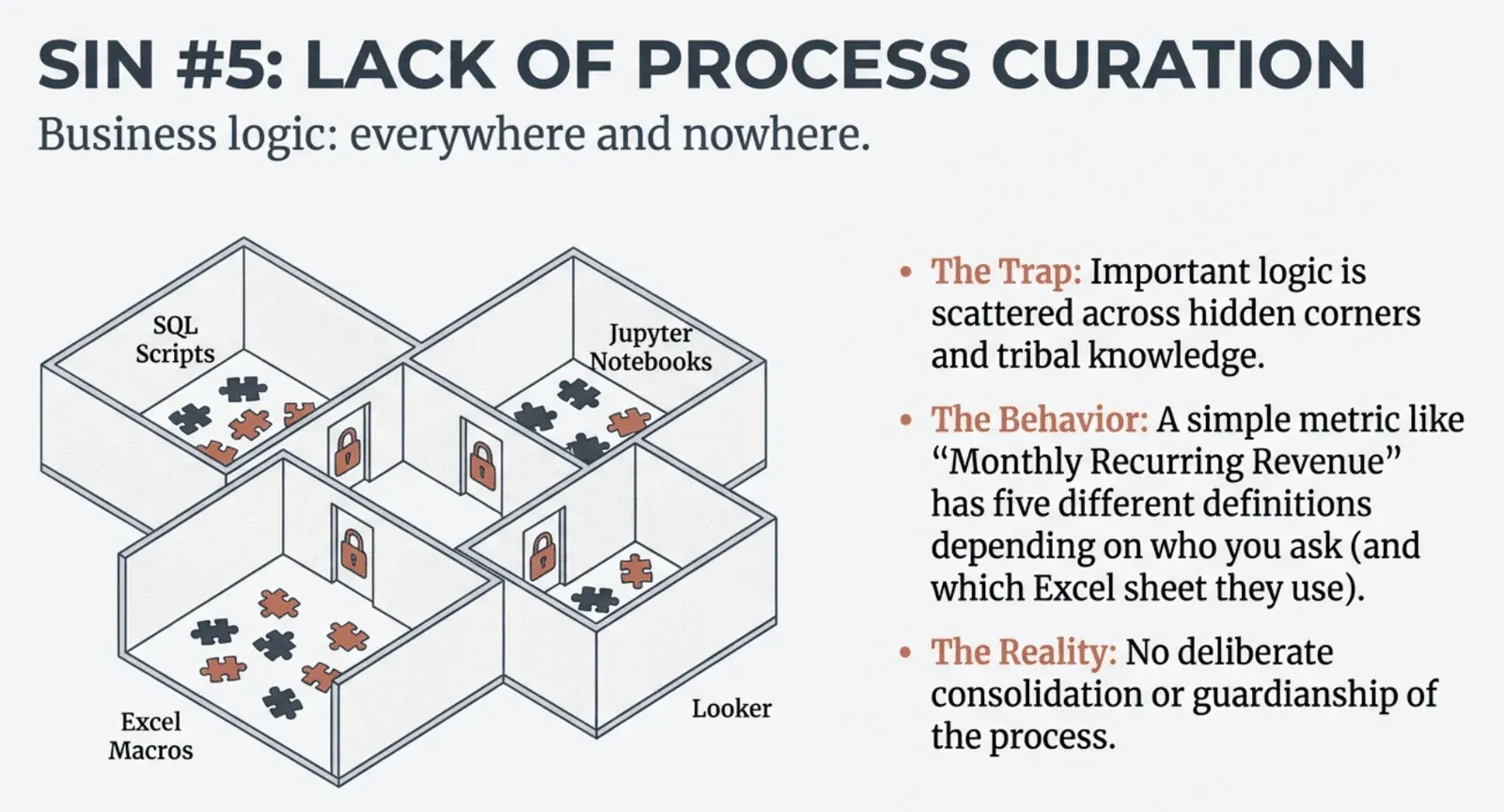
The costs compound quickly. Duplicate work becomes the norm as teams waste countless hours reinventing the wheel because they do not know what already exists or cannot trust it enough to reuse. Multiple overlapping metrics create confusion and erode stakeholder trust. When leadership asks how many customers are in the high-value segment, they get three different answers. Embarrassing data errors slip through because corrections identified by one team are not shared with the rest of the enterprise. Data engineers have a unique opportunity to address this crisis through what might be called process guardianship: actively consolidating business logic, extracting it from hidden corners and tribal knowledge, and encoding it in a centralized, version-controlled, production-ready system. This work may seem unglamorous, but it is often the most valuable contribution a data team can make.
Moving From Organizational Sin to Organizational Strength
These five organizational sins share a common thread: they all represent failures of systems and structures rather than failures of individuals. You cannot shame individual data engineers into fixing low relational coordination. You cannot train analysts out of blame culture while the incentive structures reward blame. You cannot wish your way from data-centric to process-centric thinking without fundamentally changing how work is organized and measured. This is precisely why DataOps exists. DataOps is not just DevOps for data. It is a comprehensive methodology that applies Agile development, DevOps, and lean manufacturing practices to data analytics, enabling organizations to accelerate the development of new analytics, deploy with confidence, and reduce data errors to virtually zero.
The DataOps Cookbook provides a practical roadmap for implementing these principles. Now in its third edition, the Cookbook explains how DataOps draws on lessons from the software and manufacturing industries to transform data chaos into a single, smooth, efficient process that delivers fast, error-free insight. It covers everything from understanding Data Journeys and implementing observability to building the automated testing and unified orchestration that process-centric teams require. The methodology addresses each of the organizational sins we have discussed: it breaks down silos through shared visibility and collaboration frameworks, eliminates blame culture by making pipelines transparent and accountable, shifts teams from data-centric to process-centric thinking, enables product mindsets through continuous delivery practices, and provides the foundation for true process guardianship.
The journey from organizational dysfunction to data team excellence is not easy, but it is achievable. Thousands of data professionals have already formed study groups around the DataOps Cookbook and are beginning to transform their organizations. The key insight is that you do not need to fix everything at once. Start by focusing on understanding and observing the journey that data takes through your production environment. This monitoring process identifies data errors, tool problems, and timing issues, enabling a quick win for your DataOps implementation by driving immediate improvements. Lowering production errors increases the reliability of your data and gives your team more time to focus on automation. From there, you can systematically address each organizational sin, building the collaborative, process-centric, product-oriented data organization that actually delivers on the promise of data-driven decision making. Download the DataOps Cookbook and start your team’s transformation today.
Frequently Asked Questions, TLDR;
What is the summary of the blog The Five Organizational Sins of data teams?
While the “Seven Deadly Sins” previously focused on individual behaviors (like shame and denial), the Five Organizational Sins describe systemic dysfunctions. These failures are baked into a company’s culture, incentive structures, and operating models. Even if every individual conquers their personal bad habits, these structural issues can still cause data teams to fail. Here are the five organizational sins of data teams:
1. Low Relational Coordination (“Warring Tribes”)
This sin occurs when data organizations function as isolated silos rather than partners.
The Problem: Technical, cultural, and language barriers separate data engineers, analysts, and business users. Instead of collaborating, they communicate through tickets and handoffs, behaving like “warring tribes” competing for resources.
The Consequence: This isolation creates low relational coordination, leading to stretched cycle times and poor data quality because no single group has visibility into the entire pipeline. It turns governance into a bureaucratic exercise rather than a shared commitment.
2. Blame Culture (“The Art of Buck-Passing”)
This is the systemic habit of pointing fingers when data issues arise, rather than fixing the root cause.
The Problem: When data breaks, teams immediately look for someone to blame: Development blames QA, QA blames Operations, and everyone blames the data providers.
The Consequence: This is corrosive because it discourages people from looking for problems. If finding an error means being blamed for it or having to fix it alone, engineers will “push untested code to production” to shift responsibility elsewhere. Energy that should be spent on prevention is instead spent on constructing defenses to stay outside the “blast radius” of failure.
3. Data Blindness (Data-Centric vs. Process-Centric)
This sin is the failure to manage the factory (the pipeline) because the team is too focused on the product (the tables).
The Problem: Most teams are data-centric, viewing complexity as the number of tables they manage. They treat databases like “black boxes” full of tables updated by mysterious processes they do not control.
The Consequence: Engineers are held responsible for data quality but lack control over the pipelines that cause errors. Successful organizations must shift to a process-centric approach, treating pipelines like “cattle, not pets,” and focus on orchestrating and automating the workflows that produce the data.
4. Project, Not Product Focus
This sin involves treating data assets as one-off deliverables rather than evolving products.
The Problem: Teams view success as delivering a project (like a dashboard or dataset) “on time and on budget.” Once delivered, the team moves on to the next project, creating silos and handoffs in the process.
The Consequence: This ignores the reality that data products are never truly “done.” A project mindset leads to risky “big bang” releases. A product mindset, by contrast, keeps stable teams on the asset to deliver continuous, incremental improvements and maintain value over time.
5. Lack of Process Curation
This is the chaos that ensues when business logic is scattered across the enterprise without ownership.
The Problem: Critical logic lives “everywhere and nowhere”—buried in SQL scripts, hidden in Excel macros, or locked in Tableau calculations. There is no “Process Guardian” responsible for consolidating this logic.
The Consequence: This leads to “metric confusion,” where a simple number like Monthly Recurring Revenue has five different definitions across the company. Teams waste time reinventing the wheel, and stakeholders lose trust because they get different answers to the same question from different departments.
Unlike individual sins, which can be addressed through personal initiative, organizational sins represent failures of systems. You cannot shame a team out of low relational coordination, nor train them out of a blame culture if the incentives reward it. Curing these requires a fundamental shift toward DataOps principles: shared visibility, automated orchestration, and continuous improvement.
Where can I learn more?
Low Relational Coordination – Teams behaving like warring tribes rather than partners, with technology-driven silos hindering communication
Warring Tribes into Winning Teams: Improving Teamwork in Your Data Organization
Blame Culture – The art of data buck-passing and how it corrodes organizational effectiveness
The Art of Data Buck-Passing 101: Mastering the Blame Game in Data and Analytic Teams
Data Blinders – The difference between data-centric teams (drowning in tables) and process-centric teams (controlling pipelines)
Unlocking Data Team Success: Are You Process-Centric or Data-Centric?
Project, Not Product Focus – The trap of treating data work as one-off projects rather than continuously improved products
You’re Thinking About Data Products All Wrong
Lack of Process Curation – Business logic scattered everywhere and nowhere, with no deliberate consolidation
Process Guardianship: The Most Valuable Data Engineering Work You’re Probably Not Doing