
Harnessing Data Observability Across Five Key Use Cases
The ability to monitor, validate, and ensure data accuracy across its lifecycle is not just a luxury—it’s a necessity. Data observability extends beyond simple anomaly checking, offering deep insights into data health, dependencies, and the performance of data-intensive applications. This blog post introduces five critical use cases for data observability, each pivotal in maintaining the integrity and usability of data throughout its journey in any enterprise.

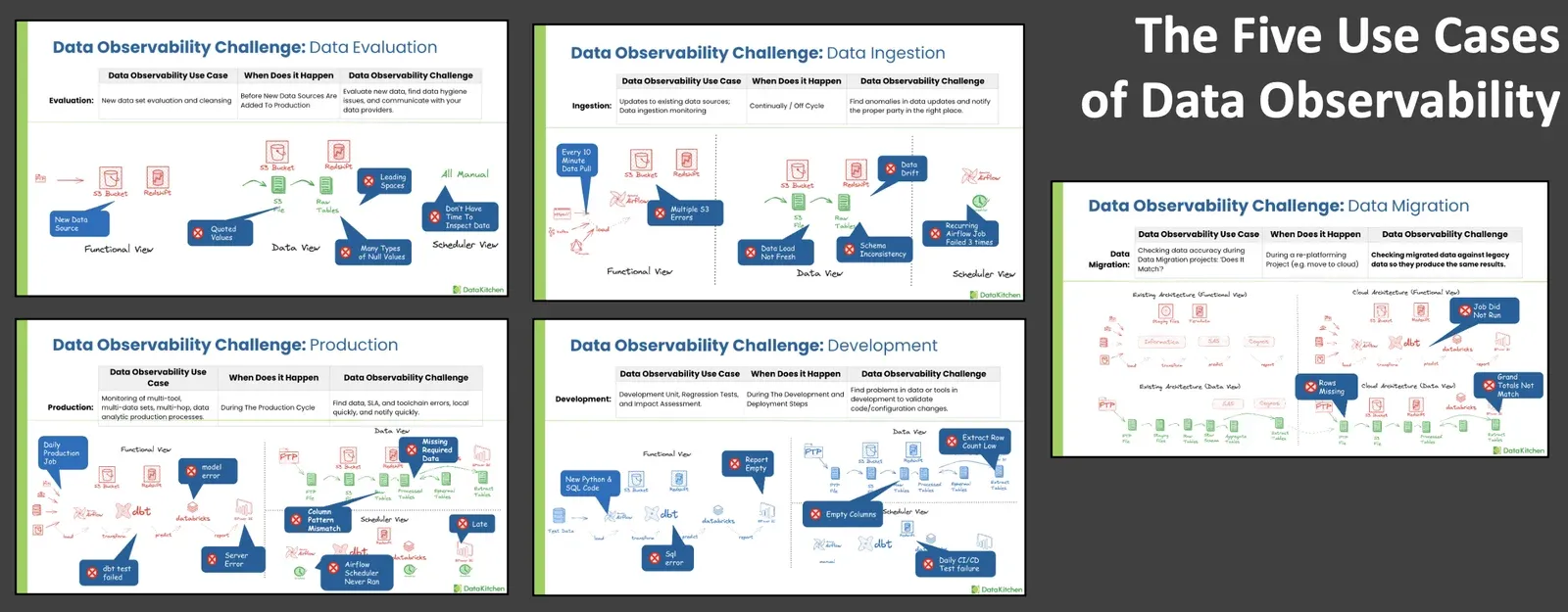
1. Data Evaluation
Before new data sets are introduced into production environments, they must be thoroughly evaluated and cleaned. This initial stage of data observability ensures that data quality is maintained from the start, preventing errors that could affect downstream processes and decisions. This use case is vital for organizations that rely on accurate data to drive business operations and strategic decisions.
2. Data Ingestion
Continuous monitoring during data ingestion ensures that updates to existing data sources are accurate and consistent. Finding Anomalies in regular tasks, such as loading CRM data, is critical to catching issues early. Data ingestion observability helps organizations avoid costly mistakes when poor-quality data is used in critical business processes.
3. Production
During the production cycle, it’s crucial to oversee processes involving multiple tools and datasets, such as dashboard production or warehouse building. Observability in this phase ensures that all components function correctly and that the correct data is delivered to end-users, maintaining the integrity of delivered insights and operational outputs.
4. Development
The development phase involves integrating new code, tools, or configurations. Data observability here includes conducting regression tests and assessing the impact of these changes. This ensures that any new integration or code alteration does not adversely affect the existing systems, thus safeguarding the overall system integrity.
5. Data Migration
Data migration, especially during projects like cloud transitions, requires meticulous checking to ensure that migrated data matches the legacy data in terms of output and functionality. Observability during migration verifies data accuracy and functionality in the new environment, ensuring seamless transitions with minimal data loss or corruption risk.

Read The Entire Blog Series
Each use case presents unique challenges and requires specific strategies to ensure data health. By following our detailed blog posts on each use case, readers can better understand how to implement effective observability strategies tailored to different data lifecycle stages. These posts will explore practical approaches, tools, and tips for enhancing data observability in your operations. We invite you to explore each of these use cases in further detail in our subsequent posts, where we will provide comprehensive insights and actionable advice on implementing data observability effectively. Stay tuned to transform your data management practices with enhanced observability!
Next Steps: Download Open Source Data Observability, and Then Take A Free Data Observability and Data Quality Validation Certification Course



