Ensuring the accuracy and timeliness of data ingestion is a cornerstone for maintaining the integrity of data systems. Data ingestion monitoring, a critical aspect of Data Observability, plays a pivotal role by providing continuous updates and ensuring high-quality data feeds into your systems. This blog post explores the challenges and solutions associated with data ingestion monitoring, focusing on the unique capabilities of DataKitchen’s Open Source Data Observability software.
NOTE
The Five Use Cases in Data Observability
Data Evaluation: This involves evaluating and cleansing new datasets before being added to production. This process is critical as it ensures data quality from the onset.
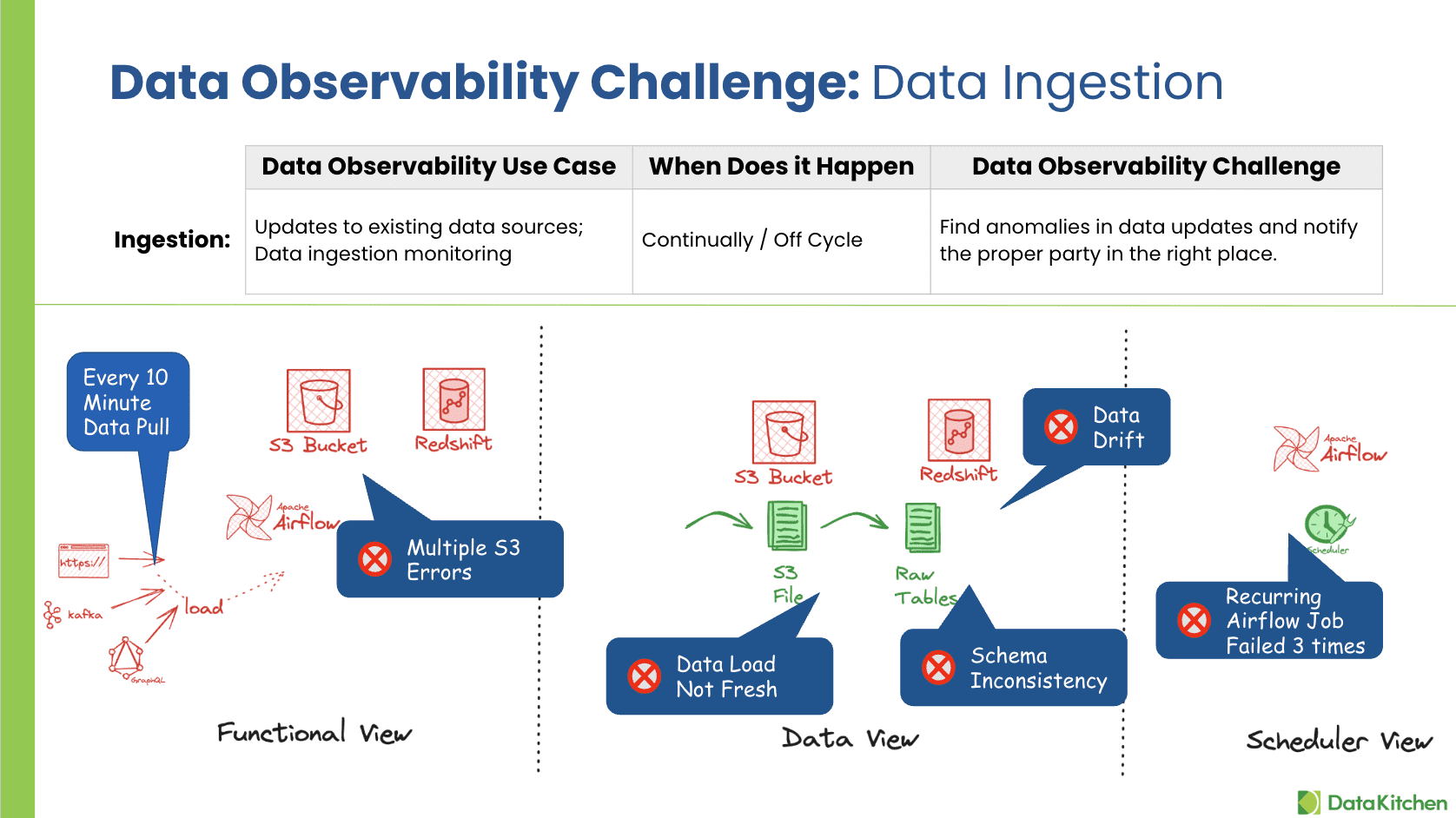
Data Ingestion: Continuous monitoring of data ingestion ensures that updates to existing data sources are consistent and accurate. Examples include regular loading of CRM data and anomaly detection.
Production: During the production cycle, oversee multi-tool and multi-data set processes, such as dashboard production and warehouse building, ensuring that all components function correctly and the correct data is delivered to your customers.
Development: Observability in development includes conducting regression tests and impact assessments when new code, tools, or configurations are introduced, helping maintain system integrity as new code of data sets are introduced into production.
Data Migration: This use case focuses on verifying data accuracy during migration projects, such as cloud transitions, to ensure that migrated data matches the legacy data regarding output and functionality.
The Challenge of Data Ingestion Monitoring
Data ingestion refers to transporting data from various sources into a system where users can store, analyze, and access it. This process must be continually monitored to detect and address any potential anomalies. These anomalies can include delays in data arrival, unexpected changes in data volume or format, and errors in data loading.
For instance, consider a typical scenario where CRM data is loaded every 10 minutes or comprehensive data change captures (CDC) that track and integrate data updates. Any disruptions in these processes can lead to significant data quality issues and operational inefficiencies. The key challenges here involve:
- Detecting unexpected changes or anomalies in data updates.
- Ensuring all data arrives on time and is of the right quality.
- Verifying data completeness and conformity to predefined standards.
Critical Questions for Data Ingestion Monitoring
Effective data ingestion anomaly monitoring should address several critical questions to ensure data integrity:
- Are there any unknown anomalies affecting the data?
- Have all the source files/data arrived on time?
- Is the source data of expected quality?
- Are there issues with data being late, truncated, or repeatedly the same?
- Have there been any unnoted changes to the data schema or format?
- My Files Usually Come On Monday And Tuesday, But Sometimes A Few Are Late, And I Don’t Know
- Did We Get The Same Data Over And Over Again?
- I Did Not Get All The Data; I Only Got Part.
- Are My Files Are Truncated?
- We Usually Get 1000 Rows Of Data Every
, But Now We Get Much Less. And I Did Not Know. - They Changed The Input Data Format, And We Have Load Errors, Unknown Failures
- Cpu Has Always Been At 50%, Not It’s 95%
- Did We Get A New Table? Or did the schema change?
- I Loaded Data Into A Table, But Only A Partial Load.
- Did I Verify That There Is No Missing Information And That The Data Is 100% Complete?
- Does The Data Conformity To Predefined Values?

How DataKitchen Addresses Data Ingestion Challenges
DataKitchen’s Open Source Data Observability software provides a robust solution to these challenges through DataOps TestGen. This tool automatically generates tests for data anomalies, focusing on critical aspects such as freshness, schema, volume, and data drift. These automated tests are crucial for businesses that must ensure their data ingestion processes are accurate and reliable. The unique value of DataOps TestGen lies in its intelligent auto-generation of data anomaly tests. This feature simplifies the monitoring process and enhances the effectiveness of data quality assurance measures. By automating complex data quality checks, DataKitchen enables organizations to focus more on strategic data utilization rather than being bogged down by data management issues.
The DataOps Observability platform enhances this capability with Data Journeys, an overview UI, and sophisticated notification rules and limits. This comprehensive approach allows data teams to:
- Quickly find and rectify problematic data.
- Reduce the time spent on diagnosing data issues.
- Lower the frequency and impact of data errors.
- Get tailored alerts
Conclusion
Effective data ingestion monitoring is essential for any organization that relies on timely and accurate data for decision-making. With DataKitchen’s innovative Open Source Data Observability software, teams can ensure their data ingestion processes are under continual scrutiny, thus enhancing overall data quality and reliability. This proactive data management approach empowers organizations to avoid potential data issues.
Next Steps: Download Open Source Data Observability, and Then Take A Free Data Observability and Data Quality Validation Certification Course