Ensuring their quality and integrity before incorporating new data sources into production is paramount. Data evaluation serves as a safeguard, ensuring that only cleansed and reliable data makes its way into your systems, thus maintaining the overall health of your data ecosystem. When looking at new data, does one patch the data? Or push back on the data provider to improve the data itself? And how can a data engineer give their provider a ‘score’ on the data based on fact?
NOTE
The Five Use Cases in Data Observability
Data Evaluation: This involves evaluating and cleansing new datasets before being added to production. This process is critical as it ensures data quality from the onset.
Data Ingestion: Continuous monitoring of data ingestion ensures that updates to existing data sources are consistent and accurate. Examples include regular loading of CRM data and anomaly detection.
Production: During the production cycle, oversee multi-tool and multi-data set processes, such as dashboard production and warehouse building, ensuring that all components function correctly and the correct data is delivered to your customers.
Development: Observability in development includes conducting regression tests and impact assessments when new code, tools, or configurations are introduced, helping maintain system integrity as new code of data sets are introduced into production.
Data Migration: This use case focuses on verifying data accuracy during migration projects, such as cloud transitions, to ensure that migrated data matches the legacy data regarding output and functionality.
The Critical Need for Data Evaluation
Adding new data sets to production environments without proper evaluation can lead to significant issues, such as data corruption, analytics based on faulty data, and decisions that may harm the business. To avoid these pitfalls, it is crucial to assess new data sources meticulously for hygiene and consistency before they are integrated into live environments.
Common Challenges in Data Evaluation
Data professionals often face several challenges when evaluating new data sources:
- Profiling Data: Understanding the data’s structure, content, and quality.
- Schema Validation: Ensuring the data adheres to the defined schema.
- Detecting Anomalies: Identifying irregularities such as embedded delimited data, leading/trailing spaces, inconsistent patterns, and non-standard blank values.
- Type Validation: Confirming data types are consistent and appropriate for each column.
- Freshness and Relevance: Assessing if the data is up-to-date and relevant.
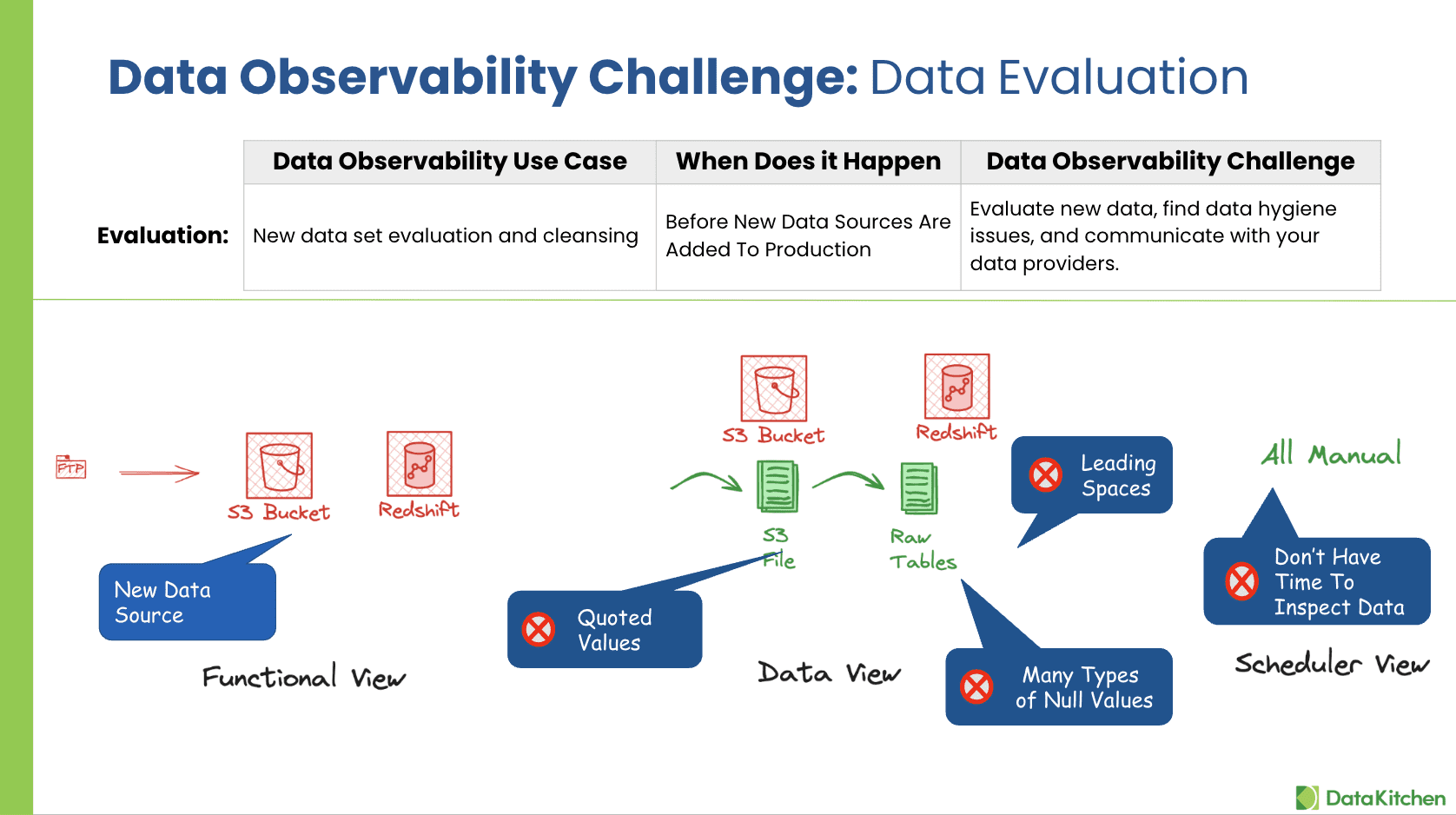
Key Data Evaluation Questions:
- Do I Understand This New Data?
- Have I Profiled The Data?
- Do I Have The Right Schema For The Data?
- Is There Delimited Data Embedded In Columns?
- Are There Leading Spaces Found In Column Values
- Are There Multiple Data Types Per Column Name?
- Are There No Column Values Present?
- Are There Non-Standard Blank Values?
- Are There Pattern Inconsistencies Within Column?
- Are Potential Duplicate Values Found?
- Are Quoted Values Found In Column Values?
- Is The Date Recent? Unlikely? Out Of Range?
- Are There A Small Percentage Of Divergent / Missing Values Found?
- What Is The Right Data Type For A Column
- Does A Column Unexpectedly Contain Boolean, Zip, Email, Or Other Values?
How DataKitchen Tackles These Challenges
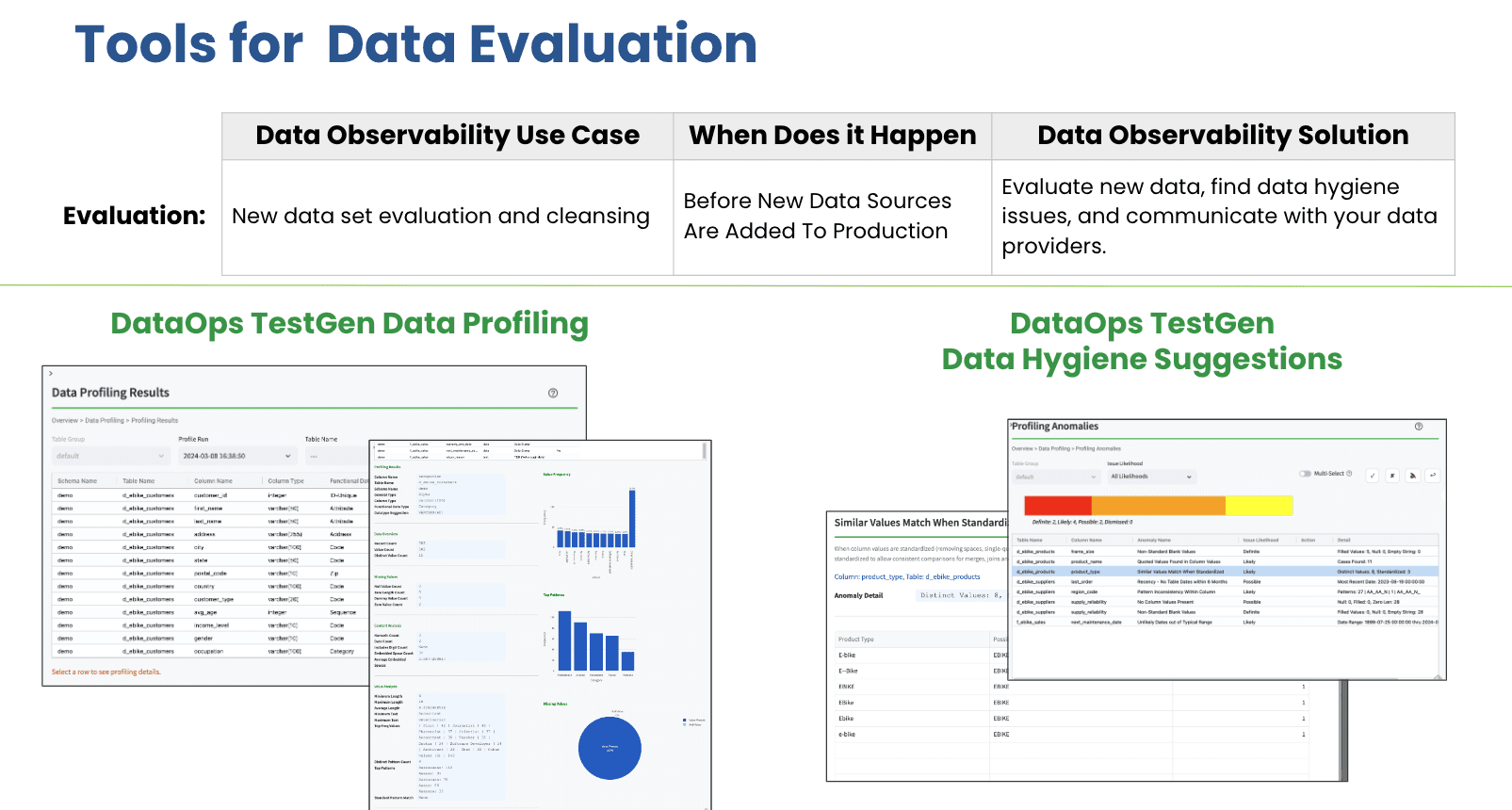
DataKitchen’s approach to solving these challenges revolves around its innovative Open Source Data Observability. Leveraging DataOps TestGen, this platform offers automated profiling of 51 distinct data characteristics and generates 27 hygiene detector suggestions. This automation and detailed scrutiny level allows teams to identify and resolve data issues earlier in the data lifecycle.
The software facilitates a comprehensive review process through its user interface, where data professionals can interactively explore and remediate data quality issues. This not only enhances the accuracy and utility of the data but also significantly reduces the time and effort typically required for data cleansing. DataKitchen’s DataOps Observability stands out by providing:
- Intelligent Profiling: Automatic in-database profiling that adapts to the data’s unique characteristics.
- 27 Automated Hygiene Suggestions: Intelligent suggestions for data cleansing based on extensive profiling results.
- Collaborative and Interactive UI: This is a platform where data teams can collaboratively review and adjust data, ensuring that only the highest-quality data enters production.
Conclusion: Getting Facts ‘Patch or Pushback’ on your Data Provider (and Boss!)
By profiling every data set and coming up with a list of data improvement suggestions, DataOps TestGen can give you fact-based evidence to your data provider (Or your boss) on what needs to be done with a new data set before you can put it into production.
The quality of your data can determine the success or failure of your business initiatives. By implementing DataKitchen’s Open Source Data Observability, organizations can ensure that new data sources are ready for production and analysis. This approach saves time, reduces errors, and significantly improves the overall data quality within your production environments.
Next Steps: Download Open Source Data Observability, and Then Take A Free Data Observability and Data Quality Validation Certification Course



