
Over the years of working with data analytics teams in large and small companies, we have been fortunate enough to observe hundreds of companies. We want to share our observations about data teams, how they work and think, and their challenges. We’ve identified two distinct types of data teams: process-centric and data-centric. Understanding this framework offers valuable insights into team efficiency, operational excellence, and data quality.
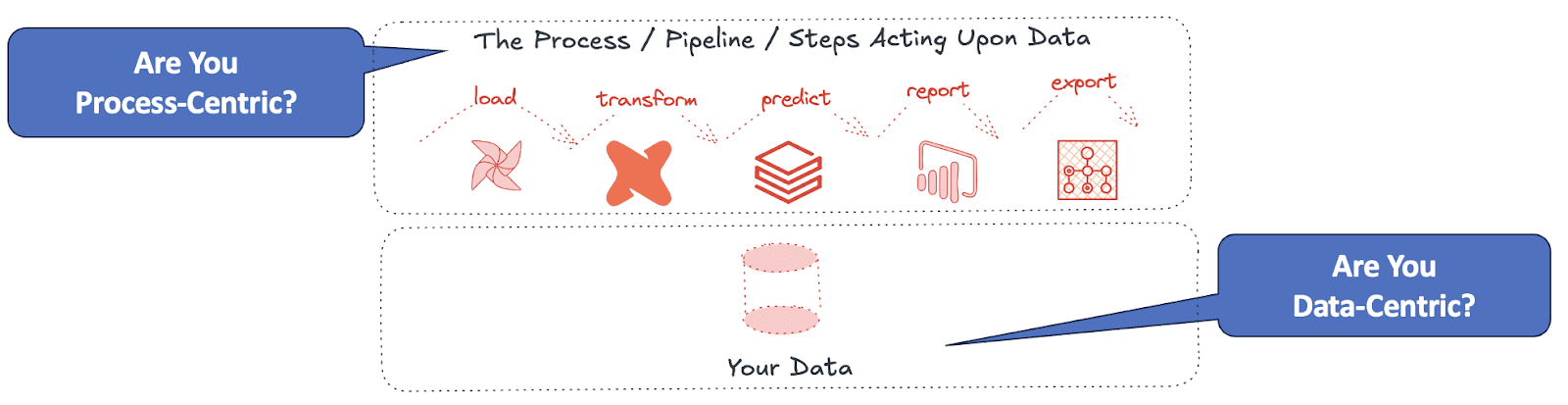
Process-centric data teams focus their energies predominantly on orchestrating and automating workflows. They have demonstrated that robust, well-managed data processing pipelines inevitably yield reliable, high-quality data. Rather than concentrating on individual tables, these teams devote their resources to ensuring each pipeline, workflow, or DAG (Directed Acyclic Graph) is transparent, thoroughly tested, and easily deployable through automation.
These teams excel because they embrace process visibility and control, believing firmly in the principles of DataOps. Their data tables become dependable by-products of meticulously crafted and managed workflows. As a result, complexity, in their view, stems from managing and orchestrating multiple processes, not from an abundance of tables. Each workflow is managed systematically, simplifying the integration of new data sources. Adding tables within an existing pipeline is manageable, posing minimal disruption. Every pipeline has embedded data quality tests, is version controlled, and is a sharable abstraction for the team to work within and deploy with low risk.
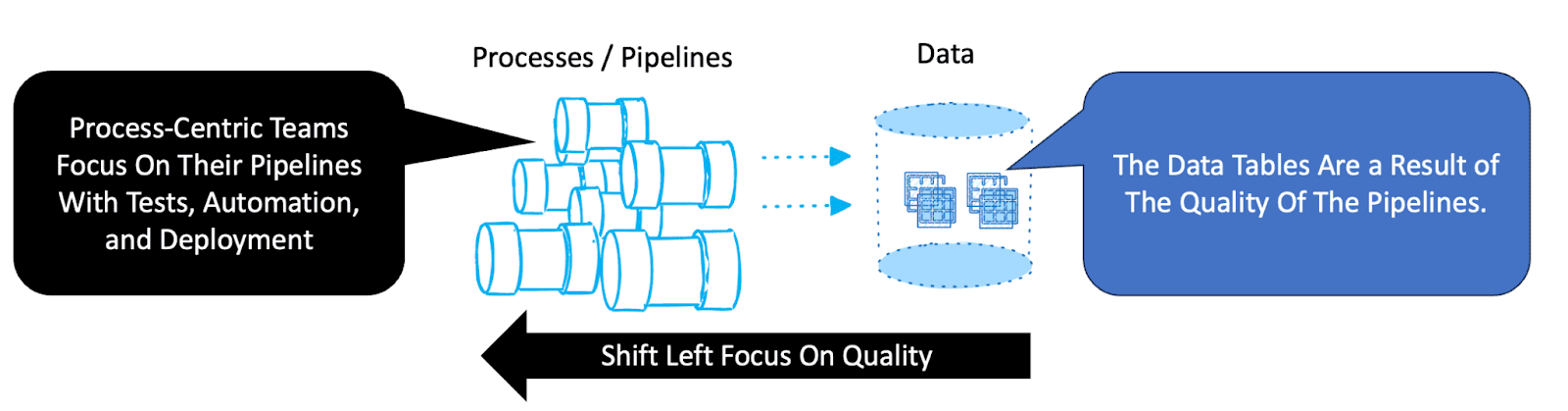
Data tables hold no emotional attachment for process-centric teams—they treat their pipelines as cattle, not pets. This mindset allows them to quickly diagnose and rectify issues at the process level rather than getting bogged down in individual data table anomalies. Their confidence comes from total control over when and how data updates occur, thanks to a unified orchestrator system. Process visibility is paramount, and data engineers are less concerned about the granular status of individual tables. Instead, their primary success metric is whether their processes run smoothly and without errors. They work in and on these pipelines. These teams, although rare, consistently achieve outstanding productivity and superior data quality.
In contrast, data-centric data teams face significant challenges due to a fundamentally different operational approach. Often burdened with numerous inherited, unmanaged, or unknown workflows, these teams are responsible for a sprawling network of data tables influenced by unknown or uncontrolled processes. Their databases feel like mysterious, daunting black boxes full of tables updated at seemingly random frequencies.
Data-centric data teams perceive complexity as directly proportional to the number of tables they manage. Each additional table intensifies their workload because visibility into data status, quality, and timeliness across hundreds or even thousands of tables is essential yet rarely achievable. Data engineers in these environments frequently react to quality issues without direct control over the processes causing the errors. This reactive stance hampers efficiency, forcing teams to patch or manually adjust data without resolving underlying process issues.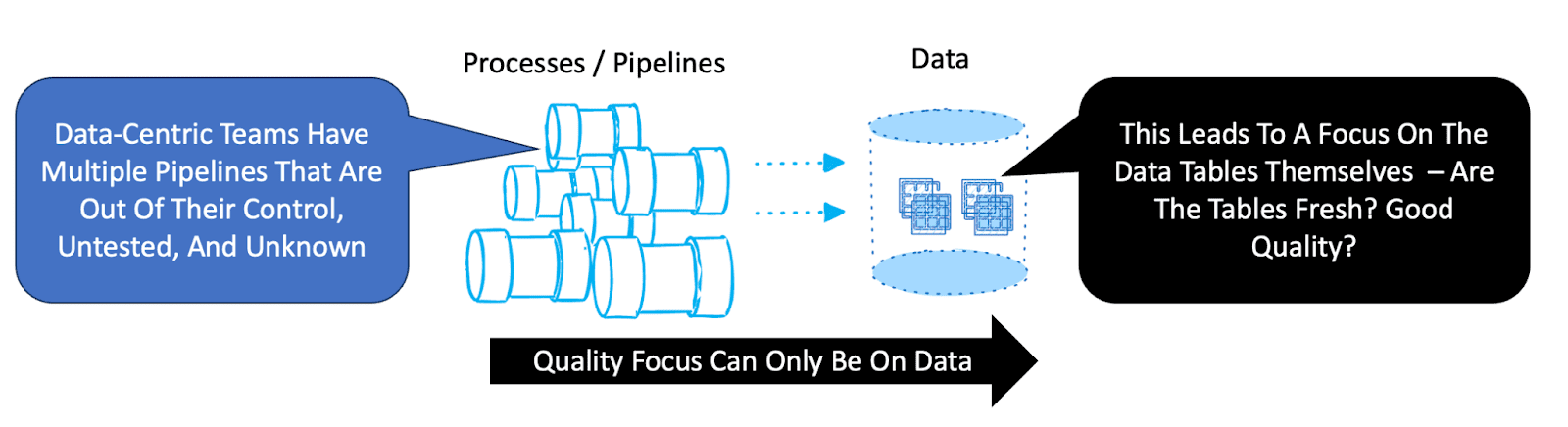
Unlike their process-focused counterparts, data-centric teams grapple with multiple orchestrators or job runners, exacerbating confusion and complicating efforts toward unified oversight. Many of these processes are out of visibility and control. They are held responsible for data errors but can’t fix or influence the pipelines that made them. These teams may be familiar with DataOps practices but struggle to implement them effectively due to time constraints, resource limitations, and demanding customers. Consequently, productivity falters, data quality remains unreliable, and the team’s morale and effectiveness decline.
Most data teams fall into this data-centric category, plagued by unclear data updates, inconsistent quality, and fragmented processes. These teams endure environments characterized by thousands of tables with uncertain update schedules and questionable accuracy. They may only control a few of their data input processes. The cumulative result is a pervasive inability to reliably answer the fundamental question: “Are our tables in good shape?” And it’s harder still to answer the more important question: “Will they be in good shape tomorrow?”
Reflecting on these two paradigms provides clarity for data engineering leadership on how best to structure, empower, and optimize their teams. Though challenging, transitioning toward a process-centric approach is achievable, yielding significant benefits in data quality, operational efficiency, and team satisfaction. Leaders committed to this transformation must prioritize unified orchestration, process transparency, and rigorous adherence to DataOps principles.
Fortunately, no matter what type of team you currently belong to, there are actionable ways to adopt and integrate DataOps principles. Small, incremental steps such as consolidating orchestration tools, creating and implementing automated tests, and increasing process observability can drive meaningful progress. Embracing DataOps practices is a journey that will enhance your team’s capabilities, improve data reliability, and significantly boost morale and productivity. The path to better data management is accessible and rewarding, regardless of your starting point. Together, you and your team can successfully transform your approach and enjoy the benefits of becoming more efficient, productive, and confident in your data operations.
DataKitchen started promoting DataOps by first building its DataOps Automation Product, a fantastic tool for process-centric data teams. We have also used it with DataKitchen’s Managed customers for years, achieving excellent quality and fantastic data engineer productivity.
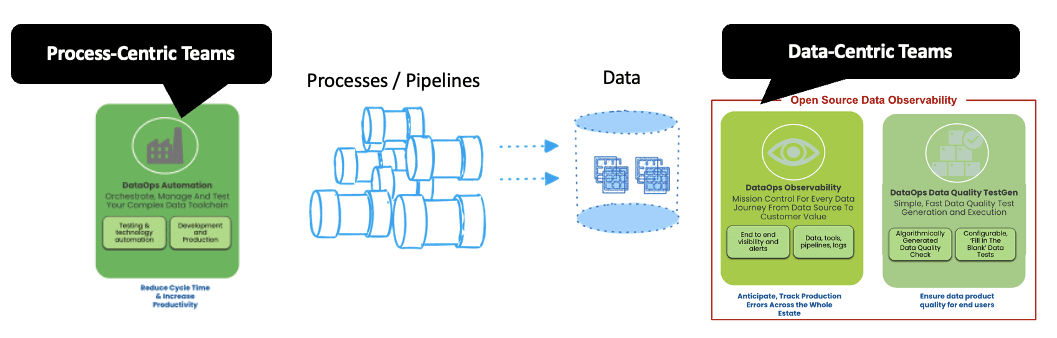
Many teams are data-centric, not because they want to be but because they have inherited a complex system of legacy data processes, pipelines, and tools. The authors of those workflows have left the building, and customers look to them when there are data problems. Over the years, we have also been helping data-centric data teams. DataKitchen’s DataOps Data Quality TestGen and DataoOps Observability are open source, easy to use, and improve the quality and visibility of your ‘dastardly dark data.’ We look for teams with thousands of tables with unknown updates/changes, unknown update frequency, unknown data quality, and no ability to tell if anything is wrong before their customer finds the problem. Check it out today!



