
10x Your Data Engineering with AI: Practitioner Patterns That Actually Work
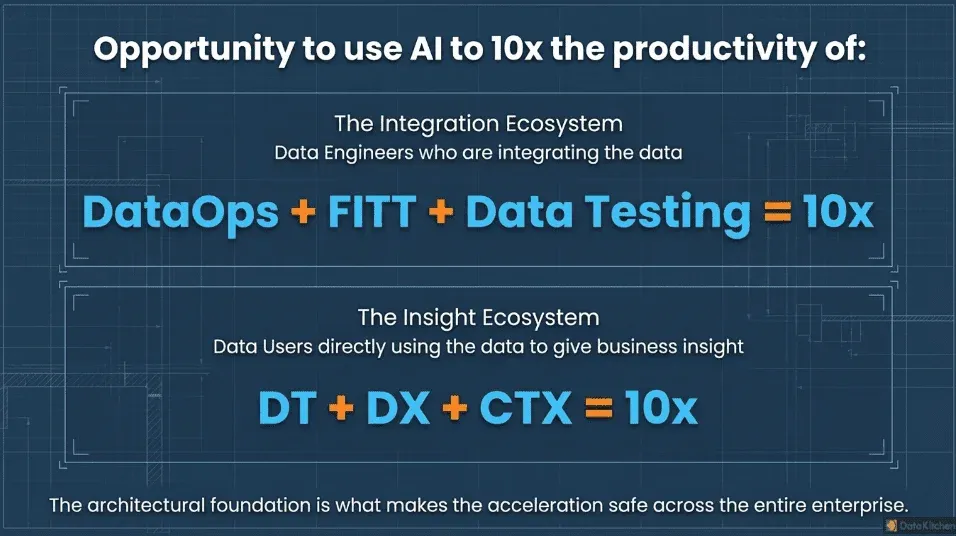
Claude Code ( DataOps + FITT + Data Testing ) = 10x Data Engineering Productivity
AI coding tools like Claude Code are generating significant excitement in software engineering. But for data engineers, getting 10 times the productivity isn’t automatic. Just adding an AI agent to a messy pipeline and hoping it works usually leads to frustration.
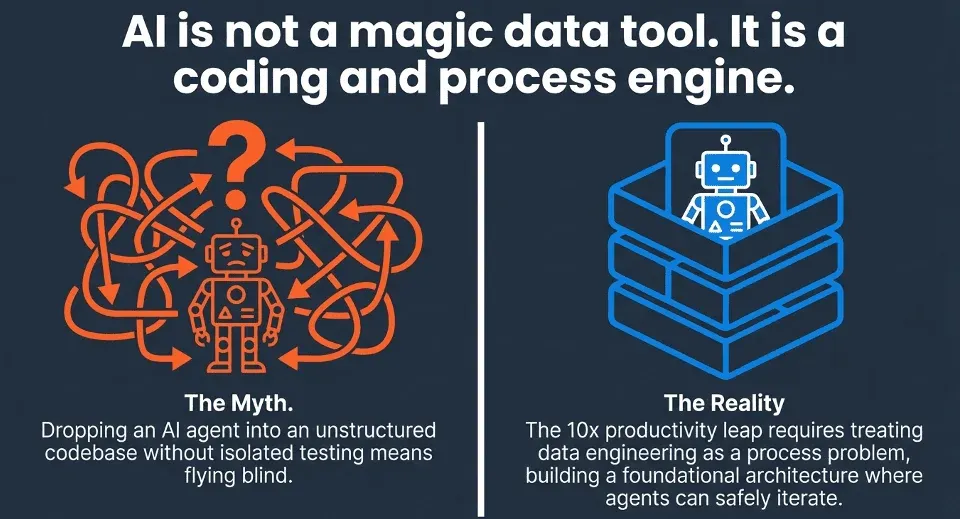
At DataKitchen, we use Claude Code every day in our data engineering consulting work. We’ve found that the productivity boost is real, but it means changing how you approach your work. Most data teams focus on data itself: tables, metadata, schemas, and datasets. Claude Code isn’t a data tool; it’s about coding and processes acting upon data. To get the most out of it, you need to think like a process-centric data team, organizing work around pipelines, workflows, and transforms instead of just tables. Once you do that, the right foundation becomes clear: DataOps principles, FITT data architecture, and solid data testing all working together.
We summed up what makes this combination effective in a simple equation:
Claude Code(DataOps + FITT + Data Testing) = 10x Data Engineering Productivity
In this post, we’ll break down each part and explain why all three are needed to unlock AI-assisted data engineering’s full potential.
Why AI Alone Is Not Enough
Claude Code is genuinely impressive. Given a clear task, it can write SQL transforms, build ingestion logic, debug schema mismatches, and keep iterating on solutions for 20 minutes or more without human input. But capability alone is not enough. An AI agent working in a messy codebase, without isolated environments or tests to validate its output, has no reliable way to know whether what it produced is correct.
Understanding why requires understanding how Claude Code actually works. It does not write code once and hand it over. It operates in an agentic loop: writing a solution, running it, reading the output, diagnosing what broke, and trying again. That cycle repeats until the output satisfies the goal. The iterations happen quickly, and the intermediate failures are invisible to the user, so the result can feel instantaneous. But what is actually happening is disciplined, self-directed trial and error, closer to how a skilled developer thinks than to how a code autocomplete tool operates.
That loop only works when the environment supports it. If Claude is iterating against a shared production database, every failed attempt is a risk. If there are no tests, Claude has no signal for when it is done or whether it has regressed something upstream. The agentic loop and the infrastructure underneath it are not separate concerns. One depends entirely on the other.
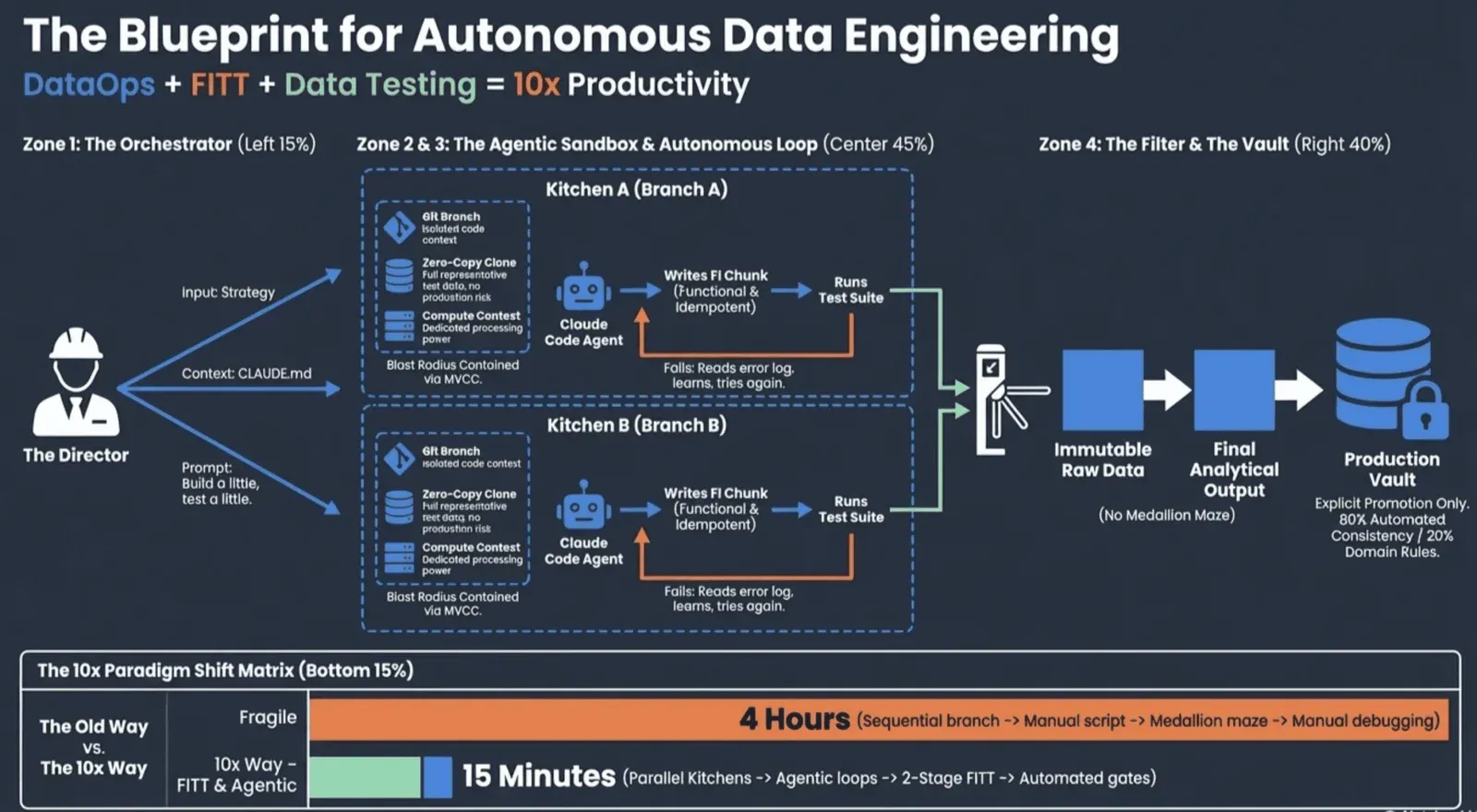
The data engineers getting 10x results have invested in the scaffolding that makes the loop safe and productive. That scaffolding has three layers
Layer 1: DataOps
The Trust Problem
Even as AI capabilities improve rapidly, most enterprises are not ready to let agents loose on production data. The fears are concrete and legitimate: an agent accidentally dropping a table, polluting the data lake with hallucinated outputs, or silently corrupting a dimension that feeds downstream reporting. These are not hypothetical failure modes. They are the natural result of handing a powerful autonomous tool access to infrastructure that was never designed for agent access patterns.
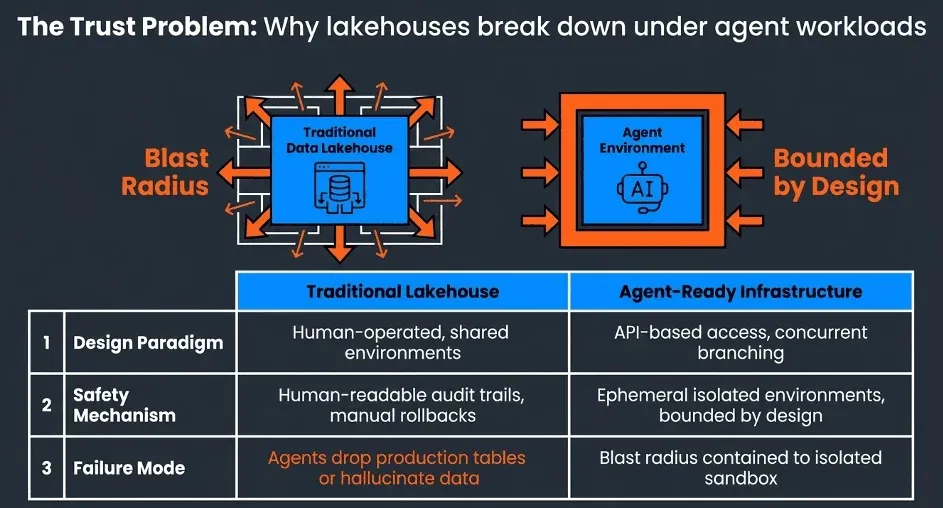
This trust gap is the real blocker for agentic data engineering adoption. It is not a capability problem. Claude Code can do the work. It is an infrastructure problem. Traditional lakehouses were built for human-operated workflows with human-readable audit trails and human-managed rollback procedures. AI Agents like Claude Code need something different.
NOTE
The path to trustworthy agentic workflows starts with solving the infrastructure problem first. Design the data environment around agent access patterns, and governance follows naturally. Try to bolt governance onto an environment that was not designed for agents, and you are constantly fighting the architecture.
The Solution: Isolated Environments
DataOps is the application of Agile and DevOps principles to data work. The DataOps Cookbook is the definitive guide to these principles, and for AI-assisted data engineering, the most critical concept it surfaces is environment branching, not just code branching. Claude Code works through trial and error. Given a task, it will attempt a solution, run it, evaluate the result, and try again. This iteration loop can run for 30 minutes, an hour, or longer. During that time, you do not want it touching your production environment or your main branch.
The key insight is that correct concurrent AI workloads require solving the data, compute, and code branch isolation through a unified API. This is the same problem that database systems solved decades ago with MVCC (Multi-Version Concurrency Control). MVCC is the mechanism that gives each database user the illusion that they are the only user of the system. Every transaction sees a consistent snapshot of the data. Changes are isolated until committed. Other users are never exposed to work in progress.
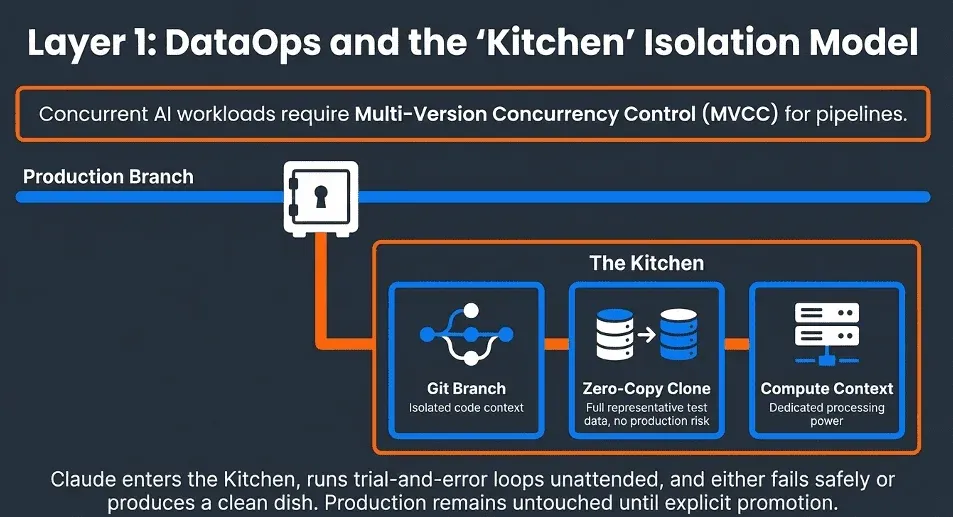
The same principle applies to AI agent environments. Each Claude session needs its own isolated view of the data and codebase, where it can read, write, experiment, and fail without any of that activity being visible to other sessions or to production. At DataKitchen, we call these isolated environments Kitchens. Each Kitchen bundles together three things Claude needs to work autonomously: a Git branch of the pipeline code, a pointer to the correct test data, and a separate compute environment. The test data itself is typically provisioned as a zero-copy clone of production, so Claude has a full representative dataset to run against without touching real data. Claude enters the Kitchen, writes or modifies a transform, runs it against the cloned dataset, evaluates whether the tests pass, and tries again if they do not. That loop repeats, unattended, until the work is done or Claude surfaces a genuine decision it cannot make alone. Production never sees any of it until the work is explicitly promoted.
NOTE
Think of it as an ephemeral Kitchen for AI agents to work in. You can spin up many Kitchens for many agents simultaneously, each one cooking up a different approach to the same problem. Once their test cooking is complete, you evaluate the results, select the best dish, and promote it to production. The others get discarded. No mess, no risk, no cleanup.
Because Kitchens are fully isolated, there is nothing shared between them that could cause interference. A single engineer can run three or four Claude Code sessions in parallel, each on a different terminal, each working in a different folder, each mapped to a different Kitchen and Git branch, each taking a different approach to the same problem. They run unattended. Claude writes, tests, iterates, and either finishes or flags for human input. When you come back, you have multiple completed attempts to evaluate side by side rather than one sequential result. The orchestration is still yours: you set the brief for each Kitchen, they cook, you judge. But the execution is fully parallel and fully autonomous. The engineer’s role shifts from writing pipeline code to directing a team of agents.
This isolation collapses the governance challenge down to a well-understood pattern: API-based access control. Instead of trying to audit every action an agent takes against a shared lakehouse, you control what the agent can do by controlling what the Kitchen API exposes. The agent can only see what it is given access to. It can only write to its own isolated context. The blast radius of any mistake is bounded by definition. DataKitchen’s DataOps Automation platform provides this unified API, giving teams the infrastructure to run autonomous Claude sessions safely without rearchitecting their entire lakehouse from scratch. That way, Claude can try new SQL, a variation of Python Code, or a script tweak in isolation.
DataOps Automation gives you the process framework that sits on top of this. You branch your code and your environment simultaneously, so Claude works inside an isolated Kitchen with its own Git branch, test data pointer, and compute context while your main branch and production environment remain untouched. You treat data pipelines as processes rather than scripts, which makes it natural to hand off a bounded unit of work to an AI agent operating inside its own Kitchen. And you maintain full lineage of the action in an Order Run data structure, so every change Claude makes is traceable, reviewable, and revertable before anything touches production.
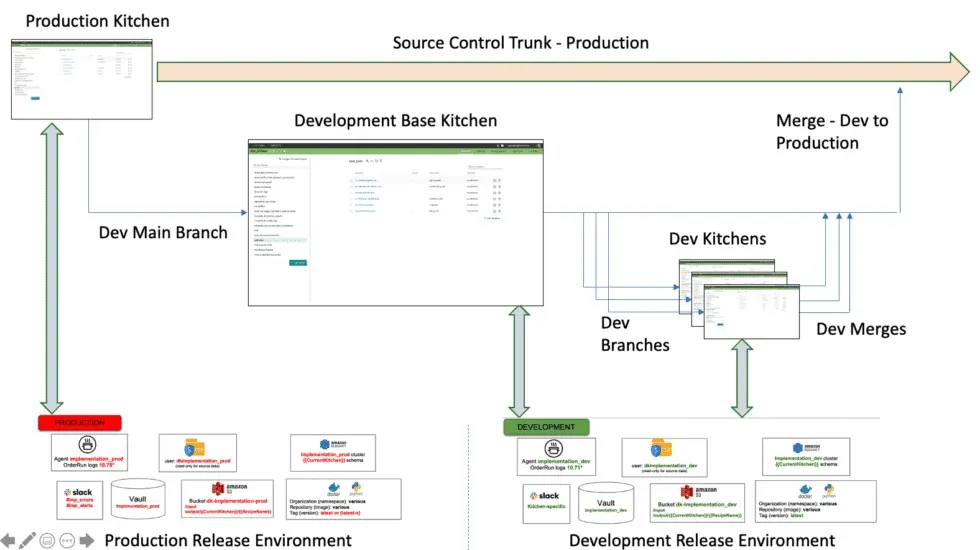
Governance of AI agents in data infrastructure is not mainly an AI issue. It is a concurrency issue. Address isolation first, and managing AI Agents becomes like overseeing multiple separate ‘kitchens’ of work. DataKitchen created its Kitchens so developers could work in isolated, aligned sandboxes and confidently combine their work. Fix the concurrency issue at the infrastructure level, and access control shifts from a complex organizational challenge to a simple API problem. This is crucial whether you have two developers or two hundred AI Agents.
Layer 2: FITT Architecture
The second layer is architectural. We call it FITT: Functional, Idempotent, Tested, Two-stage. Most data architectures are designed around vendor capabilities or medallion-layer conventions. FITT is designed around data engineer productivity and, as it turns out, AI agent productivity too. The principles that make pipelines easier for humans to reason about and recover from are precisely the principles that make them safe and productive for an autonomous agent to work on.
Functional: same input, same output, every time
A functional transform has no mystery dependencies and no hidden state. For each code version, the transformation takes clearly defined inputs and produces predictable outputs. The same input produces the same output regardless of when or where it runs. Raw data is treated as immutable by default. Functional Data Engineering eliminates an entire class of bugs that plague traditional data systems: no more wondering whether yesterday’s transformation affected today’s results, no more state-dependent edge cases that only surface in production.
For an AI agent, this property is transformative. Claude can reason about a functional transform completely from its definition. It does not need to understand the history of prior runs or the current state of upstream tables. It sees inputs, it sees the expected output shape, and it can write, test, and iterate on the logic in total isolation. The transform is a mathematical function. Claude can treat it like one.
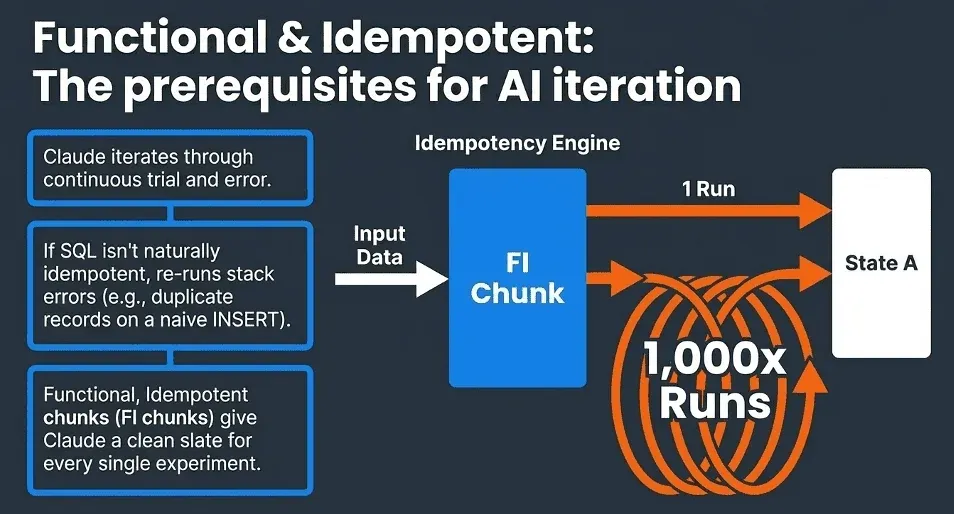
Idempotent: run it a thousand times, get the same result
Idempotency is the property that changes how the whole team thinks about failure and iteration. When a pipeline is idempotent, recovery is trivial. Did something break due to a schema change? Fix the transform and re-run it. Getting unexpected results? Re-run with debugging enabled on yesterday’s data and compare. Want to test a change safely? Re-run it on a historical snapshot. This eliminates the paralyzing fear of corrupting production data that keeps junior engineers from experimenting and keeps senior engineers up at night.
The practical implementation challenge is that SQL is not naturally idempotent. A naive INSERT run twice creates duplicate records. A CREATE TABLE AS SELECT fails on a second run if the table already exists. Making SQL truly idempotent requires deliberate design: explicitly managing state, using parameterized time windows so transforms address a specific data snapshot rather than assuming current state, and structuring each transform as what the FITT vs. Fragile SQL article calls an ‘FI chunk’, a Functional and Idempotent chunk that becomes the fundamental building block of a FITT-compliant pipeline. Whether you are using dbt, Databricks, Snowflake, or BigQuery, the goal is the same: each chunk manages its own state, declares its dependencies explicitly, and can be safely re-executed at any time.
For Claude, idempotency is not a nice-to-have. It is the property that makes autonomous iteration possible at all. Claude’s approach to any task is trial and error: write a solution, run it, evaluate the result, adjust, and try again. That loop only works if every run starts from a known state and produces a deterministic result. Without idempotency, Claude’s re-runs stack errors on top of each other. With it, each iteration is a clean experiment.
NOTE
The FITT blog describes this as a ‘build a little, test a little, learn a lot’ development rhythm. That rhythm is exactly how Claude Code works. The architecture and the agent’s working style are designed to work together.
Two-stage: raw to final, that is it.
Most teams inherit a multi-layered medallion architecture where bronze data does not match gold data, and debugging at 2 AM means tracing discrepancies across 5 intermediate layers. FITT replaces this with two stages: raw data that represents exactly what arrived from source systems —immutable and timestamped —and final data that is the complete analytical output rebuilt from that raw layer—no bronze, silver, gold, or platinum in between. The complete rebuild approach reconstructs the entire analytical dataset from immutable raw sources in a single orchestrated pass. If you need to verify last month’s results or backfill three months of data after a bug fix, you adjust the time window parameters and re-run. The process is identical whether you are processing one day or one hundred.
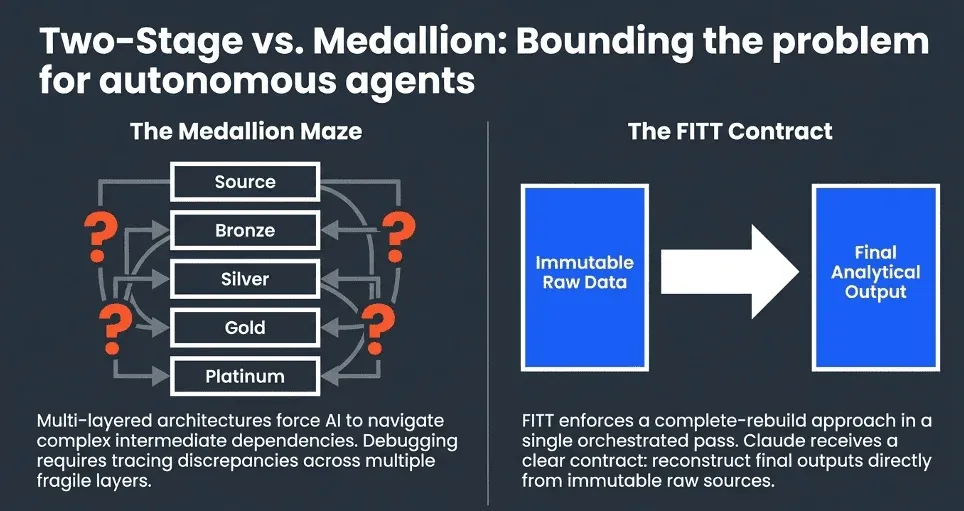
This simplicity is a significant advantage for AI agents. A Claude session working inside a Kitchen does not need to understand which intermediate layer it is allowed to modify or which upstream tables are shared with other pipelines. It works with raw inputs and produces final outputs. The Two-stage contract is clear, bounded, and easy to test.
NOTE
FITT is what makes Claude’s problem-solving granular enough to succeed. An FI chunk has clear inputs, a clear expected output, and tests that define what ‘done’ means. Claude can pick one up, iterate on it in isolation without fear of breaking anything else, and know exactly when it has finished. That is the fundamental unit of autonomous AI data engineering.
The FITT architecture is similar to the write-audit-publish pattern that Netflix first talked about. Claude writes to its isolated Kitchen environment, audits the result against the test suite, and only promotes data forward when the checks pass. FITT provides autonomous quality control built into its architecture, not bolted on afterward.
Layer 3: Data Testing
This is arguably the most important layer, and the most underinvested in most data teams.
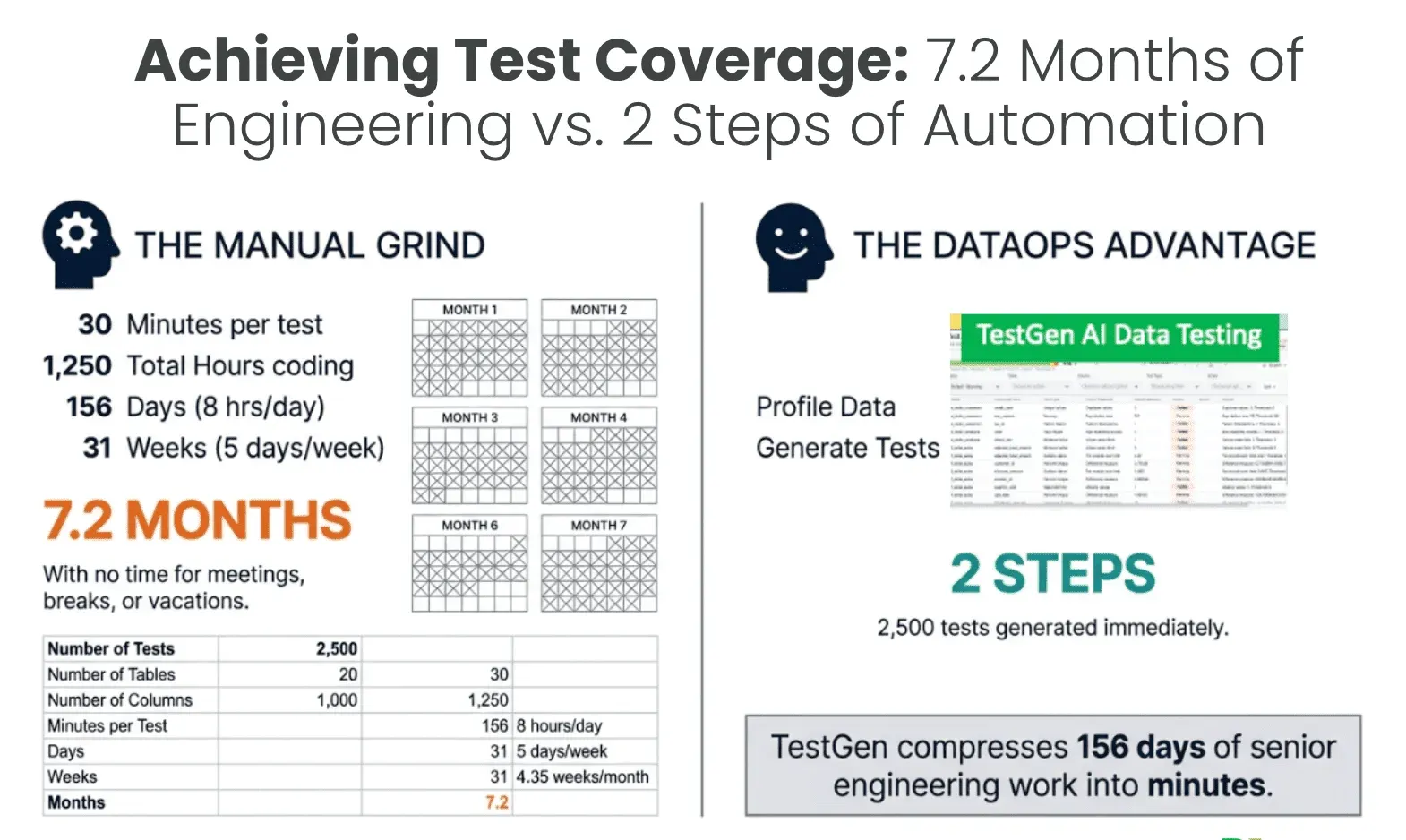
Claude Code can generate code. It can run code. What it cannot do on its own is judge whether the output is correct. That judgment has to come from data tests. Without adequate test coverage, an AI agent has no feedback loop. It cannot learn from its mistakes, cannot verify its progress, and cannot know when it is done. Our Definitive Guide to Test Coverage for Data Engineers goes deep on what a real coverage strategy looks like across every layer of your pipeline.
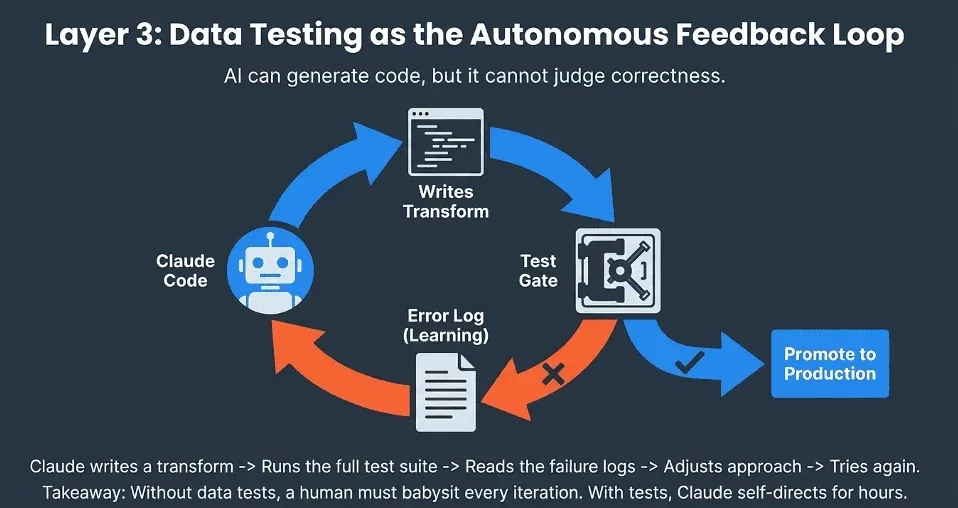
What adequate test coverage means in practice
The Definitive Guide frames test coverage around two complementary strategies: shift left and shift down. Shifting left means running data quality tests earlier in the pipeline lifecycle, catching problems before they propagate downstream and become exponentially more expensive to fix. The 1:10:100 rule captures the stakes: preventing a data quality problem at the source costs roughly $1 per record; fixing it midstream costs $10; cleaning it up after it has reached customers costs $100. Shifting down means going beyond unit-level validation to integration and end-to-end testing that validates how components interact across the full pipeline, not just in isolation.
Comprehensive coverage operates across two distinct dimensions simultaneously. Production test coverage ensures that data quality remains high throughout live operations, catching freshness failures, volume anomalies, schema drift, and distribution changes as they happen. Development test coverage validates that code changes do not introduce regressions or break existing functionality when promoted from a Kitchen to production. Many tests serve double duty across both dimensions, functioning as both production monitors and development validators.
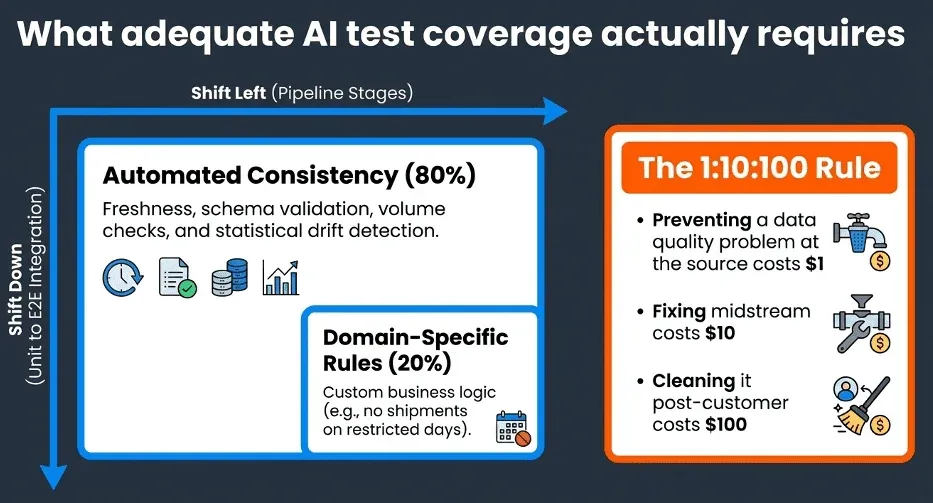
In terms of what the tests themselves cover, automated consistency tests handle the bulk of the work, roughly 80% of what a comprehensive suite needs. These include freshness and volume checks, schema validation, referential integrity, and data drift detection using statistical methods to catch gradual shifts in data characteristics that simpler threshold-based alerts miss. The remaining 20% is custom domain-specific tests that encode business rules no automated system can infer from data patterns alone: verifying that a medical practice has no more appointments than it has doctors, ensuring no shipments occur on restricted days, and confirming that revenue figures fall within historically expected ranges. Those business rule tests are where your domain knowledge becomes part of the quality gate that Claude must pass.
Representative test data is equally important. Claude needs to run against data that actually exercises the edge cases and failure modes of your pipeline. Minimal or synthetic test data can lead to false confidence. The zero-copy clone in the Kitchen exists precisely to give Claude a full, realistic dataset to work against without risking production. Development like this: yesterday’s data run against today’s code.
Tests as the AI feedback loop
Here is the workflow that makes long autonomous Claude sessions possible: Claude writes or modifies a transform, runs the full test suite against the branch, reads the failure output, adjusts its approach, and tries again.
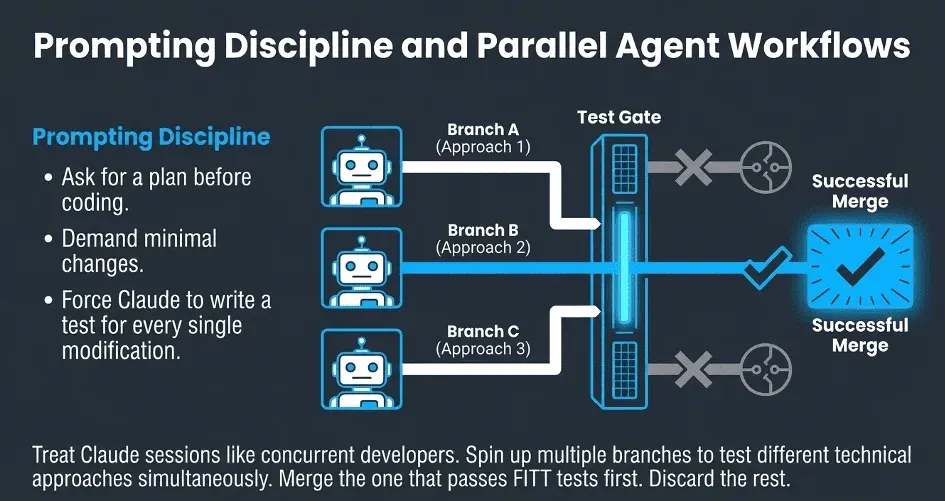
This loop can run for 20, 30 minutes, or several hours when the problem is complex. You are not babysitting it. You check back in, and either the tests are green, or Claude has surfaced a real issue that needs guidance on.
NOTE
High coverage data tests are the mechanism that turns Claude Code from a code generator into an autonomous engineering agent. Without them, you need a human in the loop for every iteration. With them, Claude can self-direct.
Data testing is how you manage AI risk. If Claude goes down the wrong path for 30 minutes, the tests catch it. Nothing ships until the tests pass. Your test suite is your safety net and your teacher simultaneously. DataKitchen’s open-source TestGen is built exactly for this: it generates thousands of data quality tests automatically from your schema and data profile, giving Claude the feedback loop it needs to work autonomously without requiring your team to hand-write every test case.
For a comprehensive treatment of how data testing and observability fit together in a modern data engineering practice, see our new book The DataOps Way to Data Quality and Data Observability.
Tips: How Data Engineers Work with Claude Code
The first thing to understand about Claude Code is that it is a CLI tool, not an IDE plugin, and that distinction matters. Claude Code manages its own persistent memory through CLAUDE.MD files that are stored in your project folders. These files are loaded automatically at the start of every session, so Claude picks up exactly where you left off without you having to re-explain your schema, conventions, or the business rules you spent 20 minutes describing last Tuesday. Every AI chat session starts with a ticking clock as context builds and earlier information is pushed out. CLAUDE.md files solve this. Use them aggressively. Ask Claude to document what it has built and what assumptions it is making so that knowledge survives session restarts, machine changes, and team handoffs. Version control those files in Git alongside your pipeline code.
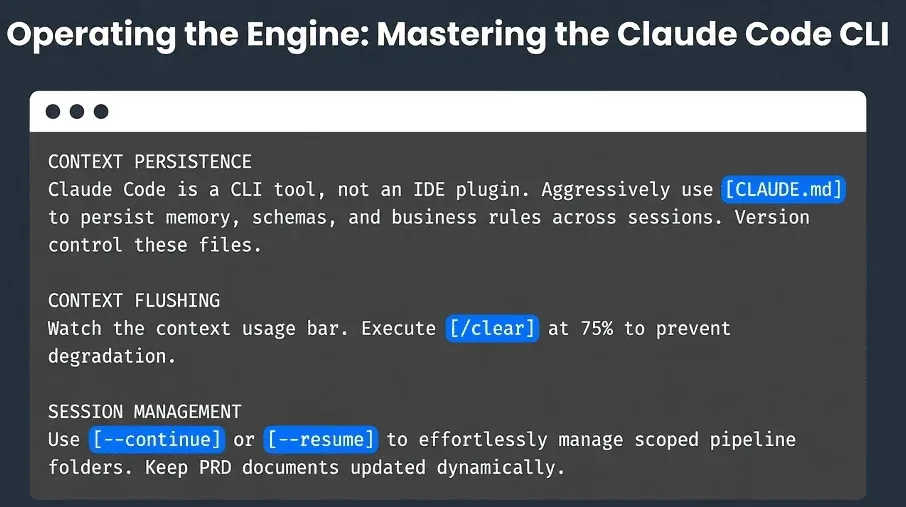
Context management is a skill you will develop quickly. Watch the context usage bar in the CLI, and use /clear when it reaches 75%. Organize your work into one session per folder, grouped by topic or pipeline stage. When you need to resume, the fastest path is claude —continue to pick up the last session instantly, or claude —resume to browse and select from named sessions. For longer-running agent workflows, create a PRD (planning document) in the folder; ask Claude to update it as work progresses. A well-maintained PRD is structured knowledge, not just chat history, and it is what allows a teammate or a fresh Claude session to step in without losing ground.
Prompting discipline makes a measurable difference. Before Claude starts any task, ask it to make a plan and review it with you before touching anything. Ask what assumptions it is making. This two-minute check prevents Claude from spending 40 minutes on an approach that misses a constraint you forgot to mention. During work, push Claude toward minimal changes: the prompt that consistently produces tighter, more reviewable diffs is simply asking for the minimum change needed to achieve the goal. After Claude makes changes, ask it to write a test that proves the changes are correct. This directly feeds the test coverage that makes autonomous iteration possible and keeps the feedback loop tight. Explicitly save work to disk before clearing context.
The highest-leverage pattern in the slides is parallel development. Think of each Claude session as a separate developer. Different folders mean different branches, and you can run multiple terminals simultaneously, each with Claude grinding on a different pipeline unit in isolation. You do not need to make perfect upfront decisions about which approach is right. Spin up two branches with two different approaches, let Claude iterate on both, and merge whichever one passes the tests first. The mental model shift is significant: you move from writing pipeline code to directing a team of autonomous agents, each working in its own safe sandbox, with data tests as the shared definition of done. Four-hour tasks become 15-minute tasks. The focus shifts entirely to what needs to be built, not how to build it.
A Walkthrough Example
A data engineer has a task: rewrite a slow, brittle SQL transform that ingests raw sales data into a final reporting table. The existing version breaks on reruns, has hidden state dependencies, and takes 40 minutes to run on a bad day. Rather than working through one approach sequentially, the engineer spins up three approaches and lets Claude explore three strategies in parallel: parameterized time windows, explicit staging-table logic, and a full-step rebuild from raw.
Provisioning the Kitchens
Each Kitchen is a bundle of three things: a Git branch forked from main, a zero-copy clone of the production dataset, and a separate compute context.
The zero-copy clone provides each Claude session with a complete, realistic, production-scale dataset to work with without duplicating storage. Each Kitchen references the same underlying production data blocks, with a copy-on-write layer on top. When Claude generates output, those changes are made to the Kitchen’s isolated layer. Production data blocks remain unchanged. The cost is nearly zero. The isolation is thorough.
The engineer opens three terminal sessions, points each at a different folder mapped to a different Kitchen, gives each a brief, and walks away.
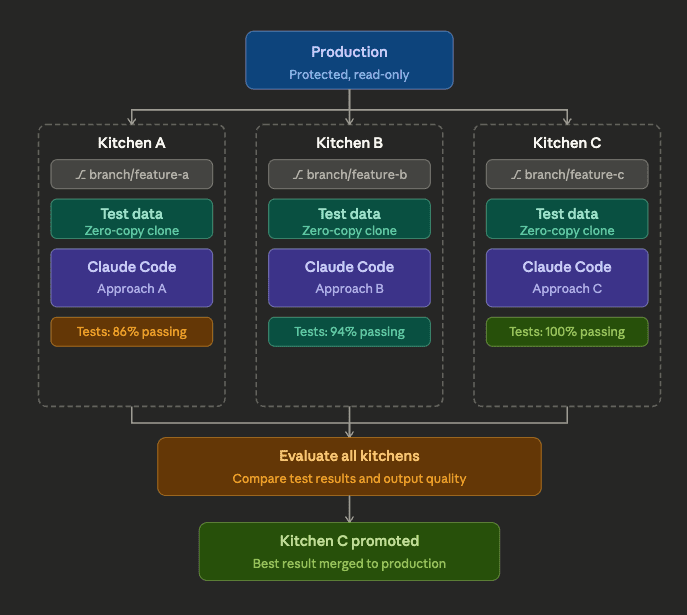
Claude Iterates in Each Kitchen
Inside each Kitchen, Claude reads the CLAUDE.md context file, inspects the schema, and starts writing. It runs the transform against the cloned dataset, evaluates the output against the test suite, reviews any failures, revises, and reruns. It does not wait for input. It repeats this process until the tests pass or it encounters a decision it cannot make on its own. Kitchen A, using the parameterized time-window approach, encounters problems with late-arriving records. After four iterations, it reaches 86%, but notes that one cross-period consistency check is still failing and may require human judgment on an acceptable tolerance. Kitchen B, employing the staging table approach, proceeds smoothly through the standard automated tests and completes at 94%. It records that the remaining failures are mainly in a single edge case involving partially fulfilled cancelled orders. Kitchen C, running the full step rebuild, takes the most aggressive route. All tests pass: 100%. It logs an 8-minute rebuild time on the cloned dataset.
Evaluation and Promotion
With test results in hand across all three Kitchens, Claude compares the outcomes. Kitchen A is eliminated: below threshold and flagged for a structural issue that would require rearchitecting the windowing logic. Kitchen B passes at 94%, but it carries a known edge-case failure that would require additional work to resolve. Kitchen C wins: 100% test pass rate, clean output, and an 8-minute rebuild cycle, well within the production schedule for a transform running every 15 minutes.
Kitchen C’s branch is promoted. The engineer reviews the diff, a clean, readable transformation built on a full rebuild from immutable raw sources following FITT conventions, and merges it into main in ten minutes. Kitchen A and Kitchen B are discarded. Their branches are deleted, their compute contexts shut down, and their zero-copy clones released. Nothing from those sessions ever made it into production.
What Just Happened
A task that would have taken a full day of sequential engineering was completed in under two hours, with three approaches explored simultaneously and the engineer’s active involvement limited to writing the briefs and reviewing the winning diff. The test suite did the continuous validation. Claude did the iteration. The engineer made the final call. That division of labor is where the 10x comes from.
The 10x Is Real, But It Is Not Magic
We want to be specific about what 10x means here. It does not mean that Claude Code writes 10x as many lines. Tasks that used to take a day take two hours. A single engineer can run multiple parallel workstreams across isolated Kitchens simultaneously. Debugging time drops sharply because tests catch errors before they propagate. Onboarding new pipeline logic is accelerated because data tests are automatically generated and document the expected behavior. And code review is faster because every diff is scoped to a FITT unit with a clear, bounded surface area.
None of this happens without the foundation. DataOps provides the branching and process discipline. FITT provides the granularity and idempotency that make autonomous iteration safe. Data testing provides the feedback loop that enables autonomous iteration.
Remove any one of the three, and the productivity gains collapse. Together, they multiply each other.
How To Get Started Today
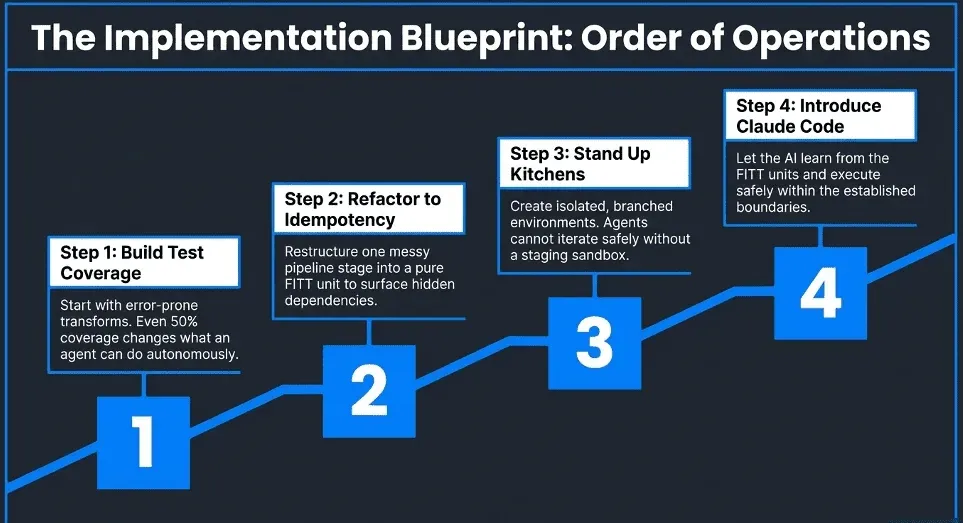
How do I start moving toward this model that enables Claude Code’s success? Build your data test coverage first. Start with the transforms that are most error-prone or most business-critical. Even 50% coverage on key transforms changes what Claude can do autonomously. Then refactor toward idempotency. Pick one messy pipeline stage and restructure it as a FITT unit. The refactor itself will surface hidden dependencies and assumptions that have been buried in the code. Next, stand up isolated branched environments. If your pipeline can only run in one place, you cannot safely let Claude iterate. Then, and only then, introduce Claude Code. With the foundation in place, the onboarding is fast. Claude learns the patterns from your existing FITT units and tests, and productive output starts immediately.
Conclusion
AI coding tools are going to change data engineering. That much is certain. The question is whether the change for your team is a genuine productivity multiplier or just a faster way to generate untested code that breaks in production.

The engineers getting 10x results are not the ones with the best prompts. They are the ones who invested in DataOps discipline, FITT architecture, and data test coverage before they picked up an AI tool. Claude Code is the accelerant. The foundation is what makes the acceleration safe.
The 10x opportunity from LLMs is not limited to data engineers. Analysts working directly with AI to answer business questions face the same foundational challenge: AI is an amplifier, and if what sits beneath it is untrustworthy, poorly documented, or missing business context, it can amplify bad answers at speed. We have a companion framework for that challenge in The Equation for AI Success: DT + DX + CTX = 10x. Where this post addresses how data engineers build the pipelines that make AI safe and productive, that one addresses how analysts make their data legible, trusted, and context-rich enough for AI to reason over it reliably. The two equations are meant to work together.
DataKitchen builds open-source tools that support this model, including TestGen for data quality testing and DataOps Automation for DataOps. If you want to see how this plays out in practice, we are happy to walk your team through it.
TIP
Want to learn more? Watch the webinar: 10x Your Data Engineering with AI: Patterns That Actually Work



