
DataOps has changed how pharmaceutical analytics teams run. The teams that get it right ship better answers, faster, with fewer mistakes. That advantage shows up most clearly in product launches, where speed and accuracy translate directly to revenue. DataOps is about eliminating errors, cutting cycle time, building trust, and gaining agility.
After a decade of drug development, the launch is the most important phase in a product’s life. The first 6 to 12 months sets the lifetime revenue trajectory. A solid early ramp puts a new medicine on track to hit its sales targets. A weak launch costs you revenue you’ll never recover. Figure 1 shows how the curves diverge.
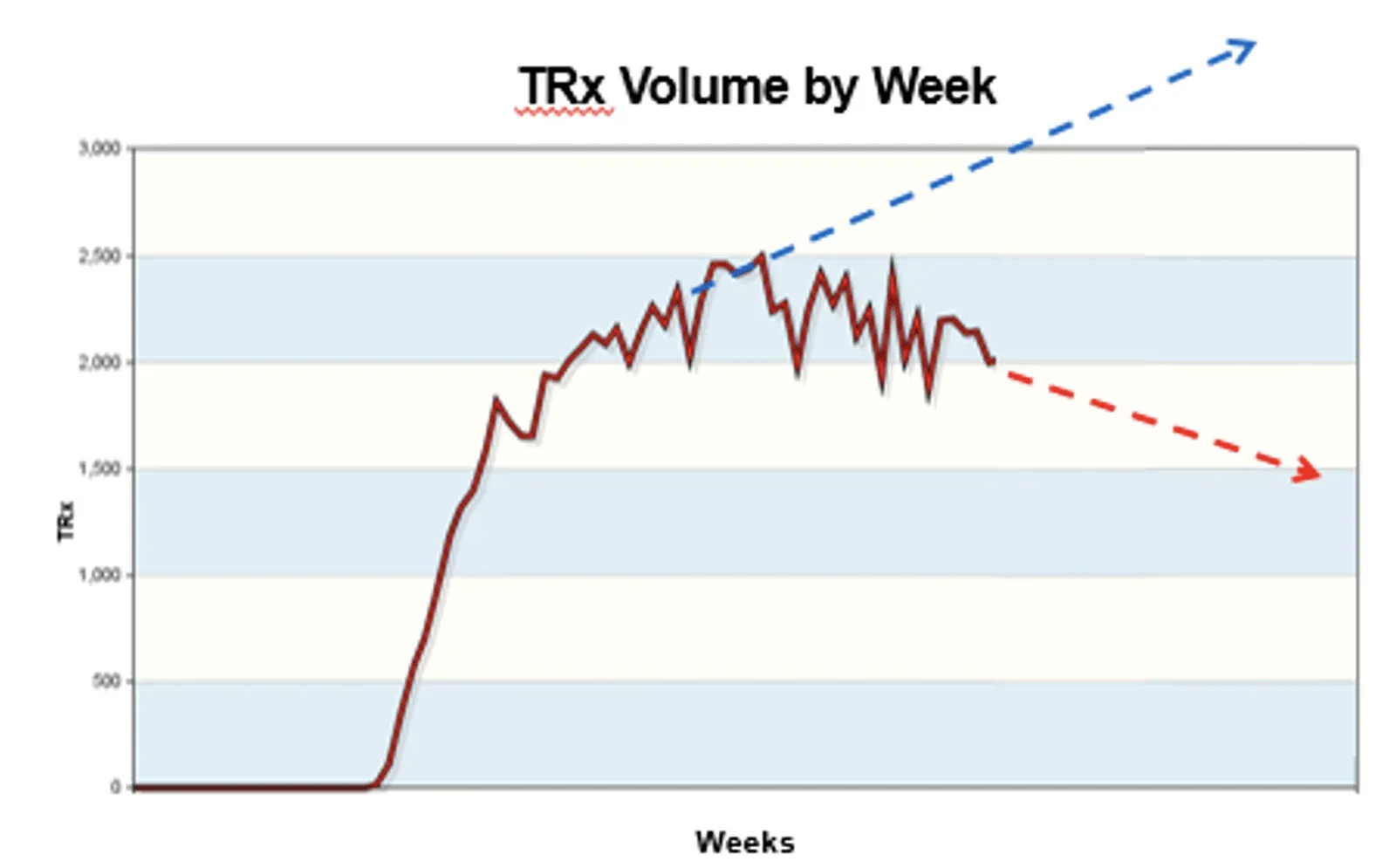
Figure 1: The first months in the product lifecycle determine its lifetime revenue.
During the launch, sales and marketing run on data. Campaigns are multi-level and analytics-driven. The work is so critical to product success that the data team often reports directly into sales and marketing.
Picture a data team of one or two dozen people serving hundreds of sales and marketing users. Each user has a territory or a campaign. They want new datasets, new dashboards, new segmentations, new cached extracts. The requests don’t stop. The clock doesn’t stop. You ship answers fast and you ship them right.
The insights flow hourly, daily, weekly, and monthly. Figure 2 shows how the data team ingests data from hundreds of internal and third-party sources.
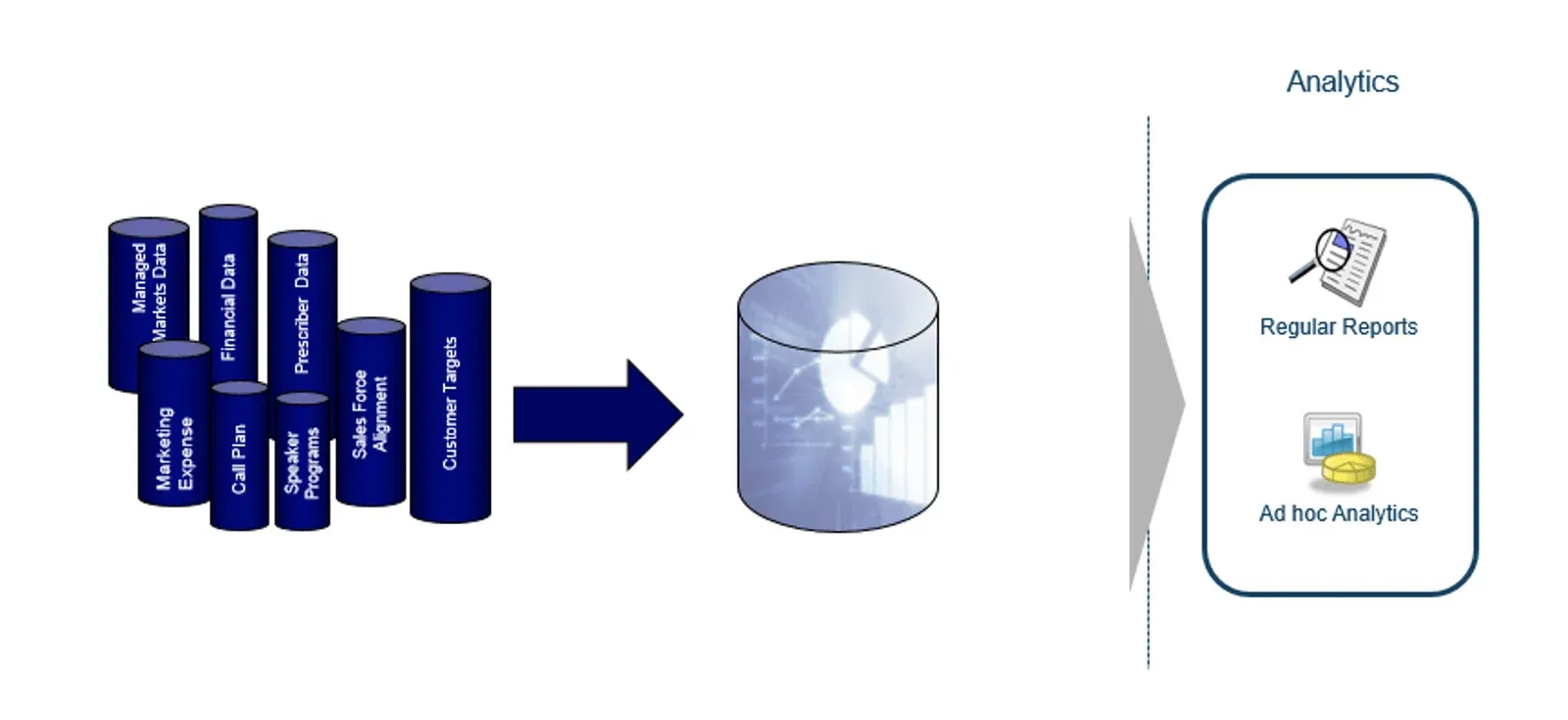
Figure 2: During the product launch, data comes from various sources and feeds into regular and ad hoc reports and analytics.
The data is messy. There are multiple lists of physicians and they don’t agree. Roughly a million physicians practice in the US, but only 40,000 are targets for a given drug. Standardizing that list matters because sales compensation rides on it.
Part of the job is judging whether a source is fit for purpose. Figure 3 shows the spread: forecasts, stocking, sales, physician, claims, payer promotion, and finance.
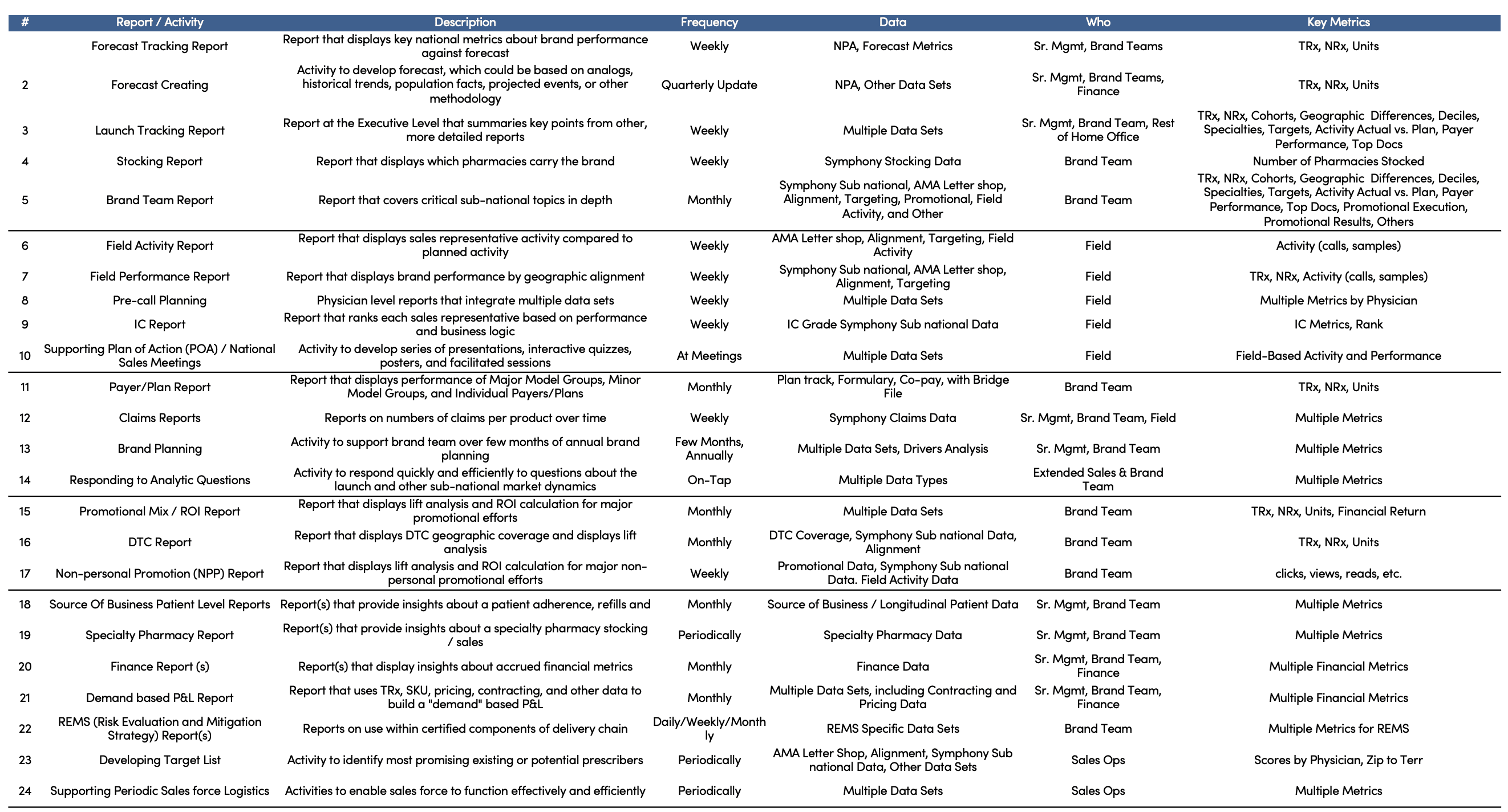
Figure 3: The vast and varied types of analytics required during the launch phase.
DataOps Success Story
The Otezla launch is a billion-dollar example of DataOps handling that complexity. Using the DataKitchen DataOps Platform, the team ran an agile shop with seven data engineers and 10 to 12 analysts. They mastered hundreds of datasets serving thousands of users with very few errors or missed SLAs. They built tens of thousands of automated tests checking data and analytics. They shipped hundreds of schema and dataset changes a week without breaking anything. Compare that to companies running hundreds of data professionals who still struggle. That’s the power of DataOps automation.
Figure 4 shows the architecture from a real biologic launch. Over seventy data sources, daily and weekly cadences. Biologic data is dirty, so the platform profiles it and runs rule-based quality checks first. Did the data arrive on time? Is the volume right? When tests pass, orchestration admits the data to the catalog.
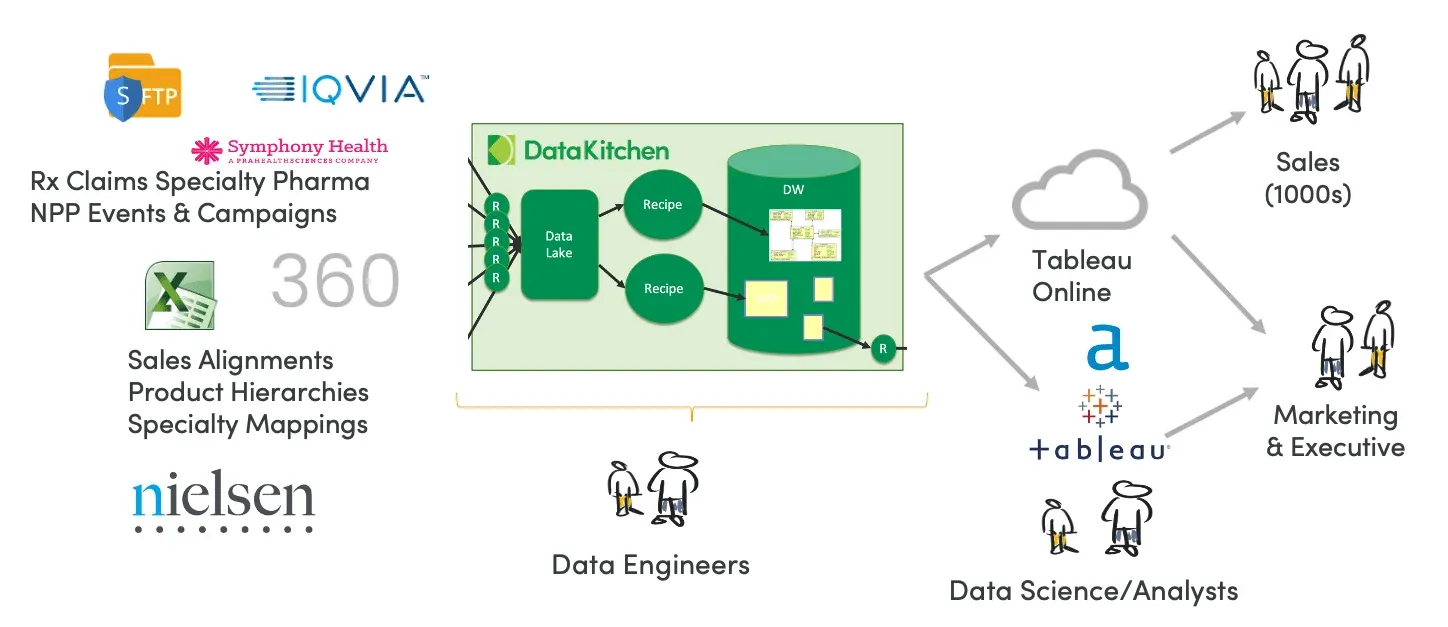
Figure 4: DataOps architecture based on the DataKitchen Platform
Reporting schemas update several times a day. Purpose-built warehouses, marts, and star views get tailored to analyst needs. When builds finish, notifications trigger refreshes of dashboards, Tableau workbooks, and whatever reports the business unit requires.
The agility shows up two ways. Production analytics refresh several times a day from dozens of asynchronous sources. And the data engineers and scientists change any part of the pipeline at any time. New datasets, new schemas, new views. The Otezla team made dozens of changes a week. Error rates stayed negligible because tests run at every stage. Observability catches problems before they hit the people consuming the analytics.
The platform replaces the army of people running manual tests, checklists, and procedures. Your team redeploys to work that creates real analytics. You ship more insight, faster. The table below shows features and benefits of the DataKitchen DataOps Platform.
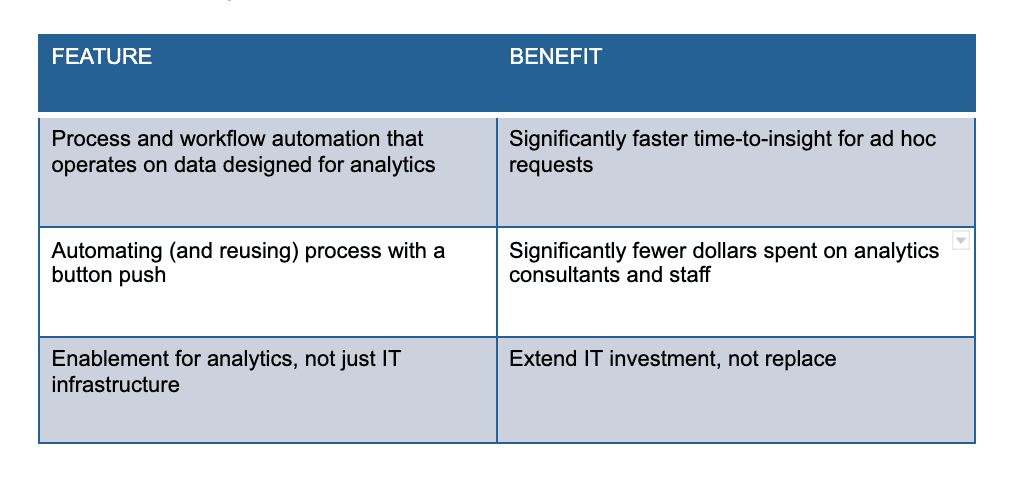
When the processes around the data are built for rapid refresh and rapid response, time-to-insight drops and ad hoc requests cost less. DataOps automation replaces the non-value-add work and the outside consultant dollars with a framework that runs efficiently and at quality. You build a factory that produces insights.
The DataOps Platform doesn’t replace your data lake or data hub. It’s the automation layer that spans the toolchain you already have. Informatica, Snowflake, Databricks. DataKitchen works alongside them and stitches them into the end-to-end data lifecycle.
The process-centric view says this: the processes that act on data are as important as the data itself. Neglect those processes and you get delays, errors, and unplanned downtime. Build for them and you get faster, more flexible analytics with almost no downtime.
DataOps Is the “New Normal” in Pharma
Otezla used DataOps automation with DataKitchen to make changes fast and ship high-quality production deliverables. They built analytics consistently across dozens of product teams. They deployed pipelines at scale, across a large group of people, spanning many tools.
DataOps is about quality assurance, automation, reusability, and repeatability. The goal is analytics agility, and analytics agility is what gets you business agility. When the analytics team works fast and accurately, decision-makers get what they need. That’s it.
Want more launch stories? Read How Three Small Pharma Companies Used DataKitchen to Achieve Commercial Launch Success and Skyrocket to $100 Billion in Acquisition Value.
Curious how DataOps can improve pharma R&D operations? Read Accelerating Drug Discovery and Development with DataOps.
This post was updated on August 27, 2025.


