A drug company tests 50,000 molecules and spends a billion dollars or more to find a single safe and effective medicine that addresses a substantial market. Figure 1 shows the 15-year cycle from screening to government agency approval and phase IV trials. Drug companies desperately look for ways to compress this lengthy time frame and to demonstrate the competitive advantage of their intellectual property. If a company can use data to identify compounds more quickly and accelerate the development process, it can monetize its drug pipeline more effectively. The capability to accelerate and streamline drug development is a tremendous competitive advantage with significant upside. Pharmaceutical companies are finding that DataOps delivers these benefits. DataOps automation provides a way to boost innovation and improve collaboration related to data in pharmaceutical research and development (R&D).
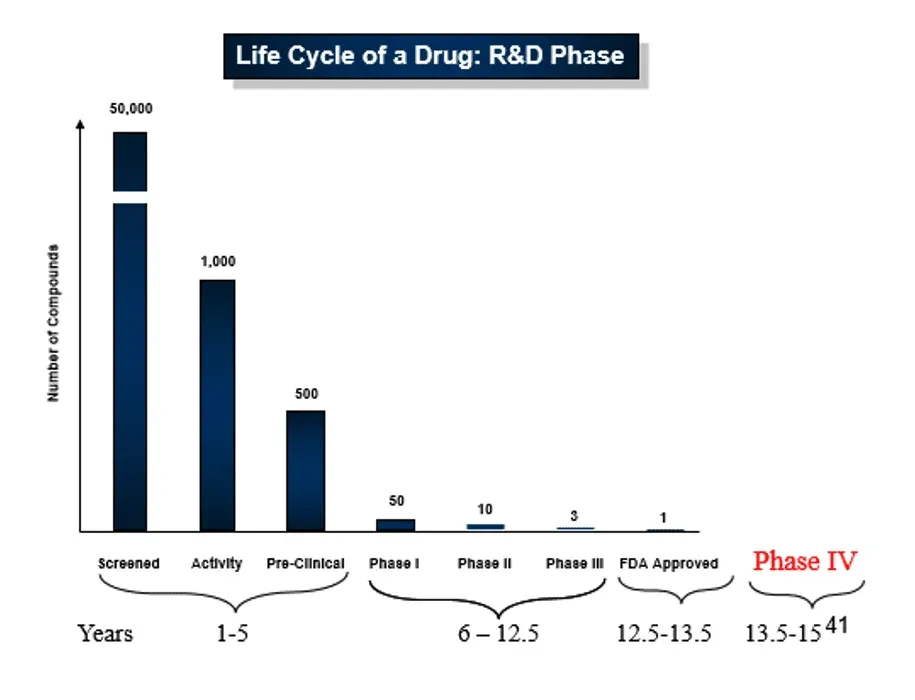
Figure 1: A pharmaceutical company tests 50,000 compounds just to find one that reaches the market.
Mastery of Heterogeneous Tools
A typical R&D organization has many independent teams, and each team chooses a different technology platform. Figure 2 illustrates a self-service DataOps Platform for scientists engaged in pharmaceutical R&D. In the example shown, one group has an on-premise toolchain, and the others use Google Cloud Platform (GCP), Azure, and Amazon Web Services (AWS). Each platform has its own set of database, ETL, visualization and other tools. Sometimes a custom tool is best for a particular job. With all this variety and lack of uniformity, it’s tough to promote consistency and reuse. How do you share best practices between different teams in a multi-language, multi-platform, multi-tool world?
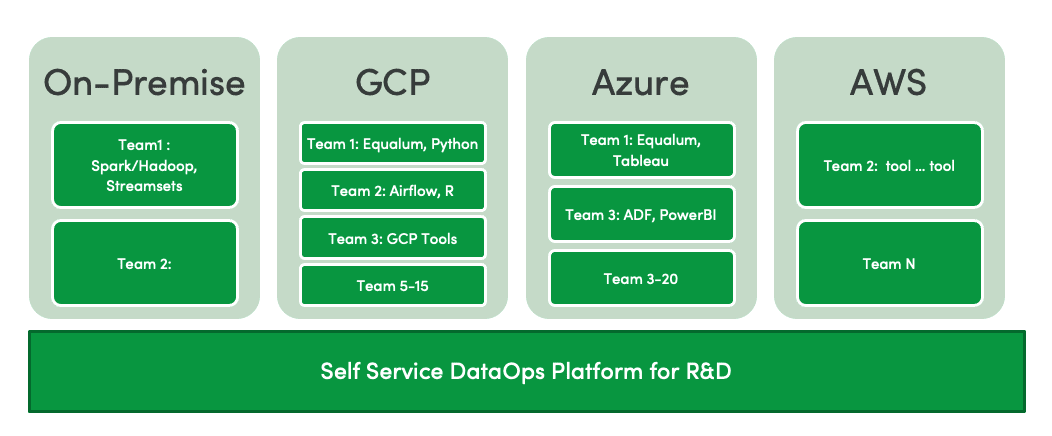
Figure 2: Different teams choose different tools when implementing self-service analytics
Figure 3 below approaches our example from a different perspective. A New Jersey (NJ) data team uses a large Spark cluster and a best-of-breed toolchain, including tools like StreamSets, on a massive set of high-value drug development data. Another R&D team in California builds their analytics on an Azure cloud platform using other tools like Databricks and other very large databases. When teams are physically decentralized and use different platforms like these, fostering collaboration can be very difficult. How can they handle schema drift or data verification? How do they share analytics and coordinate work? How do they track an error through a complex data lineage? In most cases, companies try to address these challenges with meetings and documentation, but that just frustrates everyone and slows down innovation. Inevitably, conflicts arise, and the teams lose each other’s trust.
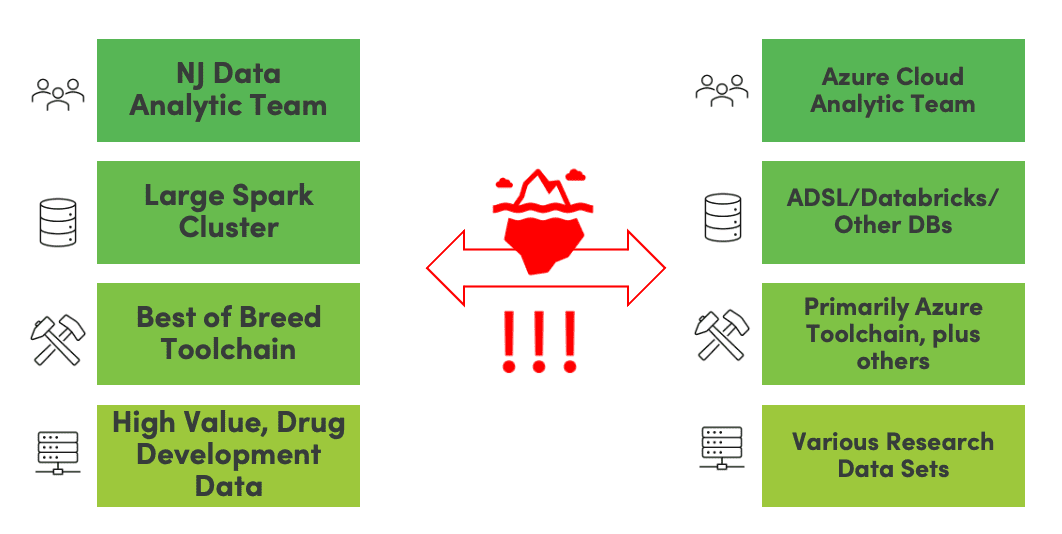
Figure 3: Inter-team coordination in a real-world pharmaceutical company.
DataOps addresses these challenges by instituting a shared process framework across toolchains, teams and data centers. DataOps ensures that local control is not sacrificed in pursuit of centralized governance. This delicate balance is maintained through a hierarchy of orchestrations that we term ” observable meta-orchestration.” Orchestration is the automation of a multistep process or workflow. In figure 4 below, we see that run-home-ingredient represents an orchestration that adds, stores, transforms and checks data for the on-prem New Jersey team.
Similarly, run-local-ingredient performs an orchestration for the cloud California team. A top-level orchestration runs these two local orchestrations and performs a schema-checker to error check the schema of data output from run-home-ingredient into run-local-ingredient. The top-level orchestration is what we call meta-orchestration. Observable meta-orchestration enhances observability by testing the quality of data at each processing stage and between orchestrations.
Observable meta-orchestration imposes governance and enforces centralization without infringing on local team independence and productivity. In our simple example, the New Jersey and California teams have total control of their local analytics and toolchains. They can iterate and publish updates freely, as long as the schema-checker passes. The two teams can use different toolchains, languages, or release cadences. The schema check frees the teams from time-consuming meetings, documentation, and sign-offs previously used to coordinate team activities.
[DataOps] takes them out of the craft world of people talking to people talking to people, and praying, to one where there is constant monitoring, constant measurement against baseline and the ability to incrementally and constantly improve the system.
– Kurt Zimmer, AstraZeneca, Head of Data Engineering inside Data Enablement (CDO Summit 2021)
Meta-orchestration is problematic for some because it requires an orchestration tool to connect seamlessly with data professionals’ vast ecosystem of tools. Unlike orchestration tools like Airflow, Azure Data Factory or Control-M, a DataOps platform like DataKitchen can natively connect to the complex chain of data engineering, data science, analytics, self-service, governance and database tools, and meta-orchestrates a hierarchy of DAGs. DataKitchen invests in that capability because of its unique role as a DataOps superstructure.
Observability is challenging in a heterogeneous environment. A DataOps superstructure provides a common testing framework. If someone from an outside team needs to write a test for the California data sets, they usually wouldn’t attempt it without Azure skills. As a tools connector, a DataOps superstructure bridges this gap. A data professional can configure tests to execute before or after a stage in a given orchestration without having to write code. Dashboards, built from fine-grain and high-level testing, ensure the quality of system-side analytics and promote micro and macro observability. Automated orchestrations also preserve log history for governance purposes.
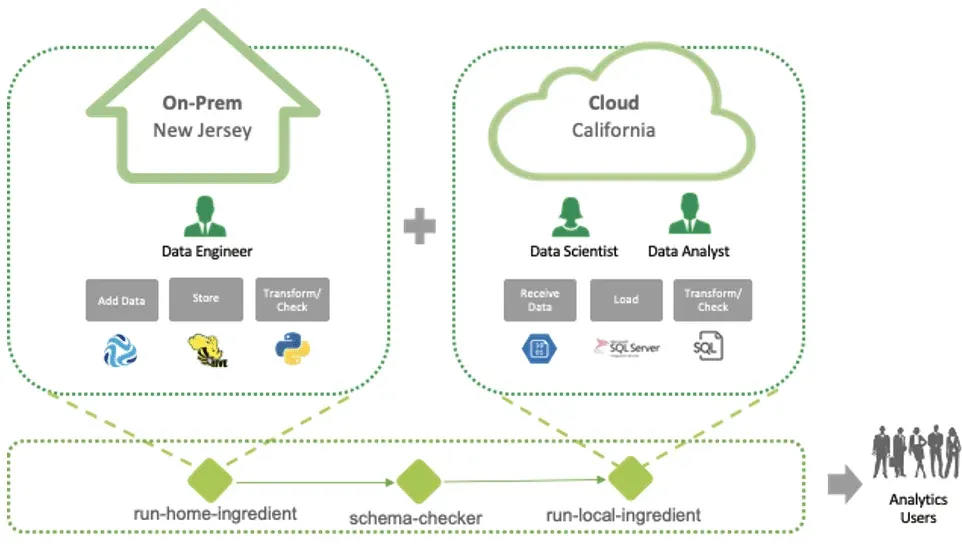
Figure 4: DataOps institutes observable meta-orchestration that balances centralization and local control.
A DataOps superstructure bridges toolchains and implements testing, monitoring and shared abstraction that assure consistency, seamless task coordination and rapid development. DataOps provides support for centralization and local control without forcing one to trade off against the other. The DataOps structure fosters greater local team autonomy, speeding the development and successful deployment of new features. DataOps process centralization, enabling the freedom to iterate in local domains, is a significant boost to analytics innovation in a growing number of pharmaceutical R&D organizations. The faster and better these organizations can sift through compounds, the more robust their product pipelines. Drug R&D is a prime example of how DataOps automation supports analytics innovation that builds and sustains competitive advantage.


