
What makes an effective DataOps Engineer? A DataOps Engineer shepherds process flows across complex corporate structures. Organizations have changed significantly over the last number of years and even more dramatically over the previous 12 months, with the sharp increase in remote work. A DataOps engineer runs toward errors. You might ask what that means. After all, we all deal with errors. Errors are an inherent part of data analytics. A DataOps Engineer embraces errors and uses them to drive process improvements.
Curating Processes
The product for a data engineer is the data set. For an analyst, the product is the analysis that they deliver for a data object. For the DataOps Engineer, the product is an effective, repeatable process. DataOps Engineers are less focused on the next deadline or analytics deliverable. We’re looking to create a repeatable process. Individual nuggets of code are fungible from our perspective. Success is all about process reliability and consistency.
The DataOps Engineer leverages a common framework that encompasses the end-to-end data lifecycle. Our goal is to seek out opportunities for reuse in the work that other data team members share with us. It can be as simple as encapsulating common joins, unions, and filters or creating views. It can also be as challenging as carving out reusable steps from orchestrations or analytics that people share with us. The goal is to identify any steps that many different people in different roles have to do repeatedly to do their work. If we can provide shortcuts, we can create leverage and give people a boost. Many organizations take weeks to procure and prep data sets. A DataOps Engineer can make test data available on demand. If we can provide shortcuts to members of the data team, we can help improve their productivity.
DataOps Engineers have tools that we apply to all of the pipeline orchestrations that we manage. We do timeliness tracking for data sources, builds, and jobs. We want to know if a data source failed to deliver an update before a complex build is kicked off. The DataOps Engineer can automate the creation of artifacts related to data structures, such as change logs that are automatically updated. We have data profiling tools that we run to compare versions of datasets. We have automated testing and a system for exception reporting, where tests identify issues that need to be addressed. All this serves to Increase transparency, which is critical to increasing trust in the process and analytics work product.

Figure 1: The DataOps Engineer considers the end-to-end people, processes and tools that act upon data.
Shepherding Processes Across the Corporate Landscape
The flow of data is fundamental to the organization. You pull information from wherever it’s generated, transform it and summarize it. Then you redistribute it to where it’s needed for people who have to make decisions and act.
DataOps Engineers are not just focused on their narrow swimlanes. They must consider the end-to-end people, processes and tools that act upon data – figure 1. The path of information doesn’t follow the lines of authority or the traditional hierarchies of an organization. We have to follow the data wherever it goes. Data paths span departments, buildings, time zones, companies, cultures, and countries. The DataOps Engineer serves as a catalyst to bring siloed contributors and teams together.
A previous post talked about the definition of “done.” In DataOps, the understanding of the word “done” includes more than just some working code. It considers whether a component is deployable, monitorable, maintainable, reusable, secure and adds value to the end-user or customer. Sometimes people confuse “doneness” with ownership. We often refer to data operations and analytics as a factory. We distinguish between owning the assembly lines of the data factory (DataOps Engineer) and owning individual steps within the assembly lines (data scientists, engineers, etc.).
When people become concerned about defending their turf, it leads to less transparency, less reusable logic, and loss of control over source code. It is harder to QC (quality control) methods and data spread among different segments and places. More points of failure ultimately lead to less reliable results. One approach that has worked well for the DataOps Engineering team at DataKitchen is the concept of building a process hub.
Process Hub
A process hub is a coherent common framework, shared workspace, and shared set of services that coordinate tasks and amplify the value contributed by various workflow participants. For example, one of the services built by our Data Engineers is an engine that generates QC rules from baseline data. It then autogenerates QC tests based on those rules. It’s an excellent way to quickly scale up to a large set of small tests for a new orchestrated process. Once this capability is in place, data scientists, analysts and engineers can take advantage of it.
The common framework of a process hub implicitly encourages collaboration, and it’s essentially a pipeline from a development process to a production process. The process hub that ties development and production together shows how they relate to each other – figure 2. Development and production exist as different points within a workflow, as do the users who work within the process framework.
The process hub allows everyone to leverage everyone else’s best work, and it liberates people from drudgery. For example, analysts keep working on insights. They don’t have to understand how to deploy analytics into production – an automated QC and deployment orchestration performs that job. When analysts stay focused, it speeds up deployment.
Another advantage to a process hub is transparency. With workflows “on the grid,” the organization can view process activity at an aggregated level. You can track, measure and create graphs and reporting in an automated way. The result is a single version of the process that supports a single version of the truth.
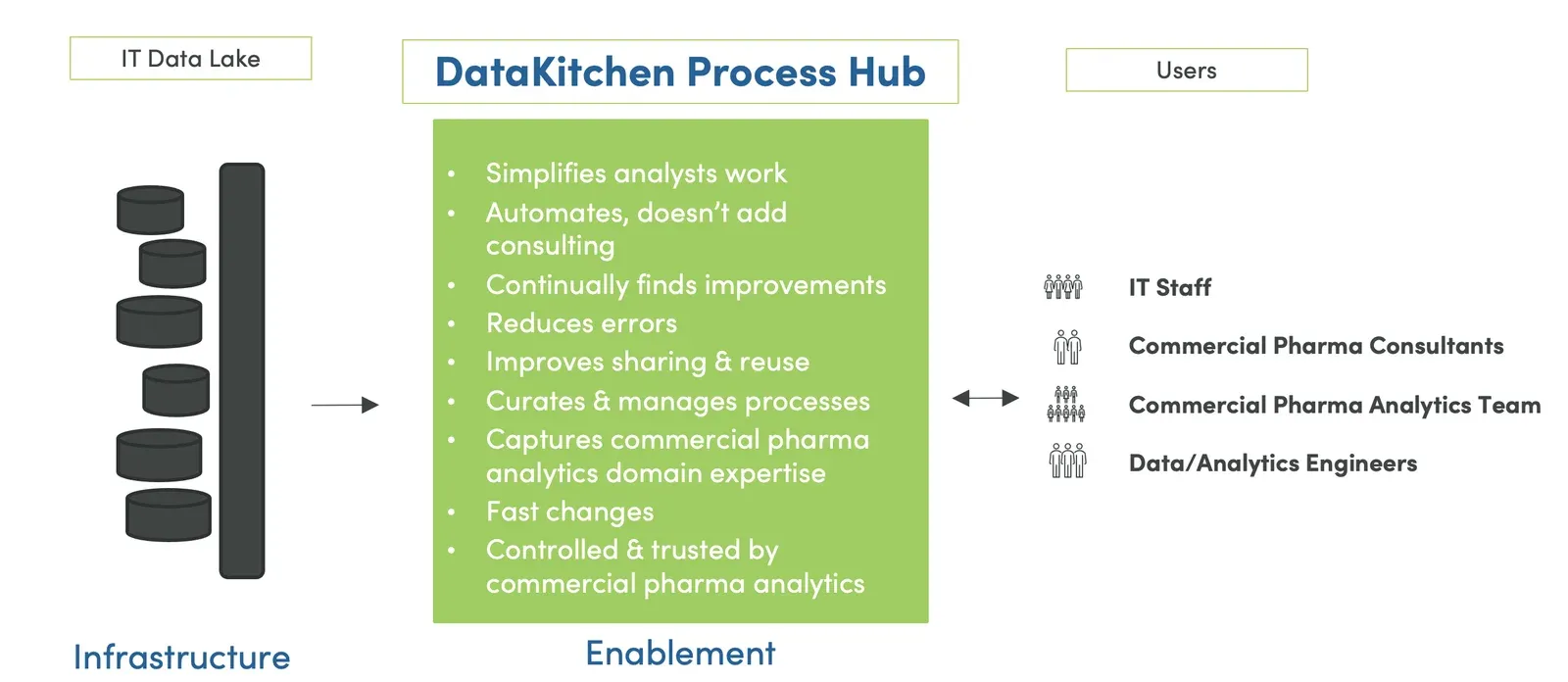
Figure 2: A process hub is a coherent common framework, shared workspace, and shared set of services that coordinate tasks and amplify the value contributed by various workflow participants.
Run Toward Errors
DataOps Engineers run towards errors. This may sound trite, but it is very challenging. Errors drive the feedback loop that makes complex processes reliable. There is complexity in data flows that cut across so many different structures that we can’t possibly anticipate everything that will go wrong. We try. There are always going to be surprises. So each error is an opportunity to go back and improve reliability. Consider a machine learning example. Let’s say a data scientist has developed a model that works perfectly with training data. You don’t necessarily see its bias and variance. When subjecting it to real-world data, it may behave differently, and you must adjust accordingly. Errors are data just like any other data and need to be understood and analyzed for data professionals to do their jobs more effectively.
Best Practices Related to Errors
If a DataOps Engineer actively seeks to avoid errors, they will fail (or succeed less). In DataOps, avoiding errors is doing any of the following:
- Meet the spec (and only the spec) – narrowly define success so you can prematurely declare victory. In one situation, we had a partner performing updates based on matching identifiers from a data set that we provided them. They sent us back an email saying that the process had been successful. What they didn’t tell us was that there were a large number of missing records and the spec said to exclude those. The missing records were due to an upstream problem. We missed critical updates, and this partner could have alerted us had they not been dogmatically following the spec.
- Demand perfection (and stifle feedback) – Perfection is usually unrealistic, and you’re not going to get it. What you will get is less honest feedback. People will hide their mistakes, and you won’t find out about errors until they explode in a high-profile data outage.
- Resist disruption (and avoid change) – resisting change keeps a system static and unable to adapt to changing business conditions.
- Protect your secrets (and hide error risks) – people generally don’t like negative attention. Still, one thing I have found at DataKitchen is that changing the culture and attitudes around errors helps to improve processes. It really makes a difference.
- QC the end-product (not the process) – you can confirm and validate that you’ve made one deliverable work successfully, but if you have to repeat it again and again, you need to QC every step of a process
- Make problems disappear (without solving them) – Senior data professionals know dozens of shortcuts for making a problem go away without actually addressing it. One of the biggest mistakes is to misuse the SELECT DISTINCT statement in SQL to make duplicate records disappear. It may work around a short-term error, but it doesn’t necessarily make the data more correct for the next person who might be working on a different use case. Another classic trick in RedShift is to set MAXERRORS to a high value. Doing so will sidestep a data error, but could potentially admit thousands of errors into the system. It is better to just fix the RedShift error upfront.
The DataOps approach encourages the data team to l ove our errors. We want to manage the possibility of errors as a routine part of our daily effort to improve the overall system. Every time we see an error, we address it with a new automated test. Our system designs are built with the expectation that people will make mistakes. We don’t want to embarrass anyone. We want to empower people, not blame them. We all need to know when these issue issues arise and what we do about them.
Another DataOps best practice curates mistakes. Our team has a checklist of silly errors that recur frequently. We want to avoid making those errors a second time. We’re also testing data at every step of the process. You catch more errors testing each step of a pipeline instead of just testing at the end.
Testing along the way also enables us to recover faster in a critical situation. It helps to know precisely where in a complicated and lengthy sequence an error was introduced. From personal experience, I favor a large number of simple tests rather than a few complex ones. You can’t anticipate all of the different things that can wrong so casting a wide net of simple tests can be more effective.
Another best practice is to double-check what you already know is true. Some day someone may change data inputs or analytics or introduce an error in an upstream process. Testing what you already know can help you find errors in business logic that stem from future scenarios that you can’t anticipate today.
DataOps Collaboration
It’s essential to communicate and provide timely feedback about errors. I was involved with an upstream system that neglected to apply an overhead factor to a financial calculation. The downstream analysts caught the problem, and instead of asking the upstream team to fix it, they worked around the problem by applying the overhead factor to their downstream analytics. The upstream team had no clue.
One bright day, someone on the upstream team fixed the bug and broke all of the downstream analytics, which were now applying the overhead factor a second time. The upstream team had been trying to fix a problem but unintentionally made it worse. Timely communication is essential in data organizations.
DataOps is first and foremost about collaboration. It’s about reuse. It’s about creating tested reliable functionality that is leveraged as a building block in a system. With a carefully constructed process hub, you can successfully minimize errors and create a culture of transparency.
TIP
To learn more about the role of a DataOps Engineer, watch the on-demand webinar, A Day in the Life of a DataOps Engineer.



