
Below is our fourth post (4 of 5) on combining data mesh with DataOps to foster innovation while addressing the challenges of a decentralized architecture. We’ve covered the basic ideas behind data mesh and some of the difficulties that must be managed. Below is a discussion of a data mesh implementation in the pharmaceutical space.
For those embarking on the data mesh journey, it may be helpful to discuss a real-world example and the lessons learned from an actual data mesh implementation. DataKitchen has extensive experience using the data mesh design pattern with pharmaceutical company data.
In the United States, private manufacturers of pharmaceuticals receive a patent for a limited period of time – approximately 20 years. In figure 1 below, we see that the data requirements are quite different for each of three critical phases of a drug’s lifecycle:

Table 1: Lifecycle phases of pharmaceutical product launch
Each distinct phase of the drug lifecycle requires a unique focus for analytics. During the launch phase, the focus is on marketing to patients through consumer channels. A successful launch lays the groundwork for the growth phase where (the manufacturer hopes) physicians prescribe the drug. As generic alternatives become available, the market enters the maturity phase where cost efficiency and margins become most important. There are different teams within the pharmaceutical company that focus on the respective target markets. Each phase is important, but a weak launch cuts the legs out from under the growth phase and decreases the lifetime revenue of the product. The analytics team is under tremendous pressure during the early phases of the drug’s lifetime. The business users propose questions and ideas for new analytics and require rapid response time. Data mesh and DataOps provide the organization, enterprise architecture, and workflow automation that together enable a relatively small data team to address the analytics needs of hundreds of active business users.
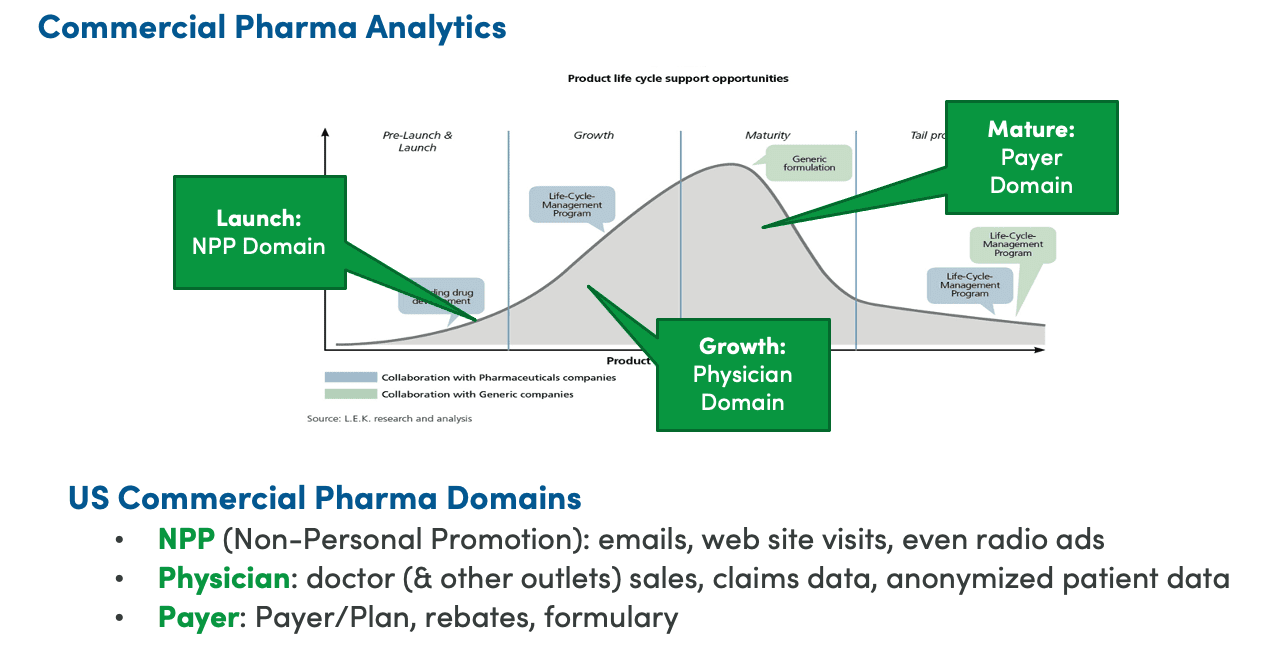
Figure 1: Data requirements for phases of the drug product lifecycle
Pharma Data Requirements
Drug companies maintain internal data sets and rely heavily upon third-party data (a multi-billion dollar industry). Some data sets are used by multiple teams, but that introduces complexity. Figure 2 shows the vast array of data sets used by pharmaceutical product launch organizations.

Figure 2: Data feeding the drug product lifecycle domains
Some data sets are a mix of actual and projected data, complicating their use with other data sets that purport to be the same but use a different algorithm to fill in gaps or posit projections. Two data sets of physicians may not match. They each tell a different story about the data.
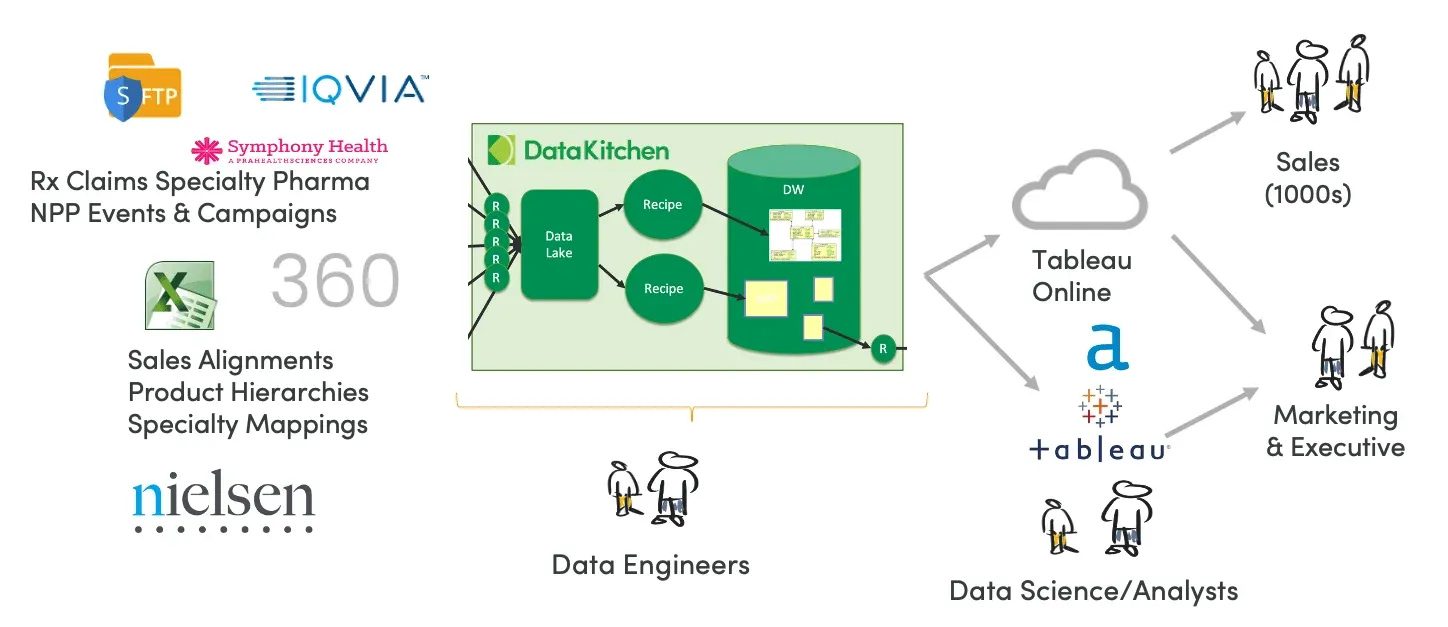
Figure 3: Example DataOps architecture based on the DataKitchen Platform
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a data warehouse leveraged by users and self-service data analysts. These users are very important to the company because their success greatly influences the strength of the revenue ramp in the drug’s growth and maturity phases.
A sales or marketing team member could propose an idea –– what if we combined data from sources A and B to find potential customers for our new product? The data engineer updates the Recipe (orchestration) that feeds the data lake if a data source needs to be added and modifies the Recipe that generates the data warehouse. The new Recipes run, and BOOM! The data scientists and analysts have what they need to build analytics for the user. With DataOps automation, making an analytics change is cut to a fraction of what it takes to execute an update manually.
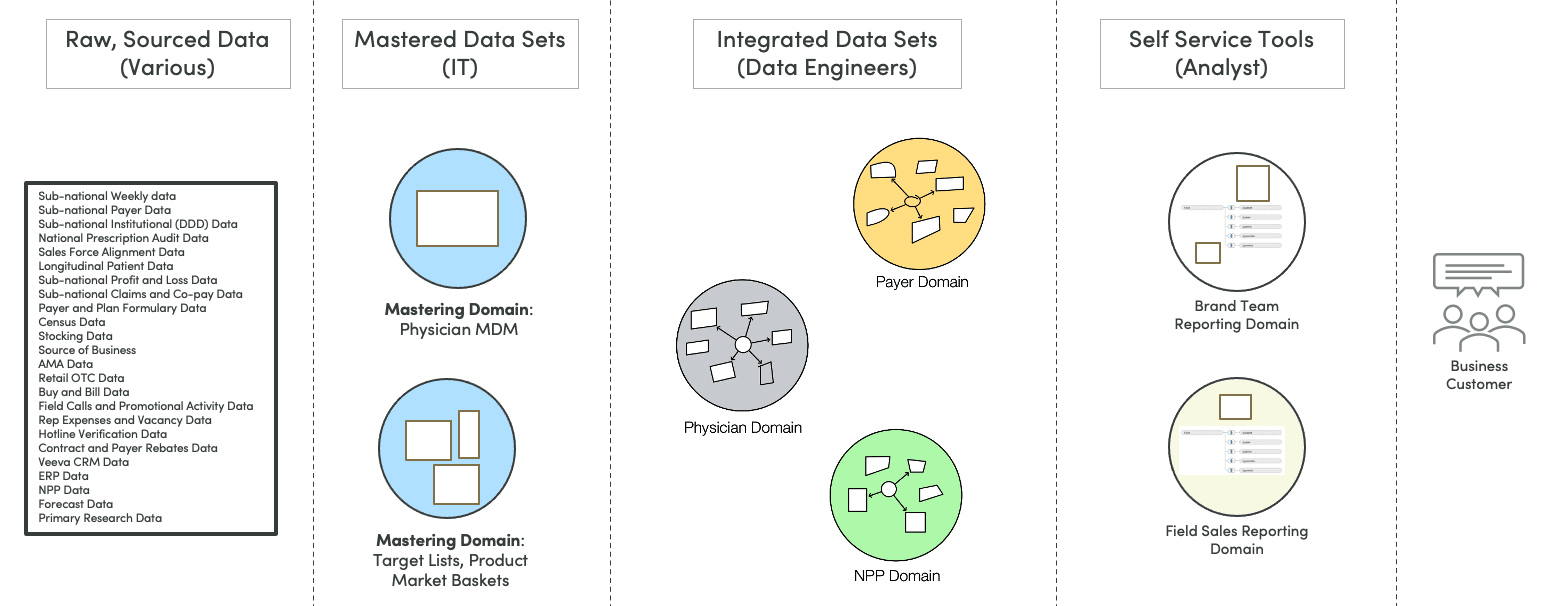
Figure 4: Example domain partitioning
Pharma Data Mesh Domains
Placing responsibility for all the data sets on one data engineering team creates bottlenecks. Let’s consider how to break up our architecture into data mesh domains. In figure 4, we see our raw data shown on the left. First, the data is mastered, usually by a centralized data engineering team or IT. Each of the mastered data sets could be a domain. For example, there may be one million physicians in the US, but for a given drug product, perhaps only 40,000 are important. Getting this standardized is vital because it affects sales compensation.
The second set of domains are the integrated data sets created by data engineers in the form of data warehouses or analytic data marts. There are facts and dimensions, along with multiple tables, used to answer business questions. In many cases, these are star schemas.
The third set of domains are cached data sets (e.g., tableau extract) or small data sets that self-service analysts can mix with the central data in Alteryx or other tools. Self-service data science teams may require their own segmentation models for building reports, views, and PowerPoints.
Each circle in figure 4 could be its own data mesh domain. The separation of these data sets enables the teams to decouple their timing from each other. In figure 5, we see that each domain has its own domain update processing (Recipes or data analytics pipelines), represented by a directed-acyclic graph (DAG). For each domain, one would want to know that a build was completed, that tests were applied and passed, and that data flowing through the system is correct.
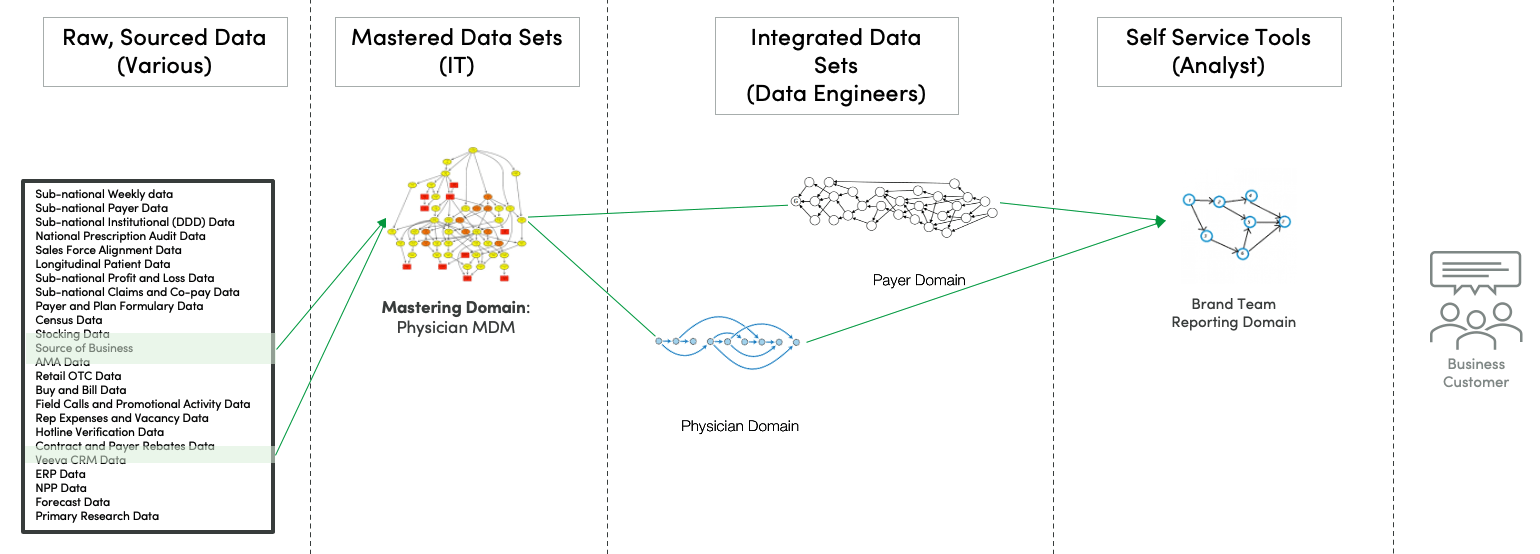
Figure 5: Domain layer processing steps
There’s a top-level DAG relationship between the raw data, arriving asynchronously, the mastered domain, the integrated data sets and the self-service domain. One challenge is that each domain team can choose a different toolset that complicates multi-level orchestration, testing and monitoring. A DataOps superstructure like DataKitchen that supports connectors to data ecosystem tools addresses this issue.
Another challenge is how to manage ordered data dependencies. The American Medical Association (AMA) may update its data set of physicians, which flows into the physician mastered domain. It then gets used by the physician and payer data warehouses which are eventually used by the self-service teams. We would not want the physician data set in the physician domain and the payer domain to drift apart or get “out of sync,” which might happen if they are updated on different iteration cadences. While the goal of a data mesh is to empower teams through decentralization, the overall architecture has to consider the order-of-operations dependencies between the domains. Manual processes that enforce synchronization and alignment interfere with domain-team productivity and are a common cause of unhappy users.
To manage complexity, the system requires inter-domain communication shown in the table below. A domain query provides information about builds, data, artifacts, and test results. Process linkage aids in multi-level DAG orchestration. Some designs perform process linkage with an event bus that marks the completion of a DAG by putting an event on a Kafka queue, using a publish/subscribe model. Data linkage refers to the sharing of common tables or the output of data from one domain being fed into another. Finally, there is development linkage. Can development environments with all related domains be created easily? Can they be modified? Is there a seamless path to production?
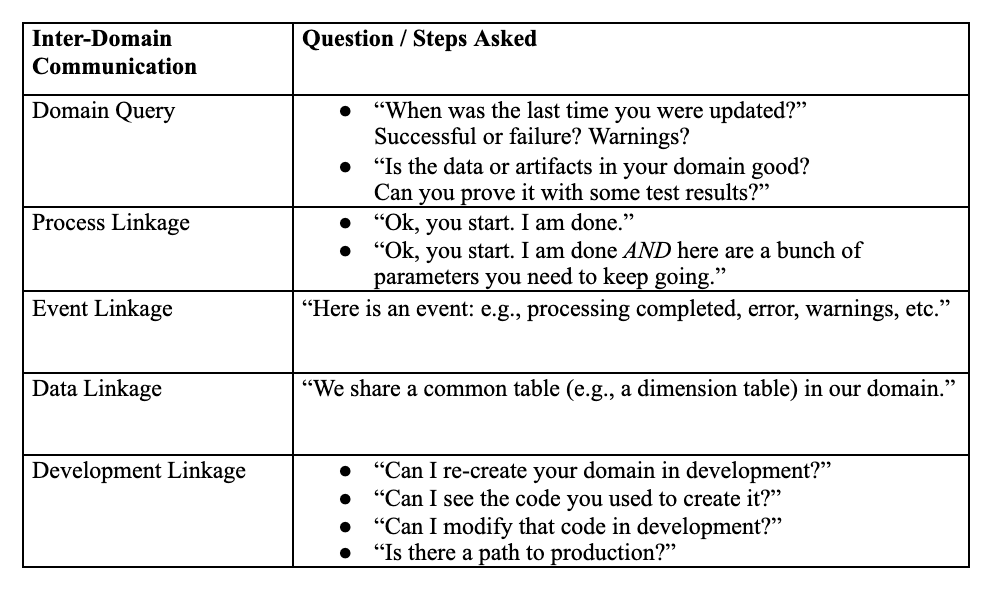
Table 2: Inter-Domain Communication
The many ports or access points of inter-domain communication illustrate why it’s so helpful to support URL-based queries. It enables the data engineer to ask questions, parse responses and set up automated orchestrations instead of maintaining checklists and manual procedures that someone must execute.
Conclusion
While there are unique aspects to the pharmaceutical industry, the flow from data sources to a data lake to a data warehouse to self-service analysts is a common design pattern that cuts across industries. Data mesh organizes teams and the system architecture so that mastered data sets, integrated data sets and self-service users can work independently and together. DataOps automates processes and workflows so that the productivity of any individual domain team isn’t overwhelmed by the complexity of the overall system. DataOps keeps inter-domain tasks flowing so that the domain team can progress at their optimal speed.
Data mesh is a powerful design pattern that leading enterprises are using to organize their enterprise analytics architectures. In our next post, we will look at tools capabilities essential for building a successful data mesh. Our discussion focuses on the value of automation and how DataOps serves as the wind beneath the wings of data mesh. If you joined this series midway, you can return to the first post here: ” What is a Data Mesh?”


