
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and data architecture and views the data organization from the perspective of its processes and workflows. The DataKitchen Platform is a “process hub” that masters and optimizes those processes. The term process hub is new to most people, so let’s look at a concrete example of how a process hub is used in a real-world application. The requirement to integrate enormous quantities and varieties of data coupled with extreme pressure on analytics cycle time has driven the pharmaceutical industry to lead in DataOps adoption.
The Last Mile Problem
During a pharmaceutical launch or any phase in a drug’s lifecycle, the data team must utilize processes that promote teamwork and efficiently act upon the data. The bottom line is how to attain analytic agility? The typical pharmaceutical organization faces many challenges which slow down the data team:
- Raw, barely integrated data sets require engineers to perform manual, repetitive, error-prone work to create analyst-ready data sets.
- A slow, un-agile approach to supporting commercial pharma analytics means that the team must do data work manually.
- Repetitive data process and query work reduce the time the commercial pharma analytics team has to create original insight.
- A lack of shared and reusable ‘ingredients’ extends the time required for analysts to perform ad hoc analyses.
- Firefighting and stress are common.
- Errors are caused by inconsistencies in how the analytics team applies data processes and business logic.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a data lake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a data lake to the final delivery of insights. One data engineer called it the “last mile problem.”
In our many conversations about data analytics, data engineers, analysts and scientists have verbalized the difficulty of creating analytics in the modern enterprise. These are organizations with world-class data engineers and the industry’s best-in-class toolchains. When we hear articulations like these, we recognize that they have neglected to pay attention to their processes and workflows.
- “How do we execute the same level of service faster?”
- “What kind of back-end process can we institute to answer ‘what-if’ questions faster?”
- “My team is being too reactive. We need to be more proactive with our customers.”
- “This is a last-mile problem.”
- “Right now, this is a 90% commercial pharma analytics problem and 10% an IT problem.”
- “It’s too hard to change our IT data product. I don’t understand how they do it or QA it.”
- “Can we create high-quality data in an “answer-ready” format that can address many scenarios, all with minimal keyboarding?
- “I wish I were in a better position. I get cut off at the knees from a data perspective, and I am getting handed a sandwich of sorts and not a good one!”
One DataKitchen customer likes to point out that he feels that analytics teams in commercial pharma are competing with Amazon. Not because of AWS or some other technology, but rather because companies like Amazon have compressed response and delivery times. If Amazon can deliver an order in one or two days, business users want the same response time from the analytics team. They want questions answered the next day and answers being delivered to the field next week. It is an on-demand world. How does an analytics team attain that insane velocity of finding quick answers to questions and then cranking out production-grade insights?
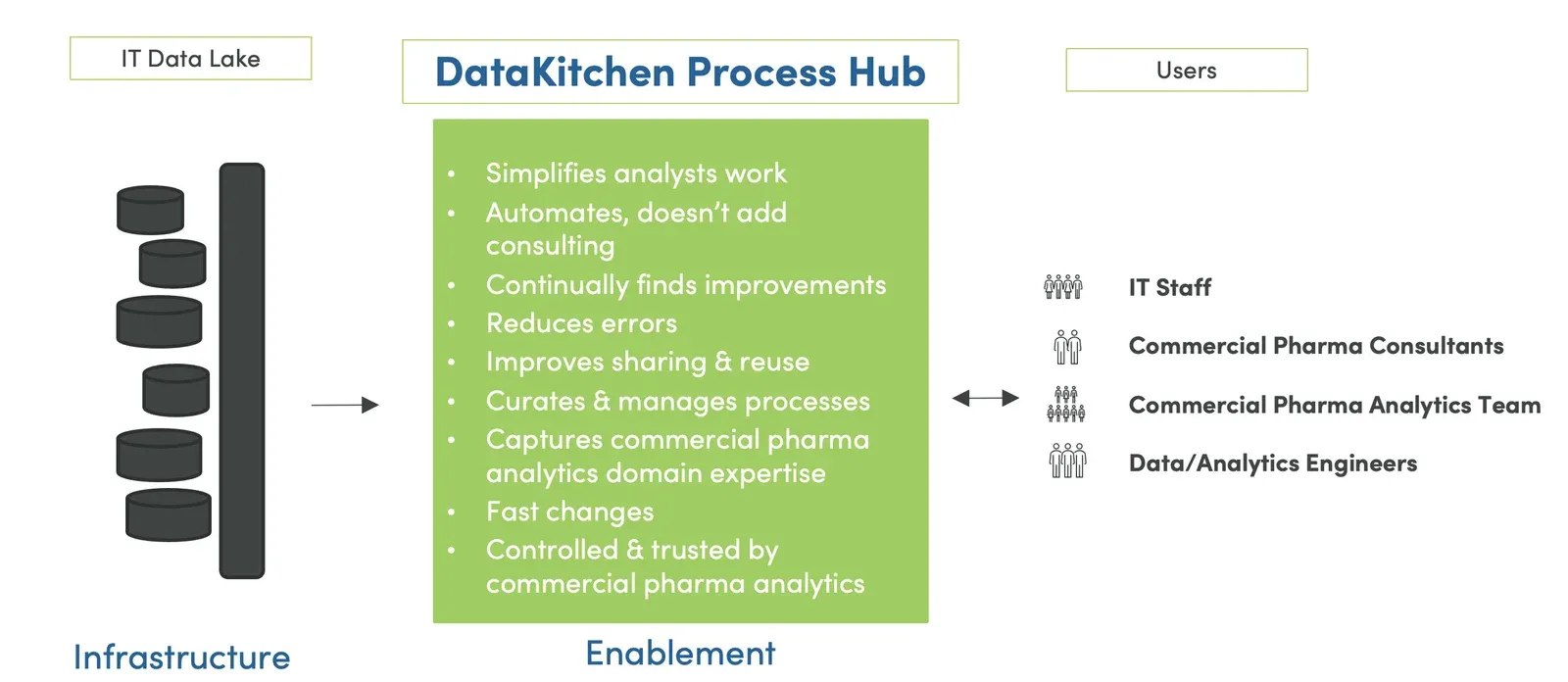
Figure 1: The DataKitchen DataOps Platform serves as a process hub.
It’s common for organizations to have built a data lake with lots of data – or a data hub to facilitate data exchange. They lack a place to centralize the processes that act upon the data to rapidly answer questions and quickly deploy sustainable, high-quality production insight. Automation provides a way to accomplish this without hiring expensive teams of consultants. Think of it as a way to curate and manage the processes that act upon data and gather analytics domain expertise in one controlled and trusted place instead of keeping it on desktops distributed throughout the organization.
Centralize the Process
If you centralize the process, you can generalize the process. B y generalizing the process, you can save time and effort, thereby freeing up the capacity to get more insight to your customers. You can think of the DataKitchen DataOps Platform as a “process hub” that coordinates activity across multiple teams, vendors and locations with governed, reusable process components that automatically detect errors. DataOps works on top of your existing data, allowing you to use your favorite tools, whether you prefer SQL, Alteryx, Tableau, Looker or whatever else. DataOps is an open, secure platform that enables anyone granted permission to access data and update the processes and workflows that operate on data. DataOps eliminates bottlenecks and delays by putting everything related to analytics under the control of the internal data team and reducing the need for outside consultants.
The DataKitchen DataOps Platform delivers on these capabilities and many more:
- Automated, governed and reusable processes
- Multi-team, multi-vendor and multi-location collaboration
- Rapid turnaround time
- Automated error reduction
- Analyst-ready trusted data sets
- Tools agnosticism – works on top of an existing data lake and your toolchain of choice
- Reusable libraries of recipes and ingredients
- Open, secure platform for anyone to:
- Access data and analytics
- Change the processes used to create data and analytics
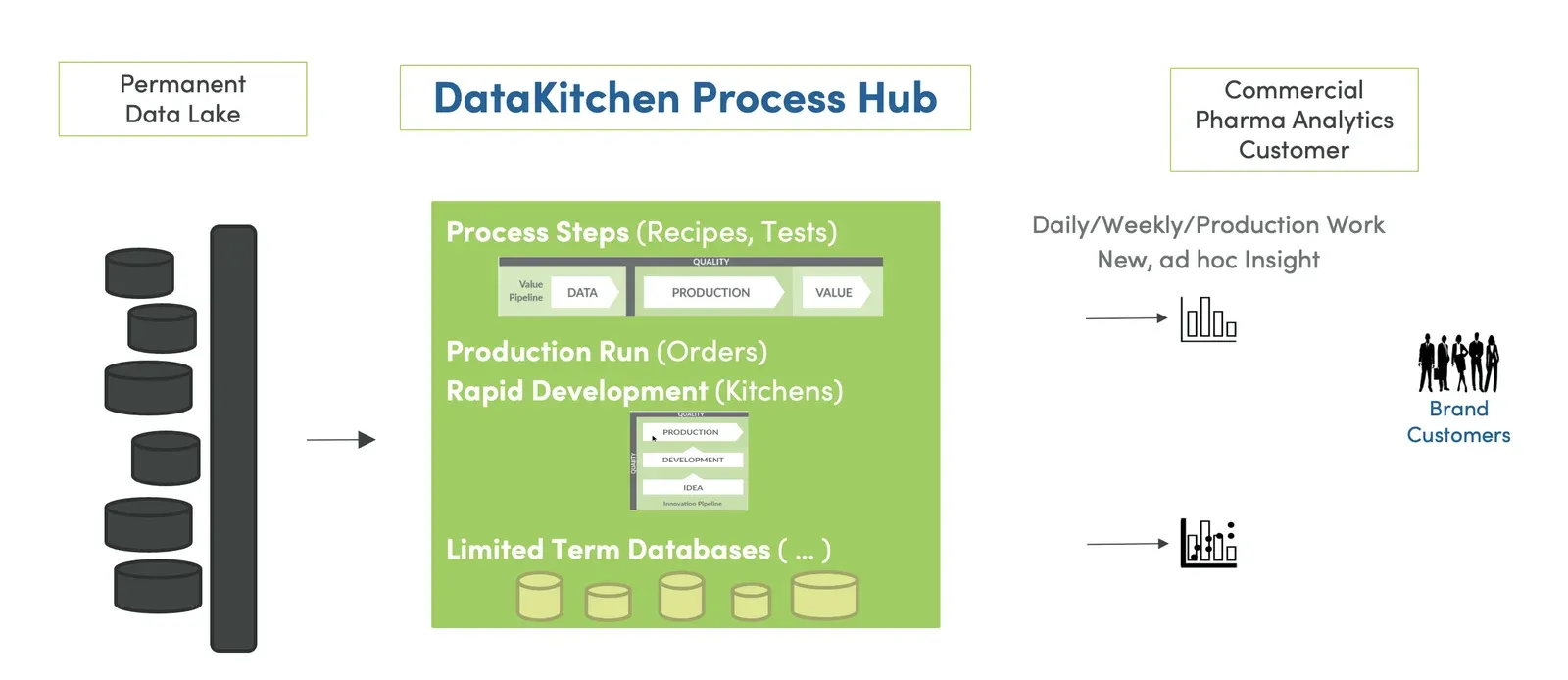
Figure 2: Employing a DataOps Platform as a process hub minimizes the cost for new analytics.
Your IT organization may have a permanent data lake, but data analytics teams need the ability to rapidly create insight from data. The DataKitchen Platform serves as a process hub that builds temporary analytic databases for daily and weekly ad hoc analytics work. These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub.
The process hub, in the middle of figure 2 above, is built for rapid change. It is expressly designed to minimize the cycle time of translating an idea into high-quality production insight. The DataKitchen Platform is based on a “process first” principle that minimizes the “cost per question.” How can the investment required to create new analytics be reduced such that it is possible to ask many more questions in a shorter amount of time? The process hub capability of the DataKitchen Platform ensures that those processes that act upon data – the tests, the recipes – are shareable and manageable.
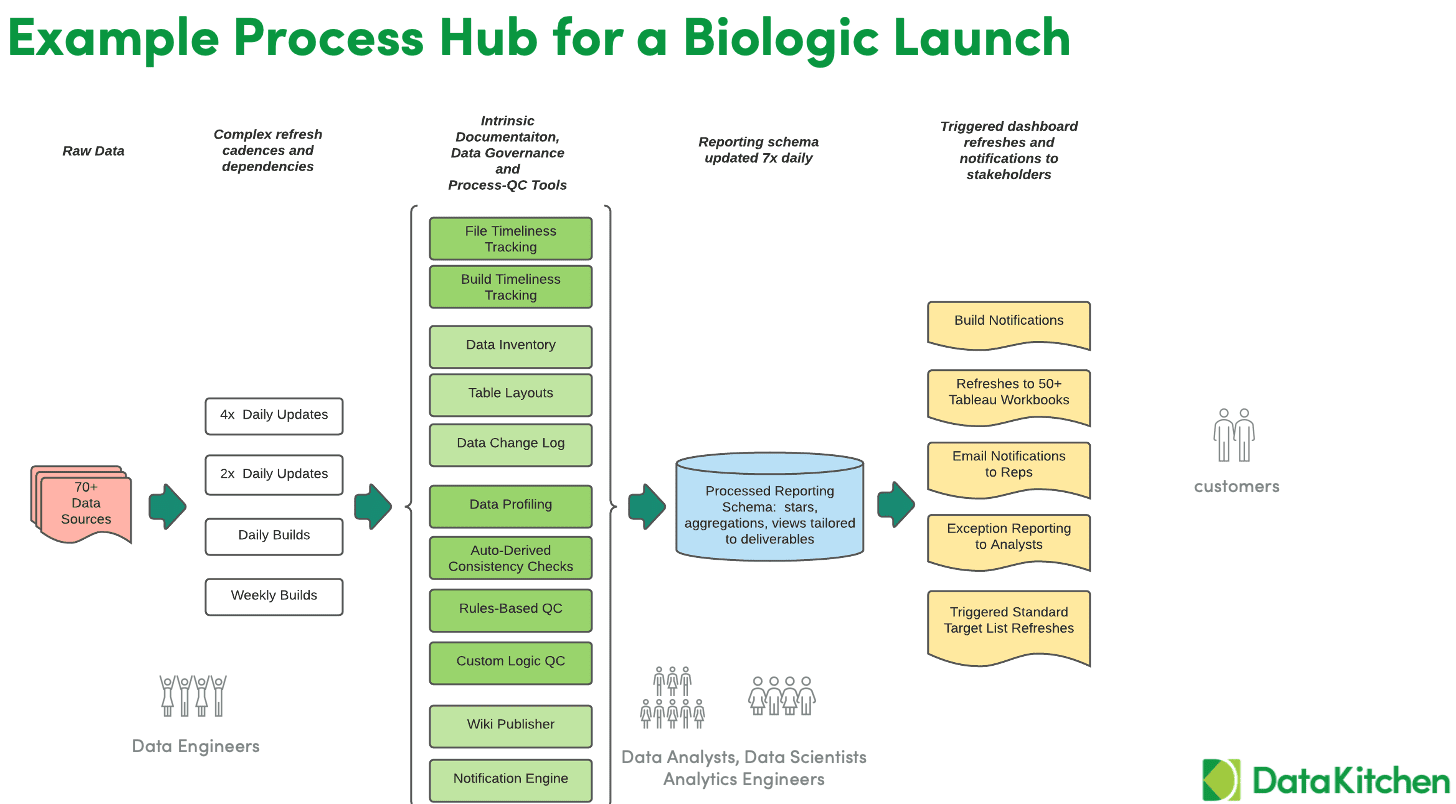
Figure 3: Example process hub for biologic launch
Let’s take a look at an example DataOps process hub for an actual biologic launch. The data pipelines must contend with a high level of complexity – over seventy data sources and various cadences, including daily/weekly updates and builds. Biologic data is complicated and not clean, so the process hub first profiles the data and imposes automated, rule-based quality checks. Has the data arrived on time? Is the quantity of data correct? When the tests pass, the orchestration admits the data to a data catalog.
New data is shared with users by updating reporting schema several times a day. This delivery takes the form of purpose-built data warehouses/marts and other forms of aggregation and star views tailored to analyst requirements. When these builds are complete, notifications trigger refreshes of dashboards, Tableau workbooks, and whatever standard reports the business unit requires.
The analytics supported by the DataOps process hub are extremely agile from two perspectives. The production analytics are updated several times a day using dozens of data sources arriving asynchronously. Perhaps more importantly, members of the data team may quickly update process orchestrations related to data at any time. With a process hub, it is possible to make dozens of process changes per week. Deployments include new data sets, new schemas, new views, whatever is required. This flexibility is accomplished while maintaining an extremely low error rate because the process tests data at every stage of the process. Errors are caught by the data team, not the consumers of analytics.
The DataOps process hub implements automation that replaces an army of people who previously executed manual tests, checklists and procedures. The team redeploys its newly freed resources on projects that create analytics that fulfill business requirements. The DataOps process hub allows commercial pharma analytics teams to produce more insight, faster and at the speed that the customers and business demand. Some features and benefits of the DataKitchen DataOps Platform are shown in the table below.
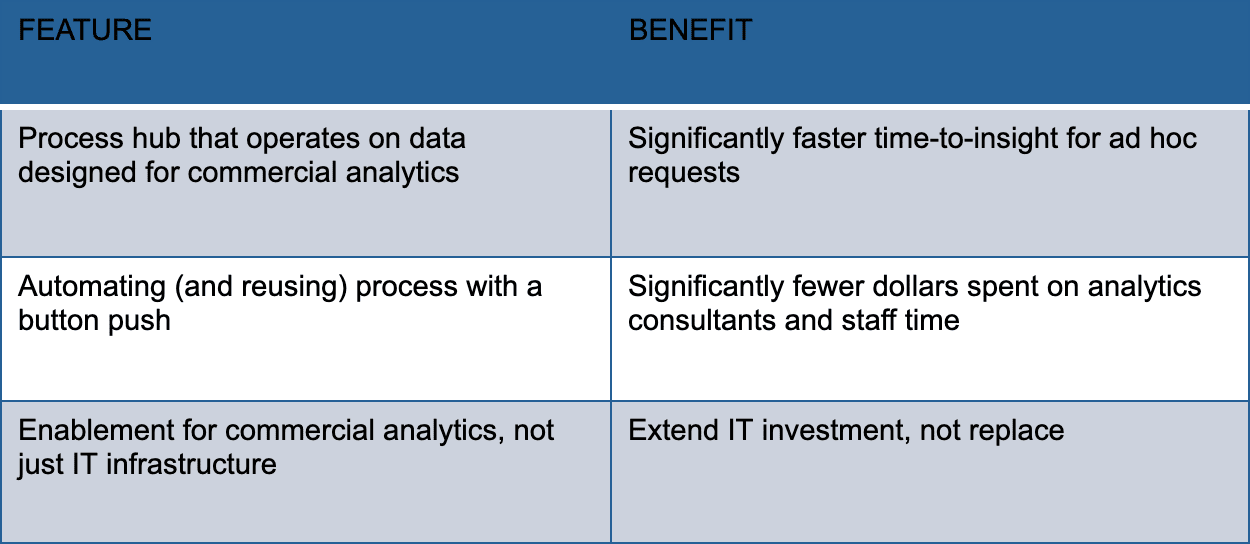
Table 1: DataKitchen Platform process hub features and benefits.
When the processes that act upon data are designed for rapid refresh and rapid-response to analytics questions, the data team can achieve a much faster time-to-insight and lower cost of implementation for ad hoc requests. DataOps automation replaces the non-value-add work performed by the data team and the outside dollars spent on consultants with an automated framework that executes efficiently and at a high level of quality. Focusing on the processes that operate on data enables the team to automate workflows and build a factory that produces insights.
The DataOps process hub does not replace a data lake or the data hub. It is an automation layer that spans the entire existing toolchain. If you are an Informatica shop or run Snowflake or Databricks, DataKitchen works alongside data ecosystem tools and integrates them into the process hub.
Although this might be seen as heresy by some, the DataOps process-centric approach considers the processes that act upon data are as important as the data itself. Neglecting those processes opens an organization up to delays, errors and unplanned downtime. Embracing the process-oriented approach to data analytics leads to ever faster and more flexible analytics development and operations with virtually zero downtime.
The DataOps Advantage
From a DataOps perspective, success is being able to build analytics consistently across dozens of product teams. It’s about deploying pipelines at scale across a large number of people and spanning a multitude of toolchains. It’s about quality assurance, automation, reusability, and repeatability. DataOps strives for analytics agility which leads to business agility. When the analytics team works rapidly and accurately, they can do a better job supporting decision-makers. It’s that simple.
DataOps is becoming an essential methodology in enterprise data organizations. Companies that implement it will derive significant competitive advantage from their superior ability to manage and create value from data. They will be able to produce high-quality, on-demand insight that consistently leads to successful business decisions. DataOps is fundamentally about eliminating errors, reducing cycle time, building trust and increasing agility. Companies that do these things well will win the next business cycle.


