
Data organizations don’t always have the budget or schedule required for DataOps when conceived as a top-to-bottom, enterprise-wide transformational change. An essential part of the DataOps methodology is Agile Development, which breaks development into incremental steps. DataOps can and should be implemented in small steps that complement and build upon existing workflows and data pipelines. Rapid and repeated development iterations minimize wasted effort and non-value-add activities. We call this approach “Lean DataOps” because it delivers the highest return of DataOps benefits for any given level of investment. With Lean DataOps, you can start small and grow your DataOps capabilities iteration by iteration. Lean DataOps delivers ” bang for the buck” by prioritizing activities that will most impact the productivity of the individual or team. As productivity improves, you can widen the DataOps circle and carefully invest in strategic process change that serves as the foundation for further improvements in team velocity.
DataOps do-it-yourselfers may start with DevOps, workflow or other lifecycle tools and customize them to integrate with their existing toolchains. Overall, this approach requires a tremendous investment before you start adding value – simply antithetical to the incremental approach that Lean DataOps proposes.
Lean DataOps relies upon the DataKitchen DataOps Platform, which attaches to your existing data pipelines and toolchains and serves as a process hub. With connectors to popular data industry tools, the DataKitchen Platform serves as the scaffolding upon which you can build incremental improvements to your end-to-end DataOps pipelines. DataKitchen jump-starts your efforts and enables you to focus on process improvement instead of infrastructure enablement. In short, Lean DataOps is the fastest path to DataOps value.
Figure 1 shows the four phases of Lean DataOps. These stages will often be executed in order but could be reordered according to an enterprise’s needs.

Figure 1: The four phases of Lean DataOps
1. Production DataOps
The pipelines and workflows that ingest data, process it and output charts, dashboards, or other analytics resemble a production pipeline. The execution of these pipelines is called data operations or data production. Production DataOps delivers a significant return on investment. If you have any doubt on how to get started, Production DataOps is an excellent choice because here DataOps can be implemented by a small team with no change to existing processes.
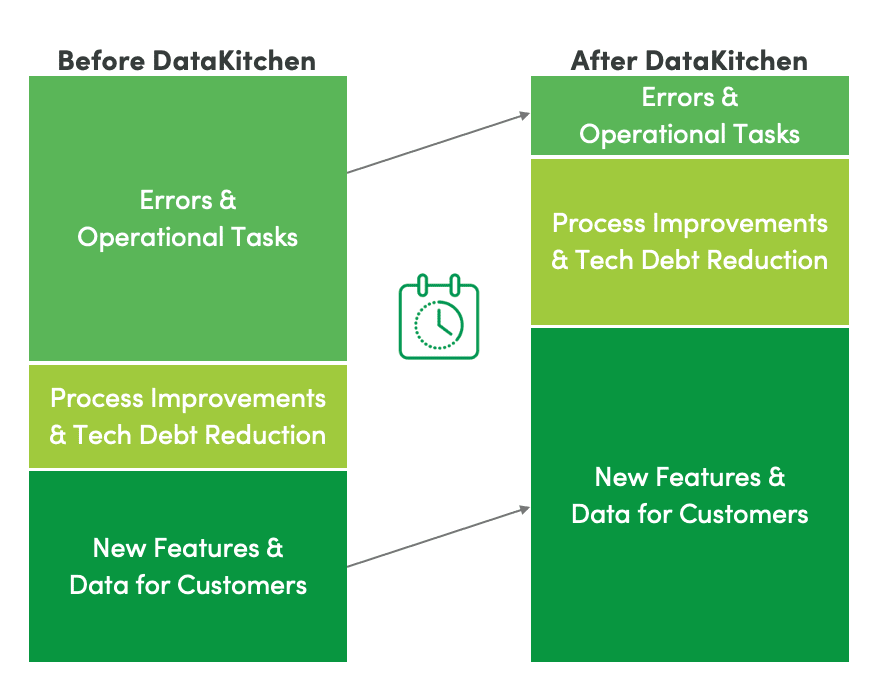
Figure 2: The DataKitchen Platform helps you reduce time spent managing errors and executing manual processes from about half to 15%. Source: DataKitchen
According to a recent Gartner survey, data teams spend only 22% of their time on “data innovation, data monetization and enhanced analytics insights.” The other 78% of their time is devoted to managing errors, manually executing production pipelines and other supporting activities. The goal of DataOps is to flip the script. The data team should be devoting 80% of their time to innovation and 20% to maintenance and support. Figure 1 shows the impact of the DataKitchen Platform on data team productivity. Data engineers, analysts and scientists spend about half of their time dealing with errors and executing tasks related to data operations (a.k.a. production). DataKitchen can help you reduce this time to around 15%. There are two dimensions of data production that serve as the biggest drivers of distraction and unplanned work: data errors and manual processes. We’ll discuss each in more detail.
Data Errors
Data errors impact decision-making. When analytics and dashboards are inaccurate, business leaders may not be able to solve problems and pursue opportunities. Data errors infringe on work-life balance. They cause people to work long hours at the expense of personal and family time. Data errors also affect careers. If you have been in the data profession for any length of time, you probably know what it means to face a mob of stakeholders who are angry about inaccurate or late analytics. If you are a senior staffer, you may have had the experience of manually checking a dashboard update the night before an important staff meeting.
In a medium to large enterprise, many steps have to happen correctly to deliver perfect analytic insights. Data sources must deliver error-free data on time. Data processing must work perfectly. Servers and toolchains must perform flawlessly. If any one of thousands of things is slightly off, the analytics are impacted, and the analytics team and their leaders are accountable.
The best way to ensure error-free execution of data production is through automated testing and monitoring. The DataKitchen Platform enables data teams to integrate testing and observability into data pipeline orchestrations. Automated tests work 24×7 to ensure that the results of each processing stage are accurate and correct. Start with just a few critical tests and build gradually. As the number of tests increases, errors and unplanned work decrease accordingly.
The DataKitchen Platform enables data teams to orchestrate tests at each stage of the production process. Figure 2 below shows the number of tests associated with each step in a data pipeline. When a test fails, the data team is notified through configurable alerts. DataKitchen also creates a common framework that can accept heterogeneous tools used in each node. So each data engineer or data scientist can use the tool they prefer, and the DataKitchen Platform handles the interfaces.
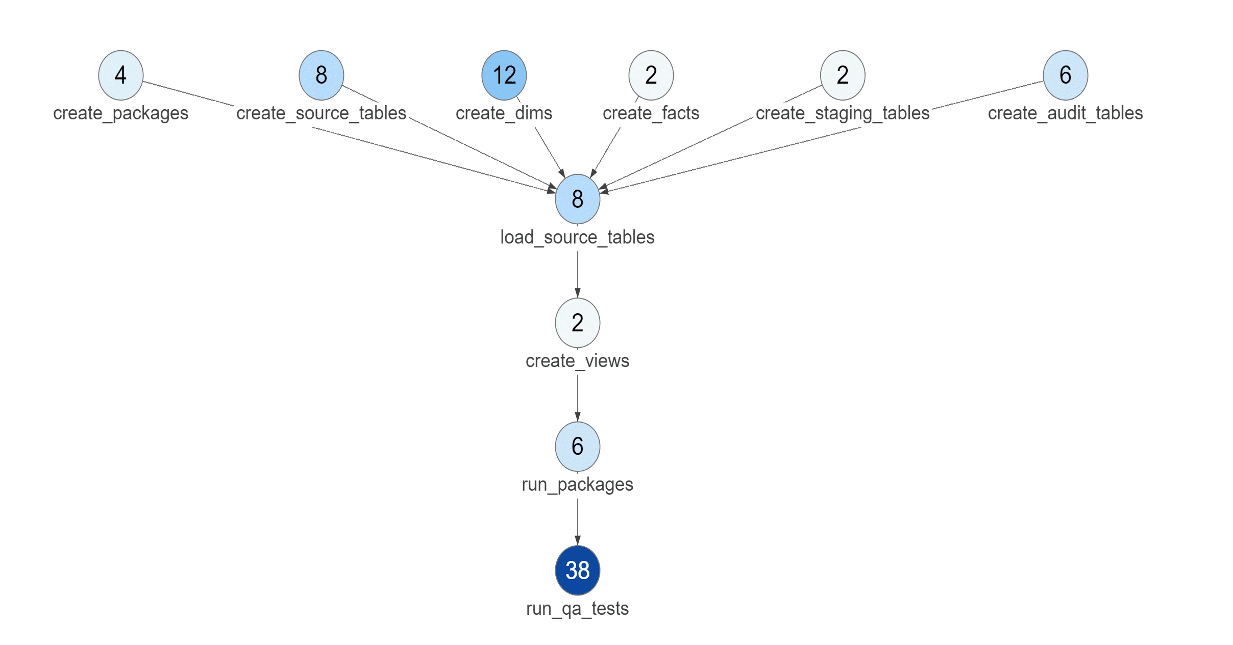
Figure 3: DataKitchen makes it easy for the data team to integrate testing and monitoring into production orchestrations. The above view of a data pipeline shows the number of tests at each stage of processing.
Enterprises that have implemented DataOps using DataKitchen typically have less than one data error per year. That is orders of magnitude better than the industry norm. In a recent DataOps survey, only 3% of the companies surveyed approached that level of quality. Eighty percent of companies surveyed reported five or more errors per month. Thirty percent of respondents reported more than 11 errors per month. This is a staggering figure, and it has implications in terms of the time spent on support and maintenance.
Reducing errors eliminates unplanned work that pulls members of the data team from their high-priority analytics development tasks. An enterprise cannot derive value from its data unless data scientists can stay focused on innovation. Errors undermine trust in data and the data team. Less trust means less data-driven decision-making. In other words, emotionally biased decision-making.
Errors in data analytics tend to occur in a very public manner. When data errors corrupt reports and dashboards, it can be highly uncomfortable for the manager of the data team. As embarrassing as it is to have your mistakes highlighted in public, it’s much worse if the errors go unnoticed. Imagine if the business makes a critical decision based on erroneous data?
DataKitchen integrates configurable, real-time alerts into data operations testing. Alerts notify the data team if data in the production pipelines requires attention. If there’s a problem, the data team knows about it before the users.
When DataOps testing with DataKitchen reduces errors to virtually zero, the data team avoids a major source of distraction. The hours formerly wasted on unplanned work can be put to more productive use – creating innovative analytics for the enterprise and improving productivity further by investing in DataOps process optimizations.
Manual Execution of Production
As discussed earlier, data professionals spend over half of their time on operational execution. Think of your data operations workflows as a series of pipeline steps. For example, data cleansing, ETL, running a model, or even provisioning cloud infrastructure. The majority of data teams execute part or all of these steps manually today.
Data professionals could do amazing things, but not while held back by bureaucratic processes. An organization is unlikely to surpass competitors and overcome obstacles while its highly trained data scientists are hand-executing data preparation, ingestion and other pipelines.
DataKitchen orchestration runs alongside existing toolchains, enabling data professionals to migrate segments or entire data pipelines to automated orchestration. Automated pipelines use resources more efficiently and can more easily scale to cope with large data sets. With DataKitchen, the data team can gradually migrate their data operations pipelines to an orchestration engine, eliminating lower value-add tasks.
Automated procedures free data scientists, analysts and engineers to refocus their time and energy on high-value add projects; new and enhanced analytic insights.
2. Development DataOps
To improve the speed (and minimize the cycle time) of analytics development, data teams need to find and eliminate process bottlenecks. Development bottlenecks prevent people from producing analytics at a peak level of performance. The DataKitchen Platform can improve data team agility by helping your data organization alleviate several common development workflow bottlenecks.
Maximizing Agility with Kitchens
The key to maximizing analytics developer productivity lies in designing automated orchestrations of common workflows that can be run by users on-demand. For example, when a project begins, users create a development environment that includes tools, data and everything else they need. In a non-DataOps enterprise, this process involves a lot of manual steps and delays. For example:
- Multiple management approvals
- Authentication of the user requesting the sandbox
- Provisioning of hardware assets
- Purchase/installation/configuration of software
- Replication/preprocessing/de-identification of data
We spoke to one enterprise recently that took between 10-20 weeks to complete these tasks. To improve their agility, they used DataKitchen to implement Kitchens that act as self-service sandboxes. A Kitchen is an environment that integrates tools, services and workflows. It includes everything a data analyst or data scientist needs to create analytics. For example:
- Complete toolchain
- Security vault providing access to tools
- Prepackaged data sets
- Role-based access control for a project team
- Integration with workflow management
- Orchestrated path to production
- Governance – tracking user activity with respect to regulated data
The Kitchen environment is “self-service” because it can be created on demand by any authenticated user. Creating and deleting sandboxes on-demand in hours affords much greater flexibility and agility than waiting weeks or months for environment creation. Kitchens help analytics developers hit the ground running on new data and analytics projects.
Speeding Deployment
When production and development environments use Kitchens, DataKitchen makes it simple to deploy new or updated analytics from development to production. A Kitchen is a virtual environment built upon a technical toolchain. When development and production environments are aligned, a data pipeline can be migrated from a development Kitchen to a production Kitchen with minimal keyboarding. Kitchens minimize the effort required to move analytics from one technical environment to another. When a developer creates an orchestrated data pipeline within a Kitchen, that data pipeline can migrate to and execute in any Kitchen with an equivalent toolchain architecture. The DataKitchen Platform automatically updates the embedded references from one toolchain instance to the other. Kitchens are one of the most powerful mechanisms used by DataKitchen to eliminate manual steps related to deployment.
Minimize Deployment Risk
Data organizations know they need to be more agile. To succeed, they need to learn lessons from software development organizations. In the 1990’s software teams adopted Agile Development and committed to producing value in rapid, successive increments. If you think a little about process bottlenecks in software development, Agile moved the bottleneck from the development team to the release team. For example, if the quality assurance (QA), regression and deployment procedures require three months, it hardly makes sense to operate with weekly dev sprints.
The solution is DevOps which automates the release process. Once an automated workflow is in place, releases can occur in minutes or seconds. Companies like Amazon perform code updates every 11.6 seconds. That’s millions of releases per year. Data analytics teams can achieve the same velocity using the DataKitchen Platform, which eases the task of integrating testing into the deployment workflow.
Using DataKitchen, automated testing is built into the release and deployment workflow. The image below is the Development Pipeline (innovation pipeline) which represents the flow of new ideas into development and then deployment. Testing proves that analytics code is ready to be promoted to production.
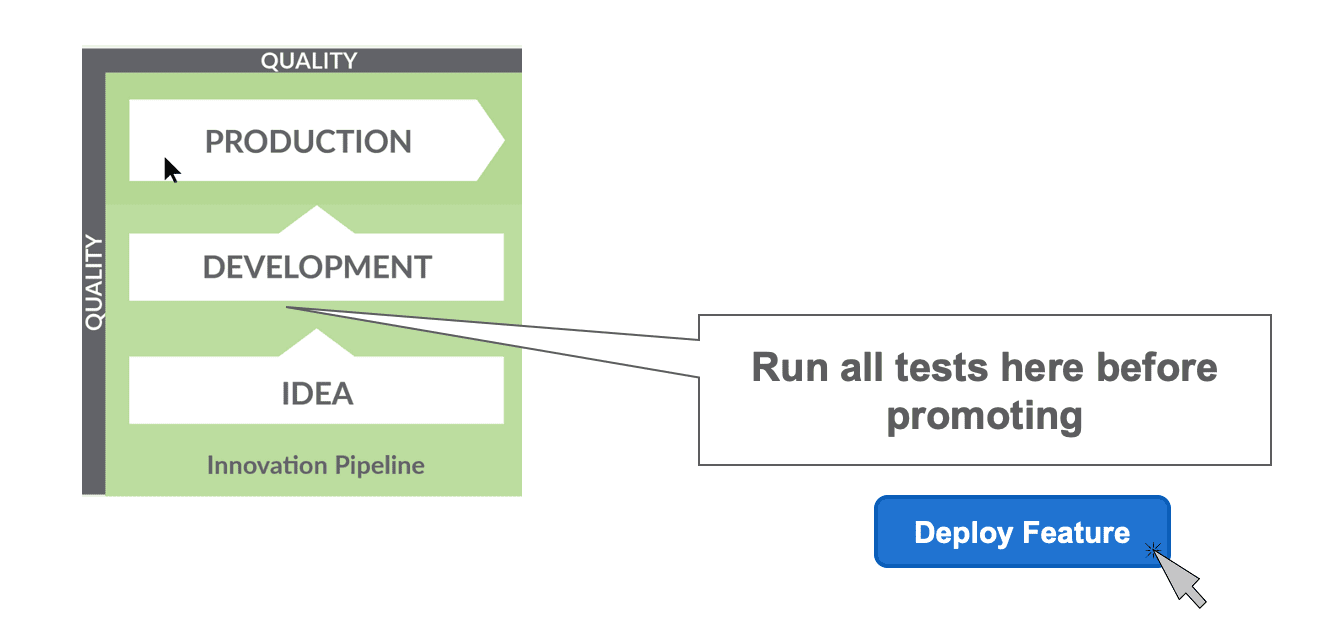
Figure 4: Tests should be run in development before deploying new analytics to production.
Benefits of Development Testing
Testing produces many benefits. It increases innovation by reducing the amount of unplanned work that derails productivity. Tests catch errors that undermine trust in data and the data team. This reduces stress and makes for happier data engineers, scientists and analysts.
As a group, technical professionals tend to dislike making mistakes, especially when the errors are splashed across analytics used by the enterprise’s decision-makers. Testing catches embarrassing and potentially costly mistakes so they can be quickly addressed.
Designing for Collaboration
Kitchens can be used quite effectively to coordinate the activities of distributed groups. A common use case is moving analytics from development to production. When Development DataOps is expanded more broadly, teams working in different locations or using different toolchains can also now collaborate with ease. The figure below shows a multi-cloud or multi-datacenter pipeline with integration challenges. The home office site in Boston and the self-service site in New Jersey have different personnel, different iteration cadences, different tools and are located far away from each other. Distributed groups like these sometimes fight like warring tribes, yet, they have to provide an integrated analytics solution for stakeholders such as the VP of Marketing.
The two groups managing the two halves of the solution have difficulty maintaining quality, coordinating their processes and maintaining independence (modularity). Each group independently tests its portion of the overall system. Do the two disparate testing efforts deliver a unified set of results (and alerts) to all stakeholders? Can their tests evolve independently without breaking each other? These issues repeatedly surface in data organizations.
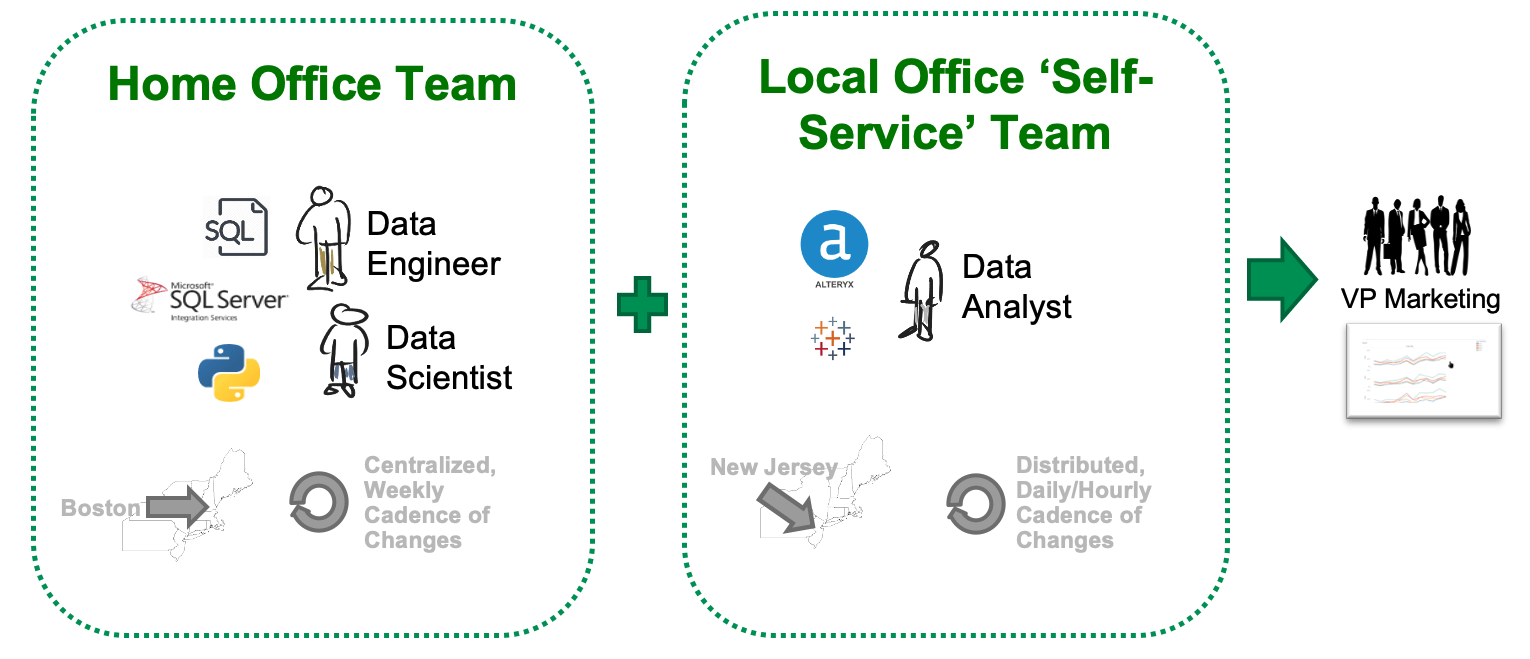
Figure 5: Distributed groups are challenged to coordinate an integrated analytics solution.
The DataKitchen Platform employs self-service Kitchens and DataOps automation to address these difficult challenges. The Kitchens in this environment are built within a seamless orchestration and meta-orchestration framework. Meta-orchestration refers to the integration of observability into a hierarchy of orchestrations. The home office team in Boston uses sandboxes built for their own data pipeline (Load, Transform, Calculate, Segment). The self-service team in New Jersey uses sandboxes aligned with their data pipeline (Add Data, Deploy, Publish). The sandboxes deploy analytics enhancements into their respective local data pipelines. The local pipelines are orchestrated by a DataOps Platform such as that supported by DataKitchen.
The highest meta-orchestration is the top-level pipeline (run-home-ingredient and run-local-ingredient) – perhaps managed by a centralized IT organization – also orchestrated by DataKitchen software. The local teams don’t have to understand the meta-orchestration or the toolchain of the other office. If any part of a local orchestration or meta-orchestrations fails a test, the group responsible is notified and can address it.
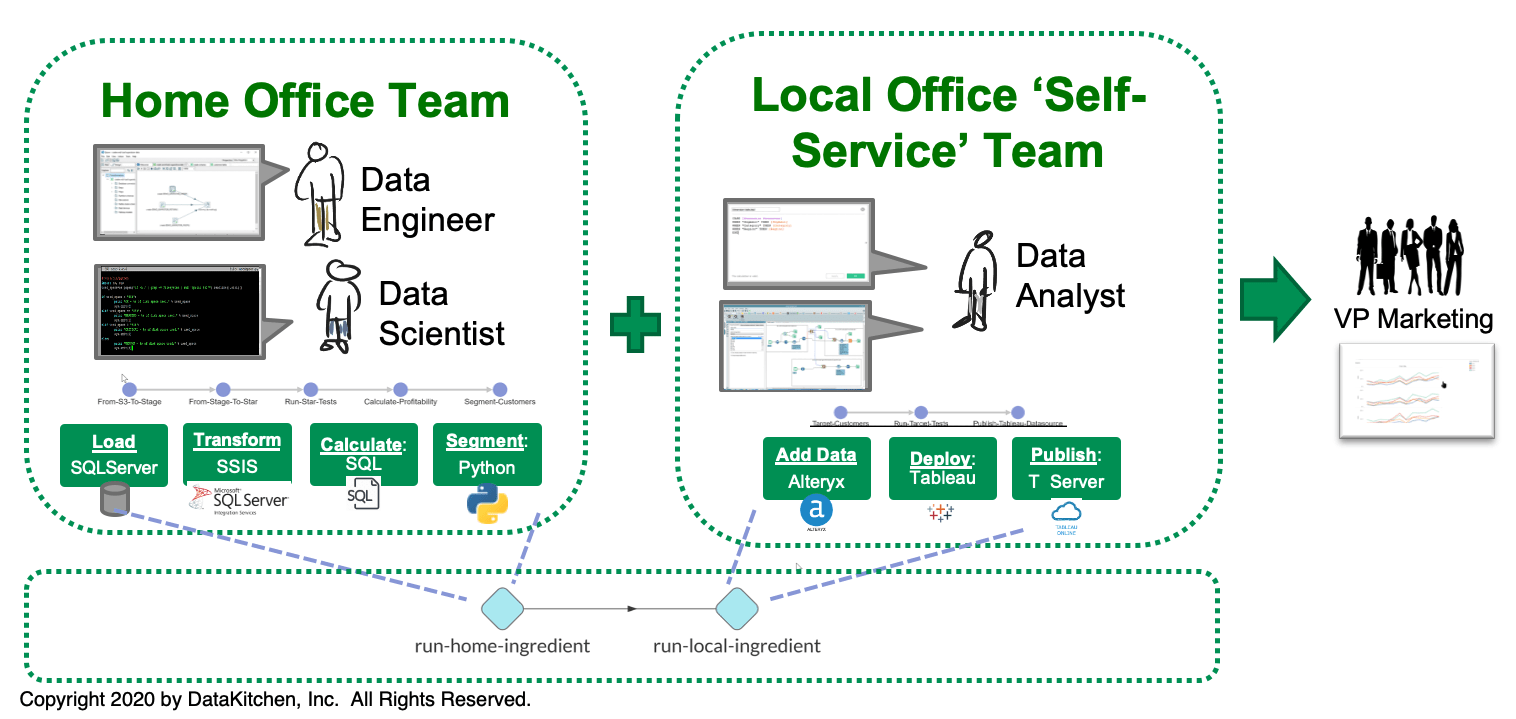
Figure 6: The DataKitchen DataOps Platform orchestrates the local pipelines and meta-orchestrates a top-level pipeline so that the two team efforts are coordinated and integrated.
Innovation Without Compromise
The DataKitchen Platform resolves the tension between the desires for faster agility and better quality. It uses self-service sandboxes to enable users to create analytics development environments on-demand. These sandboxes help users channel their creativity into new analytics that create value for the enterprise. Sandboxes also tie into orchestrations and meta-orchestrations that help individuals collaborate across locations, data centers, and groups. DataKitchen delivers all of these benefits while monitoring governance and enforcing policies as part of an automated framework. With DataKitchen, enterprises can move at lightning speed without compromising on quality, governance or security.
3. Measurement DataOps
Once you’ve made progress with your production and development processes, it’s time to start measuring and improving your processes with Measurement DataOps. The DataKitchen Platform will deliver an unprecedented level of transparency into your operations and analytics development. DataKitchen automated orchestration provides an opportunity to collect and display metrics on all of the activities related to analytics. Why not use analytics to seek further process improvements and shine a light on the benefits of DataOps itself?
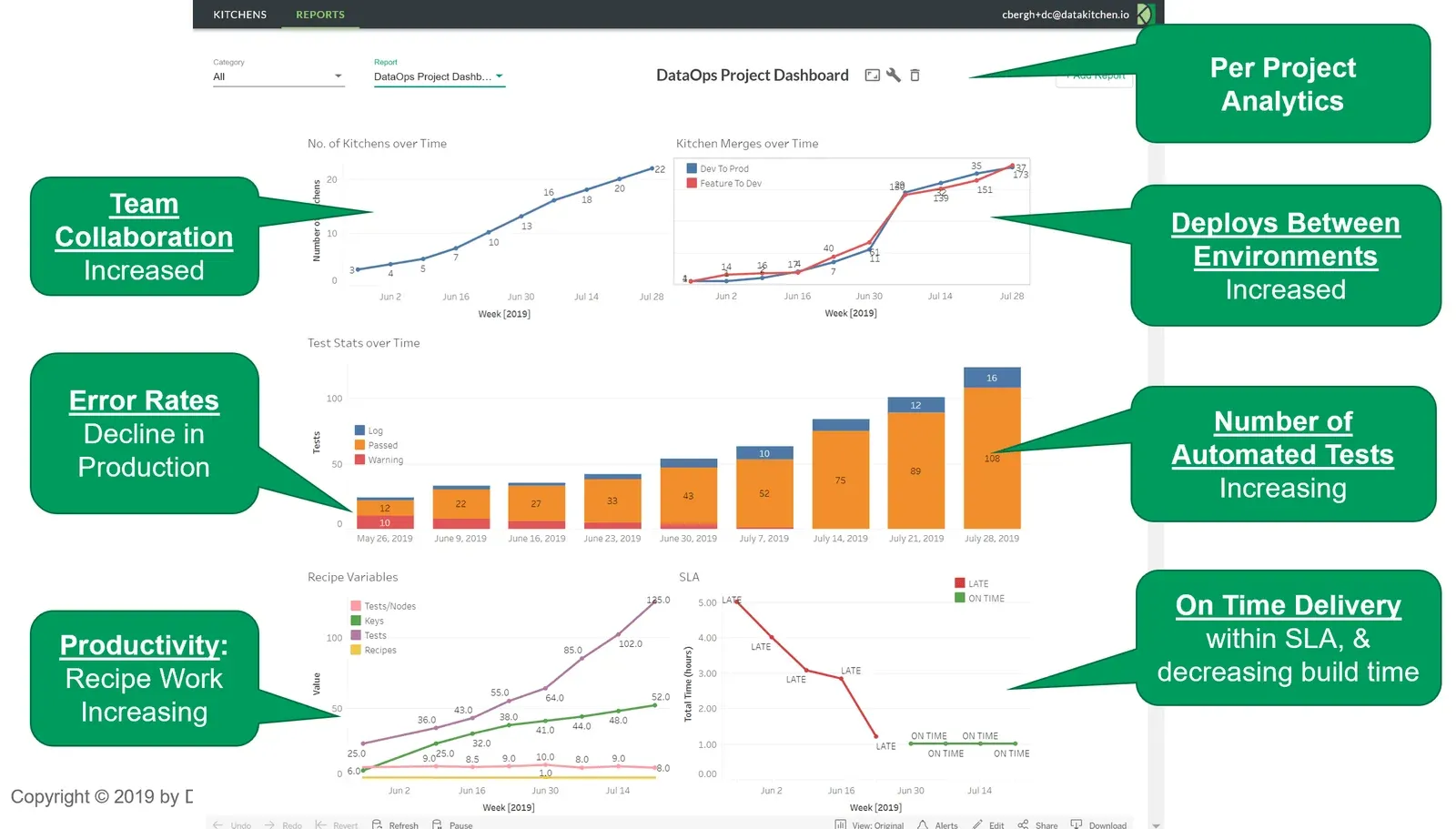
Figure 7: A typical DataOps dashboard delivered by the DataKitchen Platform.
Figure 7 shows a typical DataKitchen dashboard with metrics related to team collaboration, error rates, productivity, deployments, tests, and delivery time. Each of these measures sheds light on the organization’s development processes:
- Team Collaboration – Measure teamwork by the creation of virtual workspaces, also known as “Kitchens.” Each Kitchen creation corresponds to a new project or sub-project in a team context.
- Error rates – Shows production warnings at a rate of 10 per week, falling to virtually zero. This reduction in errors is the positive result of the 100+ tests operating 24×7 checking data, ETL, processing results, and business logic. As the number of tests increases, the data pipeline falls under increasingly robust quality controls.
- Productivity – Measure team productivity by the number of tests and analytics created. The rise in “keys” (steps in data pipelines) coupled with the increase in test coverage shows a thriving development team. Also, the number of Kitchen merges at the top right shows the completion of projects or sub-projects. The “Feature to Dev” metric shows new analytics ready for release. “Dev to Prod” merges represent deployments to production (data operations).
- On-time Delivery – Mean deployment cycle time falls sharply, meeting the target service level agreement (SLA).
Choose your metrics to reflect your DataOps project objectives. The metric gives the entire team a goal to rally around and also helps you prove DataOps value to your boss. The number of possible DataOps metrics is as varied as the architectures that enterprises use to produce analytics. When your team focuses on a metric and iterates on it, you’ll see significant improvements in each sprint.
4. Enterprise DataOps
DataOps delivers an unprecedented level of transparency into data operations and analytics development. When the first phases of DataOps demonstrate measured improvements in quality, teamwork, productivity and cycle time, the organization can make a strong case to expand DataOps to incorporate more staff, resources, and a broader scope. Successful DataOps programs often follow a gradual and methodical approach that builds value iteratively using Agile development. Enterprise DataOps expands DataOps across the organization or business unit for lasting transformational change.
Designing the Data Factory
A discussion of DataOps moves the focus away from architectures and tools and considers one of the most critical questions facing data organizations – a question that rarely gets asked. “How do you build a data factory?” Most enterprises rush to create architectures and analytics before considering the workflows that improve and monitor analytics throughout their deployment lifecycle. The careful design and refinement of the production and operations workflows that create, maintain and operate the data factory rarely receives as much attention as it deserves. It’s no wonder that data teams are drowning in technical debt.
Architecture, uptime, response time, key performance parameters – these are challenging problems, and so they tend to take up all the oxygen in the room. Take a broader view. Architect your data factory so that your data scientists lead the industry in cycle time. Design your data analytics workflows to minimize keyboarding, reliance on bureaucratic procedures, and add tests at every workflow stage to minimize errors. Doing so will enable the agility that your data organization needs to cope with rapidly evolving analytics requirements.
Enabling DataOps Adoption
The transformational benefits of DataOps are realized when enterprise-wide processes integrate work from disparate teams into seamless, efficient workflows. DataOps mediates the natural tension between centralization and decentralization. Freedom and employee empowerment are essential to innovation, but a lack of top-down control leads to chaos. The DataKitchen Platform acts as a process hub, helping teams across the organization manage this fundamental challenge.
Invent the Wheel Once
Beyond technical decisions, a key consideration for Enterprise DataOps is how to organize your team. If you roll out DataOps across several groups in an enterprise and turn them loose, one potential inefficiency is duplicating effort, each creating their individual version of enabling infrastructure that all groups require. One best practice incorporates DataOps into the organization chart. A sign of DataOps maturity is building a common technical infrastructure and tools for DataOps using centralized teams. A centralized DataOps team can give other groups a leg up, helping to bring DataOps benefits to every corner of an enterprise.
Your DataOps centralized team can create standard building blocks that are supplied as components or services to an array of groups doing DataOps work. For example, a DataOps team can implement enabling services needed by all teams rolling out Agile/DataOps:
- Source code control repository
- Agile ticketing/Kanban tools
- Deploy to production
- Product monitoring
- Develop/execute regression testing
- Development sandboxes
- Collaboration and training portals/wikis
A centralized DataOps group can also act as a services organization, offering services to other teams. Below are some examples of services that a DataOps technical services group can provide:
- Reusable deployment services that integrate, deliver and deploy end-to-end analytic pipelines to production.
- Central code repository where all data engineering/science/analytic work can be tracked, reviewed and shared.
- Central DataOps process measurement function with reports
- ‘Mission Control’ for data production metrics and data team development metrics to demonstrate progress on the DataOps transformation
- Test data management and other functions provided as a service
Measure DataOps Maturity
For organizations that wish to assess themselves, a DataOps Maturity Model can help them understand their strengths, weaknesses, and DataOps readiness. Maturity models are commonly used to measure an organization’s ability to continuously improve in a particular discipline. DataKitchen’s DataOps Maturity Model outlines a measurement approach for building, monitoring, and deploying data and analytics according to DataOps principles. With this model, teams can understand where they are today and how to move up the curve of DataOps excellence. Figure 8 shows an example Maturity Model result.
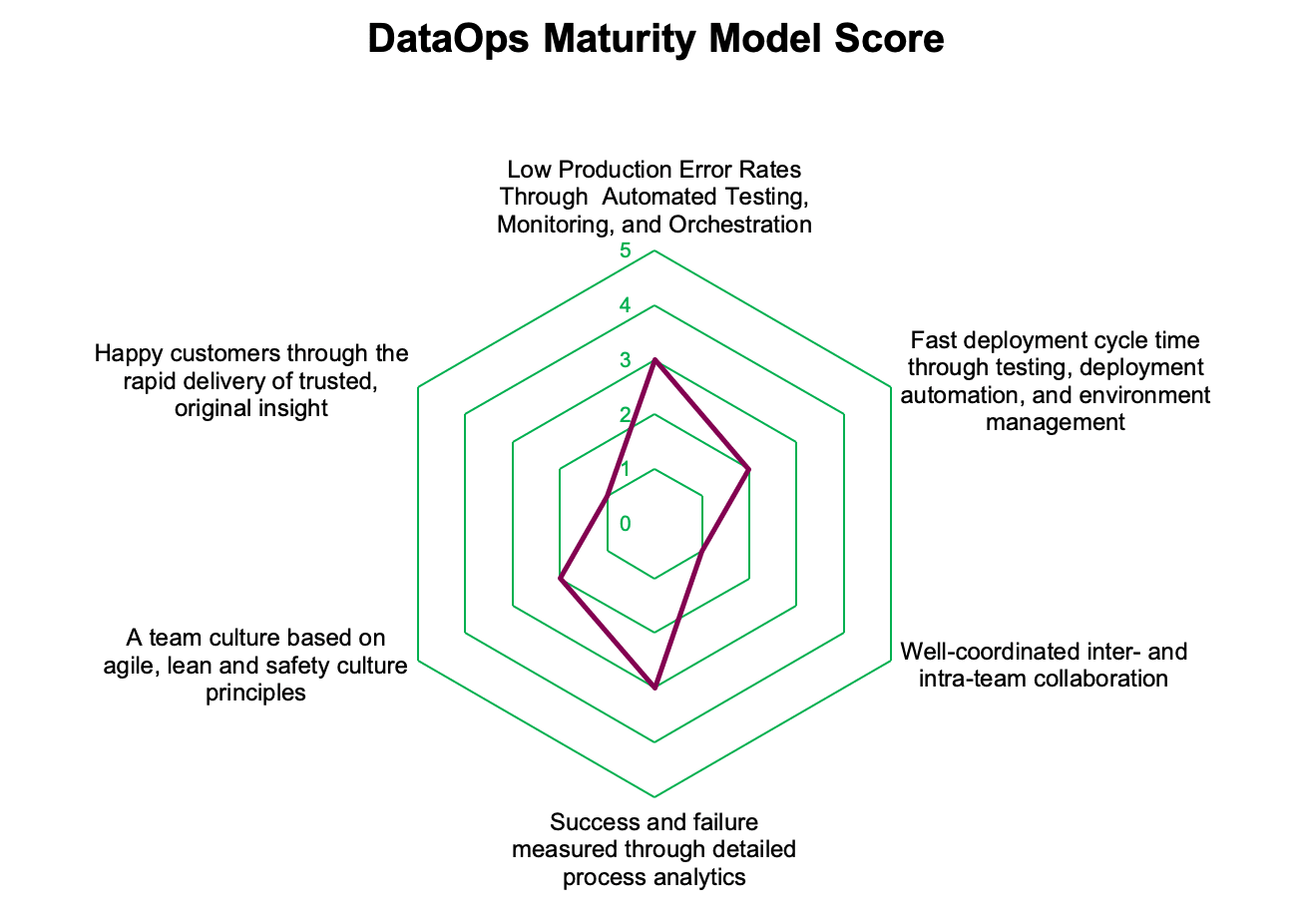
Figure 8: Typical Maturity Model results
Championing DataOps with DataKitchen
DataOps serves as a positive agent of change in an otherwise slow and process-heavy organization. Remember that leading change in technical organizations is equal parts people, technology and processes. DataOps offers the potential to reinvigorate data team productivity and agility while improving quality and predictability. Our simple four-phase program should help you introduce and establish DataOps in your data organization in an incremental and manageable way. Following this approach, you can get started today by integrating Production DataOps into your existing processes and then expand to the next phase when you are ready. In our experience, many data organizations desperately need the benefits that DataOps offers. Partnering with DataKitchen gives you the support and infrastructure to make your DataOps initiative a roaring success.


